导航
上一章:放款基本假定的模型
文章目录
经典单方程计量 经济学模型:专门问题
5.1虚拟变量模型
●根据因素的属性类型,构造只取 “0”或“1”的人工变量。通常称为虚拟变量,且记为D。
●一般地,在虚拟变量的设置中,基础类型和肯定类型取值为1,比较类型和否定类型取值为0。同时含有一般解释变量与虚拟变量的模型称为虚拟变量模型。
一、虚拟变量的引入
●虚拟变量作为解释变量引入模型有两种基本方式:
①加法方式
②乘法方式
二、虚拟变量的设置原则
●虚拟变量的个数须按以下原则确定:
定性变量所需的虚拟变量个数要比该定性变量的类别数少1,即如果定性变量有m个类别,就在模型中引入m-1个虚拟变量。
5.2滞后变量模型
●某些经济变量不仅受到同期各种因素的影响,而且也受到过去某些时期的各种因素甚至自身的过去值的影响。通常把这种过去时期的具有滞后作用的变量叫做滞后变量,含有滞后变量的模型称为滞后变量模型。
一、滞后变量模型
●同样地,被解释变量当前的变化也可能受其自身过去水平的影响,这种被解释变量受到自身或另一解释变量的前几期值影响的现象称为滞后效应,表示前几期值的变量称为滞后变量。
●滞后效应产生的原因:
①心理原因
②技术原因
③制度原因
●滞后变量模型的一般形式为:
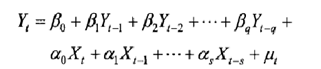
其中,q,s为滞后时间间隔,Yt-q为被解释变量Y的第q期滞后,Xt-s为解释变量X的第s期滞后。由于模型既含有Y对自身滞后变量的回归,还包括着解释变量X分布在不同时期的滞后变量,因此一般称为自回归分布滞后模型。若滞后期长度有限,称模型为有限自回归分布滞后模型:若滞后期长度无限,则称模型为无限自回归分布滞后模型。
①分布滞后模型
如果滞后变量模型中没有滞后被解释变量,仅有解释变量X的当期值及其若干期的滞后值,称为分布滞后模型。分布滞后模型的一般形式为:
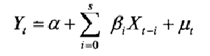
分布滞后模型的各系数体现了解释变量的当期值和各期滞后值对被解释变
量的不同影响程度,因此也称为乘数。β0称为短期或即期乘数,表示本期X变化一个单位对Y平均值的影响程度。βi (i=1,2,3,⋯s)称为动态乘数或延迟系数,表示各滞后期X的变动对Y平均值影响的大小。∑si=0 βi 则称为长期或均衡乘数,表示X变动一个单位,由于滞后效应而形成的对Y平均值总影响的大小。
②自回归模型
如果滞后变量模型中的解释变量仅包含X的当期值与被解释变量Y的一个或多个滞后值,则称为自回归模型。自回归模型的一般形式为:
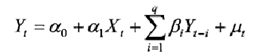
其中,滞后期长度q也称为自回归模型的阶数.
二、分布滞后模型的参数估计
●对于有限期的分布滞后模型,普通最小二乘回归也会遇到如下问题:
①没有先验准则确定滞后期长度
②如果滞后期较长,将缺乏足够的自由度进行统计检验
③同名变量滞后值之间可能存在高度线性相关,即模型存在高度的多重共线性。
●分布滞后模型的修正估计方法思想:都是通过对各滞后变量加权,组成线性合成变量而有目的地减少滞后变量的数目,以缓解多重共线性,保证自由度。
●修正方法:
①经验加权法
对于有限期分布滞后模型,往往根据实际问题的特点,以及人们的经验给各滞后变量指定权数,并按权数构成各滞后变量的线性组合,形成新的变量,再讲行估计。
权数的类型有以下三类:
①递减型
②矩形
③倒V型
②阿尔蒙(Almon)多项式法
该方法的主要思想仍是针对有限滞后期模型,通过阿尔蒙变换,定义新变量,以减少解释变量个数,然后用普通最小二乘法估计参数。
主要步骤如下:
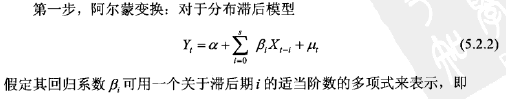

由于m<s,可以认为原模型存在的自由度不足和多重共线性问题已得到改善。需注意的是,在实际估计中,阿尔蒙多项式的阶数m一般取2或3,不超过4,否则达不到减少变量个数的目的。
③科伊克(Koyck)方法

科伊克模型有两个特点:
①以个滞后被解释变量Yt-1代替了大量的滞后解释变量Xt-i,最大限度地节省了自由度,解决了滞后期长度s难以确定的问题
②由于滞后一期的被解释变量Yt-1与Xt的线性相关程度肯定可以小于X的各期滞后值之间的相关程度,从而缓解了多重共线性。
但科伊克变换同时也产生了两个新问题:
①模型存在随机干扰项vt的一阶自相关性
②滞后被解释变量Yt-1与随机干扰项vt不独立,即Cov(Yt-1, vt)≠0.
三、自回归模型的参数估计
●许多滞后变量模型都可以转化为自回归模型,自回归模型是经济生活中吏常见的模型。
●自回归模型的构造:
①自适应预期模型
②局部调整模型
●自回归模型的参数估计:
①工具变量法
②普通最小二乘法
四、格兰杰因果检验
●当两个变量间在时间上有先导-滞后关系时,能否从统计上考察这种关系是单向的还是双向的呢?即主要是一个变量过去的行为在影响另一个变量的当前行为,还是双方的过去行为在相互影响着对方的当前行为?格兰杰(Granger)提出了个简单的检验程序,习惯上称为格兰杰因果关系检验。
●对两变量X与Y,格兰杰因果关系检验要求估计以下回归:
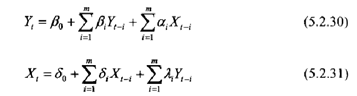
可能存在有4种检验结果:

格兰杰检验是通过受约束的F检验完成的。如针对假设:【X并不是Y的格兰杰原因】,即针对(5.2.30)式中X滞后项前的参数整体为零的假设,分别做包含与不包含X滞后项的回归,记前者的残差平方和为RSSU.后者的残差平方和为RSSR,再计算F统计量:
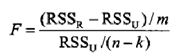
式中,m为X的滞后项的个数,n为样本容量,k为包含可能存在的常数项及
其他变量在内的无约束回归模型的待估参数的个数。
如果计算的F值大于给定显著性水平α下F分布的相应的临界值Fα (m,n-k),则拒绝原假设,认为X是Y的格兰杰原因。
●需要指出的是,格兰杰因果关系检验对于滞后期长度的选择有时很敏感,不同的滞后期可能会得到完全不同的检验结果。因此,一般而言,常进行不同滞后期长度的检验,以检验模型中随机干扰项不存在序列相关的滞后期长度来选取滞后期。
●需要指出的是,格兰杰因果关系检验对于滞后期长度的选择有时很敏感,不同的滞后期可能会得到完全不同的检验结果。因此,一般而言,常进行不同滞后期长度的检验,以检验模型中随机干扰项不存在序列相关的滞后期长度来选取滞后期。
●由于假设检验的零假设是不存在因果关系,因此严格来说,该检验应该称为格兰杰非因果关系检验。
