一、简介
1、概念
DBSCAN算法由Martin Ester和Otkar Kiel在1996年提出,适用于发现数据中的聚类,特别是当聚类形状不规则或大小不一时。DBSCAN是一种基于密度的空间聚类算法,它能够将具有足够高密度的区域划分为簇,并能在具有噪声的数据集中发现任意形状的簇。DBSCAN 算法相比传统的 K-means 算法,不依赖于簇的形状,且能够识别并处理噪声点。
2、主要思想
DBSCAN算法的主要思想是将数据点分为三类:
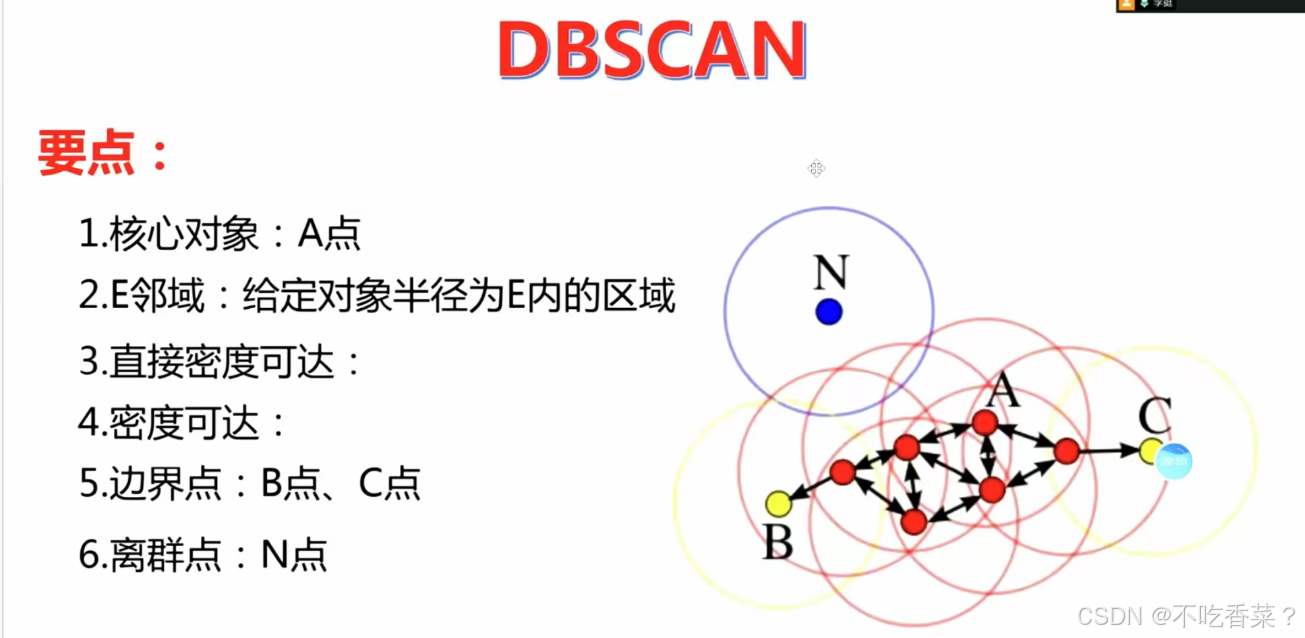
核心点(Core Point):在半径eps内至少有min_samples个点的点。
边界点(Border Point):在半径eps内少于min_samples个点,但落在核心点的邻域内的点。
噪声点(Noise Point):既不是核心点也不是边界点的点。
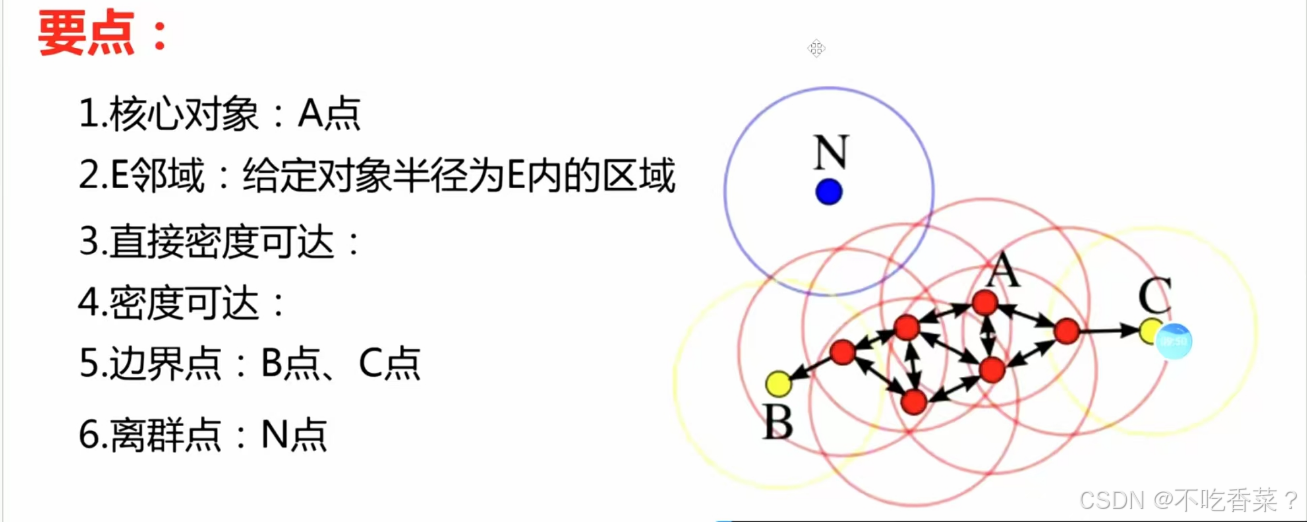
ε-邻域(ε-neighborhood):对于数据集 D 中的任何点,其 ε-邻域是 D 中与 点 距离小于等于 ε 的所有点的集合。
直接密度可达(Directly Density-Reachable):如果点 P 在点 Q 的 ε-邻域内,且 Q 是一个核心点,则称点 P 从点 Q 直接密度可达。
密度可达(Density-Reachable):如果存在一个点的序列 B,使得 B直接密度可达A,则称点B从点A密度可达。
密度相连(Density-Connected):如果存在点 A,使得点B和点C都从A密度可达,则称 P 和 Q 密度相连。
3、算法步骤
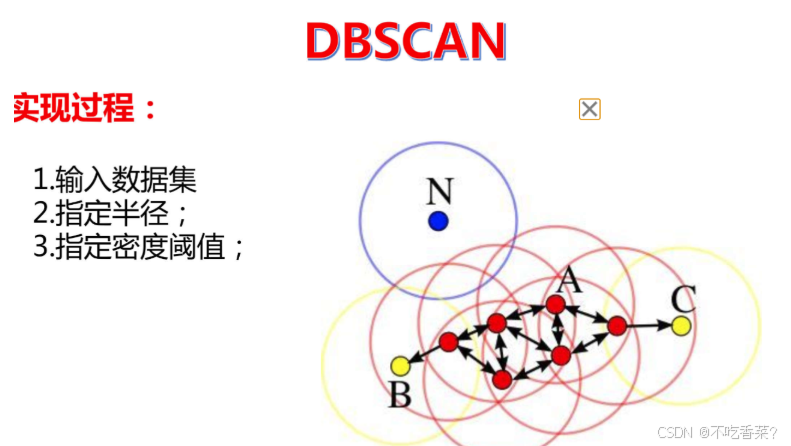
算法步骤
参数选择:选择两个参数,eps(邻域的最大半径)和min_samples(形成核心点所需的最小样本数)。
核心点识别:对于每个点,检查其eps邻域内是否至少有min_samples个点。如果是,则该点是核心点。
聚类形成:从任意核心点开始,递归地将邻域内的所有核心点和边界点加入到同一个聚类中。
噪声识别:那些既不是核心点也不是任何聚类中边界点的点被标记为噪声。
迭代处理:重复步骤3和4,直到所有点都被访问过。
二、代码实现
以下是文本data.txt的内容
name calories sodium alcohol cost
Budweiser 144 15 4.7 0.43
Schlitz 151 19 4.9 0.43
Lowenbrau 157 15 0.9 0.48
Kronenbourg 170 7 5.2 0.73
Heineken 152 11 5.0 0.77
Old_Milwaukee 145 23 4.6 0.28
Augsberger 175 24 5.5 0.40
Srohs_Bohemian_Style 149 27 4.7 0.42
Miller_Lite 99 10 4.3 0.43
Budweiser_Light 113 8 3.7 0.40
Coors 140 18 4.6 0.44
Coors_Light 102 15 4.1 0.46
Michelob_Light 135 11 4.2 0.50
Becks 150 19 4.7 0.76
Kirin 149 6 5.0 0.79
Pabst_Extra_Light 68 15 2.3 0.38
Hamms 139 19 4.4 0.43
Heilemans_Old_Style 144 24 4.9 0.43
Olympia_Goled_Light 72 6 2.9 0.46
Schlitz_Light 97 7 4.2 0.471、数据预处理
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn import metrics
#读取数据
beer = pd.read_table('data.txt',sep=' ',encoding='utf8',engine='python')
#传入变量(列名)
X = beer[["calories","sodium","alcohol","cost"]]pandas:用于数据处理和分析。
DBSCAN:用于实现基于密度的聚类算法
metrics用于评估聚类结果的质量。
pd.read_table:从文件 data.txt 中读取数据。
sep=' ':指定分隔符为空格。
encoding='utf8':指定文件编码为 UTF-8。
engine='python':使用 Python 引擎读取文件。
然后从beer中选择"calories","sodium","alcohol","cost"作为四个特征,这些特征将用于聚类分析。
2、DBSCAN聚类
db = DBSCAN(eps=20,min_samples=2).fit(X)#归一化
labels = db.labels_db = DBSCAN(eps=20,min_samples=2).fit(X)初始化DBSCAN聚类模型;
eps=20:设置邻域半径为 20,即两个样本之间的最大距离;
min_samples=2:设置核心点的最小邻居数量为 2。
fit(X):对特征数据 X 进行聚类
db.labels_:获取每个样本的聚类标签。当标签为 -1 表示该样本是噪声点(不属于任何簇),
其他标签表示样本所属的簇编号。
3、计算轮廓系数
beer['cluster_db']=labels
score = metrics.silhouette_score(X, beer.cluster_db)
print(score)将聚类标签 labels 添加到 beer 数据集中,新列名为 cluster_db
metrics.silhouette_score(X, beer.cluster_db):是用来计算轮廓系数,用于评估聚类结果的质量
X表示特征数据,beer.cluster_db表示聚类标签
轮廓系数的取值范围为 [-1, 1]:
接近 1 表示聚类结果好。
接近 -1 表示聚类结果差。
接近 0 表示聚类结果不明显。
4、运行结果
"C:\Program Files\Python310\python.exe" C:\CODE\机器学习\DBSCAN算法\DBSCAN.py
0.6731775046455796
Process finished with exit code 0说明聚类效果还可以。
三、算法总结
DBSCAN 的优点和缺点
优点:
不需要预先指定簇的数量。
能够发现任意形状的簇。
对噪声数据不敏感。
能够识别出噪声点。
缺点:
需要选择两个参数领域半径(eps)和最小样本数(min_samples),这可能需要一些实验来确定最佳值。
对于密度差异很大的数据集,可能难以找到合适的 ε 和 MinPts。
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。