一、引言
KAN神经网络(Kolmogorov–Arnold Networks)是一种基于Kolmogorov-Arnold表示定理的新型神经网络架构。该定理指出,任何多元连续函数都可以表示为有限个单变量函数的组合。与传统多层感知机(MLP)不同,KAN通过可学习的激活函数和结构化网络设计,在函数逼近效率和可解释性上展现出潜力。

二、技术与原理简介
1.Kolmogorov-Arnold 表示定理
Kolmogorov-Arnold 表示定理指出,如果 是有界域上的多元连续函数,那么它可以写为单个变量的连续函数的有限组合,以及加法的二进制运算。更具体地说,对于 光滑
其中 和 。从某种意义上说,他们表明唯一真正的多元函数是加法,因为所有其他函数都可以使用单变量函数和 sum 来编写。然而,这个 2 层宽度 - Kolmogorov-Arnold 表示可能不是平滑的由于其表达能力有限。我们通过以下方式增强它的表达能力将其推广到任意深度和宽度。,
2.Kolmogorov-Arnold 网络 (KAN)
Kolmogorov-Arnold 表示可以写成矩阵形式
其中
我们注意到 和 都是以下函数矩阵(包含输入和输出)的特例,我们称之为 Kolmogorov-Arnold 层:

其中。
定义层后,我们可以构造一个 Kolmogorov-Arnold 网络只需堆叠层!假设我们有层,层的形状为 。那么整个网络是
相反,多层感知器由线性层和非线错:
KAN 可以很容易地可视化。(1) KAN 只是 KAN 层的堆栈。(2) 每个 KAN 层都可以可视化为一个全连接层,每个边缘上都有一个1D 函数。
三、代码详解
在此示例中,我们将介绍如何利用网格细化来最大化KANs在函数拟合方面的能力
1. 初始化模型并创建数据集
from kan import *
# initialize KAN with G=3
model = KAN(width=[2,1,1], grid=3, k=3)
# create dataset
f = lambda x: torch.exp(torch.sin(torch.pi*x[:,[0]]) + x[:,[1]]**2)
dataset = create_dataset(f, n_var=2)2. 训练 KAN(网格=3)
model.train(dataset, opt="LBFGS", steps=20);3. 精分 KAN!
# initialize a more fine-grained KAN with G=10
model2 = KAN(width=[2,1,1], grid=10, k=3)
# initialize model2 from model
model2.initialize_from_another_model(model, dataset['train_input']);4. 训练 KAN(网格=10)
model2.train(dataset, opt="LBFGS", steps=20);5. 逐步细化网格
grids = np.array([5,10,20,50,100])
train_losses = []
test_losses = []
steps = 50
k = 3
for i in range(grids.shape[0]):
if i == 0:
model = KAN(width=[2,1,1], grid=grids[i], k=k)
if i != 0:
model = KAN(width=[2,1,1], grid=grids[i], k=k).initialize_from_another_model(model, dataset['train_input'])
results = model.train(dataset, opt="LBFGS", steps=steps, stop_grid_update_step=30)
train_losses += results['train_loss']
test_losses += results['test_loss']
6. 损失的训练动力学显示阶梯结构(网格细化后损失突然下降)
plt.plot(train_losses)
plt.plot(test_losses)
plt.legend(['train', 'test'])
plt.ylabel('RMSE')
plt.xlabel('step')
plt.yscale('log')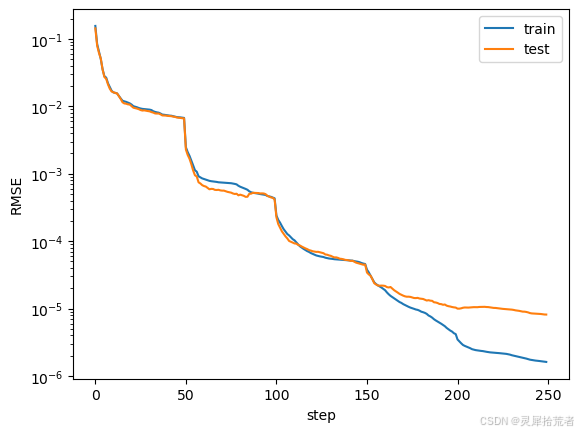
7. 神经缩放定律
n_params = 3 * grids
train_vs_G = train_losses[(steps-1)::steps]
test_vs_G = test_losses[(steps-1)::steps]
plt.plot(n_params, train_vs_G, marker="o")
plt.plot(n_params, test_vs_G, marker="o")
plt.plot(n_params, 100*n_params**(-4.), ls="--", color="black")
plt.xscale('log')
plt.yscale('log')
plt.legend(['train', 'test', r'$N^{-4}$'])
plt.xlabel('number of params')
plt.ylabel('RMSE')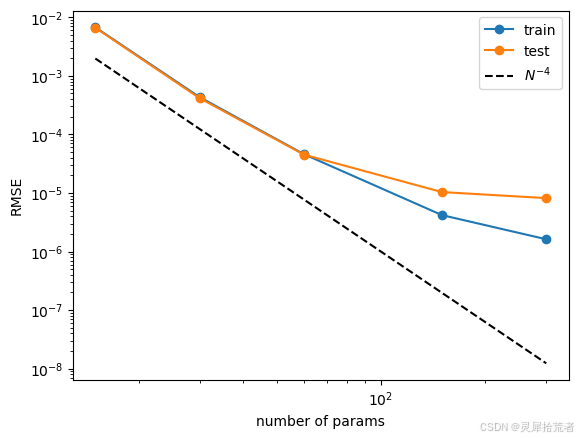
四、总结与思考
KAN神经网络通过融合数学定理与深度学习,为科学计算和可解释AI提供了新思路。尽管在高维应用中仍需突破,但其在低维复杂函数建模上的潜力值得关注。未来可能通过改进计算效率、扩展理论边界,成为MLP的重要补充。
1. KAN网络架构
-
关键设计:可学习的激活函数:每个网络连接的“权重”被替换为单变量函数(如样条、多项式),而非固定激活函数(如ReLU)。分层结构:输入层和隐藏层之间、隐藏层与输出层之间均通过单变量函数连接,形成多层叠加。参数效率:由于理论保证,KAN可能用更少的参数达到与MLP相当或更好的逼近效果。
-
示例结构:输入层 → 隐藏层:每个输入节点通过单变量函数
连接到隐藏节点。隐藏层 → 输出层:隐藏节点通过另一组单变量函数
组合得到输出。
2. 优势与特点
-
高逼近效率:基于数学定理,理论上能以更少参数逼近复杂函数;在低维科学计算任务(如微分方程求解)中表现优异。
-
可解释性:单变量函数可可视化,便于分析输入变量与输出的关系;网络结构直接对应函数分解过程,逻辑清晰。
-
灵活的函数学习:激活函数可自适应调整(如学习平滑或非平滑函数);支持符号公式提取(例如从数据中恢复物理定律)。
3. 挑战与局限
-
计算复杂度:单变量函数的学习(如样条参数化)可能增加训练时间和内存消耗。需要优化高阶连续函数,对硬件和算法提出更高要求。
-
泛化能力:在高维数据(如图像、文本)中的表现尚未充分验证,可能逊色于传统MLP。
-
训练难度:需设计新的优化策略,避免单变量函数的过拟合或欠拟合。
4. 应用场景
-
科学计算:求解微分方程、物理建模、化学模拟等需要高精度函数逼近的任务。
-
可解释性需求领域:医疗诊断、金融风控等需明确输入输出关系的场景。
-
符号回归:从数据中自动发现数学公式(如物理定律)。
5. 与传统MLP的对比

6. 研究进展
-
近期论文:2024年,MIT等团队提出KAN架构(如论文《KAN: Kolmogorov-Arnold Networks》),在低维任务中验证了其高效性和可解释性。
-
开源实现:已有PyTorch等框架的初步实现。
【作者声明】
本文分享的论文内容及观点均来源于《KAN: Kolmogorov-Arnold Networks》原文,旨在介绍和探讨该研究的创新成果和应用价值。作者尊重并遵循学术规范,确保内容的准确性和客观性。如有任何疑问或需要进一步的信息,请参考论文原文或联系相关作者。
【关注我们】
如果您对神经网络、群智能算法及人工智能技术感兴趣,请关注【灵犀拾荒者】,获取更多前沿技术文章、实战案例及技术分享!