一、YOLO V12
YOLO v12是YOLO系列中最新且最具创新性的版本,它将注意力机制引入到YOLO框架中,在保持高速推理的同时又显著提升了检测精度。成功打破了传统基于CNN在速度与性能之间的权衡困境。
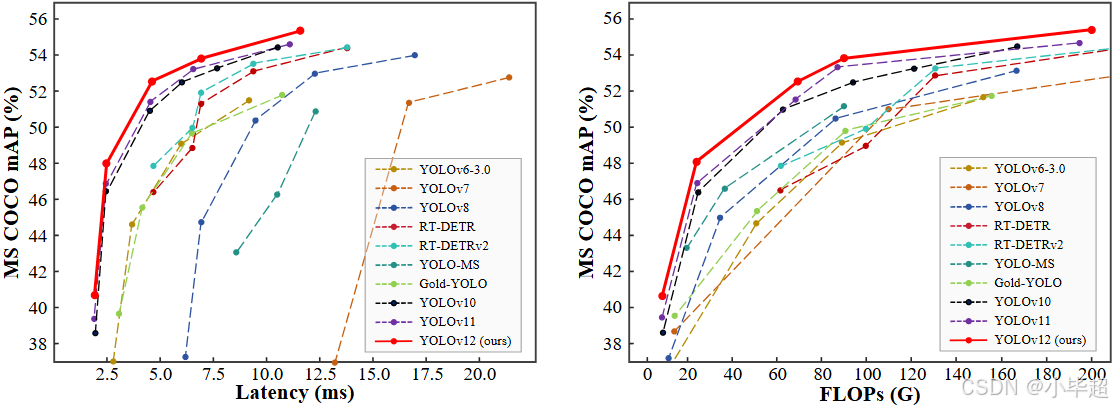
YOLO v12 在 MS COCO 数据集上取得了最先进的性能,在各个模型尺度上都超越了 YOLOv11 和 YOLOv10 等模型。与 RT-DETR 等端到端模型相比,YOLOv12 在保持相似或更高精度的同时,又具有更快的推理速度和更低的计算成本。
YOLO V12 在 MS COCO 上的表现以及和其他模型的对比:
YOLO V12 的架构亮点:
YOLO V12 最大的核心亮点便是引入了注意力机制,但YOLO V12的注意力机制和传统注意力机制还有所不同,传统注意力机制的计算复杂度为 O(n^2),其中 n 为输入序列长度,这导致计算量随着输入尺寸的增加而迅速增长,限制了其在实时目标检测中的应用。而YOLO V12为解决该问题引入了区域注意力机制,通过将特征图划分为多个区域,将全局注意力转化为区域注意力,将计算复杂度降低到 O(n^2/l),其中 l 为区域划分数量。例如,将特征图划分为 4 个区域,可以将计算复杂度降低到 O(n^2/4)。并配合 FlashAttention 解决内存访问问题,显著提高推理速度。
但加入区域注意力机制后,另一个带来的挑战就是模型收敛情况,在传统的 ELAN 结构中,每个模块的输出都需要通过多个子模块进行处理,然后再进行拼接和过渡层操作。这种设计会导致梯度在传递过程中逐渐减弱,从而影响模型的收敛和稳定性。特别是在大型模型中更为明显。因此 YOLO V12 引入了 R-ELAN , R-ELAN 引入了块级残差连接,在每个子模块的输入和输出之间添加残差连接,并引入缩放因子来控制残差连接的强度。这种设计可以有效地缓解梯度阻塞问题,提高模型的稳定性。
YOLO V12除了优化了 ELAN 结构,还针对注意力机制中MLP的比例做了调整, 在传统的注意力机制中,MLP 比例通常设置为 4.0,这意味着注意力模块中 MLP 层的输入特征维度是输入特征维度的 4 倍。为减少参数量和计算量,YOLOv12 将 MLP 比例调整为 1.2,不仅能够有效提高模型的推理速度,同时仍然能够保持较高的检测精度。
YOLO V12论文地址:
YOLO V12 Github代码地址:
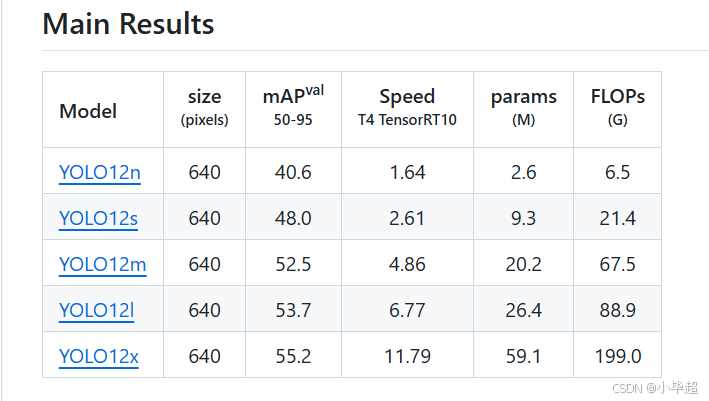
在模型上 V12 和之前的版本类似,包括不同大小的模型,从小到大包括:
YOLO12n:用于资源极其有限环境的纳米版本。YOLO12s:兼顾速度和精度的小型版本。YOLO12m:通用中型版本。YOLO12l:大型版本,精度更高,但计算资源增加。YOLO12x:超大型版本可实现最高精度和性能。
模型的比较如下:
从官方 Github 中可以看到目前 YOLO V12 已更新至 ultralytics 框架中,这极大的方便了我们的使用和微调训练。
ultralytics YOLO V12 介绍地址:
ultralytics YOLO V12 使用示例:
测试图片:

这里使用 yolo12n 模型,如果模型不存在会自动下载
from ultralytics import YOLO
# Load a model
model = YOLO('yolo12n.pt')
results = model.predict('./img/1.png')
results[0].show()

二、微调训练
数据集使用本专栏前面实验 YOLO-V10 时标注的人脸数据集, 这里你可以收集一些自定义的图片,然后根据下面文章中介绍的方式进行标注:
微调训练,其中 face.yaml 文件内容和上面文章 YOLO-V10 时的一致:
from ultralytics import YOLO
# 加载模型
model = YOLO('yolo12n.pt')
# 训练
model.train(
data='face.yaml', # 训练配置文件
epochs=100, # 训练的周期
imgsz=640, # 图像的大小
device=[0], # 设备,如果是 cpu 则是 device='cpu'
workers=0,
lr0=0.001, # 学习率
batch=8, # 批次大小
amp=False # 是否启用混合精度训练
)
运行后可以看到打印的网络结构:

训练过程:
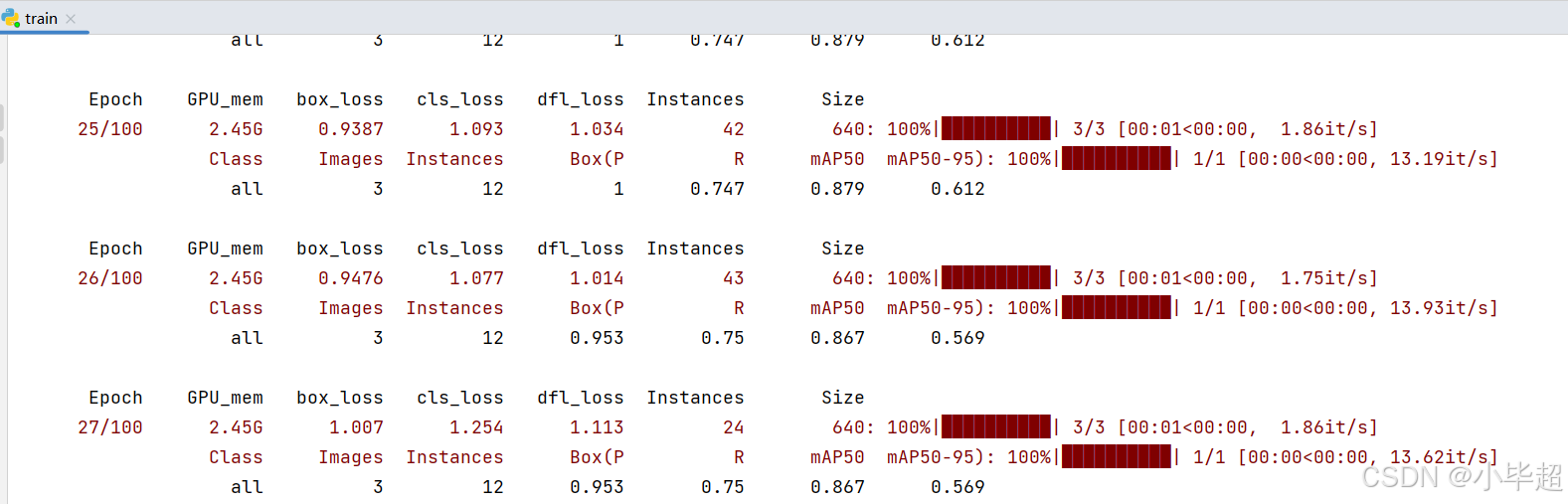
训练结束后可以在 runs 目录下面看到训练的结果:

其中 weights 下面的就是训练后保存的模型,这里可以先看下训练时 loss 的变化图:
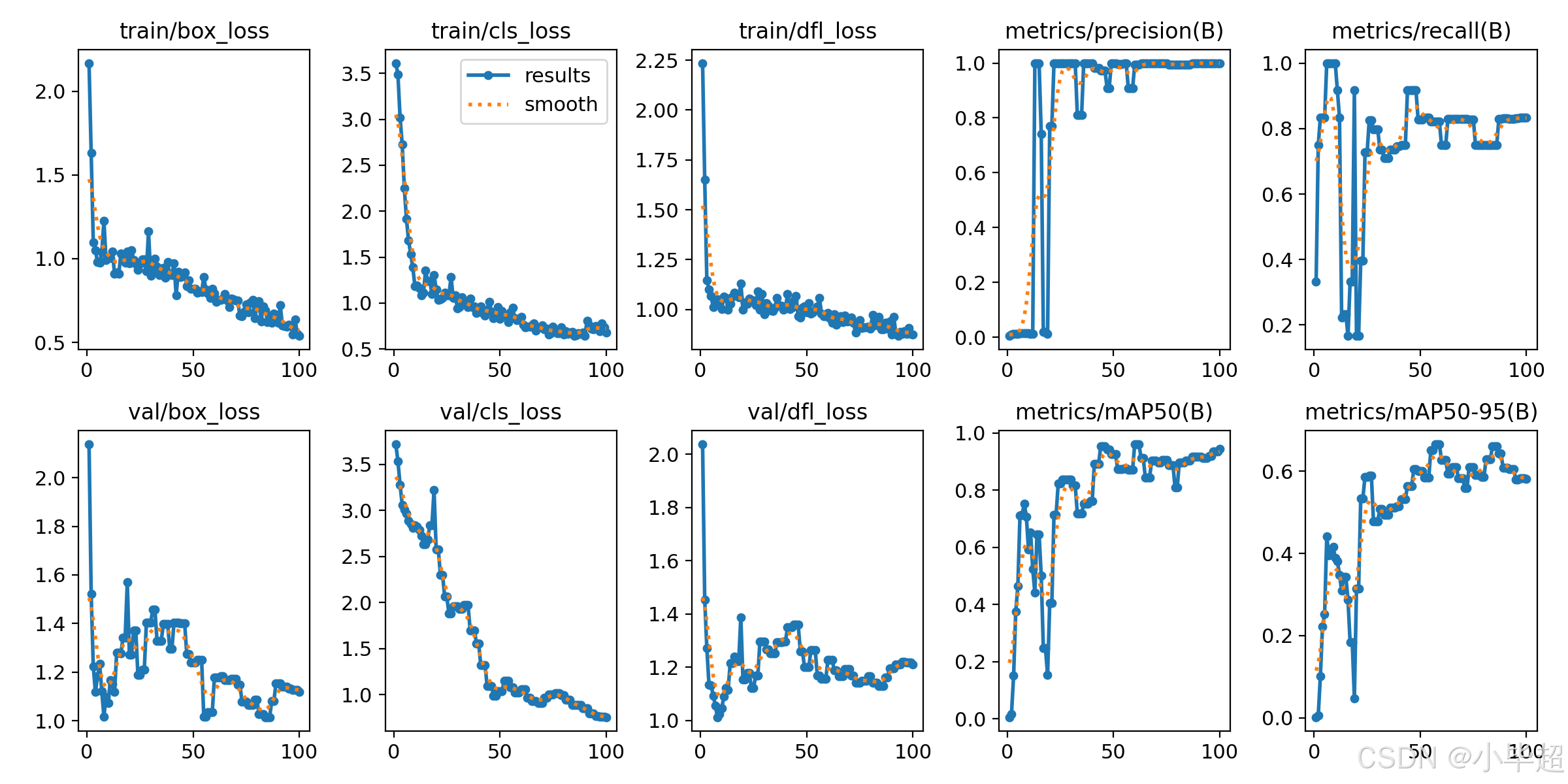
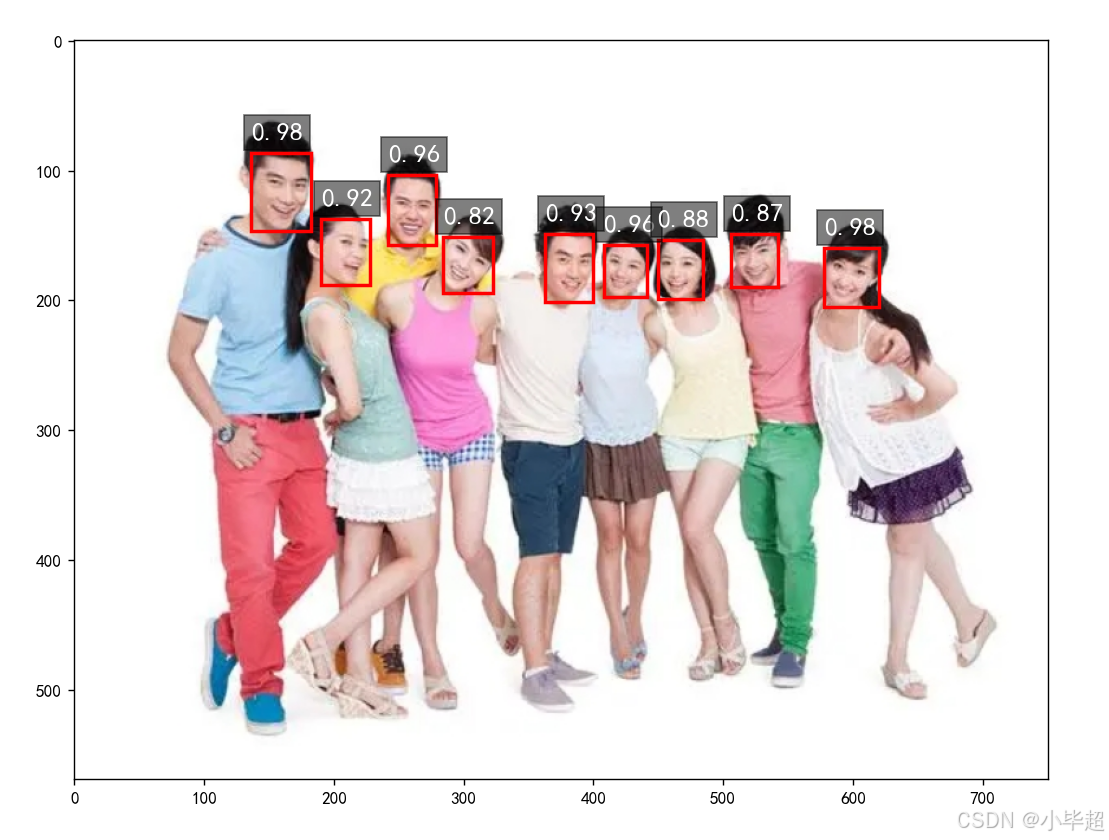
五、模型测试
在 runs\detect\train\weights 下可以看到 best.pt 和 last.pt 两个模型,表示最佳和最终模型,下面使用 best.pt 模型进行测试
from ultralytics import YOLO
from matplotlib import pyplot as plt
import os
plt.rcParams['font.sans-serif'] = ['SimHei']
# 测试图片地址
base_path = "test"
# 加载模型
model = YOLO('runs/detect/train/weights/best.pt')
for img_name in os.listdir(base_path):
img_path = os.path.join(base_path, img_name)
image = plt.imread(img_path)
# 预测
results = model.predict(image, device='cpu')
boxes = results[0].boxes.xyxy
confs = results[0].boxes.conf
ax = plt.gca()
for index, boxe in enumerate(boxes):
x1, y1, x2, y2 = boxe[0], boxe[1], boxe[2], boxe[3]
score = confs[index].item()
ax.add_patch(plt.Rectangle((x1, y1), (x2 - x1), (y2 - y1), linewidth=2, fill=False, color='red'))
plt.text(x=x1, y=y1-10, s="{:.2f}".format(score), fontsize=15, color='white',
bbox=dict(facecolor='black', alpha=0.5))
plt.imshow(image)
plt.show()