Mindstudio 简介
MindStudio为用户提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。通过依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。另一方面,MindStudio采用插件化扩展机制,以支持开发者通过开发插件来扩展已有功能。在本案例中所使用的cann 版本为7.0,具体安装流程可参考MindStudio安装教程(https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000002.html)。
具体的,MindStudio的功能包括:
针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio可以进行工程管理、编译、调试、性能分析等全流程开发,可以很大程度提高开发效率。
什么是profiling
在软件工程和计算机科学领域,profiling[是一种动态分析方法,用于收集程序运行时的信息,以研究程序的行为。其主要目的是定位程序中需要优化的部分,从而提高程序的性能。profiling可以提供详细的性能数据,帮助开发者理解程序在执行过程中的资源消耗情况,如CPU时间、内存使用、磁盘I/O和网络I/O等。
在华为的ICT服务领域,profiling特指一种实现Host+Device侧丰富的性能数据采集和全景Timeline交互分析的能力。它展示Host+Device侧各项性能指标,帮助用户快速发现和定位AI应用的性能瓶颈,包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化。profiling支持Host+Device侧的资源利用可视化统计分析,具体包括Host侧CPU、Memory、Disk、Network利用率和Device侧APP工程的硬件和软件性能数据。

昇腾Mindstudio 调优软件栈有哪些
主要有msprof,mstt,pytorch profiler,mindspore profiler,tensorflow profiler。性能数据采集侧主要负责有6+3种采集方式,其中msprof是所有工具的基础,主要采集解析逻辑都是基于该工具实现。其次是三个主流框架测的工具采集实现,主要是将msprof的功能集成在PyTroch,Mindspore与Tensorflow框架中自带的profiler,从而实现更加便捷的性能数据采集与解析,剩下几种则是一些推理侧的性能采集方式。

Ascend PyTorch profiler 简介
Ascend PyTorch Profiler是针对PyTorch框架开发的性能数据采集和解析工具,通过在PyTorch训练脚本中插入Ascend PyTorch Profiler接口,执行训练的同时采集性能数据,完成训练后直接输出可视化的性能数据文件,提升了性能分析效率。
Ascend PyTorch Profiler接口可全面采集PyTorch训练场景下的性能数据,主要包括PyTorch层算子信息、CANN层算子信息、底层NPU算子信息、以及算子内存占用信息等,可以全方位分析PyTorch训练时的性能状态。
采集方式
采集方式一:通过with语句进行采集
import torch
import torch_npu
...
experimental_config = torch_npu.profiler._ExperimentalConfig(
export_type=torch_npu.profiler.ExportType.Text,
profiler_level=torch_npu.profiler.ProfilerLevel.Level0,
msprof_tx=False,
aic_metrics=torch_npu.profiler.AiCMetrics.AiCoreNone,
l2_cache=False,
op_attr=False,
data_simplification=False,
record_op_args=False
)
with torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=1),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"),
record_shapes=False,
profile_memory=False,
with_stack=False,
with_modules=False,
with_flops=False,
experimental_config=experimental_config) as prof:
for step in range(steps):
train_one_step(step, steps, train_loader, model, optimizer, criterion)
prof.step()采集方式二:start,stop方式进行采集
import torch
import torch_npu
...
experimental_config = torch_npu.profiler._ExperimentalConfig(
export_type=torch_npu.profiler.ExportType.Text,
profiler_level=torch_npu.profiler.ProfilerLevel.Level0,
msprof_tx=False,
aic_metrics=torch_npu.profiler.AiCMetrics.AiCoreNone,
l2_cache=False,
op_attr=False,
data_simplification=False,
record_op_args=False
)
prof = torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU,
torch_npu.profiler.ProfilerActivity.NPU
],
schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=1),
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"),
record_shapes=False,
profile_memory=False,
with_stack=False,
with_modules=False,
with_flops=False,
experimental_config=experimental_config)
prof.start()
for step in range(steps):
train_one_step()
prof.step()
prof.stop()开关控制
activities
CPU、NPU事件采集列表,Enum类型。取值为:
默认情况下两个开关同时开启。
record_shapes
算子的InputShapes和InputTypes,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
profile_memory
算子的内存占用情况,Bool类型。取值为:
with_stack
算子调用栈,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。
on_trace_ready
设置采集结束时执行的操作,Callable类型。通常选择tensorboard_trace_handler,该接口用于解析采集的Profiling数据。
experimental_config
该参数用于设置NPU上的一些专有采集配置项。
•profiler_level:设置NPU采集的Level,支持:
•torch_npu.profiler.ProfilerLevel.Level0(默认)
•torch_npu.profiler.ProfilerLevel.Level1
•torch_npu.profiler.ProfilerLevel.Level2
•data_simplification:数据精简开关,默认打开;
•aic_metrics:AI Core的性能指标采集项(高阶用户);
•l2_cache:l2 cache数据采集开关(性能膨胀);
•record_op_args:记录AOE组件算子Dump数据(不建议与Profiling功能一起使用)
交付件分析
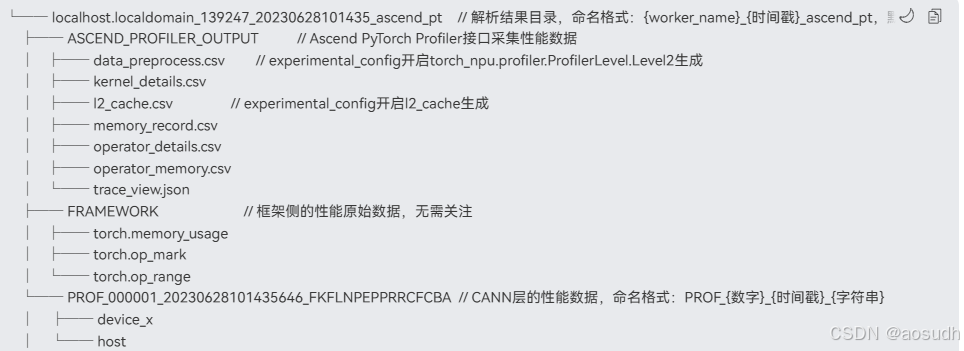

交付件可视化
前提条件
安装MindStudio Insight-安装和卸载操作(Windows)-安装与卸载-MindStudio Insight用户指南-MindStudio7.0.RC2开发文档-昇腾社区
安装Mindstudio insight 交付件可视化工具
已安装Python3,并完成执行环境的配置。
已获取采集到的原始集群数据,且单卡采集的数据中必须包含表1中的文件
处理数据(千卡以上场景,32节点内场景直接导入即可)
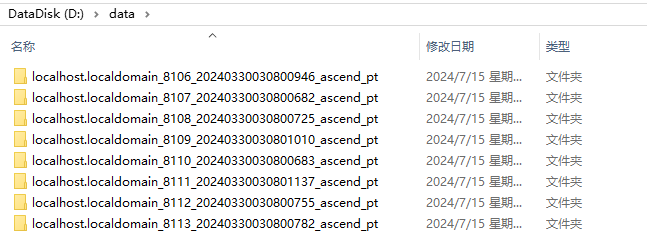
- 将所有以“ascend_pt”结尾的profiling原始数据汇总至同一个目录,如图1所示。
图1 数据汇总
- 在集群分析工具目录下,执行以下命令,解析数据,如图2所示。
python3 cluster_analysis.py -d { 原始数据存放路径}图2 解析数据

命令执行成功后,会在数据存放路径下,生成一个“cluster_analysis_output”目录,如图3所示,该目录中保存着数据解析后的结果文件,结果文件如表2所示。
图3 生成的目录
表2 cluster_analysis_output目录文件
数据类型
文件名
说明
TEXT
cluster_step_trace_time.csv
数据解析模式为communication_matrix、communication_time或all时均生成。
cluster_communication_matrix.json
数据解析模式为communication_matrix或all时生成。
cluster_communication.json
数据解析模式为communication_time或all时生成,主要为通信耗时数据。
communication_group.json
数据解析模式为communication_matrix、communication_time或all时均生成,记录通信域分组信息。
DB
cluster_analysis.db
解析analysis.db或ascend_pytorch_profiler_{rank_id}.db生成的文件。
- 将“cluster_analysis_output”目录导入MindStudio Insight工具进行分析。
分析数据
定位慢卡问题
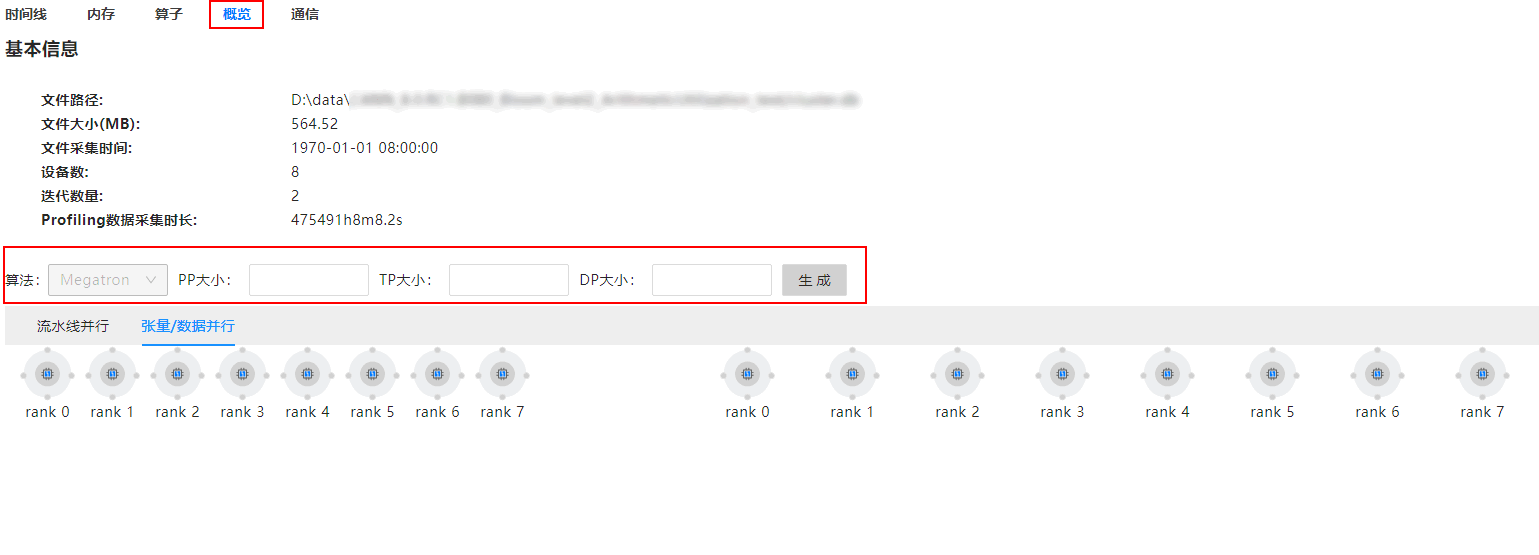
- 在概览(Summary)界面,输入模型脚本对应的并行策略值,如图1所示。其中PP为流水线并行(Pipeline Parallelism),TP为张量并行(Tensor Parallelism),DP为数据并行(Data Parallelism)。
图1 输入并行策略值
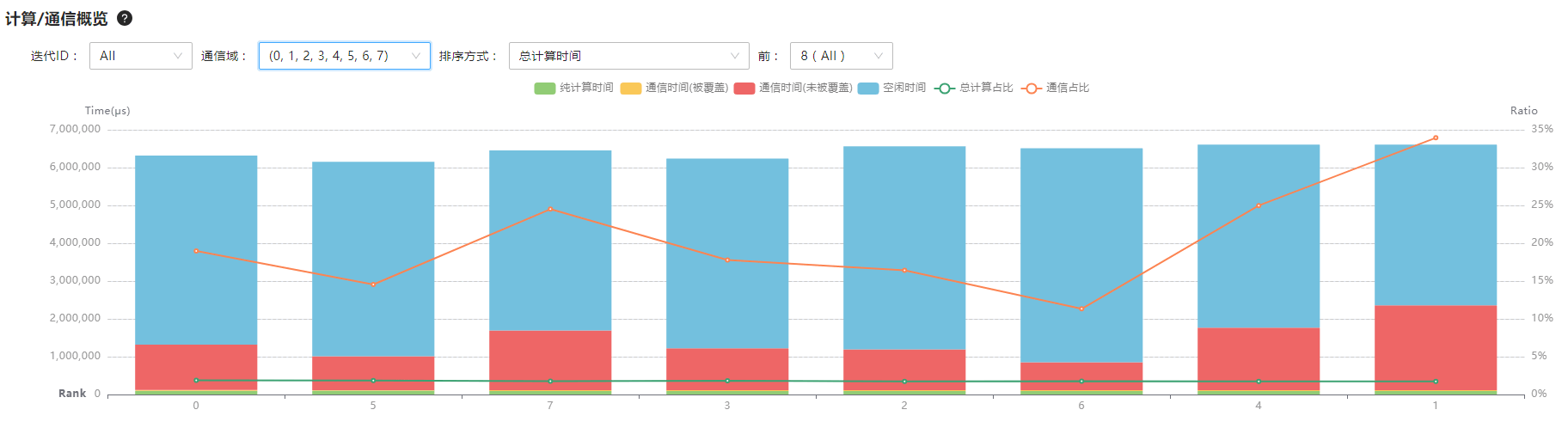
- 在“计算/通信概览”区域,分别选择“迭代ID”和“通信域”,查看柱状图,观察总计算时间和未被覆盖的通信时间时长,如图2所示。
慢卡通常表现为总计算耗时长,通信时间耗时短。
图2 查看计算与通信耗时
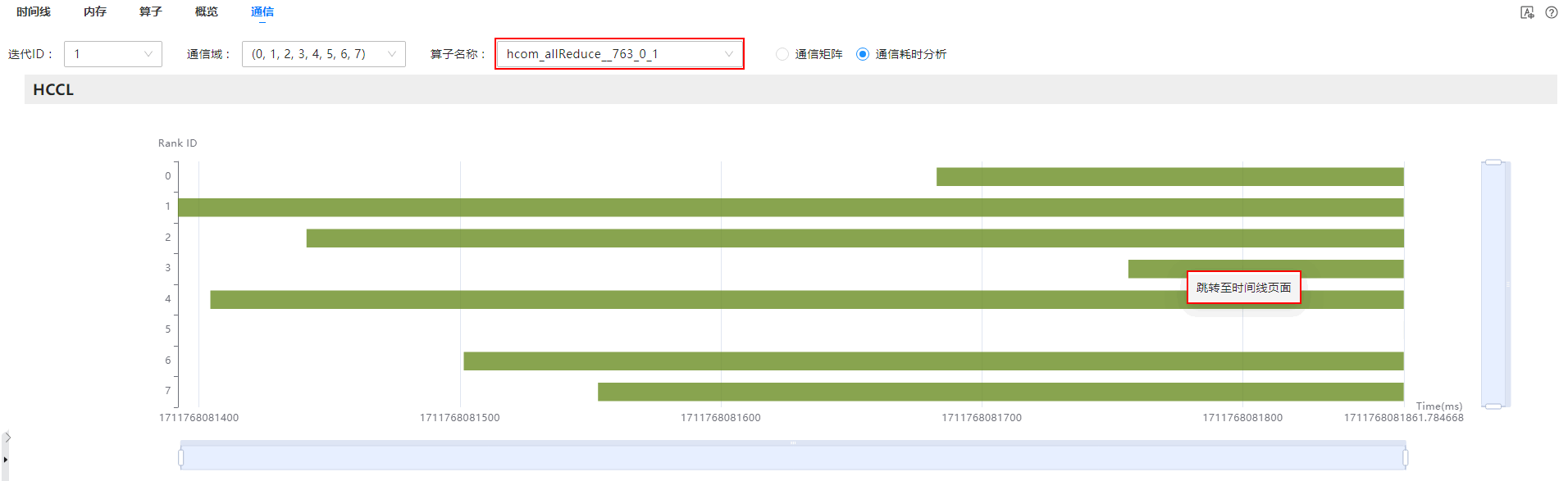
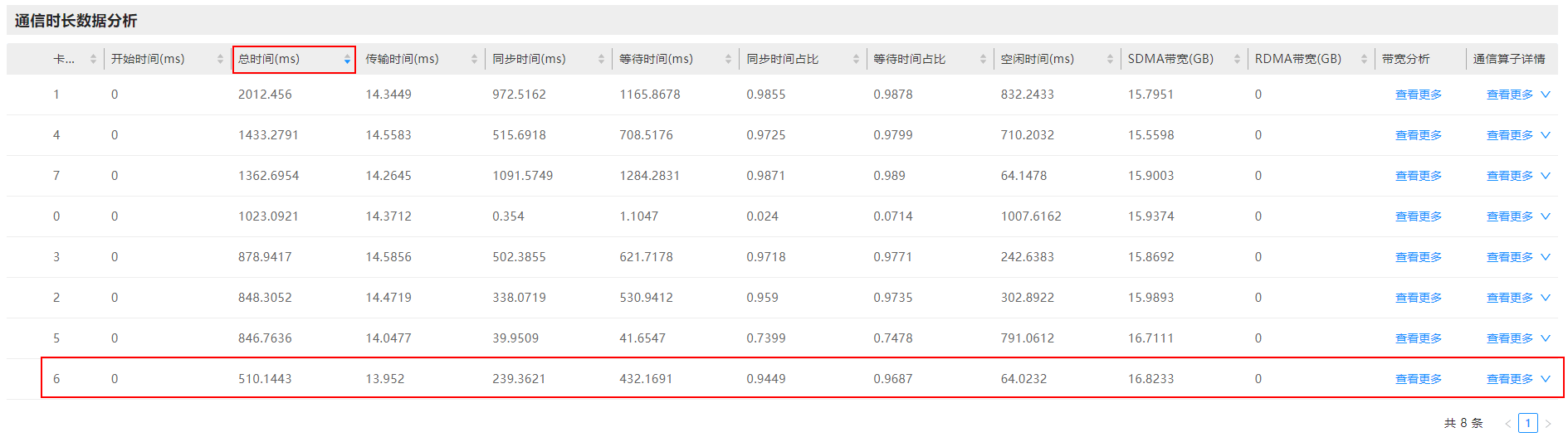
- 在通信(Communication)界面,选择“通信耗时分析”,并选择需要查看的“迭代ID”和“通信域”,在“通信时长数据分析”区域,查看所选通信域的各卡的“总时间(ms)”耗时情况。
- 单击“总时间(ms)”后的
,由大到小进行降序排序,如果发现时间差距很大的两张卡,那么耗时最短的卡即为慢卡,如图3所示。
图3 查看慢卡
- 单击慢卡“通信算子详情”列的“查看更多”,可查看每个通信算子耗时。
- 单击算子“总时间(ms)”后的
,进行降序排序,可以看到耗时最长的算子,如图4所示,复制该算子名称。
图4 查询算子
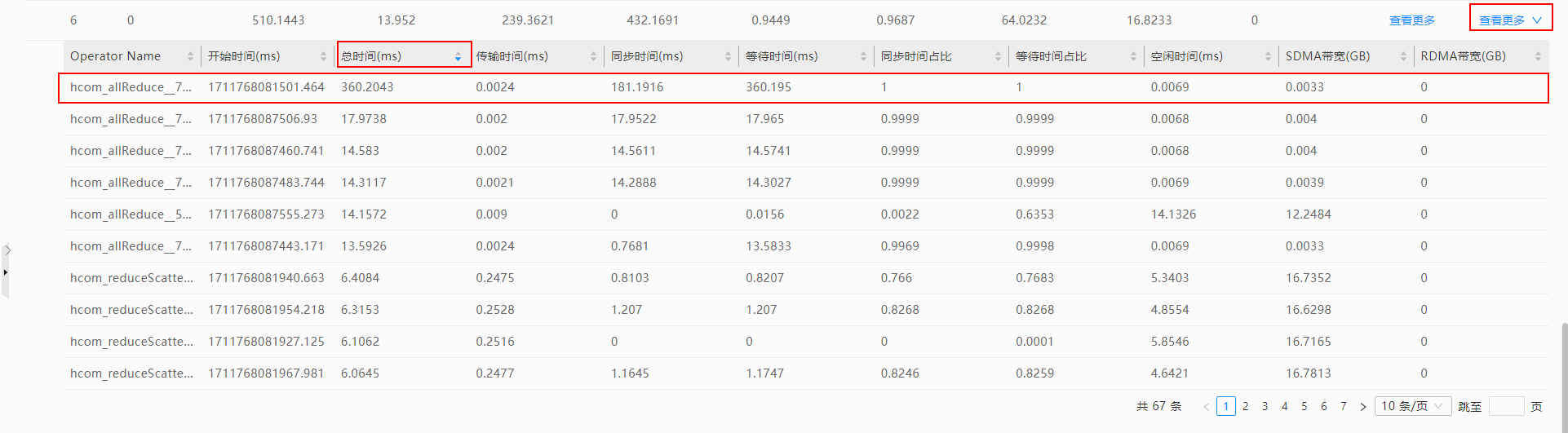
- 在通信(Communication)界面,参数配置区域的“算子名称”选项中粘贴已复制的算子名称,在下拉框选择该算子。
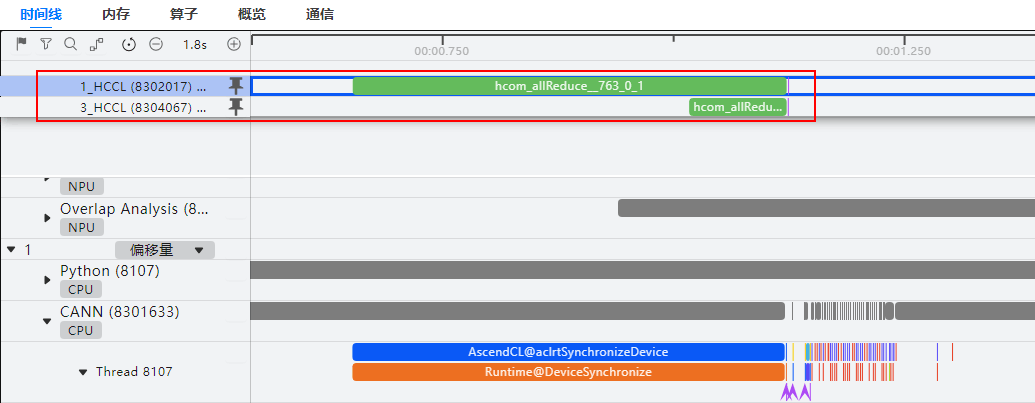
- 分别在“HCCL”和“通信时长”区域图表中,可看到该算子的耗时不对等,如图5所示,可判断是由慢卡引起的。获取图表中最快卡和最慢卡的原始数据目录,导入MindStudio Insight工具,在时间线(Timeline)界面进行具体分析。
图5 定位慢卡
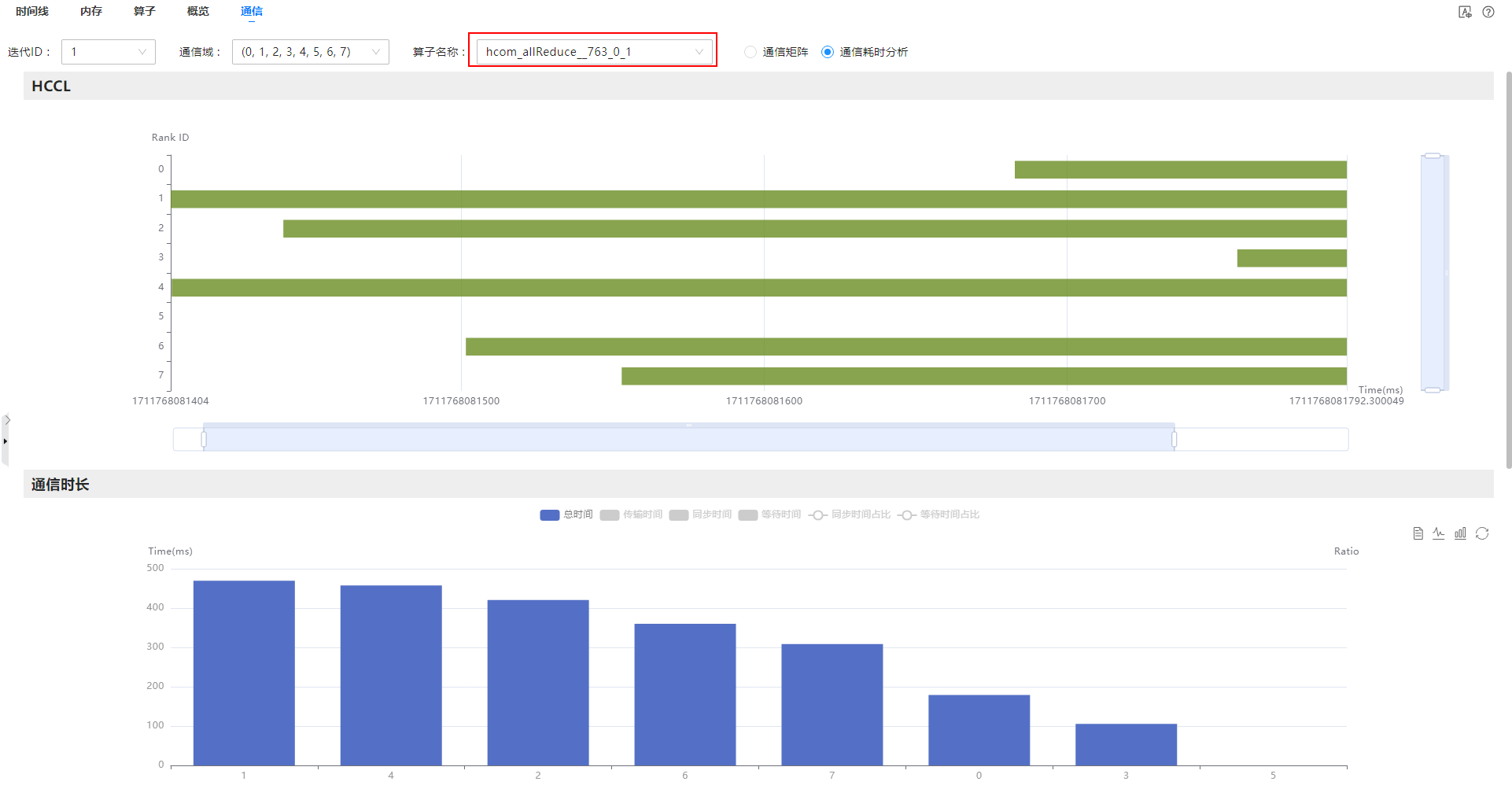
分析数据