0、概述
要搭建一个大模型应用服务,通常需要包含以下五层结构,即:基础环境、模型层、推理层、对外接口、外挂应用
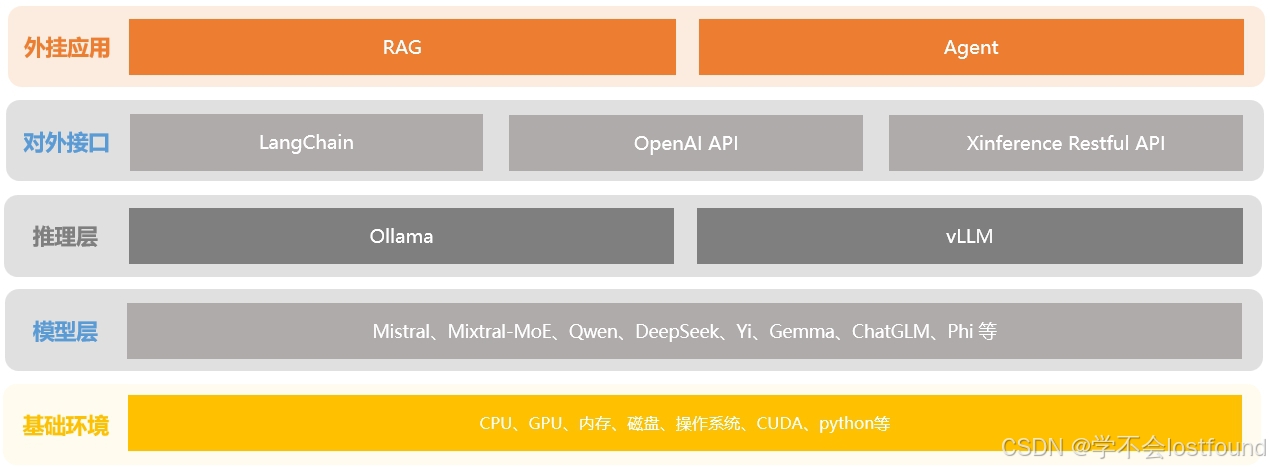
在了解了模型的微调训练之后,本文将以vLLM、OpenAI、LangChain为例,介绍大模型的推理部署以及对外接口开放调用
1、vLLM
1.1 定义
vLLM(Virtual Large Language Model)是一个开源的大语言模型高速推理框架,由加州大学伯克利分校的LMSYS组织开发,它旨在提升实时场景下语言模型服务的吞吐量和内存使用效率,特别适合于需要高效处理大量并发请求的应用场景
1.2 核心特点
-
PagedAttention:vLLM的核心技术是PagedAttention,这是一种受操作系统虚拟内存管理启发的注意力机制算法,它允许在不连续的内存空间中存储连续的键值对(keys和values),从而解决了自回归模型中的KV缓存问题;通过将每个序列的KV缓存划分为固定大小的块,PagedAttention能够有效地管理和访问这些缓存,减少了显存碎片并提高了显存利用率
-
内存优化:除了PagedAttention外,vLLM还采用了其他内存优化策略,比如memory sharing,这种机制能够在不同的序列之间共享物理内存块,进一步降低了显存需求,并提高了整体的吞吐量
-
高效推理:vLLM相比HuggingFace Transformers等其他框架,在相同的硬件条件下能提供更高的吞吐量,具体来说:它的文本生成推理速度可以达到HuggingFace实现的3.5倍到24倍不等,这使得vLLM成为资源受限环境下部署大型语言模型的理想选择
-
支持多种模型:vLLM支持多种大模型(如 GPT、BERT、T5 等),并且能够为大语言模型构建 API 服务器
1.3 应用场景
由于其高效的推理能力和良好的内存管理,vLLM适用于多种自然语言处理任务,包括但不限于:
-
文本生成:如自动写作、内容创作、广告文案生成等
-
机器翻译:实现高质量的多语言互译
-
问答系统:构建智能客服或虚拟助手,以提高用户体验
-
情感分析:用于舆情监控、产品评论分析等领域
1.4 安装部署
Step0: 模型准备
下载一个小一点的模型进行测试即可,比如:Qwen2.5-0.5B-Instruct
下载网址:魔搭社区
Step1: 安装vLLM
用pip即可安装vLLM,命令如下:
pip install vllminstall之后,可用show命令查看是否安装成功
pip show vllm成功显示版本号即代表安装成功
Step2: 部署vLLM
关键参数:自定义的端口号(port)、模型路径(model)、模型api调用所需的api-key
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 6006 \
--model /mnt/workspace/Qwen2.5-0.5B-Instruct \
--api-key abc123 \
--enable-auto-tool-choice \
--tool-call-parser hermes2、OpenAI调用部署好的vLLM
使用OpenAI的compatible API接口调用部署好的vLLM,示例代码及效果如下
from openai import OpenAI
openai_api_key = "abc123"
openai_api_base = "http://localhost:6006/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/mnt/workspace/Qwen2.5-0.5B-Instruct",
messages=[
{"role": "system", "content": "你是一个很有用的助手。"},
{"role": "user", "content": "湖北省的省会是哪个城市?"},
]
)
print("Chat response:", chat_response)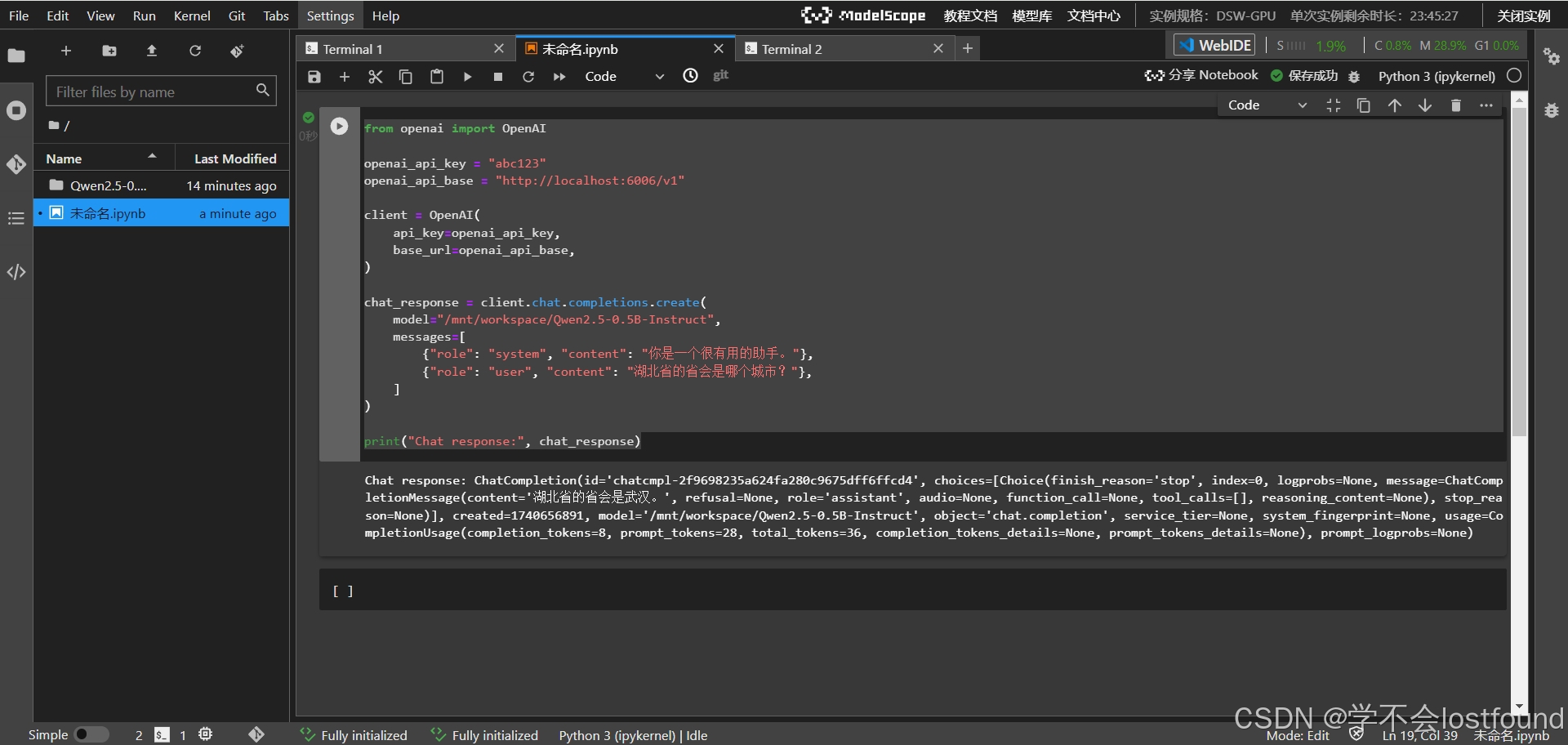
3、LangChain调用部署好的vLLM
3.1 环境搭建与模型初始化
在调用之前,需要将模型进行初始化
from langchain_openai import ChatOpenAI
# 模型配置
base_url = "https://u526261-a6b7-d77a59b1.nmb1.seetacloud.com:8443/v1"
api_key = "abc123"
model_name = "Qwen2.5-0.5B-Instruct"
# 初始化模型
model = ChatOpenAI(
base_url=base_url,
api_key=api_key,
model=model_name,
max_tokens=512,
temperature=0.1,
top_p=0.3
)3.2 模型调用与响应处理
LangChain 提供了多种方式来调用大语言模型,包括单次调用、流式调用和批量调用等
3.2.1 单次调用
# 以前叫做call,现在叫做invoke
response = model.invoke(input="你是光小环吗?")
print(response.content)3.2.2 流式调用
流式调用可以实时获取模型的输出,适合需要实时交互的场景,实现目前大家与市面上模型进行对话聊天时常见的打字机效果
response = model.stream(input="你好")
for chunk in response:
print(chunk.content)3.2.3 批量调用
批量调用可以同时处理多个输入,提高效率
queries = ["你好", "你吃饭了吗?", "我们一起去打球吧"]
responses = model.batch(inputs=queries)
print(responses)3.3 情感分析任务实现
3.3.1 案例概述
现有一个名为《samples.tsv》的语料文件,其中包含5999行数据,每行数据包含两列内容:
(1)用户的评论语句
(2)该语句的情感性质(正面/负面)
内容大致如下图所示
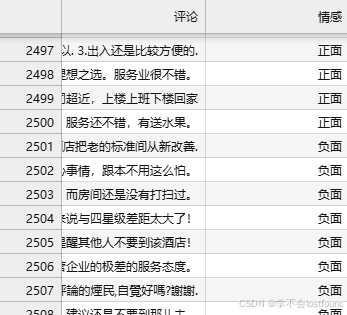
目前已经将上面内容送入Qwen2.5-0.5B-Instruct中进行了SFT微调,并将训练后的Qwen2.5-0.5B-Instruct进行了vLLM部署
现要求通过LangChain调用部署好的vLLM,对用户输入的语句进行情感性质判断
3.3.2 代码实现
Step1: 定义系统提示
from langchain_core.prompts import SystemMessagePromptTemplate
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
sys_prompt = SystemMessagePromptTemplate.from_template(template="""
你是一个情感识别专家!请对用户输入的酒店评论做情感分析!
如果是正面的评论,请输出:
{
{
"sentiment": "正面"
}},
如果是负面的评论,请输出:
{
{
"sentiment": "负面"
}}
""")
user_prompt = HumanMessagePromptTemplate.from_template(template="{text}")
prompt = ChatPromptTemplate.from_messages(messages=[sys_prompt, user_prompt])Step2: 构建 LangChain 流程
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
# 在 LangChain 中,| 符号用于连接不同的组件,构建一个完整的处理流程
# 这里的 prompt | model | output_parser 表示将提示模板、大语言模型、输出解释器依次传递给以下三个组件
chain = prompt | model | output_parserStep3: 情感分析测试
text = "刚从无锡回来,住了该酒店二号楼328YUAN的,总体感觉如下;房间干净,配制齐全还有液镜电脑;饭菜可口且不是很贵;最值得称赞的是服务水准,老公粗心大意把手机掉了,工作人员捡后马上送回,赞了!饭店的员工几乎都是笑脸相迎,很难得,单从这点就间接提升了入住该饭店的理由!"
result = chain.invoke(input={"text": text})
print(result)Step4: 数据处理与评估
使用 LangChain 流程对每个评论进行情感分析,并计算准确率
import pandas as pd
from tqdm import tqdm
# 加载数据
data = pd.read_csv(filepath_or_buffer="test.tsv", sep="\t", encoding="utf8")
# 评估模型
results = []
for idx in tqdm(range(len(data))):
comment, sentiment = data.loc[idx, :]
result = chain.invoke(input={"text": comment})
try:
result = json.loads(result)
except Exception as ex:
print(result)
results.append(result["sentiment"] == sentiment)
accuracy = sum(results) / len(results)
print(f"模型准确率:{accuracy:.2%}")