“只要不是特别大的内存开销,时间复杂度比较重要。因为改进时间复杂度对算法的要求更高。”
——吴斌(NVidia,Graphics Architect)
同样是查找,如果是顺序查找需要O(n)的时间;如果输入的是排序的数组则只需要O(logn)的时间;如果事先已经构造好了哈希表,那查找在O(1)时间就能完成。我们只有对常见的数据结构和算法都了然于胸,才能在需要的时候选择合适的数据结构和算法来解决问题。
面试题29:数组中出现次数超过一半的数字
题目:数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。
看到这道题很多应聘者就会想要是这个数组是排序的数组就好了。如果是排好序的数组,那么我们就能很容易统计出每个数字出现的次数。题目给出的数组没有说是排序的,因此我们需要先给它排序。排序的时间复杂度是O(nlogn)。最直观的算法通常不是面试官满意的算法,接下来我们试着找出更快的算法。
解法一:基于Partition函数的O(n)算法
如果我们考虑到数组的特性:数组中有一个数字出现的次数超过了数组长度的一半。如果把这个数组『排序』,那么排序之后位于数组中间的数字一定就是那个出现次数超过数组长度一半的数字。也就是说,这个数字就是统计学上的『中位数』,即长度为n的数组中第n/2大的数字。我们有成熟的O(n)的算法得到数组中任意第k大的数字。
快速排序的实现
在这一段很迷惑,是因为需要好好考虑下如何实现在 O(n) 的算法复杂度中找到任意第 k 大的数。『快速排序』第一趟排序之后,我们的到了一个中间索引(我们暂且称为 index),那么排在中间 index 前面的值都比 array[index] 小;同样的排序在中间 index 后面的元素都比 array[index] 大。第一趟的时间复杂度为O(n/2)。排序完之后,我们获得了两个子序列,同样根据上述的逻辑进行排序,假设当 k < index 时,那么我们就继续排序第二段比 index 小的部分。这一次的时间复杂度为O(n/4)。以此类推,当我们把 index 定位到 k 的时候,我们就会清楚的知道,在 k 以前的数字都比 array[k] 的值小。这也就快速的找到了任意 k 大的数组,时间复杂度
。参考的 java 代码可以如下:
void QuickSort(int[] data, int length, int start, int end) {
if (start == end) {
return;
}
int index = Partition(data, length, start, end);
if (index > start) {
QuickSort(data, length, start, index - 1);
}
if (index < end) {
QuickSort(data, length, index + 1, end);
}
}
实现快速排序算法的『关键』在于先在数组中选择一个数字(选中的数字,和返回的数字通常是不一样的),接下来把数组中的数字分为两部分,比选择的数字小的数字移到数组的左边,比选择的数字大的数字移到数组的右边。这个函数可以如下实现:
int Partition(int[] data, int length, int start, int end) {
if (data == null || length <= 0 || start < 0 || end > length) {
throw new RuntimeException("错误的参数");
}
// 从 start 到 end 之间,随机选取一个整数
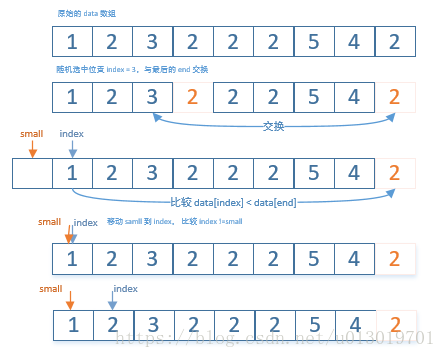
int index = new Random().nextInt(end - start) + start;
swap(data, index, end);
int small = start - 1;
for (index = start; index < end; ++index) {
if (data[index] < data[end]) {
++small;
if (small != index) {
swap(data, index, small);
}
}
}
++small;
swap(data, small, end);
return small;
}
void swap(int[] array, int i, int j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
上面代码的实现思路如下:
- 使用 Random 函数随机生成一个
index,得到一个随机的『中间参考值』,将该值换到函数的末尾。 - 从头到尾遍历数组,将数组中,所有小于中间参考值的元素排在数组的前面,small 记录已经确定小于中间参考的下标
- 返回
small并且,换回末尾的中间参考值。 - 一趟排序下来,在
small索引前面的元素,都比data[index]小。
还有一种快速排序的实现是分别的从左往右查找小于『中间参考值』的元素,和右往左查找大于『中间参考值』的元素,进行交换,同样可以达到快速排序的目的。参考的代码如下:
/**
* <b>快速排序</b>
* <p>在数组中找一个元素(节点),比它小的放在节点的左边,比它大的放在节点右边。不断执行这个操作….</p>
*
* @param array
* @return
*/
static String quickSort(int[] array) {
if (array.length <= 0) {
return null;
}
quickSort(array, 0, array.length - 1);
return Arrays.toString(array);
}
/**
* 快速排序使用递归可以很好的实现,代码的逻辑结构如下。
* <p>1. 随机的获取一个用于比较的<b>中间值</b>,通常区中间的元素 <br>
* 2. 从前往后和从后往前分别查找比<b>中间值</b>大的元素和小的元素,进行交换<br>
* 3. 直到确定不存在,交换元素,则<b>中间值</b>元素的两边就能确比</p>
*
* @param array
* @param left
* @param right
*/
static void quickSort(int[] array, int left, int right) {
int i = left;
int j = right;
//支点: 可以取任意值(但通常选取位置中间)相对来说交换次数会比较小
int pivot = array[(left + right) / 2];
//左右两端进行扫描,只要两端还没有交替,就一直扫描
while (i <= j) {
//寻找直到比支点大的数
while (pivot > array[i])
i++;
//寻找直到比支点小的数
while (pivot < array[j])
j--;
//此时已经分别找到了比支点小的数(右边)、比支点大的数(左边),它们进行交换
if (i <= j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
i++;
j--;
}
}
//上面一个while保证了第一趟排序支点的左边比支点小,支点的右边比支点大了。
//“左边”再做排序,直到左边剩下一个数(递归出口)
if (left < j)
quickSort(array, left, j);
//“右边”再做排序,直到右边剩下一个数(递归出口)
if (i < right)
quickSort(array, i, right);
}
虽然实现两种实现方式不同,但是总体思路是一致的。

小提示:如果面试题是要求在排序的数组(或者部分排序的数组)中查找一个数字或者统计某个数字出现的次数,我们都可以尝试用『二分查找』算法。
回归到本题的思路
这种算法是受『快速排序』算法的启发。在随机快速排序算法中,我们先在数组中随机选择一个数字,然后调整数组中数字的顺序,使得比选中的数字小数字都排在它的左边,比选中的数字大的数字都排在它的右边。如果这个选中的数字的下标刚好是n/2,那么这个数字就是数组的中位数。如果它的下标大于n/2,那么中位数应该位于它的左边,我们可以接着在它的左边部分的数组中查找。如果它的下标小于n/2,那么中位数应该位于它的右边,我们可以接着在它的右边部分的数组中查找。这是一个典型的递归过程,可以用如下代码实现:
int moreThanHalfNum(int[] array, int length){
if(ChechInvalidArray(array, length)){
return 0;
}
int middle = length >> 1;
int start = 0;
int end = length - 1;
int index = Partition(array, length, start, end);
// 寻找中位数
while(index != middle){
// 如果得到 index 大于中间值,则往前半部分查找
if(index > middle){
end = index - 1;
index = Partition(array, length, start, end);
}else{
start = index + 1;
index = Partition(array, length, start, end);
}
}
int result = array[middle];
if(!CheckMoreThanHalf(array, length, result)){
return 0;
}
return result;
}
上面的代码中,CheckInvalidArray 用来判断输入的数组是不是无效的。下面代码将,使用一个全局变量来表示输入无效的情况。
// 全局变量判断数组是否无效
boolean arrayInvalid = false;
boolean CheckInvalidArray(int[] array, int length){
arrayInvalid = false;
if(array == null && length <= 0){
arrayInvalid = true;
}
return arrayInvalid;
}
而对于如何验证,中位数是否为次数最多的元素,我们可以对其进行一下次数的统计。 CheckMoreThanHalf 函数的实现,如下:
boolean CheckMoreThanHalf(int[] array, int length, int number){
int times = 0;
for (int i = 0; i < length; i++) {
if(array[i] = number){
times++;
}
}
boolean isMoreThanHalf = true;
if(times * 2 <= length){
arrayInvalid = true;
isMoreThanHalf = false;
}
return isMoreThanHalf;
}
解法二:根据数组特点找出O(n)的算法
接下来我们从另外一个角度来解决这个问题。数组中有一个数字出现的次数超过数组长度的一半,也就是说它出现的次数比其他所有数字出现次数的和还要多。因此我们可以考虑在遍历数组的时候保存两个值:一个是数组中的一个数字,一个是次数。
- 当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数字相同,则次数加1;
- 如果下一个数字和我们之前保存的数字不同,则次数减1。
- 如果次数为零,我们需要保存下一个数字,并把次数设为1。
由于我们要找的数字出现的次数比其他所有数字出现的次数之和还要多,那么要找的数字肯定是最后一次把次数设为1时对应的数字。基于上面的思路写下的代码:
public Integer moreThanHalfNum(int[] array) {
if (array == null)
return null;
Integer number = null;
int count = 0;
Integer resultInteger = null;
for (int i = 0; i < array.length; i++) {
if (number == null) {
number = array[i];
count++;
} else {
if (array[i] != number)
if (count == 0) {
number = array[i];
count = 1;
} else
count--;
else
count++;
}
if (count == 1)
resultInteger = number;
}
if (checkMoreThanHalf(array, resultInteger))
return resultInteger;
else
return null;
}
其实思路,还有很多,如果不是为了考虑效率,且统计较小的话可以直接的通过 HashMap 进行统计,得出最大的值。
据说帅哥靓女都关注了↓↓↓
