该论文由TransT改进而来,在CVPR的基础上进行扩展发表在了2023TPAMI中,具体有关TransT可以参考这篇博客:2021CVPR-TransT:基于Transformer 的视觉跟踪-CSDN博客
在TransT的基础上进行改进。首先,作者为TransT设计了一个分割分支,通过统一的框架完成边界框预测和实例分割。其次,作者用多模板方案和IoU预测设计进一步扩展了TransT。多模板方案记录目标的时间信息和外观变化。IoU预测头控制模板更新。
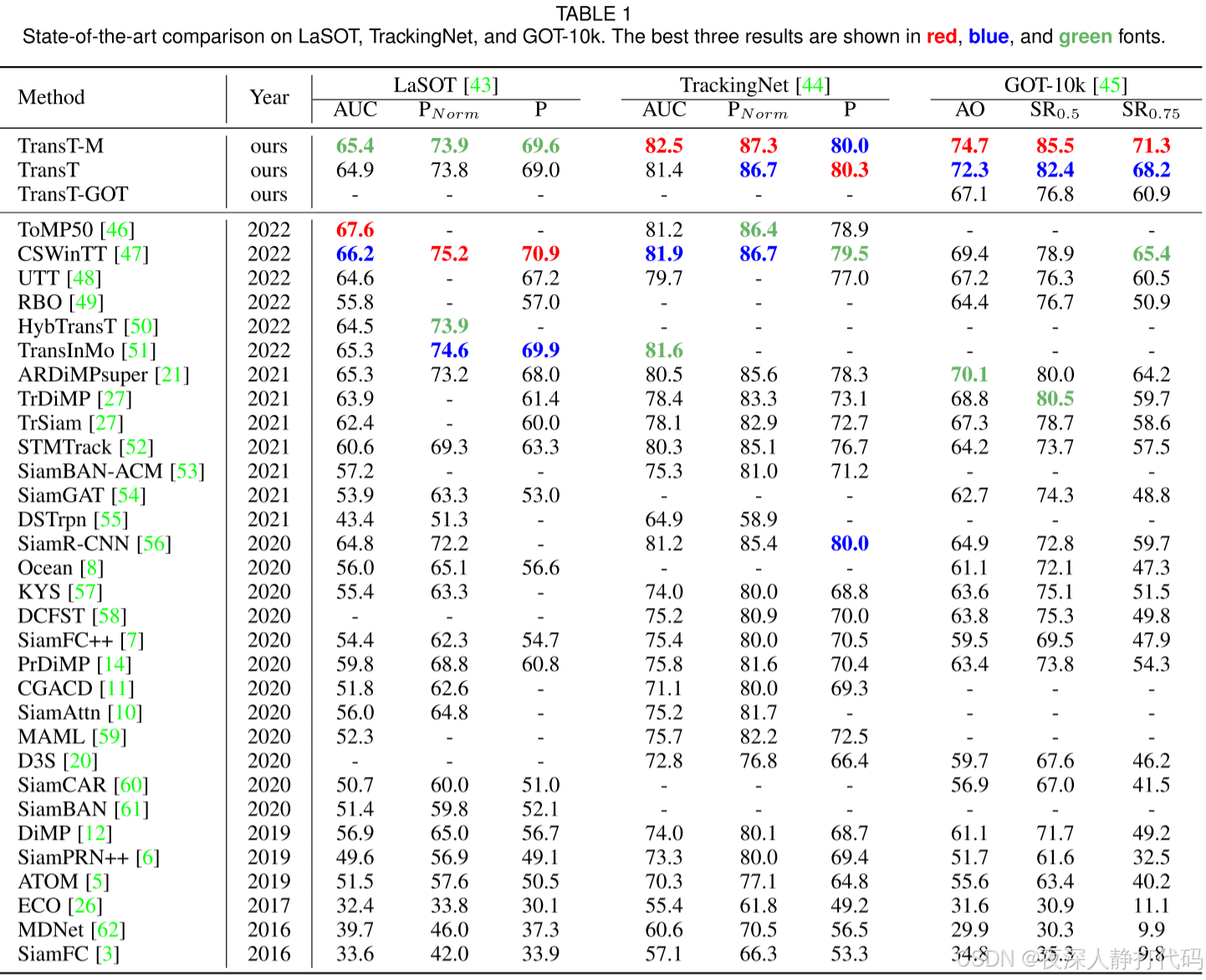
整体架构图如下:
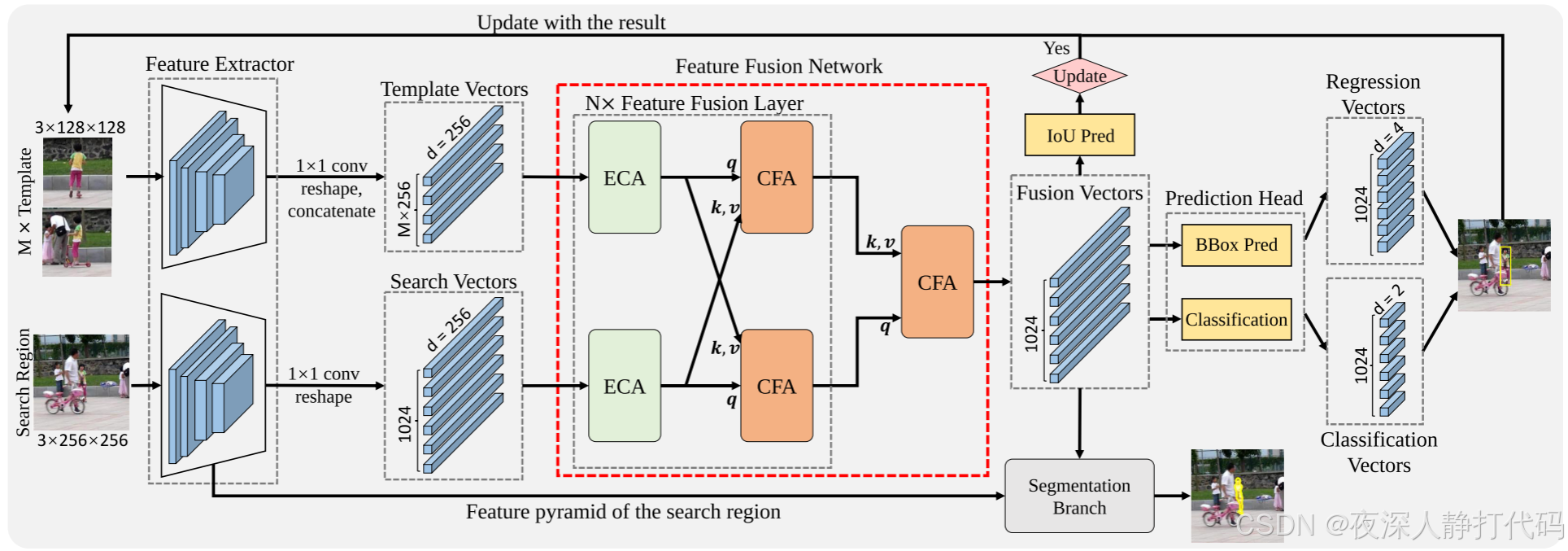
Segmentation Branch
图7显示了分割分支的详细架构。模板向量(template vectors)是TransT中模板分支最后一个特征融合层的输出特征向量。融合向量(fusion vectors)是TransT中特征融合网络的输出特征向量。对于模板向量,我们获得模板向量中间位置对应的特征向量(如图7中的中心向量),并使用额外的多头注意力来计算中心向量与融合向量的注意力图。我们采用八头注意力得到一个尺寸为32 × 32 × 8的注意力图。对于融合向量,我们获得由分类头预测的置信度最高的向量,并使用另一个多头注意力计算从它到融合向量的注意力图。然后,我们得到另一个形状为32 × 32 × 8的注意力图。之后,将融合向量在空间维度上重塑为32 × 32 × 256,并将其与两个注意图连接起来得到32 × 32 × 272的特征图。使用FPN将连接的特征与搜索区域的低级特征金字塔(从骨干网络的第1阶段到第4阶段)融合。FPN输出特征的形状为128 × 128 × 8。最后,利用掩码预测头对形状为256 × 256 × 1的分割掩码进行预测。掩模预测头是由一个3 × 3卷积层和双线性插值组成的。
图7所示,分割分支的架构。我们将融合特征与两个注意图进行连接,利用FPN网络将连接特征与底层骨干特征进行融合,并利用掩码预测头对掩码进行预测。掩模预测头是3×3卷积,然后是双线性插值。
TransT-M
我们使用多模板方案和IoU预测头扩展了TransT,以生成一个名为TransT- m的更强大的跟踪器。多模板方案记录目标的不同外观,使跟踪器对外观变化具有更强的鲁棒的。IoU预测头通过比较预测的IoU与更新阈值来控制模板的更新。
Multi-template Scheme
在跟踪过程中,有时目标的外观会发生很大的变化。仅依靠第一帧模板查找目标,特别是在有干扰物的情况下,对跟踪器来说是困难的。因此,我们使用多个模板来记录目标的外观变化。具体来说,我们在线跟踪记录了M个模板。对于M个模板,始终保持初始模板不变,因为它是精确和可靠的。对于其余的M−1个模板,使用跟踪期间收集的模板更新它们;这些模板不像初始模板那样精确。我们使用主干从这些模板中提取特征,然后将其重塑为二维特征,在空间维度上进行拼接,并将拼接后的特征输入到特征融合网络的模板分支中。
我们默认使用M = 2。在我们的设计中,没有对初始模板和更新模板进行不同的设计,而是平等地对待它们。这可能不是追求更高性能的最佳选择。根据经验,为不同的模板设计不同的分支可能会得到更好的结果。然而,我们发现将模板视为平等的简单方法效果也很好。为了保持框架的简洁,我们没有为不同的模板使用额外的设计。这种选择带来了额外的优势,因为模型可以将不同数量的模板作为输入,而无需重新设计或重新训练,从而使其在应用中具有灵活性。
用户可以自由选择单模板设置以获得更快的速度或多模板设置以获得更好的性能,而无需重新训练。这一特点也是由于以下原因。首先,注意力可以接收不同数量的特征向量作为输入。注意层的结果由softmax加权平均计算得到。例如,输入一个模板的结果与输入该模板的多个副本的结果相同。其次,我们使用拼接的方法来组合多个模板的特征。在拼接方法中,不同的特征向量是独立的,从而保证了注意层在训练中看到独立的初始模板特征向量和更新模板特征向量。因此,该模型学会了如何处理这两种类型的特征向量。在测试中,即使模板数量不同,每个模板特征向量也不超过这两种类型中的一种。
IoU Prediction Head
跟踪器需要一个指示器来控制模板的更新。然而置信度分数并不是一个很好的指标,因为它代表的是目标在每个特征向量上存在的可能性,而不是该特征向量预测的边界框是否适合作为模板。因此,我们设计了一个IoU预测头,以确定预测是否适合作为模板。IoU预测头很简单。我们将通道维度中的回归向量和融合向量拼接起来,并使用三层感知器来预测每个向量上的IoU。然后,我们将预测的IoU与更新阈值进行比较,以控制模板的更新。
IoU prediction loss
IoU预测头输出Hx ×Wx个IoU值。将每个正样本与相应的真实边界框计算得到的IoU作为IoU真实值。IoU预测头使用MSE损失,因为只需要IoU预测来判断边界框的质量,而不需要判断正样本和负样本,所以只有正样本才会造成这种损失。
Segmentation prediction loss
对于分割分支,使用dice loss和focal loss。其中m为预测掩码mask,mˆ为真实值。λD = 1和λf = 1是实验中的正则化参数。
![]()
Experiment
training
对于TransT-M,我们将训练过程分为两个阶段。首先,我们训练多模板TransT基线。我们使用m = 2,即默认情况下有两个模板。对于视频数据集,我们对一个视频序列中的M + 1帧进行采样,形成一个样本对。
为了模拟在线跟踪过程,我们选择头帧或尾帧来生成搜索区域,使用距离搜索区域帧最远的帧生成初始模板补丁,使用中间帧生成更新模板补丁。对于COCO检测数据集,我们应用变换来生成图像对。随机选择一幅图像生成搜索区域补丁,另一幅图像生成初始模板补丁,其余图像生成更新模板补丁。对于搜索区域补丁和更新后的模板,我们在获取补丁时对目标框的位置和形状进行抖动和变换,模拟模板更新在跟踪过程中的不准确性。对于初始模板不应用抖动或变换,因为在线跟踪中给出的初始目标边界框一般是准确的。其他训练设置与TransT中的设置相同。对于第二阶段,冻结多模板TransT基线的参数并训练IoU预测头。对于IoU预测头,使用与TransT基线相同的训练数据集。
我们采用学习率为1e-3,权值衰减为1e-4的AdamW。在两个NVIDIA Titan RTX gpu上训练IoU预测头,批处理大小为256,90个epoch,每个epoch 迭代200次。每30个epoch 后,学习率降低10倍。我们没有将IoU预测头与TransT基线一起训练,因为我们希望IoU预测头的真实值与最终网络的边界框预测一致,并且在训练的初始阶段不受不良边界框预测的影响。对于分割分支,我们使用YouTube-VOS和一些显著性数据集作为Alpha-Refine进行训练。训练策略与IoU预测头相同,只是初始学习率设置为1e-2。我们没有使用TransT基线一起训练分割分支,因为分割数据集相对较小,容易被庞大的跟踪数据集覆盖。
对于TransT,我们总是使用第一帧的初始目标的边界框作为模板,而不更新它。对于TransT-M,我们默认使用两个模板,并且始终保留初始模板并更新其他模板。模板的更新由预测的IoU控制。如果预测的IoU高于更新阈值,则更新模板。
Postprocessing
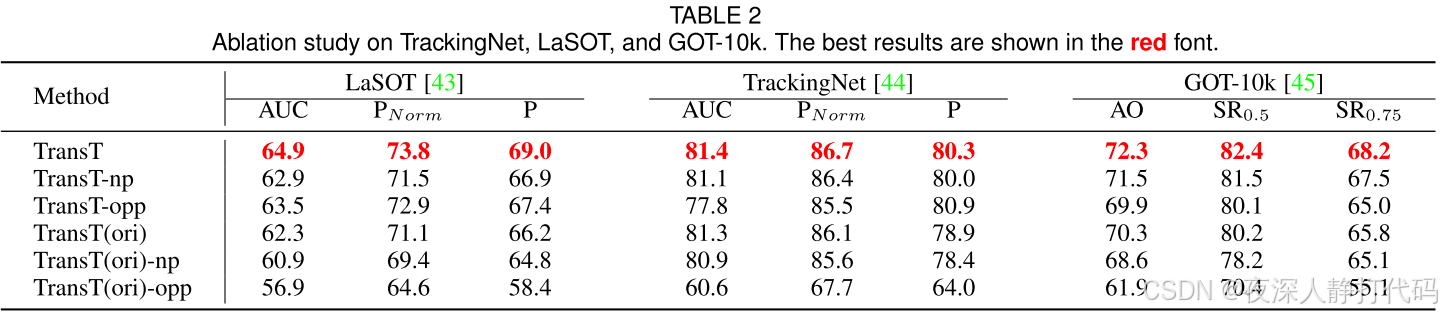
在之前的SiamRPN、SiamRPN++和Ocean等作品中,通过余弦窗惩罚、尺度变化惩罚和边界框平滑等后处理方案选择最终的跟踪结果。然而,这些后处理方案是参数敏感的,因为三个超参数需要为不同的测试集仔细调整。为了避免这个问题,在本工作中,我们只采用窗口惩罚对所有测试集使用默认参数进行后处理。为了显示后处理的效果,我们在表2中比较了有后处理步骤和没有后处理步骤的TransT变量。TransT表示跟踪器,TransT-np是不经过后处理的跟踪器。首先,从表2中我们可以得出结论,没有后处理的TransT仍然达到了最先进的性能,这归功于类transformer的融合方法。
Evaluation on TrackingNet, LaSOT and GOT-10k Datasets