什么是昇腾Ascend 300I Pro
基于昇腾310P芯片的Ascend 300I Pro推理卡是华为推出的一款高性能AI推理加速卡,专为数据中心和边缘计算场景设计。其核心架构与性能特点如下:
架构设计
-
硬件集成
Atlas 300I Pro采用昇腾310P AI处理器,融合了“通用处理器、AI Core、编解码模块”三大核心组件。其中:-
昇腾310P芯片:基于达芬奇架构(Da Vinci Core),内置8个AI专用计算核心和8个自研CPU核心,主频1.9GHz,支持整图下沉执行,减少Host-Device交互开销,提升计算效率。
-
内存与带宽:配备24GB LPDDR4X内存,总带宽达204.8GB/s,支持高吞吐量数据处理,满足实时推理需求。
-
编解码能力:集成H.264、H.265视频编解码和JPEG图片编解码模块,适用于多媒体分析场景。
-
-
工作模式
该卡以PCIe Gen4 x16接口运行于EP(Endpoint)模式,作为Host服务器的协处理器,支持多卡并行扩展,适用于分布式推理任务。
性能特点
-
超强算力
-
AI算力:单卡提供140 TOPS的INT8算力和70 TFLOPS的FP16算力,尤其擅长处理大规模特征检索和高密度推理任务,如每秒55亿次特征比对。
-
CPU支持:8核1.9GHz通用CPU协同处理逻辑控制和任务分发,增强复杂任务的处理能力。
-
-
超高能效
-
能效比达2 TOPS/W,为业界平均水平的2.1倍,显著降低数据中心能耗与部署成本。
-
-
安全与可靠性
-
安全启动:通过完整启动链验证和初始状态锁定,防止恶意固件植入,确保设备运行安全。
-
稳定性:支持0℃~55℃宽温工作环境,适应严苛部署条件49。
-
-
可维护性优化
-
支持在线升级、带内/带外设备状态监控(温度、功耗等),以及命令行与图形化管理工具,简化运维流程。
-
典型应用场景
Atlas 300I Pro广泛应用于以下领域:
-
搜索推荐系统:通过召回、排序算法实现用户画像与内容的精准匹配,部署于推理服务器中。
-
内容审核:支持视频、图像、语音、文本的多模态审核,应用于互联网平台的内容安全校验。
-
OCR识别:实现身份证认证、票据识别等功能,服务于智慧政务与金融领域。
-
城市视图分析:例如与格灵深瞳合作,单卡可解析64路视频流或256QPS图片流,特征比对性能达150亿次/秒,赋能智慧城市大数据处理。
技术规格
-
功耗与尺寸:最大功耗72W,采用单槽位半高半长设计(169.5mm×68.9mm),适配标准服务器机架。
-
兼容性:支持主流AI框架(如TensorFlow、PyTorch)和华为自研MindSpore,提供MindStudio全流程开发工具链。
| AI处理器 |
1 x 310系列处理器
|
|
| 内存规格 |
|
|
| CPU算力 |
8 core * 1.9 GHz |
|
| 编解码能力 |
|
|
| 虚拟化实例规格 |
支持通过虚拟化的方式将1路昇腾AI处理器切分成若干路虚拟NPU,每路虚拟NPU可支持4/2/1个AI Core,其他硬件资源(如内存、编解码模块)等比例切分,1路310系列处理器最大支持切分7路虚拟NPU。 |
|
| PCIe接口 |
|
|
| PCI IDs |
Vendor ID: 0x19E5 Device ID: 0xD500 Subsystem Vendor ID: 0x0200 Subsystem Device ID: 0x0100 |
|
| 单板功耗 |
72W |
|
准备工作
物理安装
在宿主机中输入
lspci -n -D | grep d500Device ID 参考列表如下,300I 系列310P 芯片pcie device id 为 d500,300T 系列 910B 芯片pcie device id 为 d801
| Vendor ID |
Device ID |
产品型号 |
|---|---|---|
| 19e5 |
d500 |
Atlas 300I Pro 推理卡、Atlas 300V Pro 视频解析卡、Atlas 300I Duo 推理卡和Atlas 300V 视频解析卡。 |
| 19e5 |
d801 |
Atlas 300T Pro 训练卡(型号:9000)、Atlas 300T 训练卡(型号:9000)、Atlas 800 训练服务器(型号:9000)、Atlas 800 训练服务器(型号:9010)和Atlas 900 计算节点。 |

固件与驱动安装
https://support.huawei.com/enterprise/zh/doc/EDOC1100422575/289e2d2d
参考该文档,主要安装流程如下
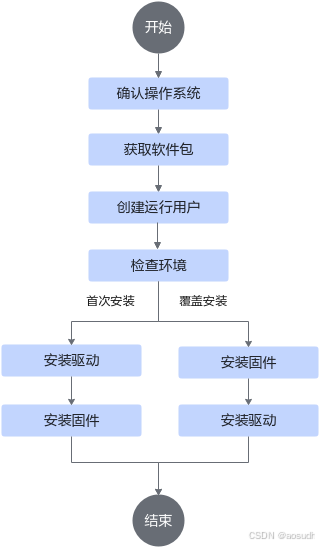
安装完成后,本地宿主机输入,即可查询当前固件与驱动的实际版本与兼容性信息
npu-smi info -t board -i id 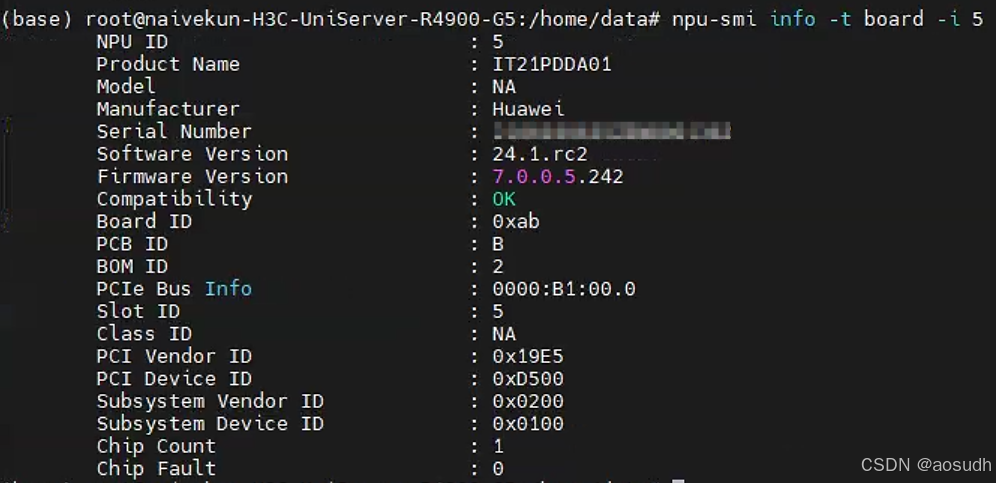
模型选择
根据下面的网页,可以查询到具体的模型支持信息
MindIE支持模型列表-MindIE是什么-MindIE1.0.RC2开发文档-昇腾社区
本次需要运行的是DeepSeek-R1-Distilled-Qwen,其本质上仍然是Qwen-7B,可以查询到兼容性如下,在推理卡中仅支持FP16的精度,W8A8量化仅在基于910B芯片的计算卡中支持。单卡300I pro 24G在排除ECC冗余与AICPU占用后实际可用显存大小为20G左右,所以最高仅能支持DeepSeek-R1-Distilled-Qwen-7B

模型下载
在huggingface或者魔塔社区中,可以下载到原版的safetensor模型权重文件
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/tree/main
下载好后解压到对应文件夹,给文件夹中所有文件赋予权限
镜像下载
在华为MindIE官网中,通过申请后即可下载镜像
https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
或者通过第三方OBS中留存的镜像下载
https://tools.obs.cn-south-292.ca-aicc.com/tools/mindie_docker_images/mindie_1.0.0_300IDuo.tar
镜像搭建
加载镜像
下载完成后,首先在docker中加载本地镜像
docker load -i mindie:1.0.0-300I-Duo-py311-openeuler24.03-lts(下载的镜像名称与标签)镜像中各组件版本配套如下:
| 组件 | 版本 |
|---|---|
| MindIE | 1.0.0 |
| CANN | 8.0.0 |
| PTA | 6.0.0 |
| MindStudio | 7.0.0 |
| HDK | 24.1.0 |
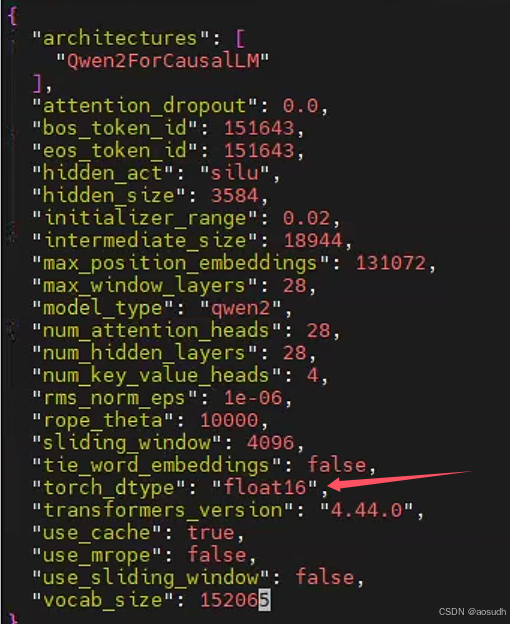
修改精度
如上文所述,在大模型推理应用中 310P 芯片仅支持FP16精度,并不支持BF16或INT8等数据类型,因此需要到模型权重文件中修改config.json

修改dtype为:float16后保存
新建容器
使用下面的脚本利用刚刚导入的mindie镜像创建新的docker本地容器环境,
docker run -itd --ipc=host \
--name=mindie_1.0.0 \
--privileged=true \
--net=host \
--entrypoint=/bin/bash \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /etc/localtime:/etc/localtime \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v {主机中权重文件的绝对路径}:{主机中权重文件的绝对路径} \
{本地镜像名}
其中,本地镜像名可以通过输入下面的代码查看
docker images
在完成上述步骤后,使用docker ps -a 查看新创建的容器名

使用下面的命令即可进入容器
docker exec -it ${容器名称} bash容器内环境配置
进入环境后,在 ~/.bashrc 中添加自动环境变量使能语句
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh
source /usr/local/Ascend/mindie/set_env.sh
进入
/usr/local/Ascend/mindie/1.0.0/mindie-service/conf/config.json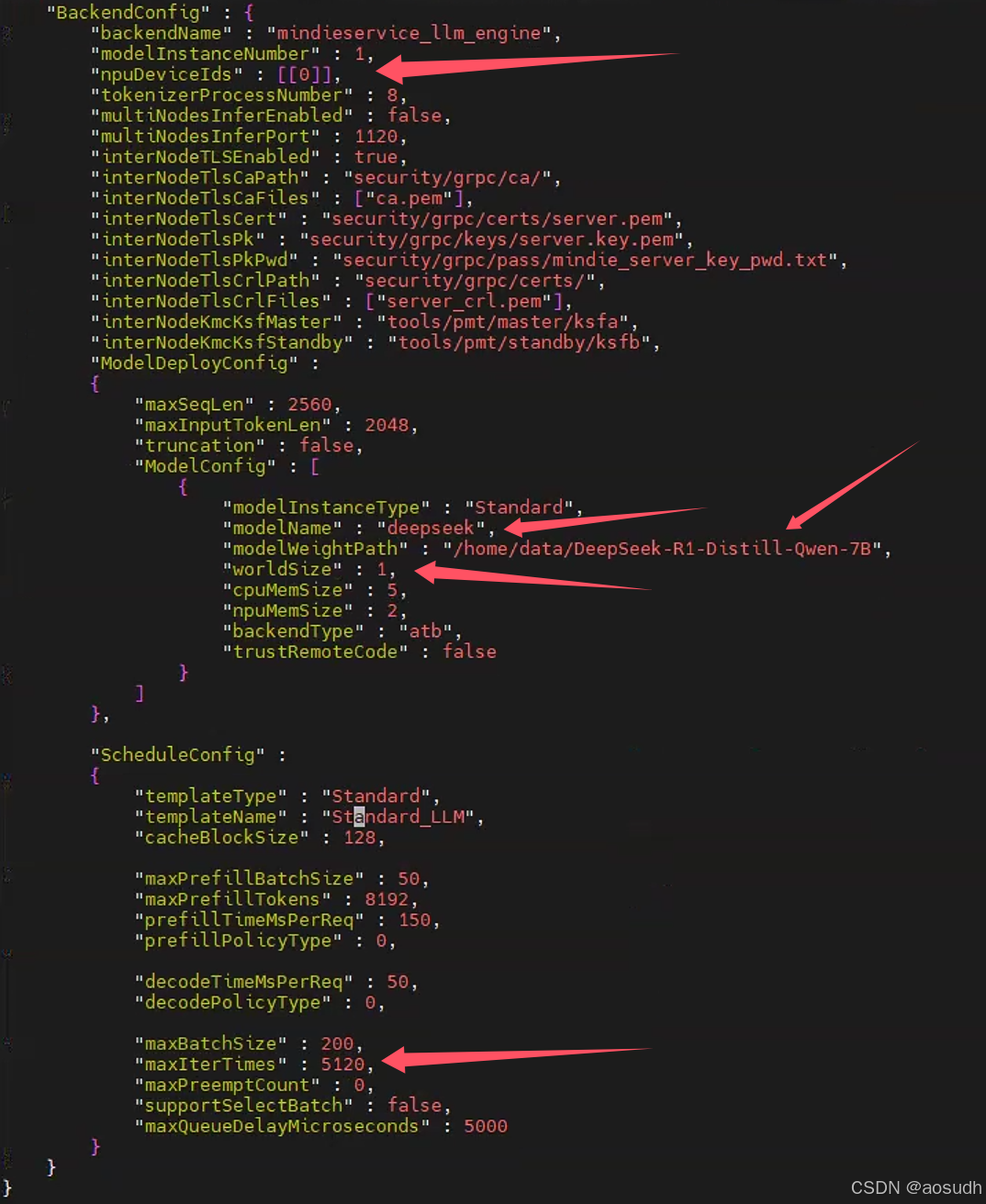
npuDeviceIds:单卡推理,所以填[[0]],假如是多卡,则根据卡数量填[[0,1,2,3][4,5,6,7]]等
truncation:false
modelName:自定义的模型名
modelWeightPath:模型的路径
worldSize:这里填实际推理使用的卡的数量,我是单卡,所以填1
httpsEnabled" : false
maxIterTimes与maxBatchSize: 如果需要输入长上下文,则按需改大这两个位置
保存退出后,输入
cd /usr/local/Ascend/mindie/latest/mindie-service/bin
./mindieservice_daemon当出现Daemon start success时,即为服务启动成功
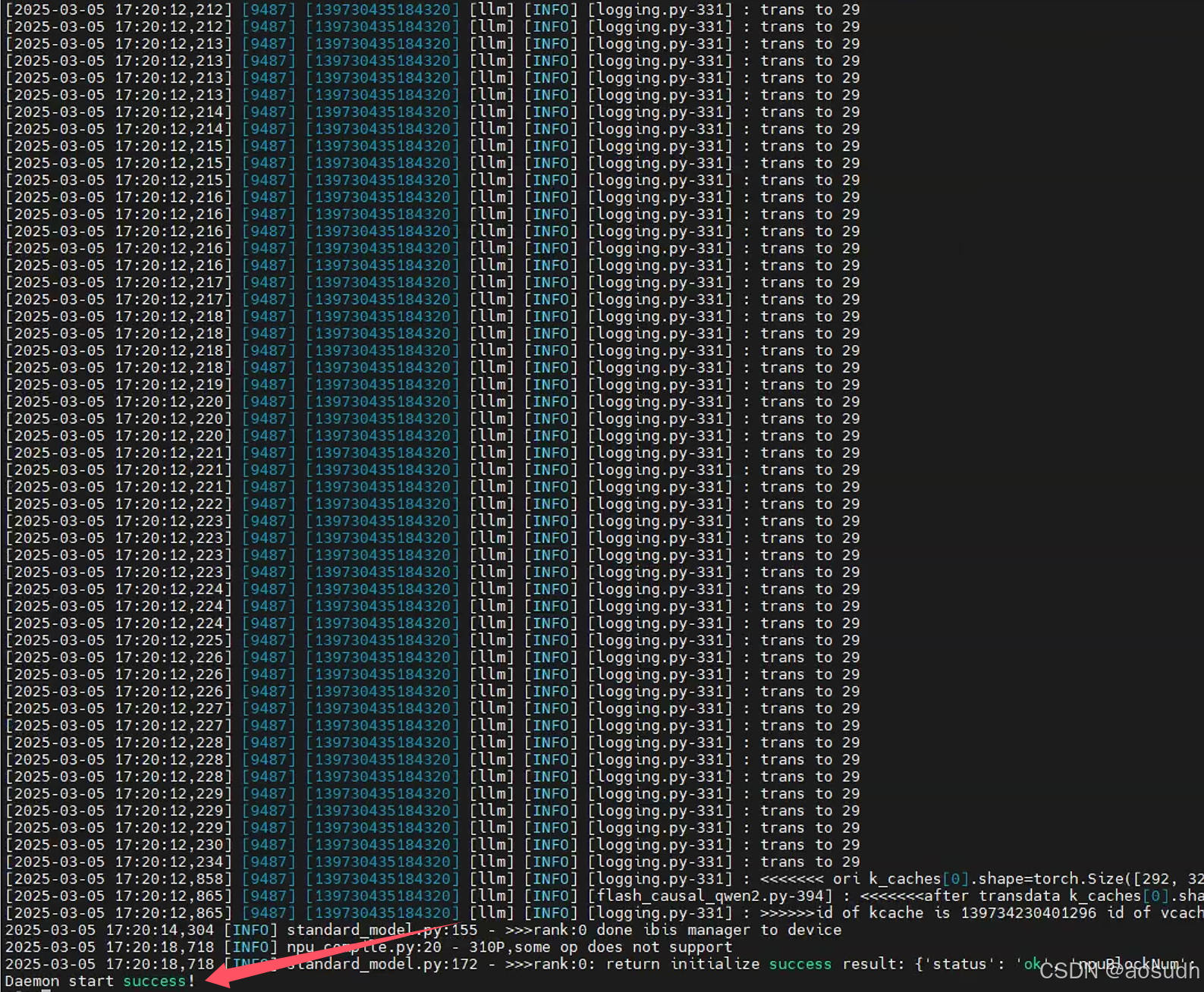
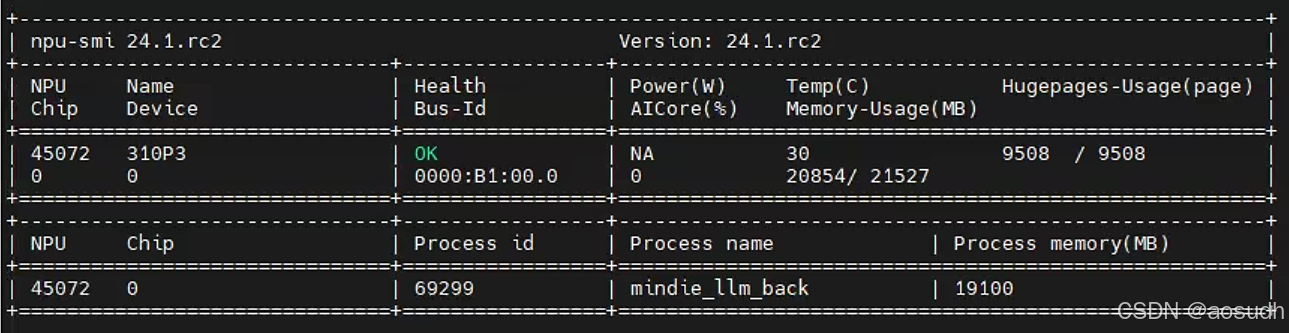
此时AI Core 利用率为0,显存占用基本满了
新建窗口测试(VLLM接口)
curl -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{
"model": "deepseek",
"messages": [{
"role": "user",
"content": "写一个有关你自己的介绍,包括模型大小,训练时间,训练所需的硬件等,要求不包含思考内容总长度要有四千个中文单词的内容,不能有任何删减"
}],
"max_tokens": 4096,
"presence_penalty": 1.03,
"frequency_penalty": 1.0,
"seed": null,
"temperature": 0.5,
"top_p": 0.95,
"stream": false
}' http://127.0.0.1:1025/v1/chat/completions
运行时占用如下
 最终实际性能大约在11-14tokens/s
最终实际性能大约在11-14tokens/s
 稀疏量化
稀疏量化
-
Step 1
- 注意该量化方式仅支持在Atlas 300I DUO/Atlas 300I Pro/Atlas 300V卡上运行
- Atlas 300I DUO/Atlas 300I Pro/Atlas 300V不支持多卡量化
- 修改模型权重config.json中
torch_dtype字段为float16 - 下载msmodelslim量化工具
- 下载地址为msit: 统一推理工具链入口,提供客户一体化开发工具,支持一站式调试调优 - Gitee.com
- 根据msmodelslim量化工具readme进行相关操作
- 进入到{msModelSlim工具路径}/msit/msmodelslim/example/qwen的目录
cd msit/msmodelslim/example/Qwen注: 安装完cann后 需要执行source set_env.sh 声明ASCEND_HOME_PATH值 后续安装msmodelslim前需保证其不为空
# 执行"jq --version"查看是否安装jq,若返回"bash:jq:command not found",则依次执行"apt-get update"和"apt install jq" jq --version # 指定当前机器上可用的逻辑NPU核心 通过修改export ASCEND_RT_VISIBLE_DEVICES值 指定使用卡号及数量 export ASCEND_RT_VISIBLE_DEVICES=0 # 运行量化转换脚本 python3 quant_qwen.py --model_path {浮点权重路径} --save_directory {W8A8S量化权重路径} --calib_file ../common/boolq.jsonl --w_bit 4 --a_bit 8 --fraction 0.011 --co_sparse True --device_type npu --use_sigma True --is_lowbit True -
Step 2:量化权重切分及压缩
export IGNORE_INFER_ERROR=1 torchrun --nproc_per_node {TP数} -m examples.convert.model_slim.sparse_compressor --model_path {W8A8S量化权重路径} --save_directory {W8A8SC量化权重路径}- TP数为tensor parallel并行个数
- 注意:若权重生成时以TP=2进行切分,则运行时也需以TP=2运行
- 示例
torchrun --nproc_per_node 2 -m examples.convert.model_slim.sparse_compressor --model_path /data1/weights/model_slim/Qwen-7b_w8a8s --save_directory /data1/weights/model_slim/Qw相关文章
DeepSeek-R1-Distill-Llama-8B-模型库-ModelZoo-昇腾社区
鲲鹏服务器+昇腾卡(Atlas 300I pro)搭建DeepSeek-R1-Distill-Qwen-7B(自己存档详细版)_atlas 300i duo deepseek-CSDN博客
mindie:1.0.0-300I-Duo-py311-openeuler24.03-lts以及其他mindie镜像下载列表【昇腾社区】-CSDN博客
ascend-docker-image: 提供Ascend相关的Dockerfile示例,展示如何创建docker镜像。 - Gitee.com
语言模型deepseek部署到华为昇腾NPU的详细步骤_deepseek 华为-CSDN博客
Atlas 300I Pro 推理卡介绍-适配测试指导书-Atlas 300I Pro 推理卡开发文档-昇腾社区
msit: 统一推理工具链入口,提供客户一体化开发工具,支持一站式调试调优 - Gitee.com
