作者Toby,原文来源公众号Python风控模型,《顶刊复现-基于机器学习模型的贷款违约可解释预测》
标题
大家好,我是重庆未来之智Toby老师,今天复现与点评CiteScoreQ1期刊的文章,题目是:《Explainable prediction of loan default based on machine learning models》,翻译为中文:基于机器学习模型的贷款违约可解释预测。

Volume 6, Issue 3, September 2023, Pages 123-133第 6 卷,第 3 期,2023 年 9 月,页码 123-133
XuZhu a徐朱a, Qingyong Chu a清永楚A, Xinchang Song a宋欣昌A, Ping Hu a胡平, Lu Peng a b卢鹏ab
DOI:https://doi.org/10.1016/j.dsm.2023.04.003
论文简介:https://www.sciencedirect.com/science/article/pii/S2666764923000218。
收录期刊Data Science and Management
收录期刊Data Science and Management数据科学与管理。

《Data Science and Management》(DSM)是一本专注于数据科学及其在商业、经济、金融、运营、工程、医疗、交通、农业、能源、环境、体育和社会管理等领域应用的同行评审开放获取期刊。该期刊由西安交通大学自2021年起出版,旨在成为该领域内领先知识的高声誉和值得信赖的资源,促进全球学术交流。
DSM鼓励提交涉及数据科学各个方面及其在多个领域应用的原创研究文章、综述文章和技术报告。期刊的当前兴趣领域包括但不限于:
-
机器学习与智能管理
-
数据挖掘与商业分析
-
数据统计与决策制定
-
智能计算与算法
-
数据驱动的管理决策
-
基于数据的政策评估
-
商业智能与商业数据科学
-
数字经济
-
数据质量与数据隐私
-
数据与知识管理
-
企业数字化管理
-
网络空间管理
-
数据安全管理
-
智能城市管理
-
智能社会管理
-
数字工程管理
-
数据可视化
-
数据驱动的智能系统管理
-
数据科学应用。
ISSN (International Standard Serial Number) 是一种国际标准连续出版物编号,用于唯一标识期刊、杂志等连续出版物。它由8位数字组成,通常分为两组,每组4位,中间用连字符(-)隔开。ISSN 2666-7649 指的是该期刊的国际标准序列号。
CN 是中国国内统一刊号的缩写,格式为 CNXX-XXXX/YY,其中XX代表地区号,XXXX代表序号,YY代表分类号。CN 61-1530/TN 表示该期刊在中国的国内统一刊号,其中61代表陕西省的地区号,1530是该期刊的序号,TN代表无线电电子学、电信技术分类。
p-ISSN(print ISSN)是指期刊的印刷版ISSN,用于标识期刊的纸质版。2097-3187 是《Data Science and Management》期刊的印刷版ISSN号。这表明该期刊既有电子版也有印刷版,p-ISSN用于区分同一期刊的不同版本。
Data Science and Management数据科学与管理同时拥有ISSN和CN,表明收录文章同时面向国内和国外,并且拥有电子版也有印刷版。
期刊Data Science and Management数据科学与管理的CiteScore分区为Q1,Q2,挺高。
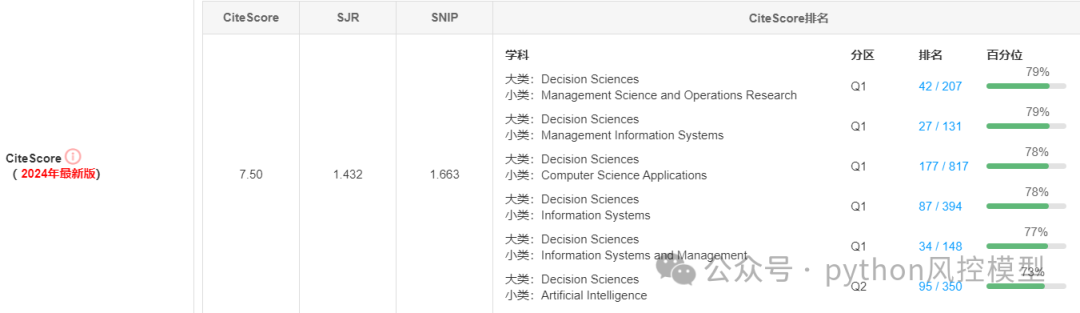
由于该期刊2021年起出版,历史积累文章不多,因此未被SCI,中科院收录,但这并不代表期刊质量不好。等时间积累后,后续指标可能有优秀表现。
Toby老师补充介绍一下CiteScore:
CiteScore™ 是由Elsevier公司推出的一个期刊评价指标,它基于Scopus数据库中的引用数据来计算期刊在近四年内发表的文章的平均被引用次数。这个指标可以帮助研究人员、出版商、图书馆员以及作者更全面、透明和最新地了解期刊的影响力。
CiteScore的计算方法如下:对于某一年,比如2023年的CiteScore,是通过统计该期刊在2020年至2023年间发表的文章、综述、会议论文、书籍章节和数据论文在2023年被引用的总次数,然后除以该期刊在2020年至2023年间发表的这些文献的总数来得出的。
CiteScore的特点包括:
-
与出版商无关,提供了一个公正的期刊评价工具。
-
包括了同行评审的文章、综述、会议论文、书籍章节和数据论文,使得期刊之间的比较更加可靠。
-
排除了早期访问文章,确保了所有活跃出版物的公平竞争环境。
-
符合《莱顿宣言》和《旧金山科研评估宣言》(DORA)中的负责任度量原则。
CiteScore为研究人员提供了一个重要的参考,帮助他们了解期刊的学术影响力,同时也是出版商和图书馆员在期刊选择和评估时的重要指标。通过CiteScore,用户可以更深入地了解科研影响力,并做出更明智的决策。
总之,期刊Data Science and Management数据科学与管理的CiteScore分区为Q1,Q2,表明该期刊质量并不差,后续可能有良好表现。
论文概述
该论文《Explainable prediction of loan default based on machine learning models》的结构和内容可以转述如下:
标题:
基于机器学习模型的贷款违约可解释预测
摘要:
随着在线贷款的便利性,越来越多的人选择在网络平台上借款。机器学习技术的出现使得预测贷款违约成为一个热门话题。然而,机器学习模型存在“黑箱”问题,这使得模型的预测规则难以理解,影响用户对模型的信任。为了提高预测模型的可解释性,本研究采用了逻辑回归、决策树,XGBoost和LightGBM模型来预测贷款违约。预测结果显示,LightGBM和XGBoost在预测能力上优于逻辑回归和决策树模型。LightGBM的AUC值为0.7213,准确率和精确度均超过0.8和0.55。此外,本研究还采用了局部可解释模型无关解释方法(LIME)对预测结果进行了可解释性分析,发现贷款期限、贷款等级、信用评级和贷款金额等因素对预测结果有显著影响。
关键词:
可解释预测、机器学习、贷款违约、局部可解释模型无关解释(LIME)
引言:
介绍了在线贷款的普及、机器学习在贷款违约预测中的应用以及模型可解释性的重要性。
方法:
详细描述了所使用的四种机器学习模型(逻辑回归、决策树、XGBoost、LightGBM)以及LIME方法在模型可解释性分析中的应用。
结果:
展示了不同模型的预测性能,包括AUC值、准确率和精确度,并比较了它们之间的差异。
讨论:
分析了模型预测结果的可解释性,讨论了影响贷款违约预测的关键因素,并探讨了模型在实际应用中的潜力和局限性。
结论:
总结了研究的主要发现,强调了LightGBM和XGBoost模型在贷款违约预测中的优越性能,以及LIME方法在提高模型可解释性方面的有效性。
经费支持:
该论文得到武汉理工大学的财政支持。该研究得到中央高校基本科研业务费专项资金(WUT: 2022IVA067)的部分支持。
Toby老师备注一下,能得到科研经费支持的论文一般质量很高,是一个团队耗费大量时间撰写的经典文章。大家要高度关注和仔细阅读有经费支持的论文。
论文实证分析数据集
《Explainable prediction of loan default based on machine learning models》论文实证分析数据下载地址如下,根据我方核实,数据就是来自home credit数据集
https://tianchi.aliyun.com/competition/entrance/531830/information。
该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
字段表
| Field | Description |
|---|---|
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 |
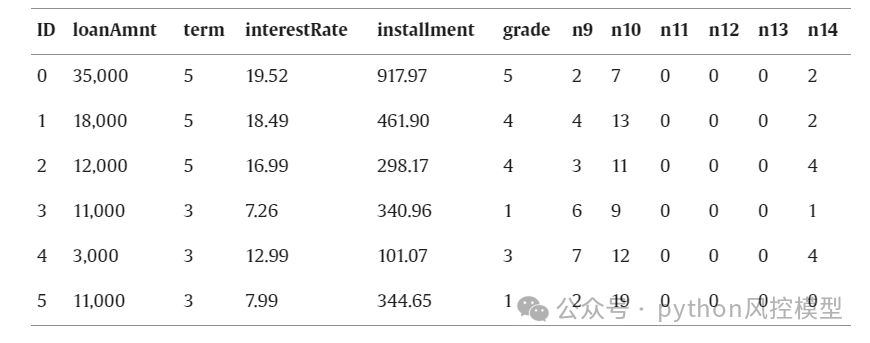
Toby老师点评,平台说该数据来自某信贷平台的贷款记录,但Toby老师一看就知道是来自home credit捷信数据集。home credit捷信数据集非常大,常规变量400+,数据总量数百万,数据清洗和变量衍生工作量非常大,属于很难的数据集。
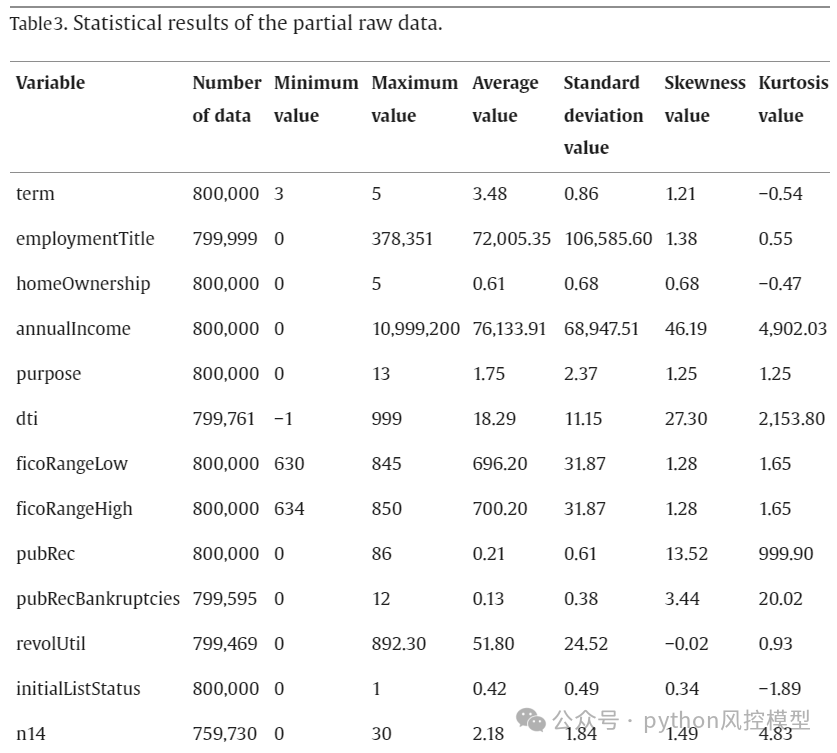
论文作者对变量做了描述性统计分析,包括变量数据量,最小值,最大值,平均值,标准差,偏态,峰度。这是经验丰富建模人士建模前工作,值得大家学习。
数据预处理
首先,作者对数据预处理包括缺失值和异常值的处理。首先处理缺失值。在本研究中,使用中位数来填充所有缺失值。对于时间变量,我们将时间格式转换为数值。第二种方法涉及处理异常值。我们使用标准差来检测异常值,采用3σ(σ代表标准差)原理来标记和去除异常值。如果数据服从正态分布,则离群值是指不在 (μ–3σ, μ+3σ) 区间内的值。μ表示平均值。值不在(μ–3σ,μ+3σ)区间内的可能性小于0.3%。去除异常值后,最终样本大小为 612,742。预测模型的输入基于 612,742 个样本。
Toby老师点评缺失值处理方法很多,常见的处理方法和作者类似,但目前诸多主流集成树算法可以自动处理缺失值,无需人工干预。
此论文用(μ–3σ, μ+3σ) 外数据判断异常值,实际上异常值处理比较复杂。异常值分为合理异常值和不合理异常值。合理异常值应该保留,而不是教科书式方法用(μ–3σ, μ+3σ) 剔除异常值。这样处理后,模型AUC可能会大幅度降低。Toby老师建议在异常值处理方面,除了统计学,机器学习的算法,还需要业务知识判断,不能一刀切。
模型降维
论文作者为了提高模型的训练速度,必须去除冗余变量。这一点Toby老师完全赞同。
PCA降维法
模型降维方法很多,论文作者用了PCA主成分法来降维。PCA偏统计法,也是经典降维方法。Toby老师在其它数据集实验经验中发现部分数据集通过PCA降维,模型性能略有上升,但也有很多数据集通过PCA降维后,模型AUC下降明显。大家在实证分析时候要具体问题具体分析,以实验结果为准,不要盲目照搬。从改论文数据集实验效果来看,PCA效果非常好。
PCA(Principal Component Analysis,主成分分析)是一种统计方法,用于通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,称为主成分。局限性:PCA假设数据的变异性是最重要的特征,并且它对异常值敏感。此外,PCA是线性方法,可能无法捕捉数据中的非线性结构。作者在数据清洗环节中剔除了异常值,为PCA降维做好铺垫。整个论文结构和思路非常精细,是运用了大量时间设计和准备,堪称经典!
论文作者根据收入和收入负债率的实际含义构造了一个新的变量“净利润”。我们设定净利润=年收入×(1-dti)。“净利润”变量主要用来反映借款人在正常还款情况下的收入。在特征构建过程中,匿名变量与贷款等级的融合可以提高模型的非线性建模能力。和 subGrade 变量是离散数值特征,原始数据包含 0-32 的 33 位正整数。通过使用 Eq 与 和 subGrade 变量交互来生成新变量“subGradetomeann4”。
论文作者构造新特征 npca1-1、npca1-2 和 npca1-3 来替换匿名变量 n1、n2、n4、n5、n7、n8、n9 和 n10
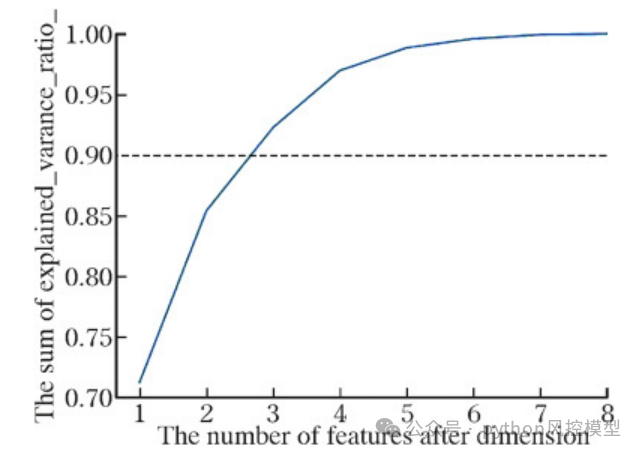
PSI剔除不稳定变量
释义:population stability index,稳定度指标,越低越稳定。用于比较当前客群与模型开发样本客群差异程度,评价模型的效果是否符合预期。PSI越接近0,模型稳定性越好。当PSI小于0.1时表示模型比较稳定,当psi在0.1和0.25之间时模型稳定性出现波动,需要检查模型,如果必要,需要重新开发模型。
作者删除PSI大于0.25变量,说明在金融风控建模学术上或业务上有一定经验。
Toby老师之前建模也会考虑删除PSI大于0.25变量,但不是绝对,这还需要对比此策略执行后模型综合性能下降程度。有时候剔除PSI大于0.25变量后模型AUC会下降显著,我们可能会保留这些变量。大家在实证分析时候要具体问题具体分析,以实验结果为准,不要盲目照搬。从改论文数据集实验效果来看,PCA效果非常好。
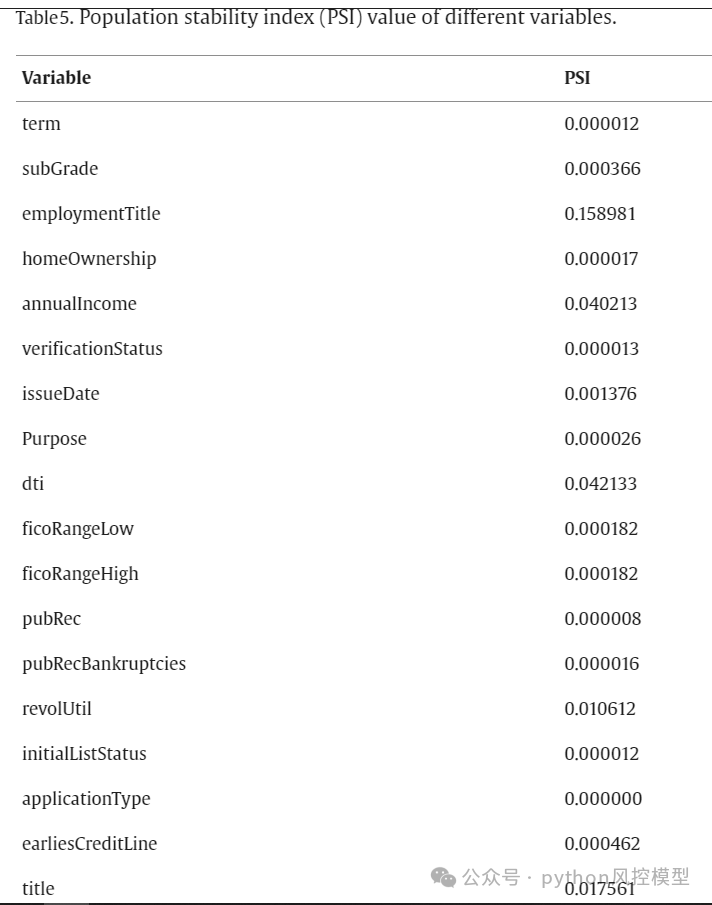
最终入模变量
论文作者通过PSI,PCA等方法降低模型维度,最后有25个变量入模。

模型验证
作者的实证分析用了Kolmogorov-Smirnov,Area under curve,Accuracy,Precision四个指标。
-
Kolmogorov-Smirnov (K-S) 检验:
- K-S指klmogrov-smirnov,这是一个区隔力指标。所谓区隔力,是指模型对于好坏客户的区分能力。K-S值从0-1,越大越好,越小越差。真实场景中风控领域的模型ks能超过0.4的很少。
-
曲线下面积(Area under Curve, AUC):
-
AUC是评估分类模型性能的一种指标,特别是在二分类问题中。
-
它表示接收者操作特征曲线(Receiver Operating Characteristic curve, ROC曲线)下的面积,该曲线是通过改变分类阈值来绘制的。
-
AUC的值范围从0到1,值越接近1表示模型的分类性能越好。AUC为0.5时,表示模型的性能等同于随机猜测。一般来说模型AUC大于0.8的算非常优秀,且很少见。
-
-
准确率(Accuracy):
-
准确率是分类模型正确预测的样本数占总样本数的比例。
-
它的计算公式为:(TP + TN) / (TP + TN + FP + FN),其中TP是真正例,TN是真负例,FP是假正例,FN是假负例。
-
准确率是一个直观的性能度量,但在类别不平衡的数据集中,高准确率可能具有误导性。
-
-
精确度(Precision):
-
精确度衡量的是模型预测为正类的样本中实际为正类的比例。
-
它的计算公式为:TP / (TP + FP)。
-
精确度关注的是减少假正例的数量,对于需要控制误报的应用场景(如疾病筛查、垃圾邮件过滤)非常重要。
-
这些指标在评估和比较机器学习模型时非常重要,它们提供了不同方面的性能信息,帮助研究者或开发者选择最合适的模型。
作者的论文实证分析中,多算法比较的模型验证结果如下,AUC最高的是lightgbm,0.7213,性能只能算良好。当然模型性能不是作者能够决定的,而是数据质量决定的。如果数据质量好,模型AUC高,数据质量不好,作者即使有三头六臂也不可能大幅提升模型性能。
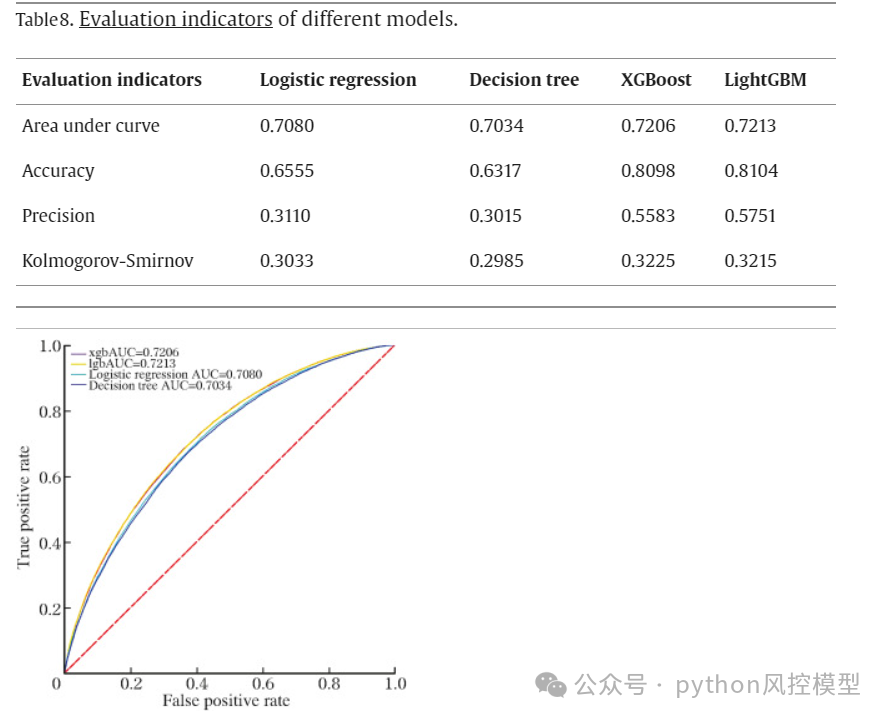
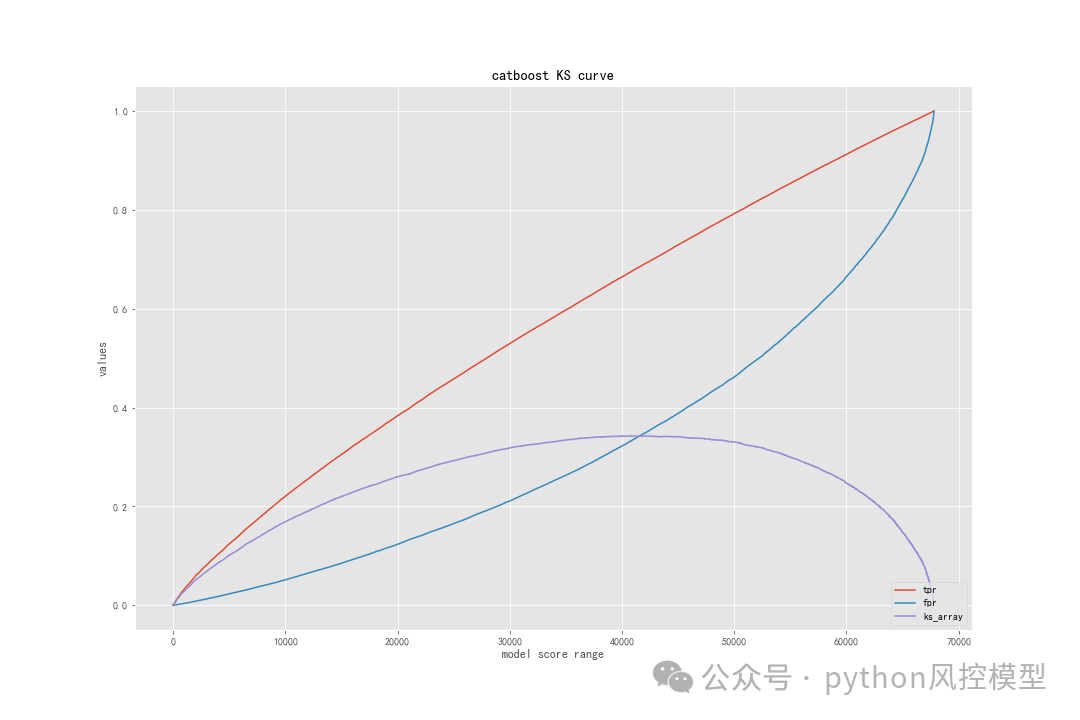
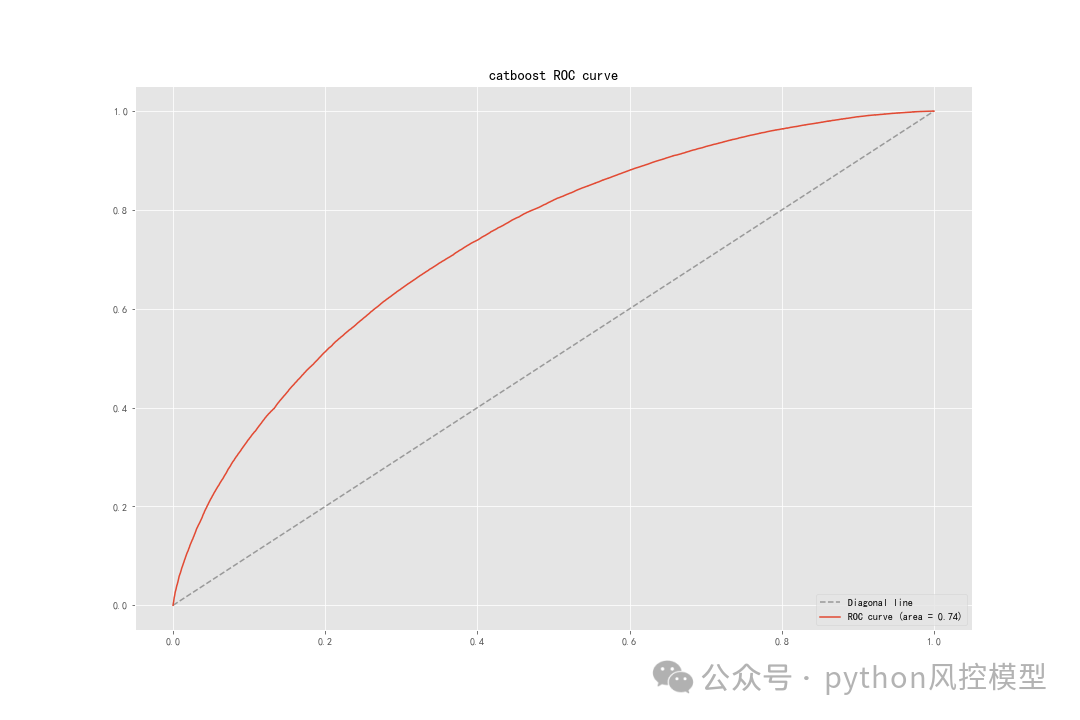
Toby老师快速实验后性能如下,AUC=0.736,KS和ROC绘图如下,模型性能只能算良好。后期如果加上数据预处理衍生变量和调参,模型性能还会提升。对比论文最好算法lightgbm,AUC=0.7213,仅用25个变量,Toby老师模型AUC略高0.015。但作者通过了复杂降维,我认为作者降维后实验效果是可以接受的,AUC仅有略微降低,但模型降维47%。
#代码问题反馈作者QQ:231469242,微信:drug666123,公众号:Python风控模型
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sn
import numpy as np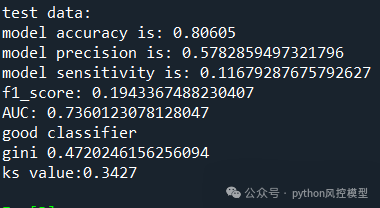
模型黑箱解释技术-LIME
作者用了LIME方法解释局部样本。Toby老师介绍一下LIME方法。
LIME(Local Interpretable Model-Agnostic Explanations)是一种机器学习模型解释性分析方法,它允许用户理解模型的预测是如何做出的。LIME的核心思想是通过对模型预测结果进行局部近似,来生成易于理解的解释。以下是LIME的中文介绍:
-
局部性(Local):LIME专注于解释模型对单个预测结果的原因,而不是整个模型。它通过在待解释样本的邻域内创建扰动样本(即微小变化的样本),并观察模型预测的变化,来理解模型在该区域的行为。
-
可解释性(Interpretable):LIME通过生成一个简化的模型(通常是线性模型),来近似原始复杂模型在局部区域的行为。这个简化模型的参数(如权重和偏差)可以直观地展示各个特征对预测结果的影响。
-
模型无关性(Model-Agnostic):LIME可以应用于任何机器学习模型,无论其内部结构如何。这意味着LIME可以为各种类型的模型提供解释,包括决策树、神经网络、支持向量机等。
-
解释生成:LIME通过以下步骤生成解释:
-
选择一个待解释的样本。
-
在该样本的邻域内生成扰动样本。
-
使用原始模型对这些扰动样本进行预测。
-
训练一个线性模型来拟合原始模型在邻域内的预测行为。
-
提取线性模型的参数,作为对原始模型预测的解释。
-
-
应用场景:LIME在需要模型解释的领域中非常有用,如医疗诊断、金融风险评估、法律判断等。它帮助用户理解模型的决策过程,增加用户对模型的信任,并可能揭示模型的潜在偏差。
-
局限性:尽管LIME在提供局部解释方面非常有效,但它可能无法捕捉到模型全局行为的复杂性。此外,LIME的解释可能受到扰动样本选择和线性模型拟合质量的影响。
总的来说,LIME是一种强大的工具,用于提高机器学习模型的透明度和可解释性,尤其是在需要对模型预测进行详细解释的场景中。
违约率高的样本解释示例
对于违约率较高的样本,以测试集中的第117,949个样本为例。基于LIME解释方法对样品进行解释,结果如图,该样本违约概率0.7。
橙色背景中的特征导致样本违约的概率增加。蓝色背景中的特征导致样本违约概率降低。根据特征变量的影响程度依次排序。
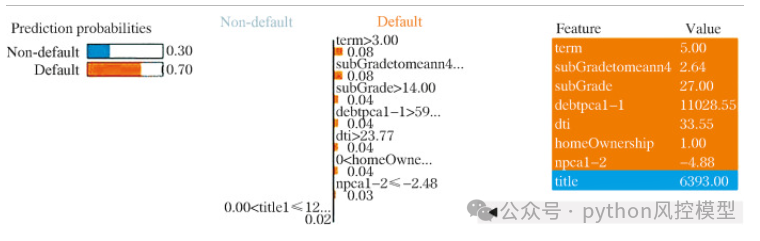
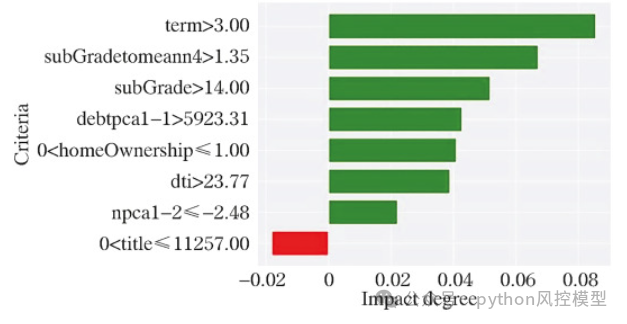
上图中,纵坐标表示特征变量及其取值范围。 横坐标代表相应的权重。绿色条表示特征变量增加了违约概率。红色条表示特征变量降低了违约概率。在样本中,八个变量表现出较高的绝对值。term,subGradetomeann4、subGrade、debtpca1-1、homeOwnership、dti 和 npca1-2 变量会增加违约概率,而变量标题会降低违约概率。
违约率低的样本解释示例
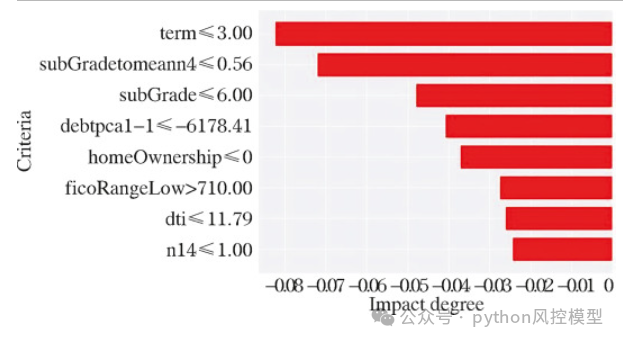
对于违约率较低的样本,以测试集中的第85312个样本为例。基于LIME解释方法对样品进行解释,结果如图1所示。8..预测模型将样本分类为默认分类的概率为 0.01,而非默认分类的概率为 0.99。

下图可以直观地展示不同变量的影响程度。term, subGradetomeann4、subGrade、debtpca1-1、homeOwnership、ficoRangeLow、dti 和 n14 变量可降低违约概率。这八个变量促使模型将样本分类为非默认样本。
为了进一步探讨不同特征变量对违约和非违约样本的影响,我们选择了违约概率高和低的样本。根据不同样本关联特征变量的积分权重和影响程度,分析判断不同特征变量的影响程度。
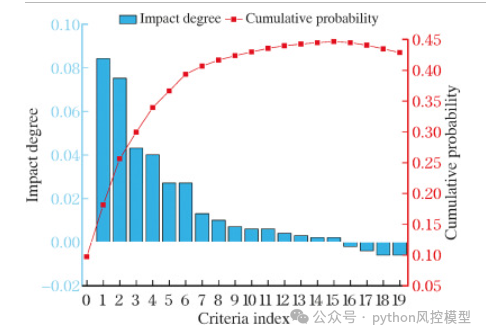
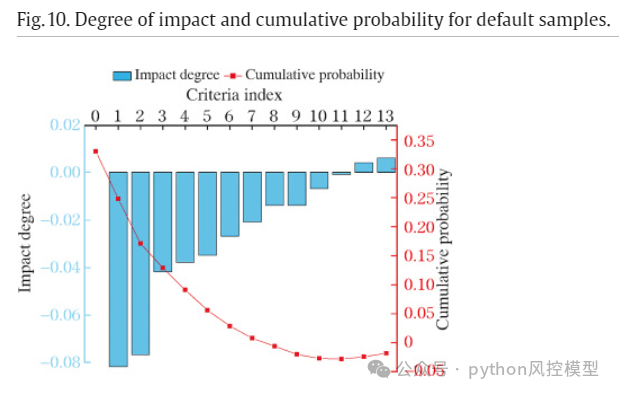
非违约样本的影响程度和累积概率。


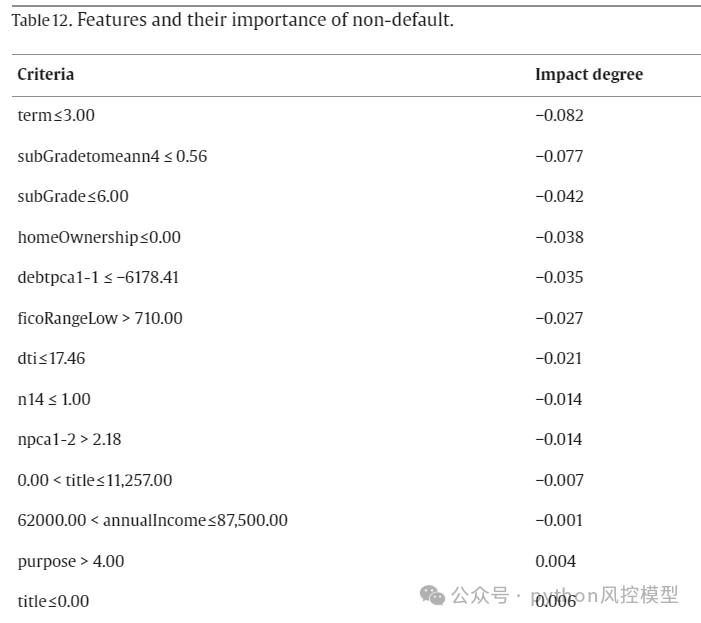
非违约的特征及其重要性
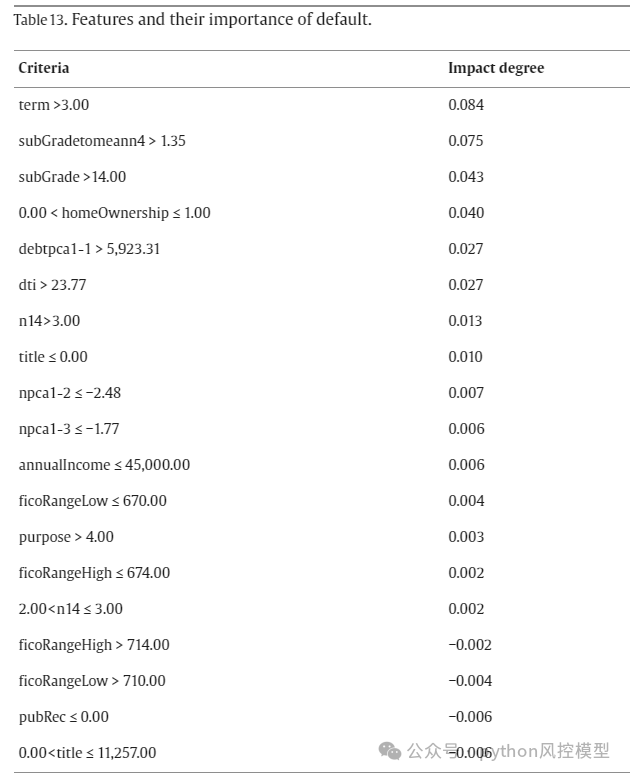
违约样本特征和变量重要性如下图
当使用复杂的机器学习模型来预测贷款违约时,LIME 可用于为模型结果添加可解释性分析。管理者可以深入理解复杂模型的预测原理。管理者不再被动地接受模型的结论,而是在保证模型可信度的前提下接受。管理者主动决策,选择是否使用模型推荐,以实现更准确、更有效的决策。LIME 有一定的局限性。首先,由于其局部可解释性,并非所有样本都可以解释。而且,应用LIME的时间成本很高。LIME 用于在本地训练和解释模型。在扰动数据范围的选择上,相似度很难定义,这也导致稳定性较差。扰动的不同样本数据常常会得出不同的结论。此外,由于预测模型的多样性,输出结果和格式也存在极大差异。因此,预测模型往往并不直接建立解释模型,这给解释带来了更大的挑战。在本研究进行的实验中,LightGBM使用的预测模型的输出格式被调整以匹配构建解释模型的需要,这大大降低了简单性。
论文结论
1.本研究将逻辑回归、决策树、XGBoost 和 LightGBM 模型应用于贷款违约预测。XGBoost和LightGBM模型的预测能力优于逻辑回归和决策树模型。
2.预测模型,使用LIME来解释预测结果。研究结论:贷款期限、贷款等级、借款人登记时提供的房屋所有权状况、贷款金额、分期金额、债务收入比、借款人信用评分是影响个人贷款违约的重要因素。因此,使用 LIME 解释模型并明确预测规则可以增强用户对模型的信心。
3.我们的研究中,预测模型和可解释模型相结合来预测个人贷款违约。机器学习模型的预测能力将进一步提高,其复杂性也将增加。可解释的模型可以有效帮助模型识别和判断模型是否与现实相符。因此,预测和可解释模型的组合可以用于其他预测问题(Wakjira 等人,2022)。将来,还可以应用其他可解释的模型来估计所使用特征的总体影响(Lim et al., 2021)。
Toby老师对此论文表达高度赞赏,如果满分是100分,我能给95分。我希望各位学员有空多读读这篇论文,从中找到很好启发。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。