hello ,好久不见!
目录
1.void string::Insert(size_t pos, char ch)
2.void string::Insert(size_t pos, const char* str)
3.到底在哪里定义static const size_t npos ?
正文开始——
一、string实现时要注意的细节点
1.void string::Insert(size_t pos, char ch)
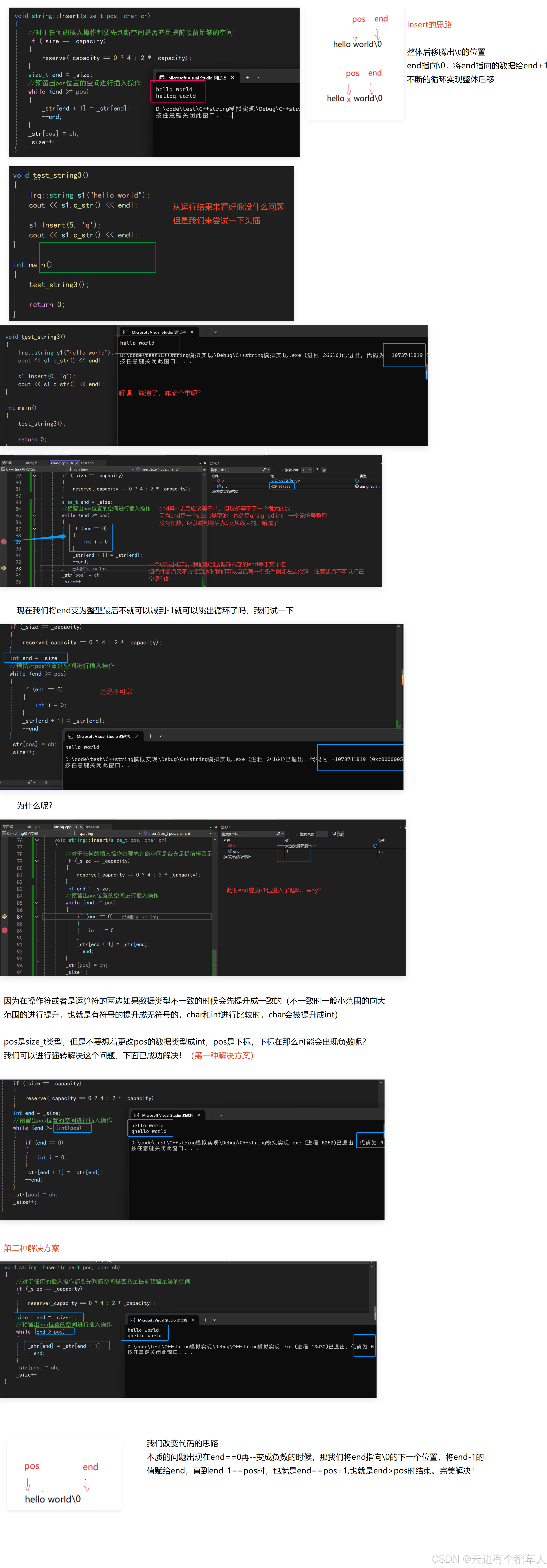
void string::Insert(size_t pos, char ch)
{
//对于任何的插入操作都要先判断空间是否充足提前预留足够的空间
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
size_t end = _size+1;
//预留出pos位置的空间进行插入操作
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
}2.void string::Insert(size_t pos, const char* str)
第一种方法
跟我们前面讲的很相似,利用强转来解决类型的问题
void string::Insert(size_t pos, const char* str)
{
//还是先扩容
size_t len = strlen(str);
if (_size + len > _capacity)
{
//扩容
size_t newCapacity = 2 * _capacity;
//扩2倍不够直接需要多少扩多少
if (newCapacity < _size + len)
newCapacity = _size + len;
reserve(newCapacity);
}
int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
end--;
}
//将str进行挨个插入
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = str[i];
}
_size += len;
}第二种方法
是将end-len移到end指向的数据
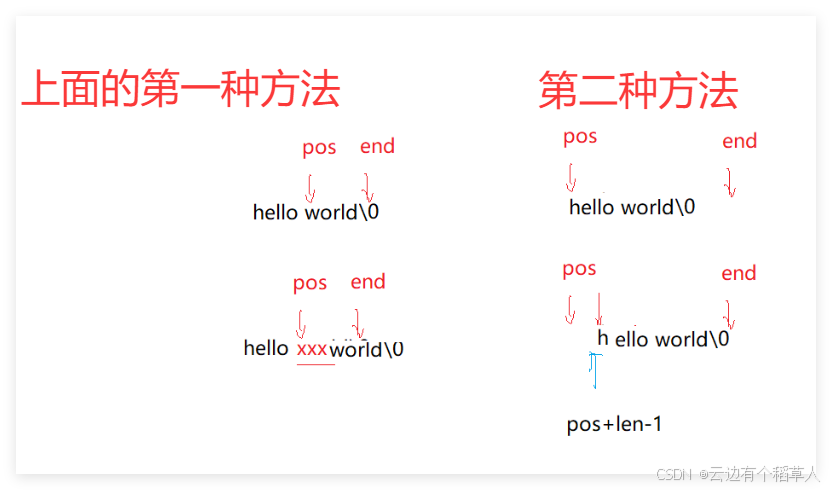
void string::Insert(size_t pos, const char* str)
{
//还是先扩容
size_t len = strlen(str);
if (_size + len > _capacity)
{
//扩容
size_t newCapacity = 2 * _capacity;
//扩2倍不够直接需要多少扩多少
if (newCapacity < _size + len)
newCapacity = _size + len;
reserve(newCapacity);
}
size_t end = _size + len;
while (end >= pos+len) //end-len==pos,end==pos+len,
{
_str[end] = _str[end-len];
end--;
}
//将str进行挨个插入
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = str[i];
}
_size += len;
}3.到底在哪里定义static const size_t npos ?
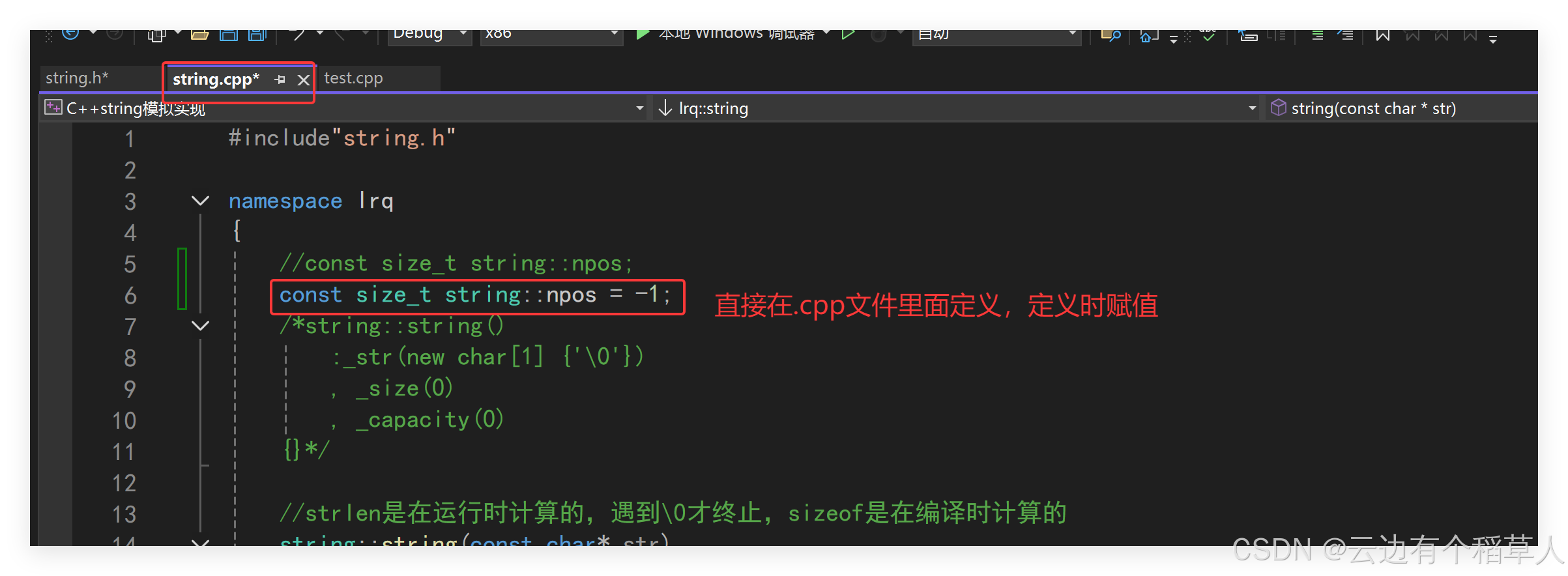
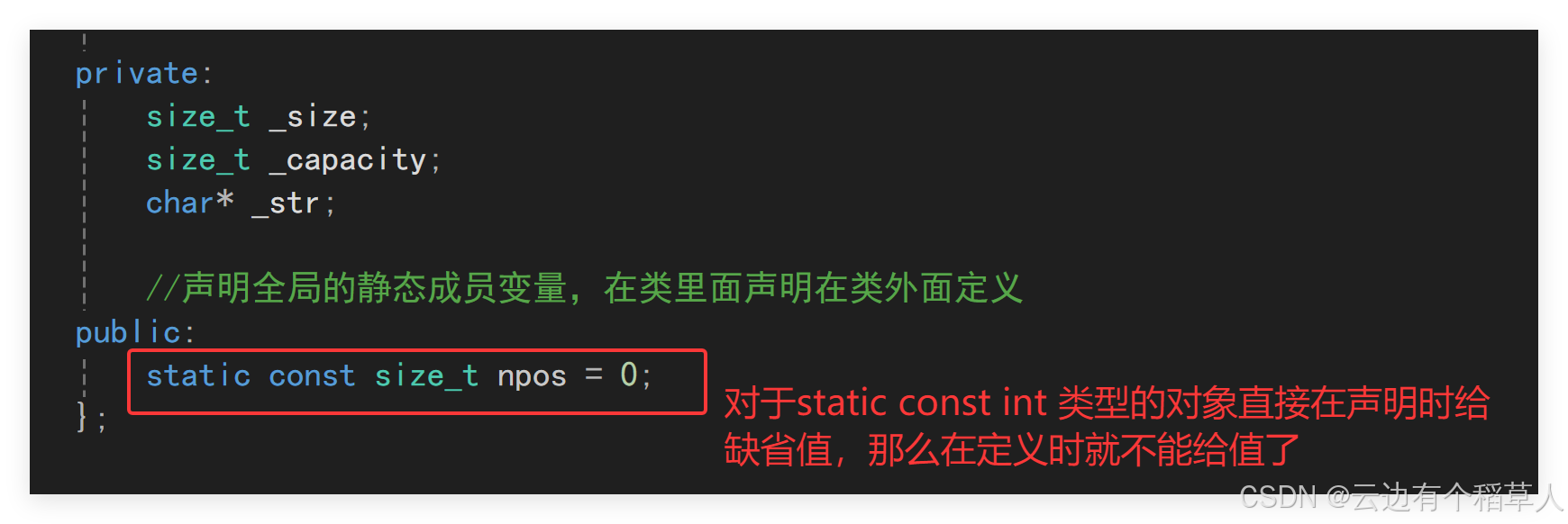
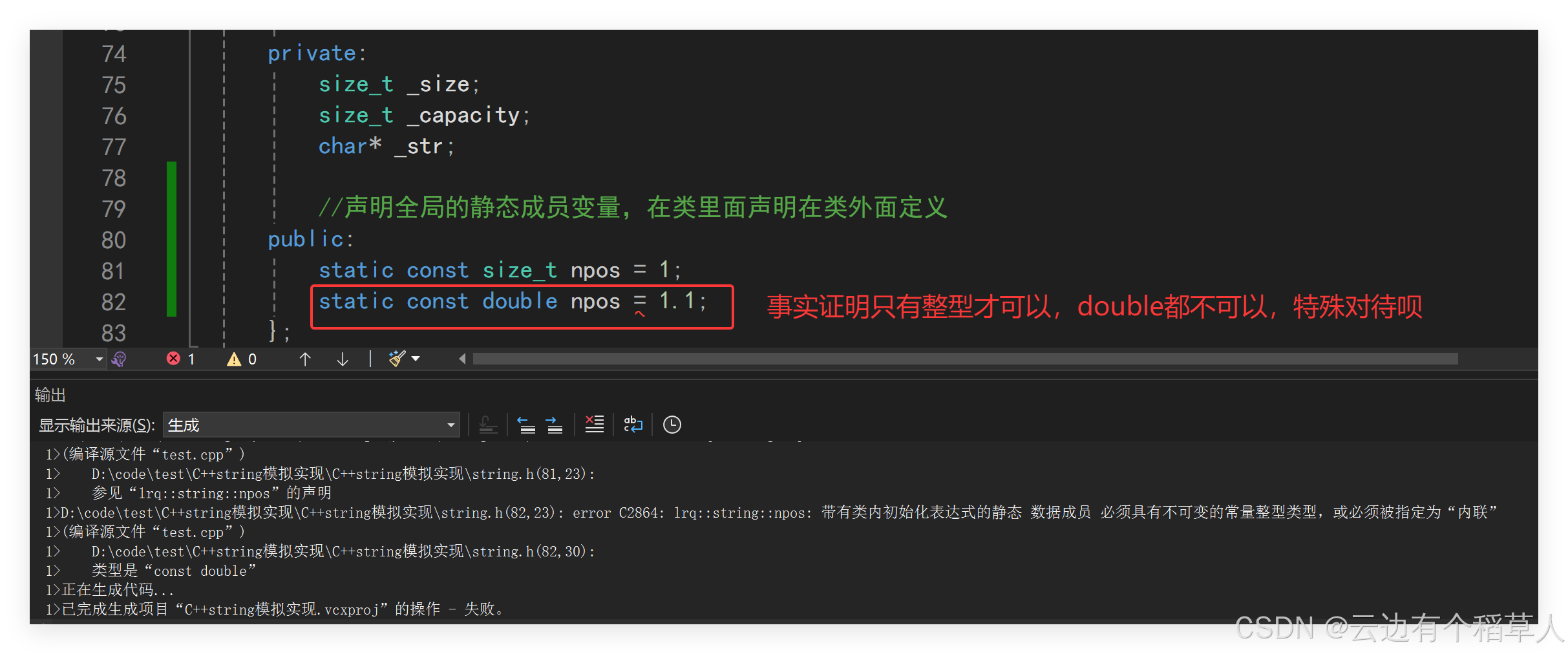
(1)所有的.c或者.cpp文件在编译链接的时候都会生成.o文件(VS下叫.obj文件),.h文件在预处理的时候就在两个.cpp文件里面展开了,我们在类域外面定义的npos就会在两个.cpp里面展开,当两个.cpp文件链接合并生成可执行程序的时候,就构成了下面报错里面的重定义,所以当静态成员变量定义和声明分离的时候要在.cpp文件里面定义,不能像以前那样在类里面声明在类外面定义。对于npos要加上const,不可修改。(2)同时npos要在定义的时候给值,对于const对象是只有定义时一次初始化的机会。(3)特殊的一点,对于静态的const(只有整型类型的数据才可以的,这算是一个特殊处理)成员变量可以在声明的时候给缺省值,那么在定义的时候就不可以再给值了。

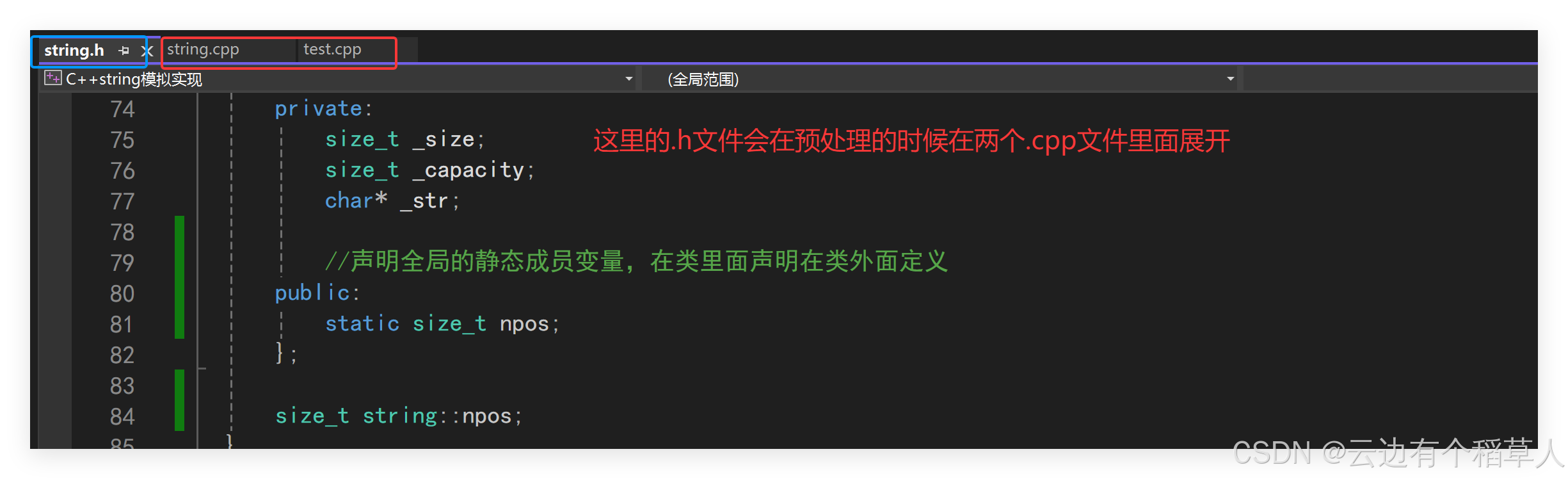
总结一下,对于这种情况有两种解决办法
4.实现取域名
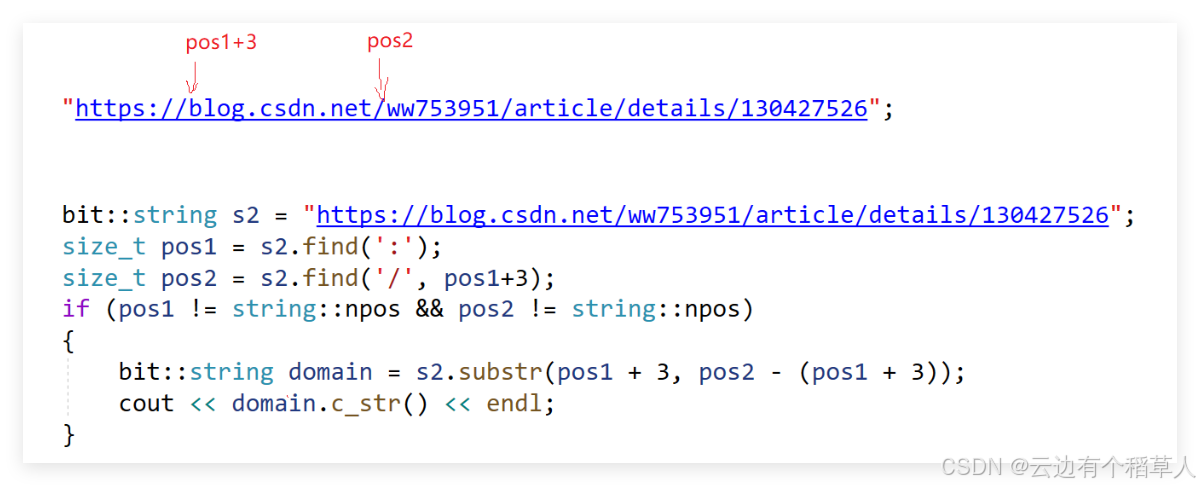
//取域名
void test_string4()
{
lrq::string s1 = "https://mpbeta.csdn.net/mp_blog/creation/editor/147116669?spm=1000.2115.3001.4503";
size_t pos1 = s1.find(':');
size_t pos2 = s1.find('/', pos1 + 3);
//判断是否找到目标字符
if (pos1 != string::npos && pos2 != string::npos)//npos受类域影响
{
lrq::string domain = s1.substr(pos1 + 3, pos2 - (pos1 + 3));//注意pos1和pos2到底指向哪些个位置
cout << domain.c_str() << endl;
}
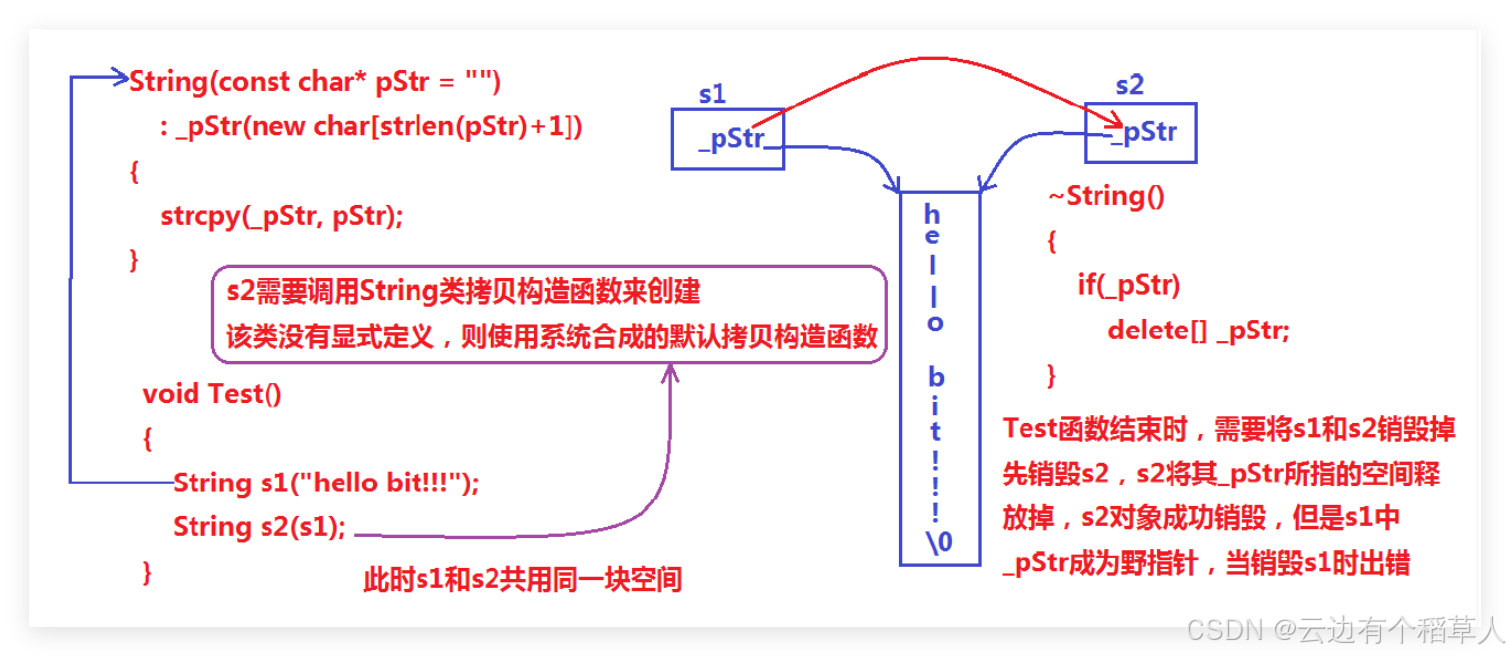
}5.拷贝—拷贝构造和赋值
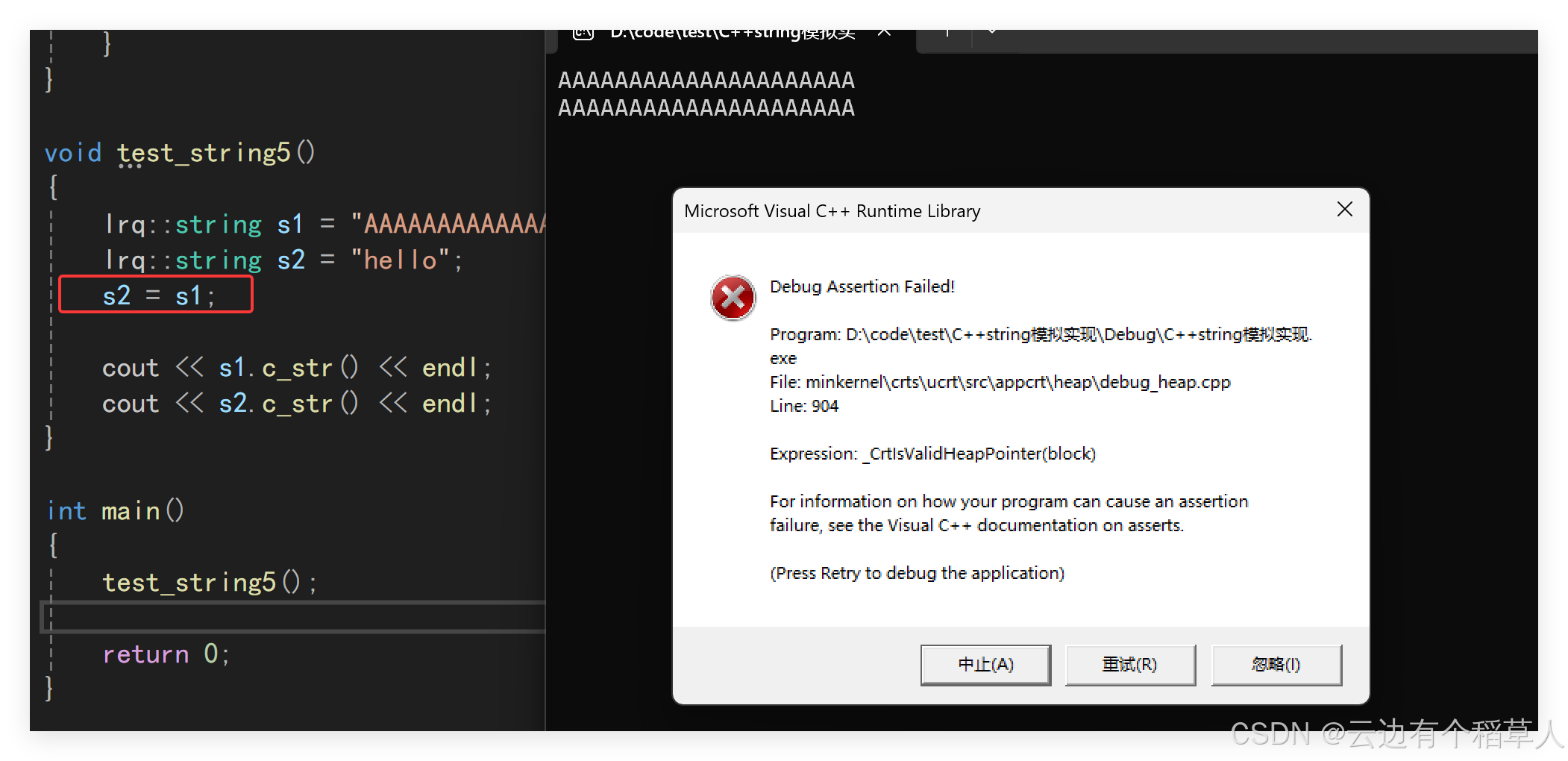
我们不显示写拷贝构造和赋值拷贝(都是一种赋值行为),编译器默认都会进行浅拷贝。(1)像上面的代码将s1拷贝赋值给s2,编译器默认的浅拷贝会导致s2和s1指向同一块空间,函数结束的时候会先析构s2再析构s1导致同一块空间析构两次就会出现上面的运行崩溃;(2)还会导致内存泄漏,s2之前的空间没有得到释放。(如果一个类需要显示写析构,那么一般就需要写拷贝构造和赋值)

//s1 = s3
string& string::operator=(const string& s)
{
if (this != &s)
{
//上来先将s1给释放掉
delete[] _str;
_str = new char[s._capacity + 1];//预留一个\0的空间
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
return *this;
}6.流插入
我们输入的是abcd efg,中间包含一个空格字符,但是ch好像并没有从缓冲区里面提取到空格,看下图,记住,cin在直接使用流提取的时候无论输入任何类型,int,char,它都会默认忽略掉空格和换行,规定认为空格和换行都是多个值之间的分割,也就无法判断什么时候结束,所以我们要进行代码的修改。
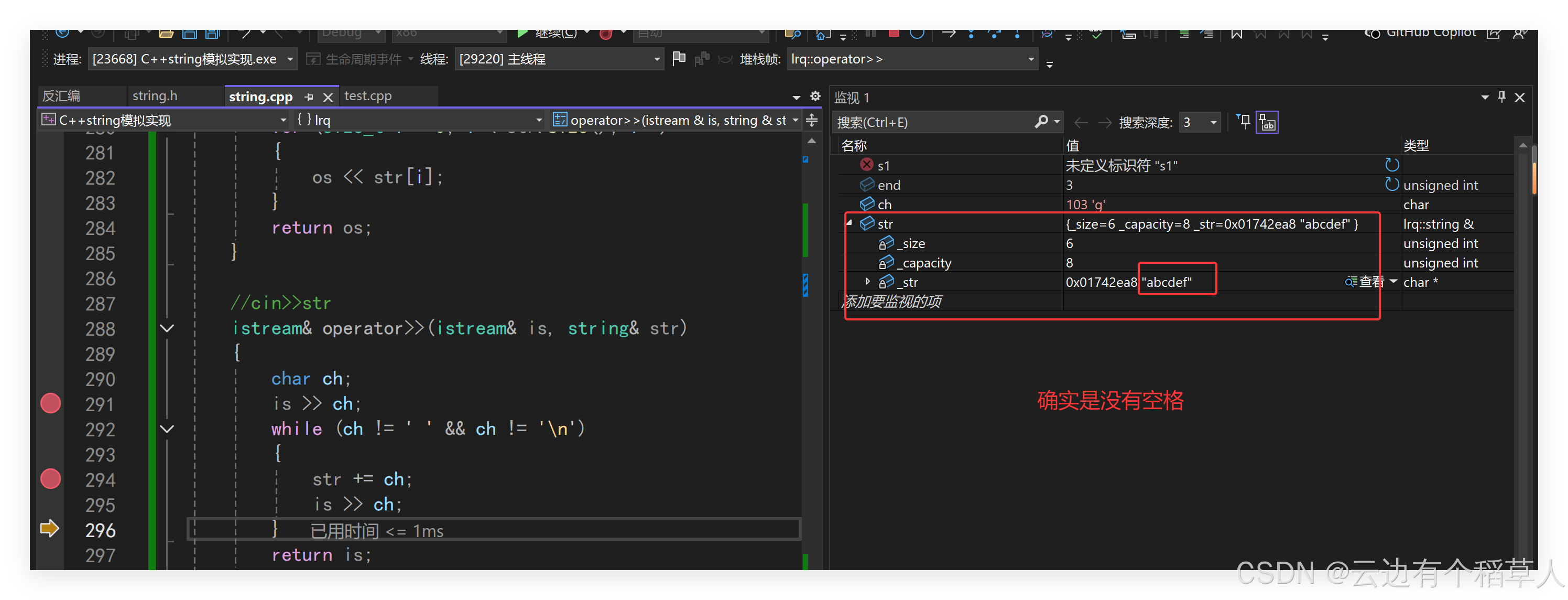
我们使用istream类里面的get,可以提取到空格和换行


//cin>>str,这个实现的功能和前面讲的getline很像,只不过结束字符不同而已,我们要融会贯通一下
istream& operator>>(istream& is, string& str)
{
str.clear();//清空str里面原来的字符,否则会继续加在str上面,这是实现和STL里面的string::>>一样的效果
char ch;
ch = is.get();
while (ch != ' ' && ch != '\n')
{
str += ch;
ch = is.get();
}
return is;
}优化一下:
istream& operator>>(istream& is, string& str)
{
str.clear();
int i = 0;
char buff[256];
char ch;
ch = is.get();
while (ch != ' ' && ch != '\n')
{
// 放到buff
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0)
{
buff[i] = '\0';
str += buff;
}
return is;
}7.三个swap

二、
2.1 经典的string类问题
// 为了和标准库区分,此处使用String
class String
{
public:
/*String()
:_str(new char[1])
{*_str = '\0';}
*/
//String(const char* str = "\0") 错误示范
//String(const char* str = nullptr) 错误示范
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
// 测试
void TestString()
{
String s1("hello bit!!!");
String s2(s1);
}
2.2 浅拷贝

2.3 深拷贝

(1)【传统版写法的String类】
class String
{
public:
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* pStr = new char[strlen(s._str) + 1];
strcpy(pStr, s._str);
delete[] _str;
_str = pStr;
}
return *this;
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};(2)【现代版写法的String类】
class String
{
public:
String(const char* str = "")
{
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(nullptr)
{
String strTmp(s._str);
swap(_str, strTmp._str);
}
// 对比下和上面的赋值那个实现比较好?
String& operator=(String s)
{
swap(_str, s._str);
return *this;
}
/*
String& operator=(const String& s)
{
if(this != &s)
{
String strTmp(s);
swap(_str, strTmp._str);
}
return *this;
}
*/
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};(3)【写时拷贝】(了解)
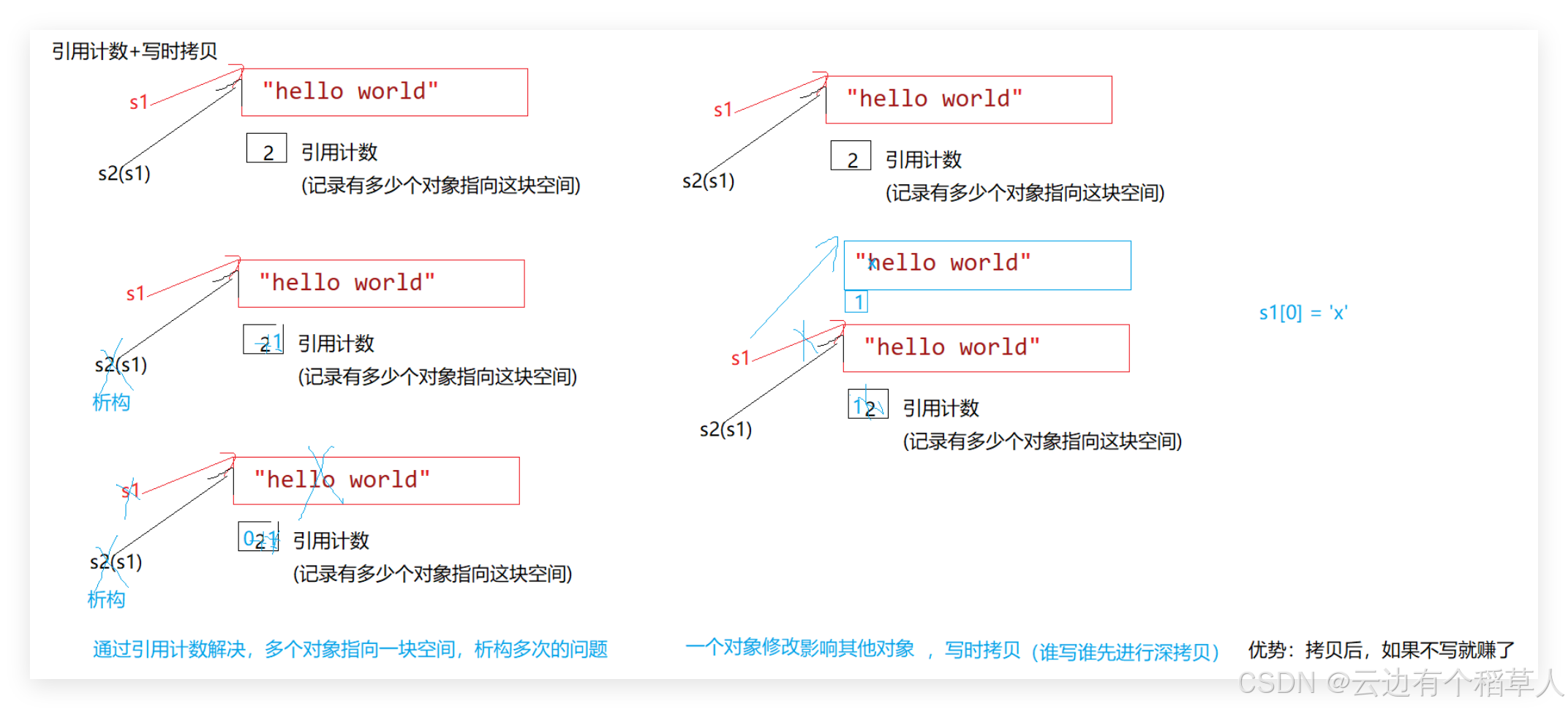
(4)扩展阅读
(5)编码
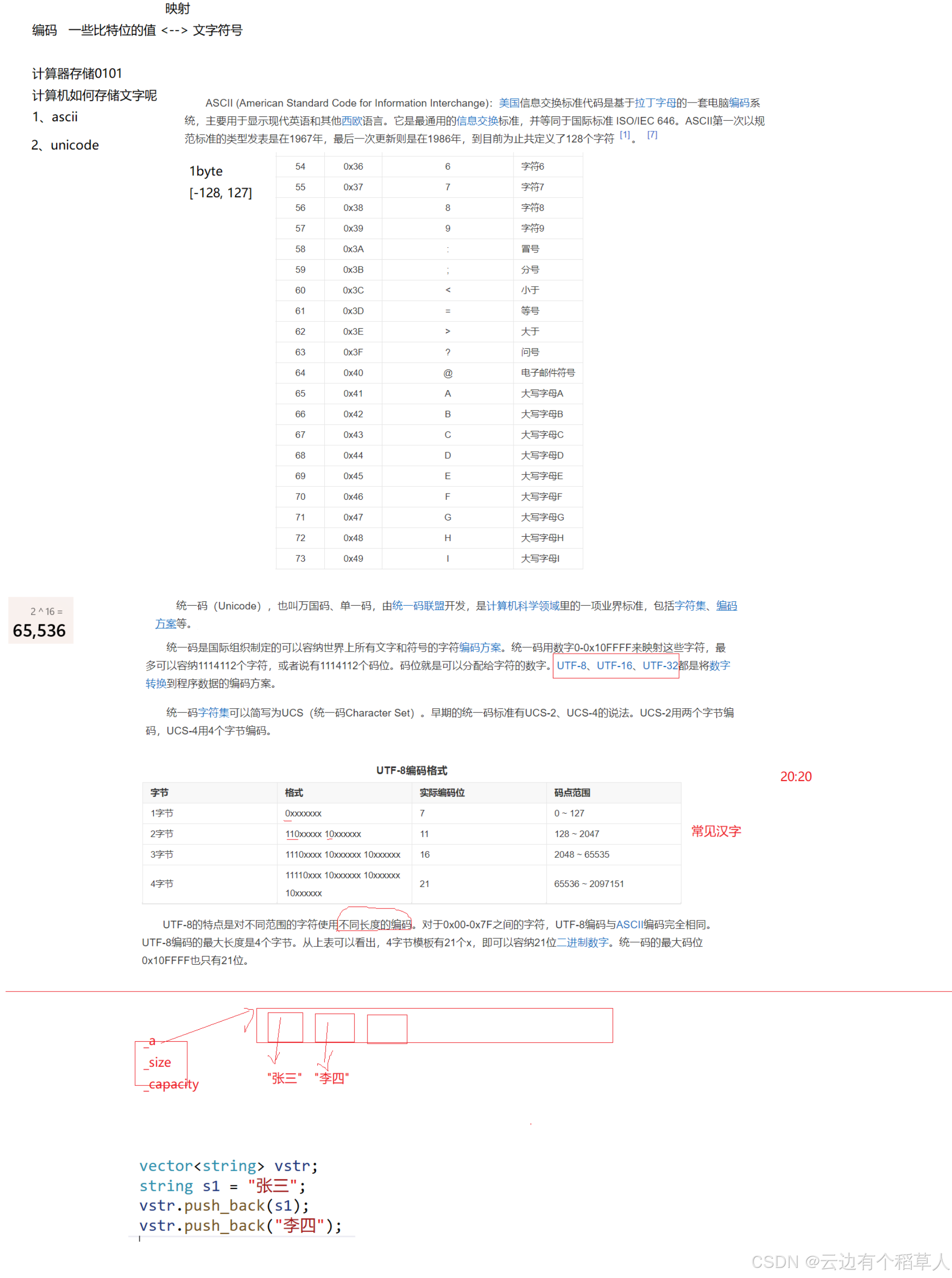
三、综合代码
string.h
#define _CRT_SECURE_NO_WARNINGS 1
#pragma once
#include<iostream>
#include<assert.h>
using namespace std;
namespace bit
{
class string
{
public:
//typedef char* iterator;
using iterator = char*;
using const_iterator = const char*;
//string();
string(const char* str = "");
string(const string& s);
string& operator=(string s);
~string();
void reserve(size_t n);
void push_back(char ch);
void append(const char* str);
string& operator+=(char ch);
string& operator+=(const char* str);
void insert(size_t pos, char ch);
void insert(size_t pos, const char* str);
void erase(size_t pos, size_t len = npos);
size_t find(char ch, size_t pos = 0);
size_t find(const char* str, size_t pos = 0);
char& operator[](size_t i)
{
assert(i < _size);
return _str[i];
}
const char& operator[](size_t i) const
{
assert(i < _size);
return _str[i];
}
iterator begin()
{
return _str;
}
iterator end()
{
return _str+_size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
size_t size() const
{
return _size;
}
const char* c_str() const
{
return _str;
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
void swap(string& s);
string substr(size_t pos, size_t len = npos);
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
public:
//
//static const size_t npos = -1;
static const size_t npos;
};
void swap(string& s1, string& s2);
bool operator== (const string& lhs, const string& rhs);
bool operator!= (const string& lhs, const string& rhs);
bool operator> (const string& lhs, const string& rhs);
bool operator< (const string& lhs, const string& rhs);
bool operator>= (const string& lhs, const string& rhs);
bool operator<= (const string& lhs, const string& rhs);
ostream& operator<<(ostream& os, const string& str);
istream& operator>>(istream& is, string& str);
istream& operator>>(istream& is, string& str);
istream& getline(istream& is, string& str, char delim = '\n');
}string.cpp
#include"string.h"
namespace bit
{
const size_t string::npos = -1;
// 11:52
/*string::string()
:_str(new char[1]{ '\0' })
, _size(0)
, _capacity(0)
{}*/
string::string(const char* str)
:_size(strlen(str))
{
_capacity = _size;
_str = new char[_size + 1];
strcpy(_str, str);
}
// 传统写法
// s2(s1)
/*string::string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}*/
// s2(s1)
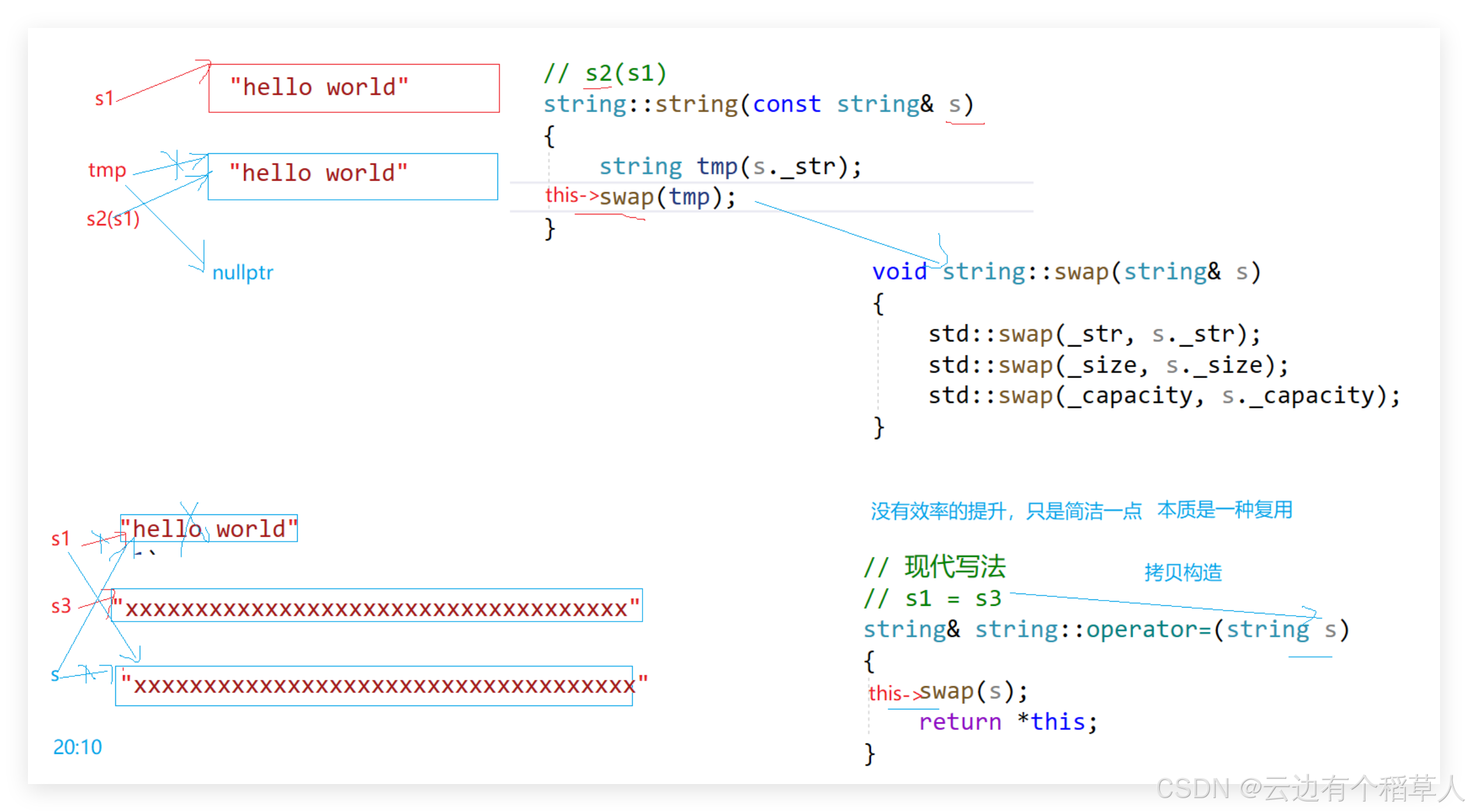
// 现代写法
string::string(const string& s)
{
string tmp(s._str);
swap(tmp);
}
// s2 = s1 = s3
// s1 = s1;
// 传统写法
/*string& string::operator=(const string& s)
{
if (this != &s)
{
delete[] _str;
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
return *this;
}*/
// 现代写法
// s1 = s3
string& string::operator=(string s)
{
swap(s);
return *this;
}
string::~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
void string::reserve(size_t n)
{
if (n > _capacity)
{
//cout << "reserve:" << n << endl;
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void string::push_back(char ch)
{
/*if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;*/
insert(_size, ch);
}
void string::append(const char* str)
{
//size_t len = strlen(str);
//if (_size + len > _capacity)
//{
// size_t newCapacity = 2 * _capacity;
// // 扩2倍不够,则需要多少扩多少
// if (newCapacity < _size + len)
// newCapacity = _size + len;
// reserve(newCapacity);
//}
//strcpy(_str + _size, str);
//_size += len;
insert(_size, str);
}
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
void string::insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
/*int end = _size;
while (end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}*/
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
}
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
size_t newCapacity = 2 * _capacity;
// 扩2倍不够,则需要多少扩多少
if (newCapacity < _size + len)
newCapacity = _size + len;
reserve(newCapacity);
}
/*int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
--end;
}*/
size_t end = _size + len;
while (end > pos + len - 1)
{
_str[end] = _str[end - len];
--end;
}
for (size_t i = 0; i < len; i++)
{
_str[pos + i] = str[i];
}
_size += len;
}
void string::erase(size_t pos, size_t len)
{
assert(pos < _size);
if (len >= _size - pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
// 从后往前挪
size_t end = pos + len;
while (end <= _size)
{
_str[end - len] = _str[end];
++end;
}
_size -= len;
}
}
size_t string::find(char ch, size_t pos)
{
assert(pos < _size);
for (size_t i = pos; i < _size; i++)
{
if (ch == _str[i])
return i;
}
return npos;
}
size_t string::find(const char* str, size_t pos)
{
assert(pos < _size);
const char* ptr = strstr(_str + pos, str);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
string string::substr(size_t pos, size_t len)
{
assert(pos < _size);
// 大于后面剩余串的长度,则直接取到结尾
if (len > (_size - pos))
{
len = _size - pos;
}
bit::string sub;
sub.reserve(len);
for (size_t i = 0; i < len; i++)
{
sub += _str[pos + i];
}
//cout << sub.c_str() << endl;
return sub;
}
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
void swap(string& s1, string& s2)
{
s1.swap(s2);
}
bool operator== (const string& lhs, const string& rhs)
{
return strcmp(lhs.c_str(), rhs.c_str()) == 0;
}
bool operator!= (const string& lhs, const string& rhs)
{
return !(lhs == rhs);
}
bool operator> (const string& lhs, const string& rhs)
{
return !(lhs <= rhs);
}
bool operator< (const string& lhs, const string& rhs)
{
return strcmp(lhs.c_str(), rhs.c_str()) < 0;
}
bool operator>= (const string& lhs, const string& rhs)
{
return !(lhs < rhs);
}
bool operator<= (const string& lhs, const string& rhs)
{
return lhs < rhs || lhs == rhs;
}
ostream& operator<<(ostream& os, const string& str)
{
//os<<'"';
//os << "xx\"xx";
for (size_t i = 0; i < str.size(); i++)
{
//os << str[i];
os << str[i];
}
//os << '"';
return os;
}
istream& operator>>(istream& is, string& str)
{
str.clear();
int i = 0;
char buff[256];
char ch;
ch = is.get();
while (ch != ' ' && ch != '\n')
{
// 放到buff
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0)
{
buff[i] = '\0';
str += buff;
}
return is;
}
istream& getline(istream& is, string& str, char delim)
{
str.clear();
int i = 0;
char buff[256];
char ch;
ch = is.get();
while (ch != delim)
{
// 放到buff
buff[i++] = ch;
if (i == 255)
{
buff[i] = '\0';
str += buff;
i = 0;
}
ch = is.get();
}
if (i > 0)
{
buff[i] = '\0';
str += buff;
}
return is;
}
}test.cpp
#include"string.h"
void test_string1()
{
bit::string s2;
cout << s2.c_str() << endl;
bit::string s1("hello world");
cout << s1.c_str() << endl;
s1[0] = 'x';
cout << s1.c_str() << endl;
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
cout << endl;
// 迭代器 -- 像指针一样的对象
bit::string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
(*it1)--;
++it1;
}
cout << endl;
it1 = s1.begin();
while (it1 != s1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
// 修改
// 底层是迭代器的支持
// 意味着支持迭代器就支持范围for
for (auto& ch : s1)
{
ch++;
}
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
const bit::string s3("xxxxxxxxx");
for (auto& ch : s3)
{
//ch++;
cout << ch << " ";
}
cout << endl;
}
void test_string2()
{
bit::string s1("hello world");
cout << s1.c_str() << endl;
s1 += '#';
s1 += "#hello world";
cout << s1.c_str() << endl;
bit::string s2("hello world");
cout << s2.c_str() << endl;
s2.insert(6, 'x');
cout << s2.c_str() << endl;
s2.insert(0, 'x');
cout << s2.c_str() << endl;
bit::string s3("hello world");
cout << s3.c_str() << endl;
s3.insert(6, "xxx");
cout << s3.c_str() << endl;
s3.insert(0, "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
cout << s3.c_str() << endl;
}
void test_string3()
{
bit::string s1("hello world");
cout << s1.c_str() << endl;
s1.erase(6, 2);
cout << s1.c_str() << endl;
s1.erase(5, 20);
cout << s1.c_str() << endl;
s1.erase(3);
cout << s1.c_str() << endl;
}
void test_string4()
{
bit::string s1("hello world");
cout << s1.find(' ') << endl;
cout << s1.find("wo") << endl;
bit::string s2 = "https://legacy.cplusplus.com/reference/cstring/strstr/?kw=strstr";
//bit::string s2 = "https://blog.csdn.net/ww753951/article/details/130427526";
size_t pos1 = s2.find(':');
size_t pos2 = s2.find('/', pos1+3);
if (pos1 != string::npos && pos2 != string::npos)
{
bit::string domain = s2.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << domain.c_str() << endl;
bit::string uri = s2.substr(pos2+1);
cout << uri.c_str() << endl;
}
}
void test_string5()
{
bit::string s1("hello world");
bit::string s2(s1);
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
s1[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
bit::string s3("xxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
s1 = s3;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
s1 = s1;
cout << s1.c_str() << endl;
}
void test_string6()
{
//bit::string s1("hello world");
//bit::string s2(s1);
//bit::string s3 = s1;
构造+拷贝 ->优化直接构造
//bit::string s4 = "hello world";
//cout << (s1 == s2) << endl;
//cout << (s1 < s2) << endl;
//cout << (s1 > s2) << endl;
//cout << (s1 == "hello world") << endl;
//cout << ("hello world" == s1) << endl;
operator<<(cout, s1);
//cout << s1 << endl;
//cin >> s1;
//cout << s1 << endl;
//
//std::string ss1("hello world");
//cin >> ss1;
//cout << ss1 << endl;
bit::string s1;
//cin >> s1;
//cout << s1 << endl;
getline(cin, s1);
cout << s1 << endl;
getline(cin, s1, '#');
cout << s1 << endl;
}
//void test_string7()
//{
// bit::string s1("hello world");
// bit::string s2("xxxxxxxxxxxxxxxxxxxxxxx");
//
// //swap(s1, s2);
// s1.swap(s2);
// cout << s1 << endl;
// cout << s2 << endl;
//}
void test_string8()
{
bit::string s1("hello world");
bit::string s2(s1);
bit::string s3("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx");
s1 = s3;
cout << s1 << endl;
cout << s3 << endl;
char arr1[] = "types";
char16_t arr2[] = u"types";
char32_t arr3[] = U"types";
wchar_t arr4[] = L"types";
cout << sizeof(arr1) << endl;
cout << sizeof(arr2) << endl;
cout << sizeof(arr3) << endl;
cout << sizeof(arr4) << endl;
char arr5[] = "苹果 apple";
cout << sizeof(arr5) << endl;
arr5[1]++;
arr5[1]++;
arr5[1]--;
arr5[1]--;
arr5[1]--;
arr5[1]--;
arr5[3]--;
arr5[3]--;
arr5[3]--;
}
//int main()
//{
// test_string8();
//
// return 0;
//}
#include<vector>
int main()
{
vector<int> v1;
vector<int> v2(10, 1);
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
// 遍历
for (size_t i = 0; i < v1.size(); i++)
{
cout << v1[i] << " ";
}
cout << endl;
vector<int>::iterator it1 = v1.begin();
while (it1 != v1.end())
{
cout << *it1 << " ";
++it1;
}
cout << endl;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
vector<string> vstr;
string s1 = "张三";
vstr.push_back(s1);
vstr.push_back("李四");
for (const auto& e : vstr)
{
cout << e << " ";
}
cout << endl;
vstr[0] += 'x';
vstr[0] += "apple";
//vstr[0][0]++;
vstr[0][1]++;
vstr[0][1]++;
vstr.operator[](0).operator[](1)++;
for (const auto& e : vstr)
{
cout << e << " ";
}
cout << endl;
return 0;
}完——
下次继续吧。。。vector

至此结束!
我是云边有个稻草人
期待与你的下一次相遇!