混合专家模型(Mixture of Experts, MoE)是一种深度学习模型架构,它结合了多个子模型(专家),并根据输入动态选择其中一部分来进行计算,从而提高计算效率和模型的表现。其核心思想是通过选择不同的专家来对特定任务进行建模,从而避免了使用所有专家的高计算成本。
论文出处
混合专家模型(Mixture of Experts, MoE)的原始论文是由 Shazeer et al. 提出的,标题为:
- “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”,发表在 Google Research 的论文中,2017年。
该论文介绍了基于稀疏门控机制的混合专家模型,这种模型通过选择性地激活一些专家模型(而不是所有的专家)来大大提升计算效率。
架构图
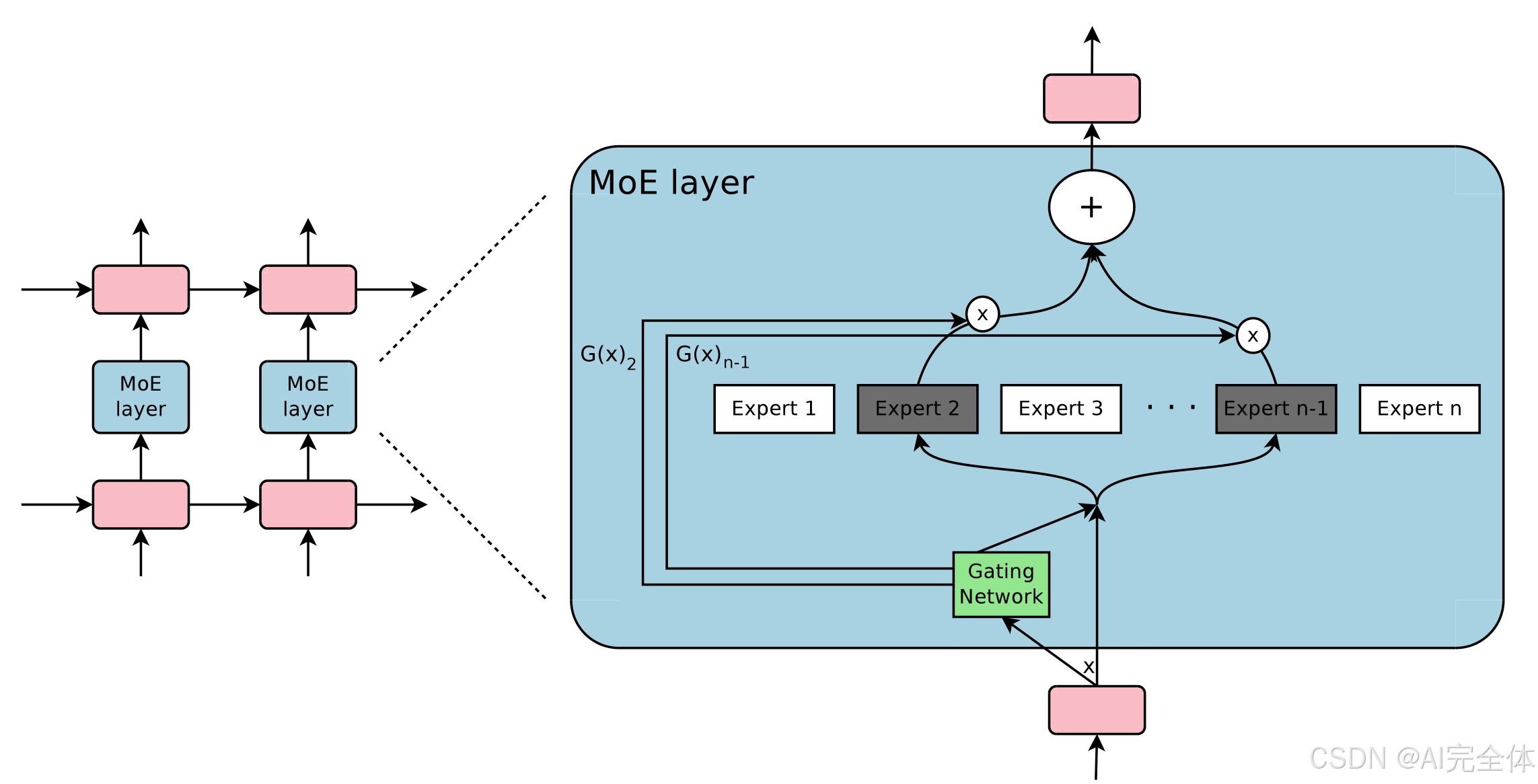
图片出处:原始论文
工作原理
- 专家(Experts):在MoE模型中,通常有多个专家,每个专家都是一个独立的子网络,负责处理不同类型的输入。
- 门控网络(Gating Network):门控网络用于决定对于每个输入,哪些专家应该参与计算。它通常是一个小型的神经网络,输出一个分布,表示每个专家的选择概率。
- 选择专家:根据门控网络的输出,MoE模型选择一部分专家来处理输入。例如,如果有10个专家,门控网络可能只选择其中2个或3个专家来处理当前的输入。
- 加权输出:每个专家会输出一个结果,门控网络根据专家的选择概率加权这些输出,得到最终的结果。
优势
- 计算效率:通过动态选择专家,而不是让所有专家参与每个输入的计算,MoE可以显著减少计算量。
- 模型容量:MoE允许使用大量的专家,从而提供更强的建模能力,同时由于不是每个输入都使用所有专家,模型可以高效利用资源。
- 灵活性:可以根据不同任务选择不同的专家子集,适应性强。
应用
- 自然语言处理(NLP):在大规模预训练语言模型中,MoE可以用来处理不同的语言或任务。
- 计算机视觉:MoE模型也可以用于图像处理,动态选择处理特定图像内容的专家。
- 强化学习:MoE有时也应用于强化学习,选择不同的策略专家来处理不同的情境。
挑战
- 专家负载不均:如果门控网络的输出不均衡,可能导致部分专家几乎不参与计算,浪费计算资源,而其他专家则过度工作,影响模型效果。
- 训练难度:需要设计合适的训练策略,确保所有专家得到有效训练,避免出现过拟合或梯度消失问题。
混合专家模型已经在多个领域取得了显著成果,尤其是在处理非常大的模型时,它能够通过减少每次计算所需的专家数量来提高效率和节省计算资源。