1、概述
目前,市面上的很多大模型(如阿里的通义千问、百度的文心一言、月之暗面的kimi、深度求索的deepseek等),它们除了能让我们自己直接进行使用之外,通常还支持通过开放API接口的形式,让我们进行接入,从而使得我们自己的IT系统具备大模型相关能力
本文将以阿里云百炼平台(https://bailian.console.aliyun.com/#/home)为例,介绍如何调用第三方大模型云服务
2、第三方大模型云服务(阿里云百炼平台)的基本调用
Step1: 访问官网(https://bailian.console.aliyun.com/#/home)
Step2: 创建API-KEY
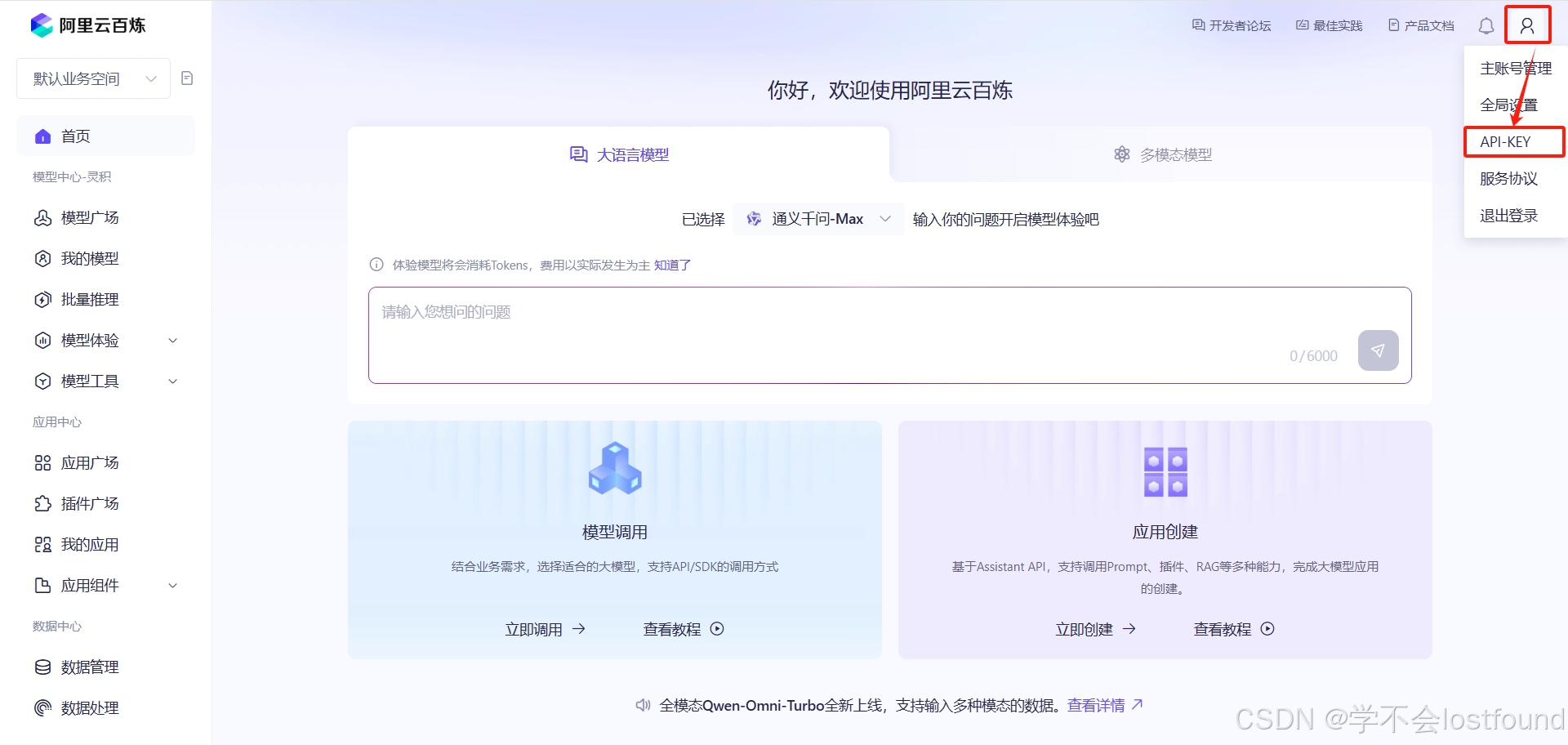
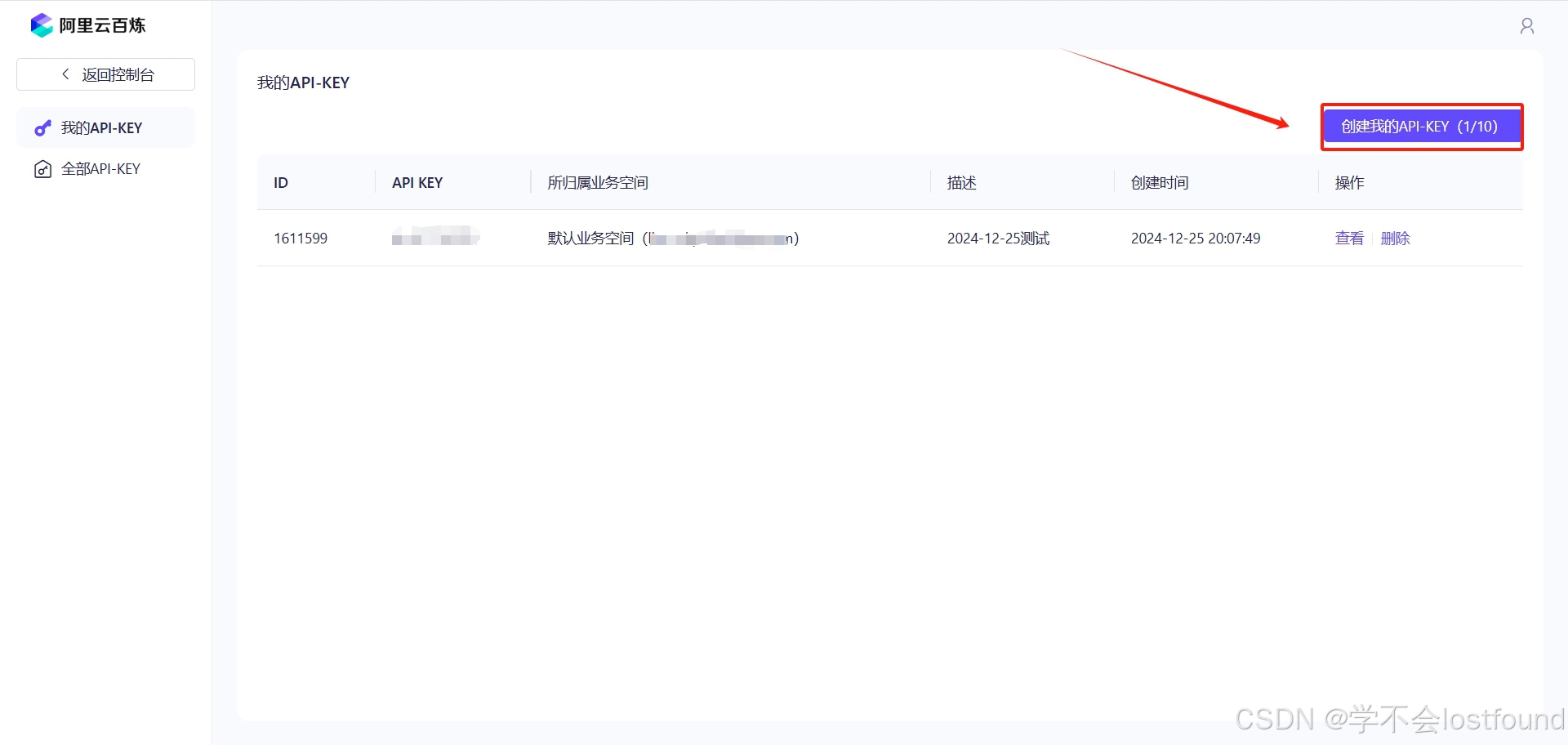
Step3: 将API-KEY放入环境变量中
方法有很多种,这里介绍其中的一种方法,即:在项目目录下创建名为《.env》的文件,并将API-KEY的值赋予DASHSCOPE_API_KEY参数

备注:jupyter下默认不显示以小数点开头的文件,可以通过资源管理器(windows系统)或ls -a命令(linux系统)的方式进行查看
Step4: 安装环境依赖
pip install dashscope -UStep5: 代码调用
# 加载环境变量中的DASHSCOPE_API_KEY
from dotenv import load_dotenv
load_dotenv()
# 加载阿里大模型
from langchain_community.chat_models import ChatTongyi
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
# 调用qwen-turbo模型
model = ChatTongyi(model="qwen-turbo", temperature=0.1, top_p=0.3, max_tokens=512)
respose = model.invoke(input="你好")
print(respose.content)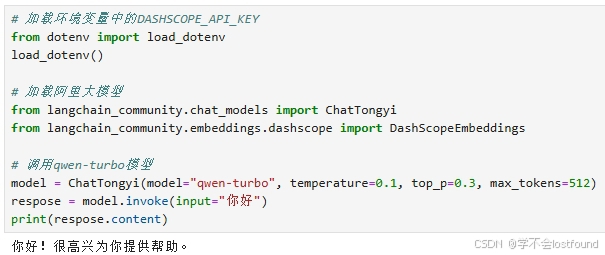
通过上面步骤,可知调用第三方大模型云服务还是非常方便,不需要自己搭建GPU环境和做部署的部署,唯一美中不足的就是需要根据调用量(tokens)来收费,不过目前价格很便宜,所以还是可以根据实际情况选择是否使用这种简单的方式
3、RAG初识
3.1 引子——阅读理解
不论是语文还是英文,对于语言类学科的学习,我们通常都遇到过“阅读理解”类的试题,即:给定一篇或一段文章,要求梳理和总结其内容,来回答指定的问题
人能做阅读理解,大模型照样可以,下面将以网站中华人民共和国电子签名法_百度百科中的部分内容为例,调用上面我们测试接入过的qwen-turbo模型,来演示大模型的“阅读理解”能力
# 加载环境变量中的DASHSCOPE_API_KEY
from dotenv import load_dotenv
load_dotenv()
# 加载阿里大模型
from langchain_community.chat_models import ChatTongyi
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
sys_prompt = SystemMessagePromptTemplate.from_template(template="""
你是一个阅读理解机器人!
请认真阅读用户提供的文章,并根据文章的内容来回答用户的问题!
请注意:
1, 如果问题没有在文章中出现,请直接使用你自己的知识来回答!
2, 不需要做任何的解释,直接回答问题的结果即可!
""")
user_prompt = HumanMessagePromptTemplate.from_template(template="""
文章为:
{passage}
问题为:
{question}
答案为:
""")
prompt = ChatPromptTemplate.from_messages(messages=[sys_prompt, user_prompt])
model = ChatTongyi(model="qwen-turbo", temperature=0.1, top_p=0.3, max_tokens=512)
output_parser = StrOutputParser()
chain = prompt | model | output_parser
passage = """
中华人民共和国电子签名法被认为是中国首部真正电子商务法意义上的立法。因为自1996年联合国颁布《电子商务示范法》以来,世界各国电子商务立法如火如荼,有的国家颁布了电子商务法或交易法,有的国家颁布了电子签名或数字签名法,也有的国家兼采两种立法方式。 而我国电子商务立法最终在国家信息化战略的引导下出台,可以说是业内人士期盼已久的举措,也受到了各相关企业乃至政府部门的高度关注。
被称为“中国首部真正意义上的信息化法律”,自此电子签名与传统手写签名和盖章具有同等的法律效力。《电子签名法》是我国推进电子商务发展,扫除电子商务发展障碍的重要步骤。虽然舆论普遍认为《电子签名法》将会极大地促进电子商务在我国的快速发展,但在网络交易安全、相关法律衔接等“拦路虎”面前,有关专家认为,现阶段《电子签名法》的标志意义大于实际意义。
2002年5月,《中华人民共和国电子签名法》起草工作的正式启动,当时由国务院信息化领导小组组织。
2003年4月,根据国务院立法工作计划,国务院法制办会同信息产业部、国务院信息化工作办公室开始接手《中华人民共和国电子签名法(草案)》的起草工作。该《草案》于2004年4月2日提交全国人大常委会第八次会议首次审议,经第十次二读后,第十一次会议通过。
2004年8月28日第十届全国人民代表大会常务委员会第十一次会议通过,自2005年4月1日起施行。
2015年4月24日第十二届全国人民代表大会常务委员会第十四次会议《关于修改〈中华人民共和国电力法〉等六部法律的决定》修正
根据2019年4月23日第十三届全国人民代表大会常务委员会第十次会议《关于修改《中华人民共和国建筑法》等八部法律的决定》修正 [1]
"""
question = """
电子签名法的起源是?
"""
chain.invoke(input=dict(passage=passage, question=question))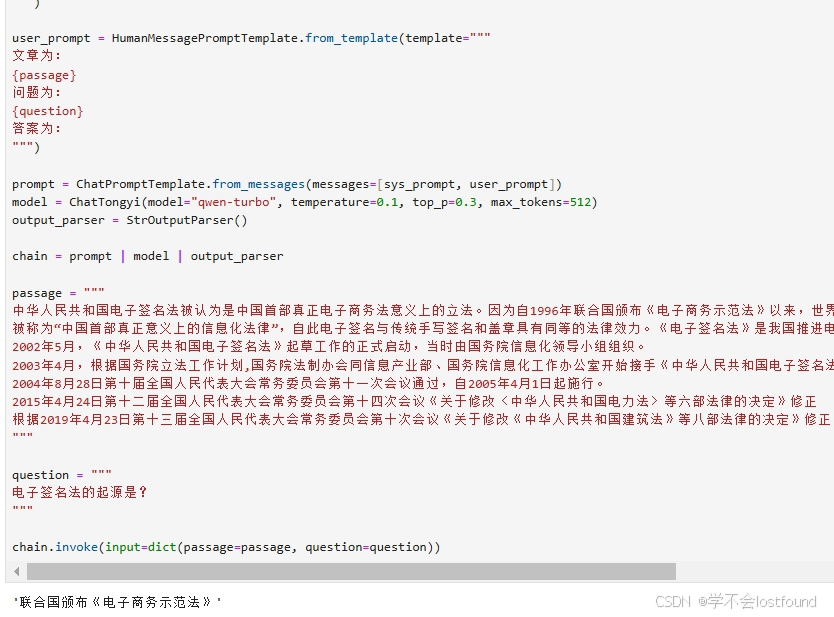
3.2 问题与思考
在当今数字化时代,很多企业都积累了海量的私有知识资料,包括产品说明、规章制度、对外文案等,这些资料是企业的宝贵财富
然而,在实际应用中,当我们要找某个资料时,我们往往都是通过“资料名称”或“资料内容”中的关键字来进行检索,然后基于自己的理解,来做进一步的知识转换和输出,这样做是可行的,但效率很低
面对此问题,我们应该思考:既然大模型能像本文【3.1 引子——阅读理解】中的操作这样针对文章或段落内容做阅读理解,那么是不是也可以基于企业内部的私有知识资料做阅读理解呢?——当然是可以的!
既然可以,那么还有一个重要问题需要思考,即:当我们向大模型问一个问题时,如果我们企业内部的私有知识资料很多,则大模型应该将这些知识完全都参考吗?能不能只把跟问题有关的知识让大模型参考?——当然是可以的!
那如何判断或筛选跟问题相关的知识呢?
方法:根据文本相似度来进行检索
- 方式1:通过关键词来匹配
- 这其实就是我们目前传统的方式,但其要求太高了,需要提前把文章的关键词准备好,费时费力
- 其次,面对国际化的社会,语言的差异处理起来也很麻烦
- 最后,不能做阅读理解,只能根据文本关键字做普通检索,不够灵活
- 方式2:语义化匹配
- 原理:脱离语言本身,看内涵,跨语言、跨表达习惯,直奔这句话的本质去
- 具体方式:
- Step1:把私有资料按逻辑互相独立的单元来分段
- Step2:使用一个模型(本质:BERT,向量化)把每段知识的核心信息抽取出来,变成一个向量(比如,1024维)
- Step3:找一个数据库(向量化数据库,且需要GPU支撑)把这些知识片段及其向量都存起来
- Step4:对用户提问的处理:先把问题通过向量化模型,转换成一个向量,然后使用这个向量去向量数据库中做匹配,查找最相似的上下文
- 把问题和上下一起交给模型,让模型回答问题!
- 疑问:你都在库中找到答案了,还让大模型生成个毛啊?
- 检索出来的东西,有些高度相关,有些低相关,而且比较长 需要自己再去加工的!!!
- 大模型帮我们快速筛选和判断!!而且按你的习惯来输出结果!!
- 疑问:你都在库中找到答案了,还让大模型生成个毛啊?
- 优势:对于传统的关键词检索,其检索出来的内容有些是与问题高度相关的,有些是低相关的,而且比较长,需要自己再去加工;而大模型能帮我们快速筛选和判断,同时按照自己的习惯来输出结果
即,大致使用步骤为:
- Query——提问
- Retrieve——检索(相关的上下文)
- Augment——增强(在prompt中整合问题和上下文)
- Generate——生成(生成最终的结果)
3.3 RAG基础知识
RAG(Retrieval Augmented Generation,即:检索增强生成)是一种结合检索和生成的混合方法,旨在解决上述“企业内部私有资料的阅读理解”问题,其核心思想是通过检索技术从私有知识库中提取与问题最相关的上下文,然后将问题和上下文一起输入大语言模型,从而生成高质量的答案
3.3.1 RAG的工作原理
RAG的工作流程可以分为以下几个步骤:
Step1:加载与切分(Load & Split) 首先,需要将企业的私有知识资料加载到系统中,这些资料可以是文档、网页或其他格式
加载完成后,将知识资料按照逻辑单元进行切分(例如:将一篇长文档拆分为多个段落或章节,每个单元都应具有相对独立的语义)
Step2:向量化(Embed) 使用一个预训练的语言模型(如BERT)将每个知识单元的核心信息提取出来,并将其转换为一个高维向量(例如1024维),这些向量能够捕捉知识单元的语义特征,为后续的检索提供基础
Step3:入库(Store) 将向量化的知识单元及其对应的原始文本存储到一个专门的向量数据库中,这个数据库支持高效的向量检索,通常基于GPU加速,能够快速处理大规模数据
Step4:提问(Query) 当用户提出一个问题时,首先将问题通过相同的向量化模型转换为一个向量
Step5:检索(Retrieve) 使用问题向量在向量数据库中检索与问题最相关的知识单元,通常会返回多个相关性较高的上下文片段,这些片段可能与问题高度相关,也可能只是部分相关
Step6:增强(Augment) 将检索到的上下文片段与原始问题整合到一个增强的提示(prompt)中,这个提示将作为输入传递给大语言模型
Step7:生成(Generate) 大语言模型根据增强后的提示生成最终的答案(这个过程不仅利用了检索到的上下文信息,还结合了模型自身的语言生成能力,能够生成更准确、更符合用户需求的答案)
3.3.2 RAG的优势
-
高效性:通过检索技术,RAG能够快速从海量知识中筛选出与问题相关的部分,避免了信息过载
-
准确性:结合检索到的上下文和大语言模型的生成能力,能够生成更准确的答案
-
灵活性:RAG可以根据不同的问题动态检索相关的知识,适应性强
3.3.3 RAG的实现细节
(1)向量化模型的选择
在RAG中,向量化模型的选择至关重要,BERT是一个常见的选择,因为它能够很好地捕捉文本的语义特征
然而,随着技术的发展,也有其他更先进的模型可供选择,例如Sentence-BERT(SBERT)或DPR(Dense Passage Retrieval),这些模型在语义理解和检索效率上都有更好的表现
(2)向量数据库的选择
向量数据库是RAG的核心组件之一,它需要支持高效的向量检索,并能够处理大规模数据
常见的向量数据库包括ChromaDB、Faiss、Milvus、Elasticsearch等,这些数据库都提供了强大的检索功能,能够快速返回与问题向量最相似的知识单元
(3)检索策略
在检索过程中,可以采用不同的策略来优化结果
例如,可以设置检索的召回数量(Top-K),并根据相关性分数对检索结果进行排序;此外,还可以结合多模态信息(如图像或表格)来进一步提升检索的准确性
(4)生成阶段的优化
在生成阶段,大语言模型可以根据检索到的上下文生成答案,为了进一步优化生成结果,可以采用以下策略:
-
上下文裁剪:如果检索到的上下文过长,可以对其进行裁剪,只保留与问题最相关的部分
-
多轮对话:如果问题较为复杂,可以将RAG嵌入到多轮对话系统中,逐步细化问题和答案
-
结果校验:生成的答案可以与检索到的上下文进行对比,确保其准确性和一致性
3.3.4 RAG的实践案例
(1)企业内部问答系统
某大型制造企业采用了RAG技术来构建内部问答系统,该系统整合了企业的产品说明书、技术文档和规章制度等私有知识
通过RAG,员工可以快速查询与工作相关的问题,并获得准确的答案(例如:当员工询问某个产品的技术参数时,系统能够从海量文档中检索出最相关的部分,并结合大语言模型生成详细的答案)
(2)客户支持系统
在客户支持场景中,RAG可以帮助客服人员快速找到与客户问题相关的知识
例如:当客户询问产品的使用方法或售后服务政策时,系统能够从企业对外文案和规章制度中检索出相关内容,并生成清晰、准确的答复。这不仅提高了客户满意度,还减轻了客服人员的工作负担
3.3.5 RAG的未来展望
随着技术的不断进步,RAG在企业私有知识管理中的应用前景广阔,未来,我们可以期待以下几个发展方向
-
多模态融合:结合文本、图像、视频等多种模态的信息,进一步提升检索和生成的效果
-
跨语言支持:通过跨语言向量化技术,实现多语言知识的统一管理和检索
-
智能化优化:利用机器学习技术,自动优化检索策略和生成结果,提升系统的智能化水平