Stable Diffusion**(SD)是AI绘画领域的一个核心模型,其能够进行文生图(txt2img)、图生图(img2img)、图像修复等多种图像任务(其实能够处理图像也就能处理视频)。通俗来说,只需把想要生成图片的文字描述、模板图片底图等作料输入到Stable Diffusion,加之其他模型的微调渲染便能生成符合要求的逼真图像)!SD被广泛使用的一个优势便是它的开源免费,但是上手难度和学习成本较高(背单词、会调参、懂代码配置…)【脑阔疼】,并且非常吃电脑配置(显卡、内存)【心在滴血】。总的来说就是技术开源**、物质烧钱、精神折磨,总不能所有好事被我们占了),技术开源就知足吧!!!本文主要介绍如何配置SD使用环境,最后使用文生图功能来检验是否配置成功。
☆ ☆ ☆ 硬 件 环 境 ☆ ☆ ☆
系统:最好是Windows系统(10/11)
内存:底线 8G,16G达及格线,上不封顶
显卡:底线 4G,6G达及格线,上不封顶
硬盘:500G以上,越多越好(用于存放模型)
总之配置越高后期出图速度越快、效果越好
☆ ☆ ☆ 软 件 环 境 ☆ ☆ ☆
目前有多位大佬(秋葉、星空yyds,配享万人敬仰)做出了便于小白用户使用的整合包,真正实现傻瓜式安装。软件主要运行环境为 Python 3.10.x,桌面运行库为 Microsoft Windows Desktop Runtime 6.0。
有需要stable diffusion整合包以及提示词插件,可以扫描下方,免费获取

☆ ☆ ☆ 目 录 & 模 型 介 绍 ☆ ☆ ☆
若只是使用 SD 的话,只需知道几个主要文件夹所代表的含义、模型能够生成的对象以及相关插件提供的功能即可。常用的主要有【models】和【extensions】两个文件夹,前者是用于存放我们要使用的模型文件【Checkpoint、Lora、VAE】等,后者则是一些扩展插件,主要用于辅助对生成内容进行调整和优化。
① Checkpoint — —
体积较大的主体模型(大模型),用于限定模型输出的主要风格,通常以G为单位,后缀名为safetensors/ckpt,该模型通常存放在root/models/Stable-diffusion路径下。
② Lora — —
体积较小的绘画模型(微调模型),通常为几百M,用于对大模型微调,其后缀名为safetensors,该模型通常存放在root/models/Lora路径下。
③ VAE *— —*
实现滤镜效果(优化模型),一般情况下已集成在大模型中,该模型通常存放在root/models/VAE路径下。
④ Controlnet *— —*
实现控制输出图像的姿态、轮廓、深度等(控制模型),这些模型通常存放在extensions\sd-webui-controlnet\models路径下。
—— 科学上网!科学上网!科学上网!——
☆ ☆ ☆ 软 件 使 用 ☆ ☆ ☆
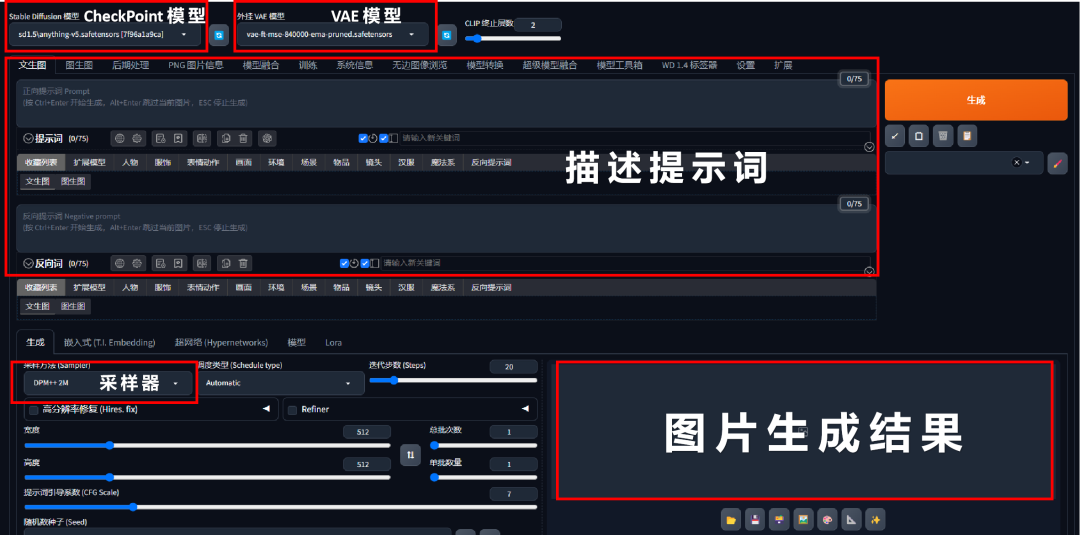
**Step-1:**选择要使用的大模型CheckPoint和VAE模型。
**Step-2:**输入正面/反面提示词。前者是你希望图片样子的提示词,后者为你不希望图片生成样子的提示词。【提示词要求为英文提示词,想要很好的使用SD,看来还是逃不了学英语了 】
】
正向提示词:positive
1boy,bust,hanfu,tang_style_outfits,lora:hanfuTang_v32:0.7,upper_body,light_smile,high_quality,masterpiece,simple_background
反向提示词:negative
hand_up,ugly,disfigured,poorly_drawn_face,skin_blemishes,skin_spots,mutated_hands,extra_arms,extra_limb,disconnected_limbs,floating_limbs,missing_fingers,fused_fingers,too_many_fingers,extra_legs,bad_feet,bad_hands,malformed_limbs,missing_limb,mutated,deformed
上述提示词表示我们希望得到的图像为穿着唐代(通过lora进行微调)风格的一个面带微笑小男孩的半身像,并且要求图片质量要高,生成的人物不丑、不出现畸形和肢体不协调问题,同时对手部位置进行了约束。
Step-3:最后点击生成按钮,稍等片刻便可得到你想要的图像。
(ps:提示词的语法并不是简单单词的堆叠和罗列,也可对一些提示词赋予权重,实现对输出图像内容的细节约束。哎学了英语还不行,还得按照特定语法格式撰写提示词,蜀道难难上加难!!)
*☆ ☆ ☆* SD 的实战效果 *☆ ☆ ☆*
 |
 |
|---|---|
 Stable Diffusion Create Portrait Stable Diffusion Create Portrait  |
|
 |
 |
| Stable Diffusion Draw Cartoon | |
 |
总 结 思 考
技术的更新换代就是如此之快,稍不留神我们便可能错失很多发展机遇。就像之前支付宝一样,开始被很多人嘲讽的一无是处,说它不可能作为一种支付手段在社会流通一样,如今却被每家每户所接受和使用 。每次技术的革新都会推动社会发生一次变革,尤其在人工智能被疯狂**“炒作”的今天(鱼龙混杂,好多人只把AI当做捞金的噱头,像秋神、星空这样把知识公开化,愿意借集体力量推动某一行业发展的人可谓是凤毛麟角
。每次技术的革新都会推动社会发生一次变革,尤其在人工智能被疯狂**“炒作”的今天(鱼龙混杂,好多人只把AI当做捞金的噱头,像秋神、星空这样把知识公开化,愿意借集体力量推动某一行业发展的人可谓是凤毛麟角 )。而我们当下所能做的就是如何通过人工来控制这份智能,让它真正把人从无效劳动中解放出来,使人们把更多的时间放在个人思维发散与创造力提升上,这背后价值和意义不正与【新质生产力】**有异曲同工之处吗?【适度使用SD真的会审美疲劳
)。而我们当下所能做的就是如何通过人工来控制这份智能,让它真正把人从无效劳动中解放出来,使人们把更多的时间放在个人思维发散与创造力提升上,这背后价值和意义不正与【新质生产力】**有异曲同工之处吗?【适度使用SD真的会审美疲劳
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!
 】
】