0. 简介
我们研究了在密集且互动的拥挤人群中,考虑环境约束(如走廊和家具)的机器人导航问题。以往的方法未能充分考虑代理与障碍物之间的各种交互,导致机器人路径不安全且效率低下。本文《HEIGHT: HEterogeneous Interaction GrapH Transformer for Robot Navigation in Crowded and Constrained Environments》利用图形化表示法来描述拥挤和受限的场景,并提出一个结构化框架,通过深度强化学习来学习机器人导航策略。我们首先将环境中不同组件的表示进行拆分,并提出一种异构时空图,以建模人类、机器人和障碍物之间的不同交互。基于异构时空图,我们提出了HEIGHT,这是一种新颖的导航策略网络架构,具有不同组件,以通过时空捕捉实体之间的异构交互。HEIGHT利用注意力机制来优先考虑重要的交互,并采用递归网络来跟踪动态场景随时间的变化,鼓励机器人自适应地避免碰撞。
1. 主要贡献
本文扩展自我们之前工作中提出的注意力图网络的贡献[9]。虽然我们之前的研究集中于开放空间中的人群导航,但本文则结合了静态障碍物和约束条件,这导致了场景表示和网络架构的重大修改。针对这些方法上的变化,我们进行了新的仿真和硬件实验,并进行了新的基准比较。总而言之,本文的主要贡献如下:
- 我们提出了一种拥挤和受限环境的输入表示,区别对待人类和障碍物。拆分的场景表示自然地允许我们在框架的其余部分中注入结构。
- 我们提出了一种结构化的拥挤和受限场景的图形表示,称为异构时空图(st-graph),以有效建模所有代理和实体之间的成对交互。
- 基于异构时空图,我们采用一种原理性的方法推导出HEIGHT,这是一种基于变换器的机器人导航策略网络,具有不同模块以推理所有类型的空间和时间交互。
- 在密集人群和密集障碍物的仿真实验中,我们的方法在未见过的障碍布局中优于以往的最先进方法。此外,我们的方法在不同人类和障碍物密度的分布外环境中表现出更好的泛化能力。
- 我们成功地将低保真度模拟器中学习到的机器人策略转移到具有挑战性的现实世界日常拥挤环境中,而无需进行微调。

图1:异构图在机器人于拥挤和受限环境中导航时辅助时空推理。彩色箭头表示机器人与人类(RH)、人类与人类(HH)以及障碍物与代理(OA)之间的交互。实心箭头表示更重要的交互,而透明箭头则表示较不重要的交互。在每个时间步t,机器人对这些交互进行推理,关注重要的交互,并做出决策。
2. 基础知识
在本节中,我们将受限人群导航形式化为马尔可夫决策过程(MDP),并介绍场景表示和奖励函数。
2.1 MDP 形式化
我们将受限人群导航场景建模为一个 MDP,定义为元组$ ⟨S,A,P,R,γ,S_0⟩$。设 w t w^t wt 为机器人状态,包括机器人的位置 ( p x , p y ) (p_x,p_y) (px,py)、速度 ( u x , u y ) (u_x,u_y) (ux,uy)、目标位置 ( g x , g y ) (g_x,g_y) (gx,gy) 和航向角 θ \theta θ。设 h i t h_i^t hit 为时间 t t t 时第 i i i 个人类的当前状态,包括人类的位置和速度 ( p x i , p y i , u x i , u y i ) (p^i_x,p^i_y,u^i_x,u^i_y) (pxi,pyi,uxi,uyi)。设 o t o^t ot 为静态障碍物和墙壁的当前观测,表示为二维点云。我们将 MDP 的状态 s t ∈ S s^t \in S st∈S 定义为 s t = [ w t , o t , h 1 t , . . . , h n t ] s^t = [w^t,o^t,h_1^t,...,h_n^t] st=[wt,ot,h1t,...,hnt],如果在时间步 t t t 观察到总共 n n n 个人类,其中 n n n 在不同时间步内可能变化。人类根据与机器人的 L2 距离递增排序。状态空间 S S S 是连续的,我们在第4节中扩展了状态表示的选择。

图 2:我们在仿真和现实世界中的流程概述。 (a) 在训练和测试的每个时间步 t t t,仿真器提供奖励 r t r^t rt 以及环境的以下观测:障碍物点云 o t o^t ot、机器人状态 w t w^t wt 和人类状态 h 1 t , . . . , h n t h_1^t,...,h_n^t h1t,...,hnt,以及掩码 M t M^t Mt(详见第4.1节)。这些观测作为 HEIGHT 的输入,HEIGHT 输出一个机器人动作 a t a^t at,以最大化未来的期望回报 R t R^t Rt。仿真器执行所有代理的动作,循环继续进行。 (b) 现实世界中的测试循环与仿真器类似,唯一不同的是获取观测的感知模块不同,并且没有奖励。
在每个回合中,机器人从初始状态 s 0 ∈ S 0 s^0 \in S_0 s0∈S0 开始。如图 2(a) 所示,根据其策略 π ( a t ∣ s t ) \pi(a^t|s^t) π(at∣st),机器人在每个时间步 t t t 采取动作 a t ∈ A a_t \in A at∈A。机器人的动作由期望的平移和旋转加速度组成 a t = [ a t r a n s t , a r o t t ] a^t = [a_{trans}^t,a_{rot}^t] at=[atranst,arott]。动作空间 A A A 是离散的:平移加速度 a t r a n s ∈ { − 0.05 m/s 2 , 0 m/s 2 , 0.05 m/s 2 } a_{trans} \in \{-0.05 \text{ m/s}^2, 0 \text{ m/s}^2, 0.05 \text{ m/s}^2\} atrans∈{ −0.05 m/s2,0 m/s2,0.05 m/s2},旋转加速度 a r o t ∈ { − 0.1 rad/s 2 , 0 rad/s 2 , 0.1 rad/s 2 } a_{rot} \in \{-0.1 \text{ rad/s}^2, 0 \text{ rad/s}^2, 0.1 \text{ rad/s}^2\} arot∈{ −0.1 rad/s2,0 rad/s2,0.1 rad/s2}。平移和旋转速度分别限制在 [ − 0.5 m/s , 0.5 m/s ] [-0.5 \text{ m/s}, 0.5 \text{ m/s}] [−0.5 m/s,0.5 m/s] 和 [ − 1 rad/s , 1 rad/s ] [-1 \text{ rad/s}, 1 \text{ rad/s}] [−1 rad/s,1 rad/s] 之内。机器人的运动受 TurtleBot 2i 动力学的控制。作为回报,机器人获得奖励 r t r_t rt(详见第2.3 节),并根据未知的状态转移 P ( ⋅ ∣ s t , a t ) P(·|s^t,a^t) P(⋅∣st,at) 转移到下一个状态 s t + 1 s^{t+1} st+1。与此同时,所有其他人类也根据他们的策略采取行动,并以未知的状态转移概率移动到下一个状态。该过程持续进行,直到机器人达到目标、时间 t t t 超过最大回合长度 T = 491 T = 491 T=491 步,或机器人与任何人类或静态障碍物发生碰撞。机器人的目标是最大化期望回报 R t = E [ ∑ i = t T γ i − t r i ] R_t = \mathbb{E}\left[\sum_{i=t}^{T} \gamma^{i-t} r^i\right] Rt=E[∑i=tTγi−tri],其中 γ \gamma γ 是折扣因子。值函数 V π ( s ) V^\pi(s) Vπ(s) 定义为从状态 s s s 开始,依次遵循策略 π \pi π 的期望回报。
2.2 状态表示
在我们的马尔可夫决策过程(MDP)中,状态由大量且变化的代理组成。为了帮助在如此复杂的状态空间中进行策略学习,我们开发了一种结构化的状态表示,将其输入到结构化的策略网络中。为了减少由原始传感器读数引起的仿真与现实之间的差距,我们的场景表示利用了来自感知、地图和机器人定位的处理信息,这些信息对领域转移相对稳健。如图 3 所示,在每个时间步 t t t,我们将场景分为人类表示 h 1 t , … , h n t h^t_1, \ldots, h^t_n h1t,…,hnt 和障碍物表示 o t o^t ot。在人类表示中(图 3(b)),每个人类的位置和速度是通过现成的人类检测器检测的。通过将每个人类表示为低维状态向量,我们抽象掉了诸如步态和外观等难以准确模拟的详细信息。我们使用二维点云作为障碍物表示。我们并不是通过传感器获取点云,而是利用同时定位与地图构建(SLAM)技术,首先创建环境的地图。在导航过程中,如图 3© 所示,假设已知机器人在地图上的定位,从地图中计算出仅包含静态障碍物的“人工”点云。与来自传感器的实时点云相比,我们的障碍物表示不受人类存在的影响,因此对不准确的人类模拟的敏感性较低。权衡在于我们的方法需要一张地图和准确的定位。如果有高保真度的模拟器可用,“人工”点云可以被来自传感器的实时点云替代,而不改变我们下面描述的其余方法。
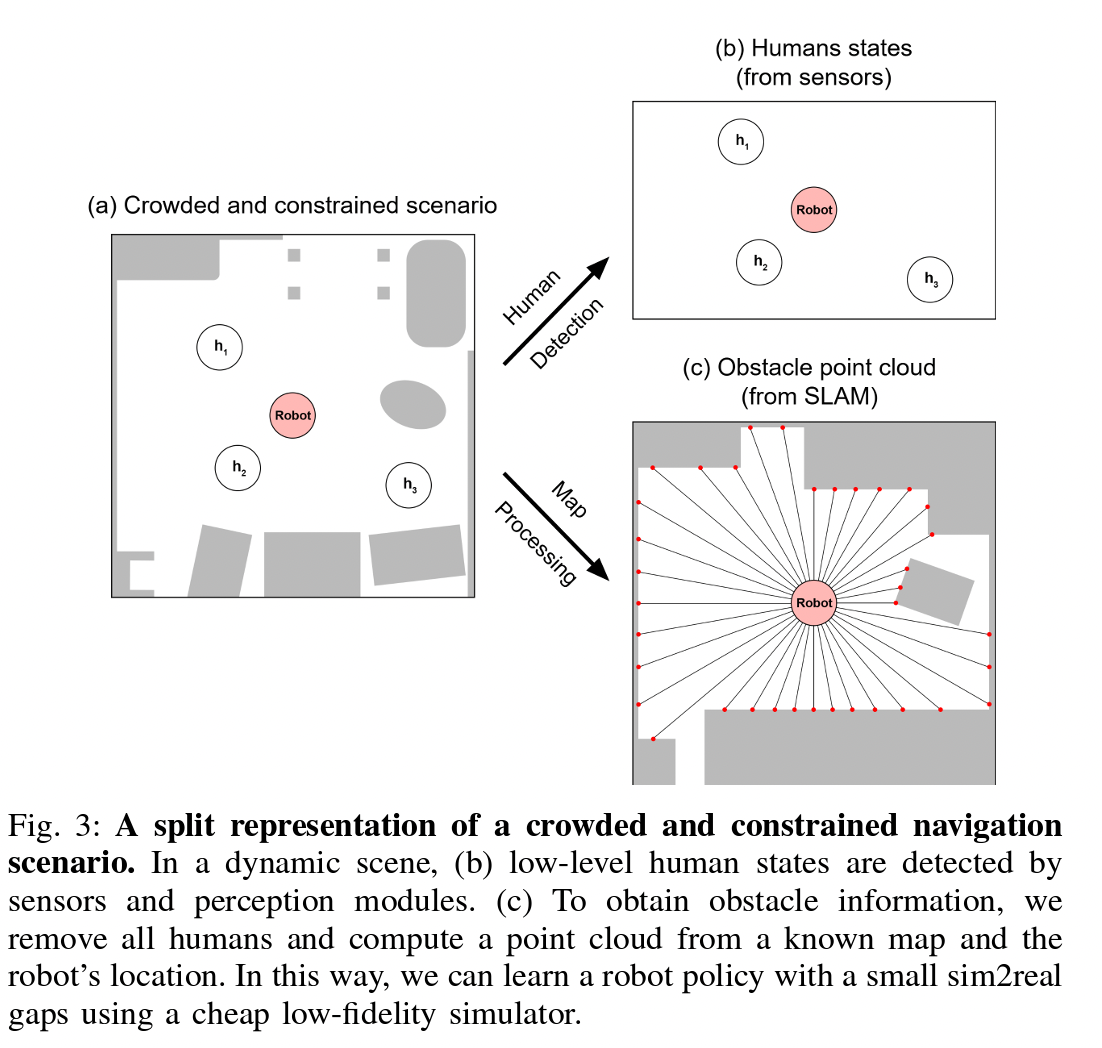

图3:拥挤且受限的导航场景的分割表示。在动态场景中,(b) 低级人类状态通过传感器和感知模块进行检测。© 为了获取障碍物信息,我们移除所有人类,并根据已知地图和机器人的位置计算点云。通过这种方式,我们可以使用廉价的低保真度模拟器学习机器人策略,从而减少sim2real差距。
2.3 奖励函数
我们的奖励函数由三个部分组成。函数的第一部分也是主要部分,奖励机器人达到目标,同时对机器人与人类或障碍物发生碰撞或过于接近进行惩罚。此外,我们添加了基于潜力的奖励,以引导机器人接近目标:
r main ( s t , a t ) = { 20 , if d goal t ≤ ρ robot − 20 , else if d min t ≤ 0 d min t − 0.25 , else if 0 < d min t < 0.25 4 ( d goal t − 1 − d goal t ) otherwise , r_{\text{main}}(s^t, a^t) = \begin{cases} 20, & \text{if } d^t_\text{ goal} \leq \rho_{\text{robot}} \\ -20, & \text{else if } d^t_\text{ min} \leq 0 \\ d^t_\text{min}-0.25 , & \text{else if } 0 < d^t_\text{ min} < 0.25 \\ 4(d^{t-1}_\text{ goal} - d^t_\text{ goal}) & \text{otherwise}, \end{cases} rmain(st,at)=⎩ ⎨ ⎧20,−20,dmint−0.25,4(d goalt−1−d goalt)if d goalt≤ρrobotelse if d mint≤0else if 0<d mint<0.25otherwise,
其中, ρ robot \rho_{\text{robot}} ρrobot 是机器人的半径, d goal t d^t_\text{ goal} d goalt 是机器人在时间 t t t 与其目标之间的 L2 距离,而 d t min d_{t \text{ min}} dt min 是机器人在时间 t t t 与任何人类或障碍物之间的最小距离。第二部分是旋转惩罚 r spin r_{\text{spin}} rspin,用于惩罚高旋转速度:
r spin ( s t , a t ) = − 0.05 ∥ ω t ∥ 2 2 r_{\text{spin}}(s^t, a^t) = -0.05 \|\omega^t\|^2_2 rspin(st,at)=−0.05∥ωt∥22
其中, ω t \omega_t ωt 是机器人的当前旋转速度。最后,我们在每个时间步添加另一个小的常量惩罚 r time = − 0.025 r_{\text{time}} = -0.025 rtime=−0.025,以鼓励机器人尽快完成任务。总之,我们的马尔可夫决策过程(MDP)的奖励函数是上述三部分的总和:
r ( s t , a t ) = r main ( s t , a t ) + r spin ( s t , a t ) + r time r(s^t, a^t) = r_{\text{main}}(s^t, a^t) + r_{\text{spin}}(s^t, a^t) + r_{\text{time}} r(st,at)=rmain(st,at)+rspin(st,at)+rtime
直观上,当机器人以较高的速度和较短平滑的路径接近目标,同时保持与动态和静态障碍物的安全距离时,将获得较高的奖励。
3. 异构时空图
代理和实体之间微妙而高度动态的互动是使人群导航变得困难的重要因素。为了以结构化的方式建模这些互动,我们将导航场景表述为一个异构时空图(stgraph)。在图4a中,在每个时间步 t t t,我们的异构时空图 G t = ( V t , E t ) G^t = (V^t, E^t) Gt=(Vt,Et) 由一组节点 V t V^t Vt 和一组边 E t E^t Et 组成。节点包括检测到的人类 h 1 t , … , h n t h^t_1, \ldots, h^t_n h1t,…,hnt 和机器人 w t w^t wt。此外,一个障碍节点 o t o^t ot 表示所有障碍物的点云整体。在每个时间步 t t t,连接不同节点的空间边表示节点之间的空间互动。不同的空间互动对机器人的决策有不同的影响。具体而言,由于我们可以控制机器人而无法控制人类,RH(机器人与人类)互动对机器人行为有直接影响,而HH(人类与人类)互动则对机器人行为产生间接影响。作为间接影响的一个例子,如果人类A强迫人类B朝机器人的前方转身,机器人必须因A与B之间的互动而做出反应。此外,由于代理是动态的而障碍物是静态的,代理之间的互动是相互的,而静态障碍物对代理的影响是单向的。因此,我们将空间边分为三种类型:HH边(图4中的蓝色)、障碍-代理(OA)边(橙色)和RH边(红色)。这三种类型的边使我们能够将空间互动分解为HH、OA和RH函数。每个函数由一个具有可学习参数的神经网络进行参数化。与之前忽略某些边的研究相比[3]、[8]、[9],我们的方法允许机器人推理在受限和拥挤环境中存在的所有观察到的空间互动。
由于所有代理的运动会动态改变每个人类的可见性,节点集 V t V^t Vt 和边集 E t E^t Et 以及互动函数的参数可能会相应变化。为此,我们使用另一个函数(在图4(a)中的紫色框表示)整合不同时间步的图 G t G^t Gt 的时间相关性。该时间函数连接相邻时间步的图,从而克服反应性策略的短视性,并使机器人能够进行长期决策。为了减少参数数量,图4(a)中相同类型的边共享相同的函数参数。这种参数共享对于我们图的可扩展性至关重要,因为当人类数量变化时,参数数量保持不变[55]。
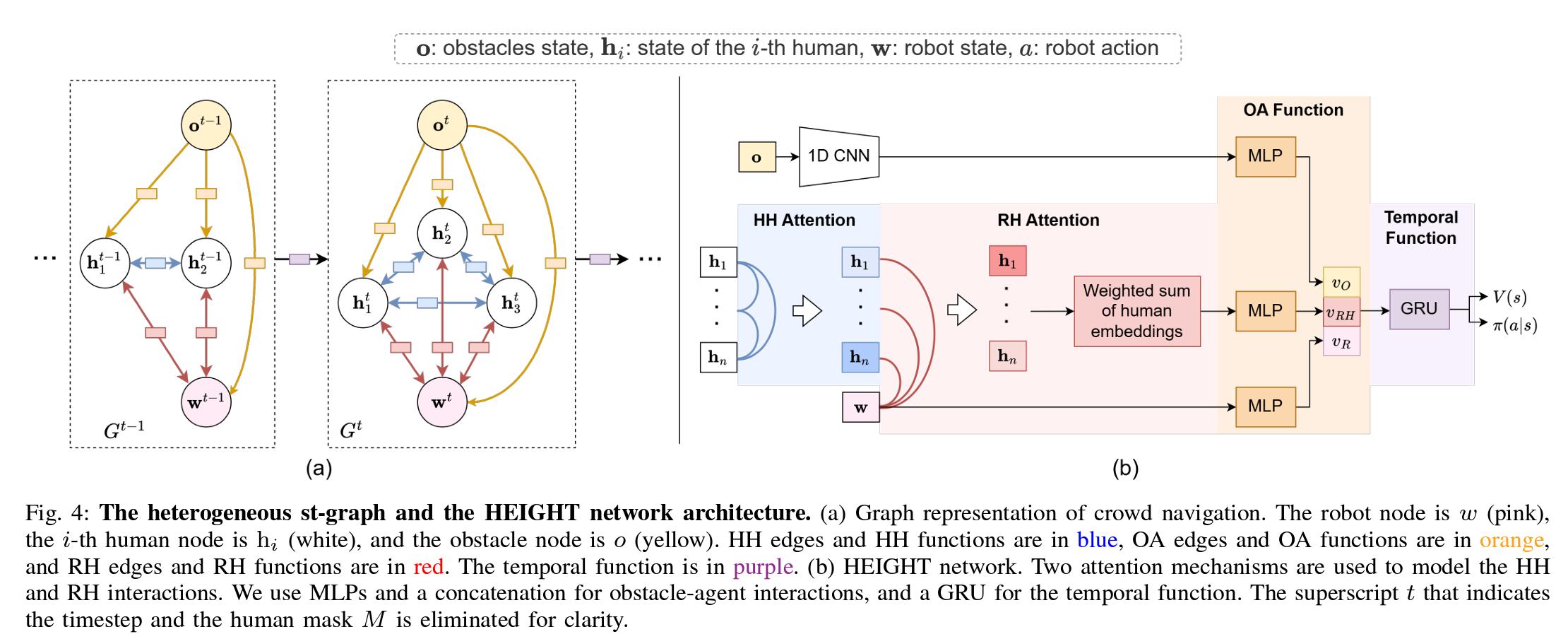
图4:异构时空图及HEIGHT网络架构。 (a) 人群导航的图表示。机器人节点为 w w w(粉色),第 i i i 个人类节点为 h i h_i hi(白色),障碍节点为 o o o(黄色)。HH边和HH函数用蓝色表示,OA边和OA函数用橙色表示,RH边和RH函数用红色表示。时间函数用紫色表示。 (b) HEIGHT网络。使用两种注意力机制来建模HH和RH互动。我们对障碍-代理互动使用多层感知机(MLPs)和拼接,对时间函数使用门控循环单元(GRU)。为清晰起见,表示时间步的上标 t t t 和人类掩码 M M M 被省略。
4. HEIGHT架构
在图4b中,我们从异构时空图推导出我们的网络架构。我们将HH和RH函数表示为具有注意力机制的前馈网络,分别称为 H H a t t n HH_{attn} HHattn和 R H a t t n RH_{attn} RHattn。我们将OA函数表示为一个带拼接的多层感知机(MLP),而时间函数则表示为一个门控循环单元(GRU)。我们用 W W W和 f f f来表示可训练的权重和全连接层。
4.1 代理之间的注意力
注意力模块为所有连接到机器人或人类节点的边分配权重,使得节点能够关注重要的边或互动。这两个注意力网络类似于带有填充掩码的缩放点积注意力[43],它通过查询 Q Q Q和键 K K K计算注意力分数,并将归一化的分数应用于值 V V V,从而得到加权值 v v v。
v : = A t t n ( Q , K , V , M ) = s o f t m a x ( Q K ⊤ + M d ) V (4) v := Attn(Q,K,V,M) = softmax \left( \frac{QK^{\top} + M}{\sqrt{d}} \right) V \tag{4} v:=Attn(Q,K,V,M)=softmax(dQK⊤+M)V(4)
其中, d d d是查询和键的维度,作为缩放因子。掩码 M M M用于处理每个时间步检测到的人数变化,下面将详细展开。
4.1.1 人类-人类注意力
为了学习每个HH边对机器人在时间 t t t的决策的重要性,我们首先使用HH注意力网络对每个观察到的人类相对于其他人类进行加权,这是一种人类之间的自注意力。在HH注意力中,当前人类的状态 h 1 t , … , h n t h^t_1, \ldots, h^t_n h1t,…,hnt被重新拼接并通过带有权重 W H H Q W^{Q}_{HH} WHHQ、 W H H K W^{K}_{HH} WHHK和 W H H V W^{V}_{HH} WHHV的线性层传递,以获得 Q H H t , K H H t , V H H t ∈ R n × d H H Q^{t}_{HH}, K^{t}_{HH}, V^{t}_{HH} \in \mathbb{R}^{n \times d_{HH}} QHHt,KHHt,VHHt∈Rn×dHH,其中 d H H d_{HH} dHH是HH注意力的注意力大小。
为了学习每个HH边对机器人在时间 t t t的决策的重要性,我们首先使用HH注意力网络对每个观察到的人类相对于其他人类进行加权,这是一种人类之间的自注意力。在HH注意力中,当前人类的状态 h 1 t , … , h n t h^t_1, \ldots, h^t_n h1t,…,hnt被重新拼接并通过带有权重 W H H Q W^{Q}_{HH} WHHQ、 W H H K W^{K}_{HH} WHHK和 W H H V W^{V}_{HH} WHHV的线性层传递,以获得 Q H H t , K H H t , V H H t ∈ R n × d H H Q^{t}_{HH}, K^{t}_{HH}, V^{t}_{HH} \in \mathbb{R}^{n \times d_{HH}} QHHt,KHHt,VHHt∈Rn×dHH,其中 d H H d_{HH} dHH是HH注意力的注意力大小。
Q H H t = [ h 1 t , … , h n t ] ⊤ W H H Q = [ q 1 , … , q n ] ⊤ Q^{t}_{HH} = [h^t_1, \ldots, h^t_n]^{\top} W^{Q}_{HH} = [q_1, \ldots, q_n]^{\top} QHHt=[h1t,…,hnt]⊤WHHQ=[q1,…,qn]⊤
K H H t = [ h 1 t , … , h n t ] ⊤ W H H K = [ k 1 , … , k n ] ⊤ K^{t}_{HH} = [h^t_1, \ldots, h^t_n]^{\top} W^{K}_{HH} = [k_1, \ldots, k_n]^{\top} KHHt=[h1t,…,hnt]⊤WHHK=[k1,…,kn]⊤
V H H t = [ h 1 t , … , h n t ] ⊤ W H H V = [ v 1 , … , v n ] ⊤ (5) V^{t}_{HH} = [h^t_1, \ldots, h^t_n]^{\top} W^{V}_{HH} = [v_1, \ldots, v_n]^{\top} \tag{5} VHHt=[h1t,…,hnt]⊤WHHV=[v1,…,vn]⊤(5)
其中 q i ∈ R 1 × d H H q_i \in \mathbb{R}^{1 \times d_{HH}} qi∈R1×dHH、 k i ∈ R 1 × d H H k_i \in \mathbb{R}^{1 \times d_{HH}} ki∈R1×dHH和 v i ∈ R 1 × d H H v_i \in \mathbb{R}^{1 \times d_{HH}} vi∈R1×dHH分别是第 i i i个人类的查询嵌入、键嵌入和值嵌入。此外,按照公式4,一个掩码 M t ∈ R n × n M^t \in \mathbb{R}^{n \times n} Mt∈Rn×n表示在当前时间 t t t每个人类对机器人的可见性,并通过机器人的感知系统获得。假设第 n n n个人类在时间 t t t不可见,则 M t M^t Mt是一个填充为零的矩阵,除了第 n n n列的每个条目为 − ∞ -\infty −∞。公式4的分子可以表示为:
Q H H t ⋅ ( K H H t ) T + M t = [ q 1 k 1 ⋯ q 1 k n − 1 q 1 k n ⋮ ⋱ ⋮ ⋮ q n k 1 ⋯ q n k n − 1 q n k n ] + [ 0 ⋯ 0 − ∞ ⋮ ⋱ ⋮ ⋮ 0 ⋯ 0 − ∞ ] = [ q 1 k 1 ⋯ q 1 k n − 1 − ∞ ⋮ ⋱ ⋮ − ∞ q n k 1 ⋯ q n k n − 1 − ∞ ] (6) Q^{t}_{HH} \cdot (K^{t}_{HH})^T + M^t = \begin{bmatrix}q_1 k_1 & \cdots & q_1 k_{n-1} & q_1 k_n \\\vdots & \ddots & \vdots & \vdots \\q_n k_1 & \cdots & q_n k_{n-1} & q_n k_n\end{bmatrix} + \begin{bmatrix} 0 & \cdots & 0 & -\infty \\\vdots & \ddots & \vdots & \vdots \\0 & \cdots & 0 & -\infty\end{bmatrix} = \begin{bmatrix} q_1 k_1 & \cdots & q_1 k_{n-1} & -\infty \\\vdots & \ddots & \vdots & -\infty \\q_n k_1 & \cdots & q_n k_{n-1} & -\infty\end{bmatrix} \tag{6} QHHt⋅(KHHt)T+Mt= q1k1⋮qnk1⋯⋱⋯q1kn−1⋮qnkn−1q1kn⋮qnkn + 0⋮0⋯⋱⋯0⋮0−∞⋮−∞ = q1k1⋮qnk1⋯⋱⋯q1kn−1⋮qnkn−1−∞−∞−∞ (6)
设 V H H t = [ v 1 , … , v n ] ⊤ V^{t}_{HH} = [v_1, \ldots, v_n]^{\top} VHHt=[v1,…,vn]⊤,其中 v i ∈ R 1 × d H H v_i \in \mathbb{R}^{1 \times d_{HH}} vi∈R1×dHH是第 i i i个人类的值嵌入。根据公式4,加权的人类嵌入$ v^{t}{HH} \in \mathbb{R}^{n \times d{HH}}$可以表示为:
v H H t = softmax ( Q H H t ( K H H t ) ⊤ + M t ) d ⋅ V H H t = [ c 1 q 1 k 1 ⋯ c 1 q 1 k n − 1 0 ⋮ ⋮ c n q n k 1 ⋯ c n q n k n − 1 0 ] ⋅ [ v 1 ⋮ v n − 1 v n ] = [ c 1 q 1 k 1 v 1 + ⋯ + c 1 q 1 k n − 1 v n − 1 ⋮ c n q n k 1 v 1 + ⋯ + c n q n k n − 1 v n − 1 ] v^{t}_{HH} = \text{softmax}\frac{\left(Q^{t}_{HH}(K^{t}_{HH})^{\top} + M_t\right)}{\sqrt{d}} \cdot V^{t}_{HH} = \begin{bmatrix} c_1 q_1 k_1 \cdots c_1 q_1 k_{n-1} & 0 \\\vdots & \vdots \\c_n q_n k_1 \cdots c_n q_n k_{n-1} & 0\end{bmatrix} \cdot \begin{bmatrix}v_1 \\\vdots \\v_{n-1} \\v_n\end{bmatrix} = \begin{bmatrix}c_1 q_1 k_1 v_1 + \cdots + c_1 q_1 k_{n-1} v_{n-1} \\\vdots \\c_n q_n k_1 v_1 + \cdots + c_n q_n k_{n-1} v_{n-1}\end{bmatrix} vHHt=softmaxd(QHHt(KHHt)⊤+Mt)⋅VHHt= c1q1k1⋯c1q1kn−1⋮cnqnk1⋯cnqnkn−10⋮0 ⋅ v1⋮vn−1vn = c1q1k1v1+⋯+c1q1kn−1vn−1⋮cnqnk1v1+⋯+cnqnkn−1vn−1
其中 c 1 , … , c n c_1, \ldots, c_n c1,…,cn是反映缩放因子 d d d和softmax函数影响的常数。因此,第 n n n个缺失人类 v n v_n vn的值被掩码 M t M_t Mt消除,从而不影响结果的加权人类嵌入 v H H t v^{t}_{HH} vHHt。该掩码指示每个人类的可见性,防止对未检测到的人类的关注,这在由于机器人传感器范围有限、遮挡、不完美的人类检测器等原因导致的部分可观测性下的拥挤导航中是常见的[31]。此外,掩码为网络提供了无偏的梯度,从而稳定并加速训练[9],[56]。
4.1.2 机器人-人类注意力
在通过HH注意力对人类进行加权后,我们再次使用另一个RH注意力网络根据机器人对其嵌入进行加权,以学习每个RH边的相对重要性。在RH注意力中,我们首先通过一个全连接层对机器人状态 w t w_t wt进行嵌入,得到RH注意力的键 K R H t ∈ R 1 × d R H K^{t}_{RH} \in \mathbb{R}^{1 \times d_{RH}} KRHt∈R1×dRH。查询和值 Q R H t , V R H t ∈ R n × d R H Q^{t}_{RH}, V^{t}_{RH} \in \mathbb{R}^{n \times d_{RH}} QRHt,VRHt∈Rn×dRH是来自HH注意力的加权人类特征的另外两个线性嵌入:
Q R H t = v H H t W R H Q , K R H t = w t W R H K , V R H t = v H H t W R H V Q^{t}_{RH} = v^{t}_{HH} W^{Q}_{RH}, \quad K^{t}_{RH} = w^t W^{K}_{RH}, \quad V^{t}_{RH} = v^{t}_{HH} W^{V}_{RH} QRHt=vHHtWRHQ,KRHt=wtWRHK,VRHt=vHHtWRHV
我们从 Q R H t , K R H t , V R H t Q^{t}_{RH}, K^{t}_{RH}, V^{t}_{RH} QRHt,KRHt,VRHt和掩码 M t M_t Mt计算注意力得分,以获得第二次加权的人类特征 v R H t ∈ R 1 × d R H v^{t}_{RH} \in \mathbb{R}^{1 \times d_{RH}} vRHt∈R1×dRH,如公式4所示。
4.2 融合障碍物和时间信息
我们首先将表示障碍物的点云 o t o_t ot输入到一个1D-CNN中,随后通过一个全连接层得到障碍物嵌入 v O t v^{t}_{O} vOt。然后,我们通过线性层 f R f_R fR对机器人状态 w t w_t wt进行嵌入,以获得机器人嵌入 v R t v^{t}_{R} vRt。
v O t = f C N N ( o t ) , v R t = f R ( w t ) v^{t}_{O} = f_{CNN}(o_t), \quad v^{t}_{R} = f_{R}(w_t) vOt=fCNN(ot),vRt=fR(wt)
最后,机器人和障碍物嵌入与两次加权的人类特征 v R H t v^{t}_{RH} vRHt连接,并输入到GRU中:
h t = GRU ( h t − 1 , [ v R H t , v R t , v O t ] ) h^t = \text{GRU}(h^{t-1}, [v^{t}_{RH}, v^{t}_{R}, v^{t}_{O}]) ht=GRU(ht−1,[vRHt,vRt,vOt])
其中 h t h_t ht是时间 t t t的GRU隐藏状态。最后, h t h^t ht被输入到一个全连接层,以获得值 V ( s t ) V(s^t) V(st)和策略 π ( a t ∣ s t ) \pi(a^t|s^t) π(at∣st)。
5. 训练
我们在模拟器中使用近端策略优化(PPO)[57]训练整个网络,如图2(a)所示(有关模拟器的详细信息,请参见第V-A节)。在每个时间步 t t t,模拟器提供构成状态 s t s^t st的所有状态信息,这些信息被输入到HEIGHT网络中。网络输出状态的估计值 V ( s t ) V(s^t) V(st)和机器人动作的对数概率 π ( a t ∣ s t ) \pi(a^t|s^t) π(at∣st),这两者都用于计算PPO损失,并随后更新网络中的参数。在训练过程中,机器人动作是从动作分布 π ( a t ∣ s t ) \pi(a^t|s^t) π(at∣st)中采样的。在测试过程中,机器人选择概率最高的动作 a t a^t at。机器人动作 a t a^t at被输入到模拟器中以计算下一个状态 s t + 1 s^{t+1} st+1,然后循环继续进行。我们的算法不依赖于专家演示的性能[3],[4],[50],因此没有任何监督学习的限制。然而,为了提高低训练数据效率这一强化学习的固有问题,HEIGHT也可以通过模仿学习与强化学习的结合进行训练。
6. 总结
我们提出了一种结构化且有原则的方法,以设计用于受限环境中人群导航的机器人策略网络。通过将复杂场景分解为独立组件,我们将复杂问题拆分为更小的函数,这些函数用于学习相应函数的参数。通过结合上述所有组件,端到端可训练的HEIGHT使机器人能够对所有成对交互进行空间和时间推理,从而实现更好的导航性能。