前言
在上文 PaddleOCR数字表计识别,环境配置,数据集制作,训练推理全套流程 中,我们介绍了如何训练一个PP-OCRv4模型,在实际使用中,主要应用ocr的需求是文本识别,故本文介绍如何通过tensorrt-cpp推理PP-OCRv4rec,便于工业应用的进一步落地。
一、训练好的模型转换为inference模型
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
转换代码:
python3 tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy Global.save_inference_dir=./inference/en_PP-OCRv3_rec/
-c 后面设置训练算法的yml配置文件,-o 配置可选参数Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。Global.save_inference_dir参数设置转换的模型将保存的地址。
>注意:如果您是在自己的数据集上训练的模型,并且调整了中文字符的字典文件,请注意修改配置文件中的character_dict_path为自定义字典文件。
转换成功后,在目录下有三个文件:
inference/en_PP-OCRv3_rec/
├── inference.pdiparams # 识别inference模型的参数文件
├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
└── inference.pdmodel # 识别inference模型的program文件
可通过下面代码测试转换的模型,如果训练时修改了文本的字典,在使用inference模型预测时,需要通过–rec_char_dict_path指定使用的字典路径。
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 48, 320" --rec_char_dict_path="your text dict path"
二、推理模型转化为onnx
ppocr转换为onnx模型需要包Paddle2ONNX ,Paddle2ONNX 支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式,算子目前稳定支持导出 ONNX Opset 9~18,部分Paddle算子支持更低的ONNX Opset转换。
安装:
python3 -m pip install paddle2onnx
模型转换:
paddle2onnx --model_dir ./inference/ch_PP-OCRv4_rec_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/rec_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
执行完毕后,ONNX 模型会被分别保存在 ./inference/det_onnx/,./inference/rec_onnx/,./inference/cls_onnx/路径下,注意:对于OCR模型,转化过程中必须采用动态shape的形式,否则预测结果可能与直接使用Paddle预测有细微不同,Paddle2ONNX 版本 v1.2.3后已默认支持动态shape。
三、tensorrt-cpp推理:
虽然PaddleOCR提供了TensorRT部署支持, 但是其代码比较复杂, 比较难解耦. 本项目提供了相对简洁的代码, 展示如何使用TensorRT C++ API和ONNX进行PaddleOCR文字识别算法的部署项目地址:
,项目下载好之后,修改CMakeLists.txt中tensort的路径为自己的路径,例如:
cmake_minimum_required(VERSION 3.18)
project(tensorrt_cpp_api)
# Set C++ version and optimization level
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Ofast -DNDEBUG")
# set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS}")
# add_compile_options(-fno-elide-constructors)
# For finding FindTensorRT.cmake
set(CMAKE_MODULE_PATH "${CMAKE_SOURCE_DIR}/cmake" ${
CMAKE_MODULE_PATH})
# TODO: Specify the path to TensorRT root dir
set(TensorRT_DIR "/home/build/下载/TensorRT-8.4.3.1.Linux.x86_64-gnu.cuda-11.6.cudnn8.4/TensorRT-8.4.3.1/")
# We require CUDA, OpenCV, and TensorRT
find_package(TensorRT REQUIRED)
find_package(CUDA REQUIRED)
find_package(OpenCV REQUIRED)
add_library(tensorrt_cpp_api SHARED
src/engine.cpp)
target_include_directories(tensorrt_cpp_api PUBLIC ${
OpenCV_INCLUDE_DIRS} ${
CUDA_INCLUDE_DIRS} ${
TensorRT_INCLUDE_DIRS}
${
TensorRT_DIR}/samples/common)
target_link_libraries(tensorrt_cpp_api PUBLIC ${
OpenCV_LIBS} ${
CUDA_LIBRARIES} ${
CMAKE_THREAD_LIBS_INIT} ${
TensorRT_LIBRARIES})
add_executable(demo src/main.cpp)
target_link_libraries(demo tensorrt_cpp_api)
修改src文件夹下的main.cpp文件,
// TODO: Specify your character_dict here.
std::string label_path = "../data/ppocr_keys_v1.txt";
// TODO: Specify your test image here.
const std::string inputImage = "../data/word_2.png";
// TODO: Specify your model here.
const std::string onnxModelpath = "../data/modelv3.onnx"; // Modify to "../data/modelv2.onnx" when using ppocrv2
将这三个地方修改为自己的路径,分别为训练时候的字符串文件,测试图片,与刚才转换好的onnx文件,修改好之后执行下面步骤。
cd /home/build/下载/PaddleOCR_TensorRT_cpp-main(1)/PaddleOCR_TensorRT_cpp-main
mkdir build
cd build
cmake ..
make
./demo
运行demo的时候会自动生成engine文件,下次运行的时候会自动调用此文件。
最终效果:

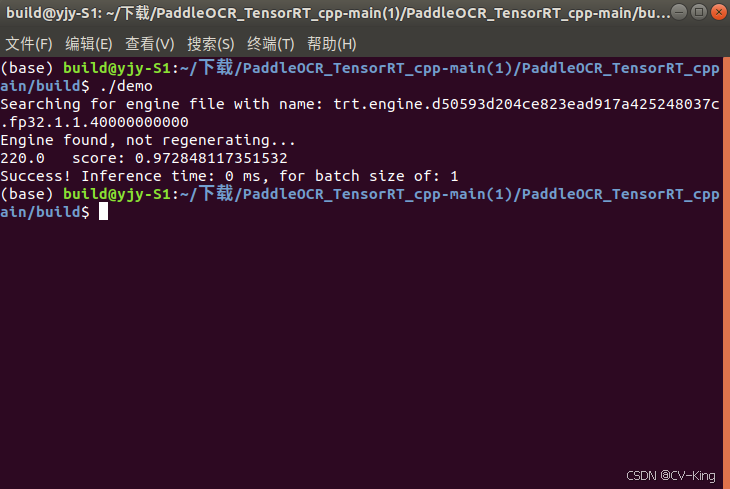 结束!
结束!