上周,Meta 发布的 Llama 4 无疑成为了众人瞩目的焦点。其创新性地采用混合专家(MoE)架构,在模型性能和效率上实现了质的飞跃,与传统 Dense 模型形成了鲜明对比。接下来,让我们深入剖析 Llama 4 的 MoE 架构,探寻它究竟是如何在这场技术角逐中脱颖而出,吊打传统 Dense 模型的。
一、Llama 4 的 MoE 架构解析
1、Scout 与 Maverick 结构概述

Llama 4 系列目前推出了 Scout 和 Maverick 两个版本,它们在架构设计上各具特色,但都围绕着 MoE 架构展开。
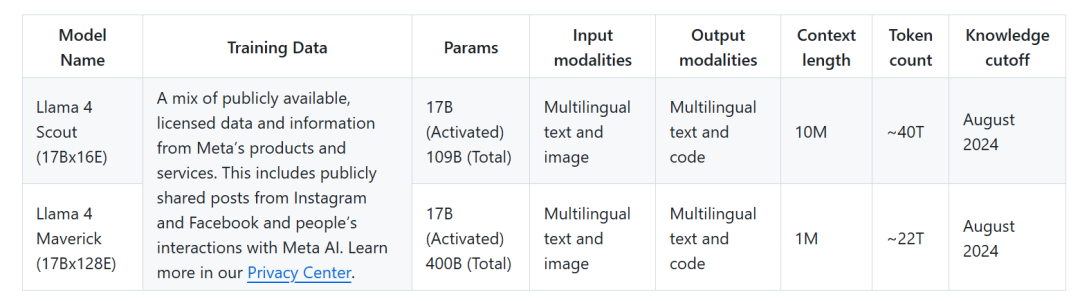
Scout 拥有 170 亿个活跃参数,配备 16 个 “专家” 模型,总参数达到 1090 亿;
Maverick 同样拥有 170 亿活跃参数,不过其 “专家” 模型数量飙升至 128 个,总参数量更是高达 4000 亿。
这些 “专家” 模型并非普通的子模型,它们如同在一个庞大知识体系中各有所长的专业学者,每个 “专家” 都针对特定类型的任务或知识领域进行了优化。例如,在处理文本情感分析时,可能会有专门擅长情感语义理解的 “专家” 模型被激活;而在进行复杂的数学推理时,另一个精通数学逻辑的 “专家” 模型则会发挥主导作用。这种分工明确的设计理念,是 MoE 架构的核心优势之一。
2、动态参数激活机制
与传统 Dense 模型在推理或训练时所有参数均参与计算不同,Llama 4 的 MoE 架构引入了动态参数激活机制。在面对输入数据时,并非所有的 “专家” 模型都会被调用,而是通过门控网络(Gating Network)来判断哪些 “专家” 模型最适合处理当前的数据。只有被选中的 “专家” 模型的参数才会被激活参与计算,其他 “专家” 模型则处于休眠状态。
以 Scout 的 16 个 “专家” 模型为例,当输入一段关于自然科学领域的文本时,门控网络会迅速分析文本特征,识别出与自然科学知识处理相关度最高的几个 “专家” 模型,假设为 3 个。此时,仅有这 3 个 “专家” 模型的 170 亿活跃参数中的一部分会被激活用于处理该文本,大大减少了不必要的计算量。这种动态参数激活机制,使得模型在运行过程中能够根据任务需求灵活调配资源,避免了传统 Dense 模型中大量参数的无效运算,极大地提高了计算效率。
3、专家调度算法
专家调度算法是 Llama 4 MoE 架构中的关键环节,它决定了门控网络如何精准地为不同输入数据分配最合适的 “专家” 模型。Meta 在 Llama 4 中采用了先进的调度算法,这些算法综合考虑了多种因素。
一方面,算法会对输入数据的特征进行深度分析,例如文本数据的主题、情感倾向、语言结构等,图像数据的内容类别、色彩特征、空间结构等。通过对这些特征的精准把握,算法能够快速筛选出与输入数据特征匹配度最高的 “专家” 模型。另一方面,算法还会考虑 “专家” 模型的历史表现,即过去在处理类似数据时的准确性和效率。那些在特定领域表现出色、处理速度快且准确率高的 “专家” 模型,在面对相关输入数据时,被调度的优先级会更高。
例如,在处理一系列代码生成任务时,曾经在代码生成任务中表现卓越、生成代码质量高且速度快的 “专家” 模型,会在后续的代码生成任务中被优先调用。这种基于数据特征和 “专家” 模型历史表现的专家调度算法,确保了模型在处理各种任务时都能以最优的方式分配资源,进一步提升了模型的整体性能和效率。
二、Llama 4 的 MoE 架构与传统 Dense 模型的效率对比
1、算力需求对比
传统 Dense 模型在运行过程中,由于所有参数都参与计算,其算力需求与参数量成正比。以 Llama - 2 - 13B 为例,推理时 13 亿参数全部投入运算,在 Q8_0 量化(8 - bit 量化)后,内存需求达到 14 - 15GB。而 Llama 4 的 MoE 架构,如 Scout 版本,虽然总参数高达 1090 亿,但在推理时仅激活 170 亿活跃参数中的一部分。假设在某一任务中,实际激活的参数数量为 50 亿(根据动态参数激活机制,具体激活数量因任务而异),相比之下,其算力需求大大降低。 在大规模训练场景下,传统 Dense 模型的算力需求更是呈指数级增长。训练一个 5000 亿参数的 Dense 模型,需要 2 万张 H100 的数据中心集群,建设成本高达 10 亿美元,每年的电费消耗就达到 5.3 亿元人民币。而 Llama 4 的 MoE 架构,通过动态参数激活和专家调度算法,使得在相同计算预算下,可以显著扩大模型或数据集的规模,大大降低了训练所需的算力成本。
2、内存使用对比
在内存使用方面,传统 Dense 模型的内存需求直接取决于参数量。像 70 亿参数的 Llama - 2 - 70B 模型,在相应量化条件下,内存需求约为 70GB。对于一些内存资源有限的设备,如 24GB 内存的 M4 Mac,运行这类模型时可能会出现内存不足甚至直接 “爆炸” 的情况。
反观 Llama 4 的 MoE 架构,以 Maverick 版本为例,虽然总参数量高达 4000 亿,但在推理时实际使用的激活内存与参与计算的活跃参数相关。由于门控网络会根据任务选择激活部分 “专家” 模型,假设在某一推理任务中,实际激活的参数对应的内存需求仅为 30GB(远低于其总参数量对应的内存需求)。并且,MoE 架构在设计上可以通过优化内存管理策略,进一步降低内存峰值,提高内存使用效率,使得模型能够在内存资源相对有限的环境下也能高效运行。
3、推理速度对比
推理速度是衡量模型效率的重要指标之一。传统 Dense 模型在推理时,由于需要对所有参数进行运算,计算过程较为繁琐,推理速度相对较慢。例如,Llama - 2 - 13B 在 24GB 内存的 M4 Mac 上运行时,推理速度大约为 8 - 15 tokens/s(每秒生成 8 - 15 个词)。
而 Llama 4 的 MoE 架构凭借其动态参数激活和高效的专家调度算法,推理速度得到了显著提升。例如,在处理类似的文本生成任务时,Scout 版本的推理速度能够达到 25 tokens/s 以上。这是因为 MoE 架构能够快速筛选出最合适的 “专家” 模型处理输入数据,减少了不必要的计算步骤,从而大大提高了推理速度。在实际应用场景中,如实时问答系统、智能客服等,快速的推理速度能够为用户提供更流畅、更及时的交互体验,增强了模型的实用性和用户满意度。
4、模型扩展性对比
随着人工智能技术的不断发展,对模型性能和功能的要求也越来越高,模型的扩展性显得尤为重要。传统 Dense 模型在扩展性方面存在一定的局限性。当需要增加模型的参数以提升性能时,例如从 13B 扩展到 70B,其算力和内存需求会直接翻倍,这不仅对硬件设备提出了极高的要求,而且在实际操作中,由于资源限制,往往难以实现大规模的扩展。
Llama 4 的 MoE 架构在扩展性方面具有明显优势。通过增加 “专家” 模型的数量,就可以在不显著增加算力需求的情况下扩展模型的功能和性能。例如,从 Scout 的 16 个 “专家” 模型扩展到 Maverick 的 128 个 “专家” 模型,虽然总参数量大幅增加,但由于动态参数激活和专家调度算法的存在,模型在推理和训练时的算力需求并没有呈现出同等幅度的增长。这种良好的扩展性使得 Llama 4 能够更好地适应未来人工智能发展中对模型不断升级和优化的需求,为其在更广泛领域的应用奠定了坚实的基础。
Meta Llama4 的 MoE 架构通过动态参数激活和专家调度算法,在效率上大幅超越了传统的 Dense 模型。这种架构不仅提高了模型的计算效率,还优化了资源利用,增强了模型的灵活性。
三、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】