本文为读书笔记,书籍为Java并发编程的艺术
书籍里的好像是1.6的
我发现jdk8里面的找不到segments的东西
1.为什么要用ConcurrentHashMap?
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
原理是:当往HashMap中添加元素时,会引起HashMap容器的扩容
可参考
而ConcurrentHashMap的锁分段技术可有效提升并发访问率;HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。
2.ConcurrentHashMap的结构(非1.8结构)
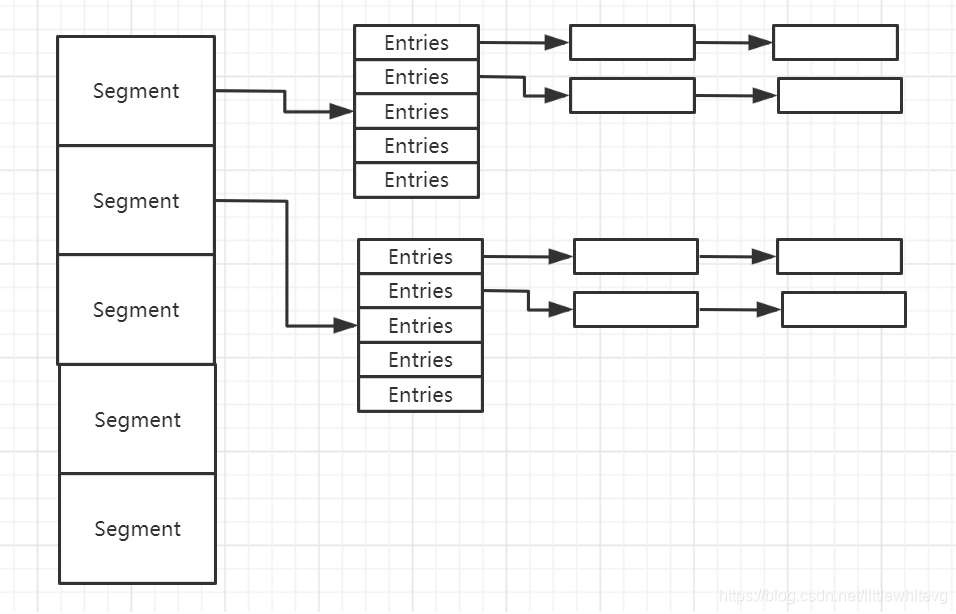
Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;
HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组。
一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
可见Segment继承 自ReentrantLock,就知道了,它可以充当锁的角色
ConcurrentHashMap的结构(1.8结构)
CAS+synchronized+hashentry
https://blog.csdn.net/programmer_at/article/details/79715177
jdk1.7 与1.8的区别
https://www.jianshu.com/p/e694f1e868ec
https://blog.csdn.net/xingxiupaioxue/article/details/88062163
ConcurrentHashMap能完全替代HashTable吗?
强一致性 与 弱一致性
其实只有两类数据一致性,强一致性与弱一致性。强一致性也叫做线性一致性,除此以外,所有其他的一致性都是弱一致性的特殊情况。所谓强一致性,即复制是同步的,弱一致性,即复制是异步的。
用户更新网站头像,在某个时间点,用户向主库发送更新请求,不久之后主库就收到了请求。在某个时刻,主库又会将数据变更转发给自己的从库。最后,主库通知用户更新成功。
如果在返回“更新成功”并使新头像对其他用户可见之前,主库需要等待从库的确认,确保从库已经收到写入操作,那么复制是同步的,即强一致性。如果主库写入成功后,不等待从库的响应,直接返回“更新成功”,则复制是异步的,即弱一致性。
强一致性可以保证从库有与主库一致的数据。如果主库突然宕机,我们仍可以保证数据完整。但如果从库宕机或网络阻塞,主库就无法完成写入操作。
在实践中,我们通常使一个从库是同步的,而其他的则是异步的。如果这个同步的从库出现问题,则使另一个异步从库同步。这可以确保永远有两个节点拥有完整数据:主库和同步从库。 这种配置称为半同步。
