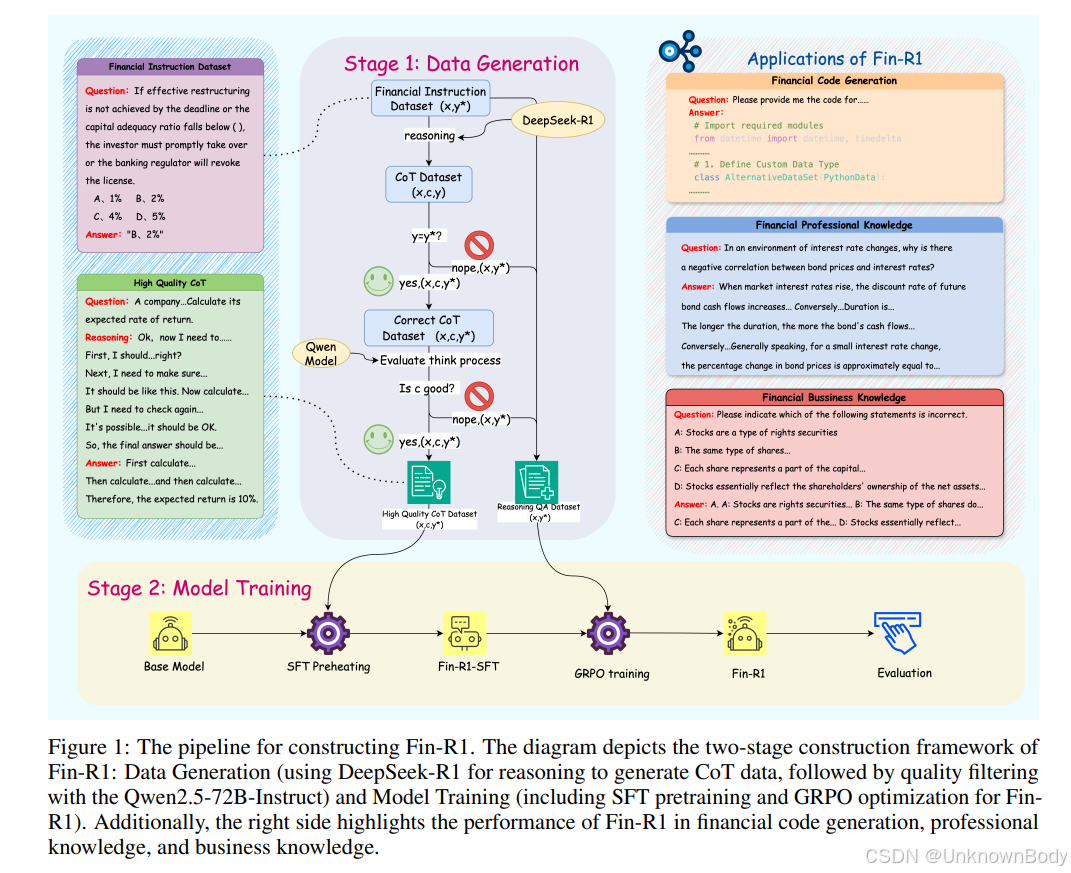
文章主要内容与创新点总结
主要内容
-
模型设计
Fin-R1是一个专为金融领域设计的轻量级大语言模型(70亿参数),通过监督微调(SFT)和强化学习(RL)两阶段训练框架,解决金融推理中的核心问题。 -
数据集构建
提出了高质量金融推理数据集Fin-R1-Data,包含60,091条多维度金融知识样本,涵盖中文和英文双语内容,通过数据蒸馏和过滤确保准确性。 -
训练方法
- 监督微调(SFT):基于Qwen2.5-7B-Instruct模型,优化金融推理能力。
- 强化学习(RL):采用**Group Relative Policy Optimization (GRPO)**算法,结合格式奖励和准确性奖励,提升回答的规范性和内容质量。 </