- 大数定律成立的条件比中心极限定理宽松,前者只需要一阶矩存在,而后者需要前两阶矩都存在。
因为条件更强,中心极限定理的结论也更强,大数定律只是证明几乎处处收敛,却没有指明收敛的速度,而中心极限定理给出了收敛的极限分布和渐近方差。 - 简单来说,大数定律讲的是样本均值收敛到总体均值(就是期望),而中心极限定理告诉我们,当样本量足够大时,样本均值的分布慢慢变成正态分布。
中心极限定理的一个应用
假设有一个群体,如我们之前提到的清华毕业的人,我们对这类人群的收入感兴趣。怎么知道这群人的收入呢?我会做这样4步:
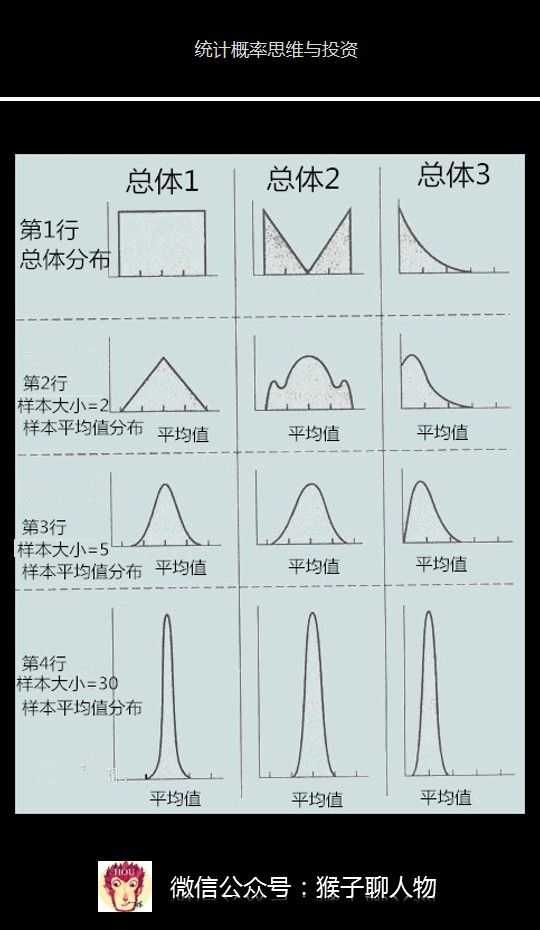
第1步.随机抽取1个样本,求该样本的平均值。例如我们抽取了100名毕业于清华的人,然后对这些人的收入求平均值。该样里的100名清华的人,这里的100就是该样本的大小。有一个经验是,样本大小必须达到30,中心极限定理才能保证成立。
第2步.我将第1步样本抽取的工作重复再三,不断地从毕业的人中随机抽取100个人,例如我抽取了5个样本,并计算出每个样本的平均值,那么5个样本,就会有5个平均值。这里的5个样本,就是指样本数量是5。
第3步.根据中心极限定理,这些样本平均值中的绝大部分都极为接近总体的平均收入。有一些会稍高一点,有一些会稍低一点,只有极少数的样本平均值大大高于或低于群体平均值。
第4步.中心极限定理告诉我们,不论所研究的群体是怎样分布的,这些样本平均值会在总体平均值周围呈现一个正态分布。
如何用样本估计总体?
现在我们已经可以用样本来估计出总体平均值。现在我想用样本来估计出总体的标准差,该怎么办呢?我们已经知道,一个数据集的标准差是数值与平均值的偏离程度。当你选择一个样本后,相比总体,你拥有数据的数量是变少了,因此,与总体中的数值偏离平均值的程度相比,样本中很有可能把较为极端的数值排除在外,这样使得数值更有可能以更紧密的方式聚集在均值周围。也就是说,样本的标准差要小于总体标准差。所以,为了更好的用样本估计总体的标准差,统计学家就将标准差的公式做了像下面图中公式中这样的改造。

即原来的标准差公式是除以n,为了用样本估计总体标准差,现在是除以n-1。这样就是的标准略大。一般用字幕s表示用样本估计出的总体标准差。很多书上都会把除以n-1的标准差叫做样本标准,其实会给很多人造成误解。其实这个样本标准差的目的是用于估计总体标准差。你可能会疑惑,那我什么时候标准差除以n还是n-1呢?那就要看你使用标准差的目的是什么。如果你只是想计算一个数据集的标准差,那么就除以n,例如你有100个毕业与清华人的收入,只是想了解这100个人构成的数据集的波动大小,那你就用除以n的标准差公式。如果你想把这100个人当成一个样本,用这个样本来估计出总体(所有毕业与清华人的收入)的标准差,那么就除以n-1的标准差公式。我们在看下什么是标准误差?标准差是用来衡量数据集的波动大小。比如毕业于清华大学所有人的收入分布。标准误差其实也是标准差,只不过它是所有样本平均值的标准差。结合我刚才给的图片中的例子就更容易理解了。如果我从毕业于清华大学中抽取100个人作为样本1,然后我计算出标准差。那么这个标准差就是用来描述这100个人组成的数据集的波动大小。我连续刚才重复抽取样本的动作,最后抽取出2个样本,每个样本都有100个人。对每个样本计算平均值,这样就有2个平均值。这2个平均值其实组成了1个新的数据集,就是所有的“样本平均值”。然后对这2个平均值数据计算出标准差。就是标准误差。
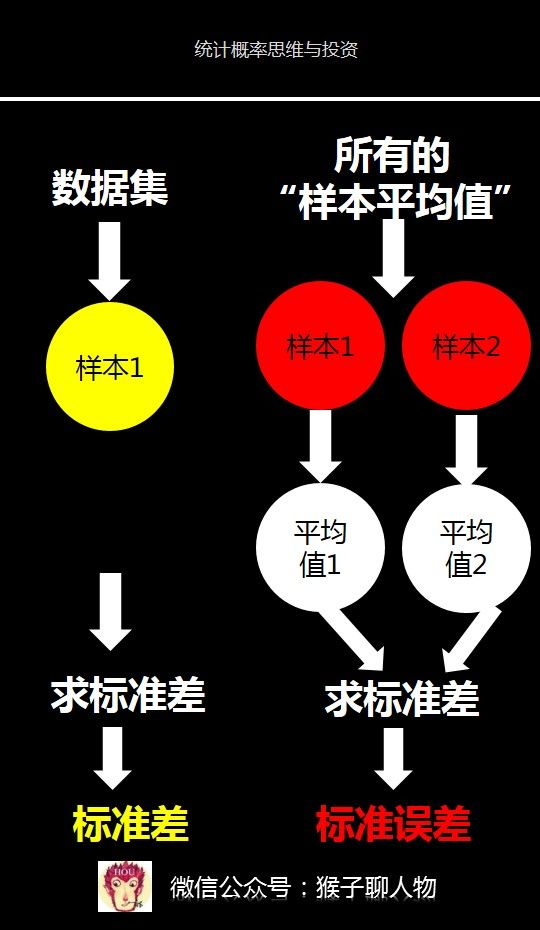
你看,标准误差其实也是标准差,只不过它的计算对象是所有的“样本平均值”。所以,标准误差是用来衡量样本平均值的波动大小。
其实,计算标准误差有个简单的公式。下面图片我们一起看下
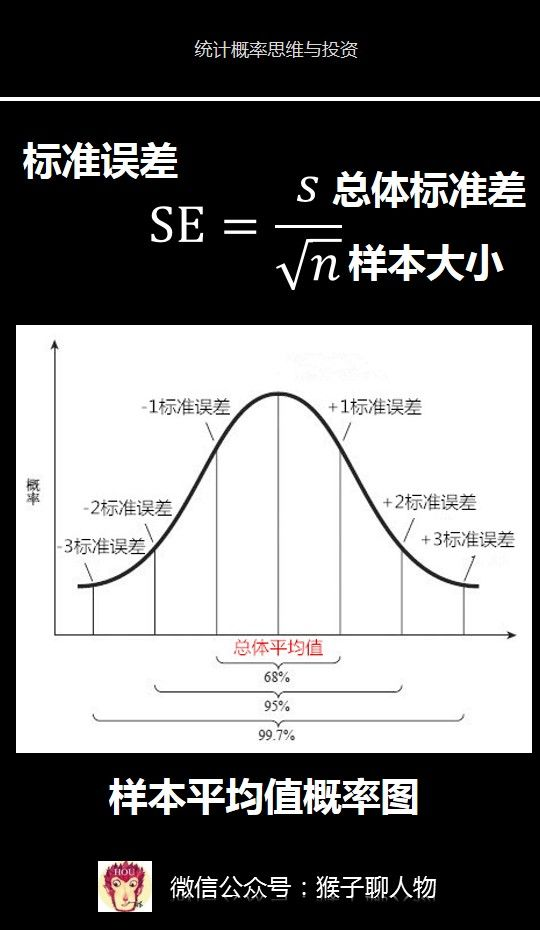
标准误差SE等于总体标准差除以n的开方。但是我们不知道总体标准差怎么办。其实前面我们已经讲了可以用样本来估计出总体标准差的公式s。根据中心极限定理,我们知道样本平均值是呈正态分布的,那么我们便可以通过这里图片中的样本平均值概率图来获得推理所需的“超能力”。看到这个图是不是很熟悉,这个图其实就是前面我们讲过的正态分布概率图,只不过这里的横轴是样本平均值的大小,纵轴是该平均值出现的概率。这里是标准误差。在前面介绍正态分布的时候,我们已经知道了正态分布的一个奇特超能力,应用到样本正态分布上,那就是:1)有68%的样本平均值会在总体平均值一个标准误差的范围之内数值范围(总体平均值-1个标准误差,总体平均值+1个标准误差)2)有95%的样本平均值会在总体平均值的两个标准误差的范围之内(总体平均值-2个标准误差,总体平均值+2个标准误差)3)有99.7%的样本平均值会在总体平均值3个标准误差的范围之内。(总体平均值-3个标准误差,总体平均值+3个标准误差)假如某个样本的平均值减去总体的平均值,大于3个标准误差。根据99.7%的样本平均值会处于总体平均值3个标准误差的范围内,因此我们可以得出该样本不属于总体。4.一句话总结中心极限定理

中心极限定理也就是这么两句话:
1)任何一个样本的平均值将会约等于其所在总体的平均值。
2)不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
2.中心极限定理有什么用呢?
1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体如果我们掌握了某个正确抽取样本的平均值和标准差,就能对估计出总体的平均值和标准差。举个例子,如果你是北京西城区的领导,想要对西城区里的各个学校进行教学质量考核。同时,你并不相信各个学校的的统考成绩,因此就有必要对每所学校进行抽样测试,也就是随机抽取100名学生参加一场类似统考的测验。作为主管教育的领导,你觉得仅参考100名学生的成绩就对整所学校的教学质量做出判断是可行的吗?答案是可行的。中心极限定理告诉我们,一个正确抽取的样本不会与其所代表的群体产生较大差异。也就是说,样本结果(随机抽取的100名学生的考试成绩)能够很好地体现整个群体的情况(某所学校全体学生的测试表现)。当然,这也是民意测验的运行机制所在。通过一套完善的样本抽取方案所选取的1200名美国人能够在很大程度上告诉我们整个国家的人民此刻正在想什么。
2)根据总体的平均值和标准差,判断某个样本是否属于总体如果我们掌握了某个总体的具体信息,以及某个样本的数据,就能推理出该样本是否就是该群体的样本之一。通过中心极限定理的正态分布,我们就能计算出某个样本属于总体的概率是多少。如果概率非常低,那么我们就能自信满满地说该样本不属于该群体。这也是统计概率中假设检验的原理.