前言
在前面的学习中我们已经了解在并发编程下最常使用的键值对容器为·ConcurrentHashMap,也了解了在JDK1.7中对该容器的实现(相关实现的详情可参考:https://blog.csdn.net/TheWindOfSon/article/details/103979122)但在JDK1.8对该容器的实现却有很大的差别。
1.JDK1.8中该容器的结构图

与JDK1.7实现上的不同:
(1)从上图我们可以了解到它取消了Segment数组,直接使用table保存数据,锁的粒度更小,减少了并发冲突的概率。
(2)在JDK1.7中存储数据时直接使用了链表,而在1.8中使用了链表+红黑树,在存链表的遍历上,时间复杂度为O(n),而使用了红黑树(是一种自平衡二叉查找树),它在遍历查找的时间复杂度为O(logn),性能上得到了很大的提高。
那么链表和红黑树在何种情况下进行转化呢?
当链表的元素大于等于8个的时候,由链表转为红黑树
当红黑树下的元素小于等于6个的时候,由红黑树转为链表
2.了解一下它的构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
从上面我们可以了解到它只是个给成员变量赋值,put()操作的时候才会对实际的table数组进行填充
在上一节所讲的三个参数
1)initalCapacity:初始化容量的大小,默认为16
2) loadFactor:扩容因子,默认为0.75,当一个Node存储的元素数量大于initalCapacity*loadFactor时,该Node就会进行一次扩容。
3) concurrentLevel:并发度,默认为16,并发度可以理解为程序运行时能够同时更新ConcurrentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中分段锁的个数,即Node [] 的数组长度,如果并发度设置过小,会带来严重的锁竞争问题,如果并发度设置过大,原本位于一个Node内的访问扩散到不同的Node中,CPU的cache命中率会下降,从而引起程序的性能下降。
下面我们会经常说到table数组,在JDK源码中,它表示的是一个存放键值对节点的数组

不同点是:
我们可以观察到在构造参数的最后一行加入了一个新参数sizeCtl 。它是用来初始化table数组的,主要作用是进行长度控制。
参数不同取值的意义不同:
(1)负数:表示进行初始化或者扩容(其中-1表示正在初始化,-N表示有N-1个线程正在进行扩容)
(2)0:表示还没有被初始化
(3)正数:初始化或者下一个次进行扩容的阈值。
3.了解一下它的get()和put()方法
get()操作:
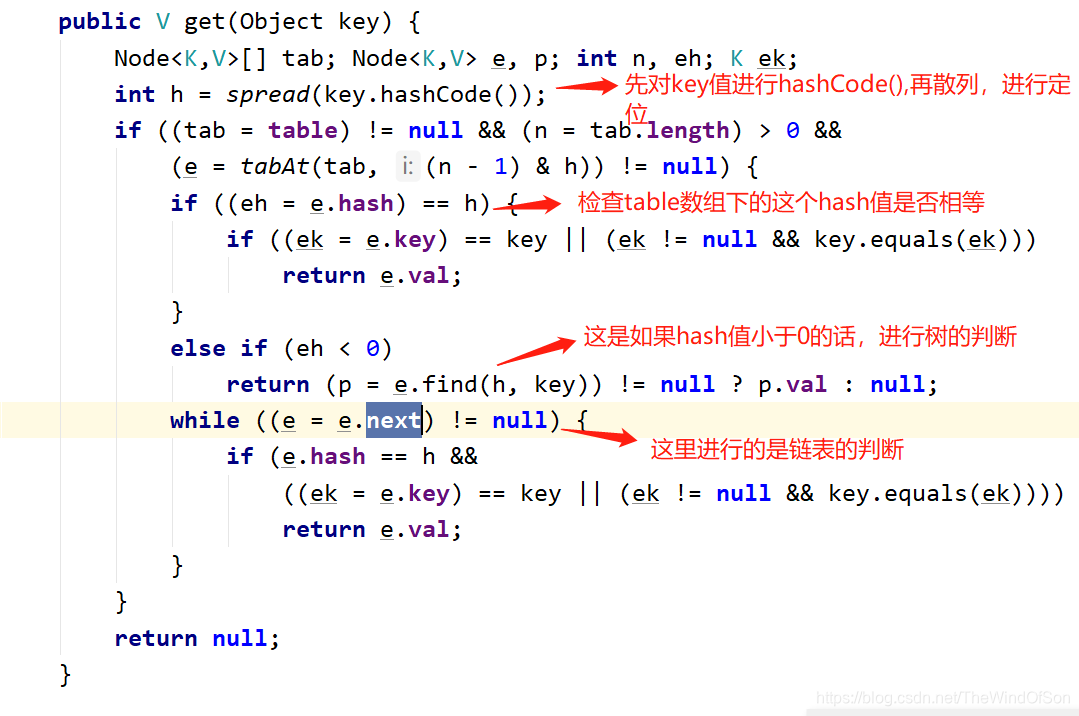
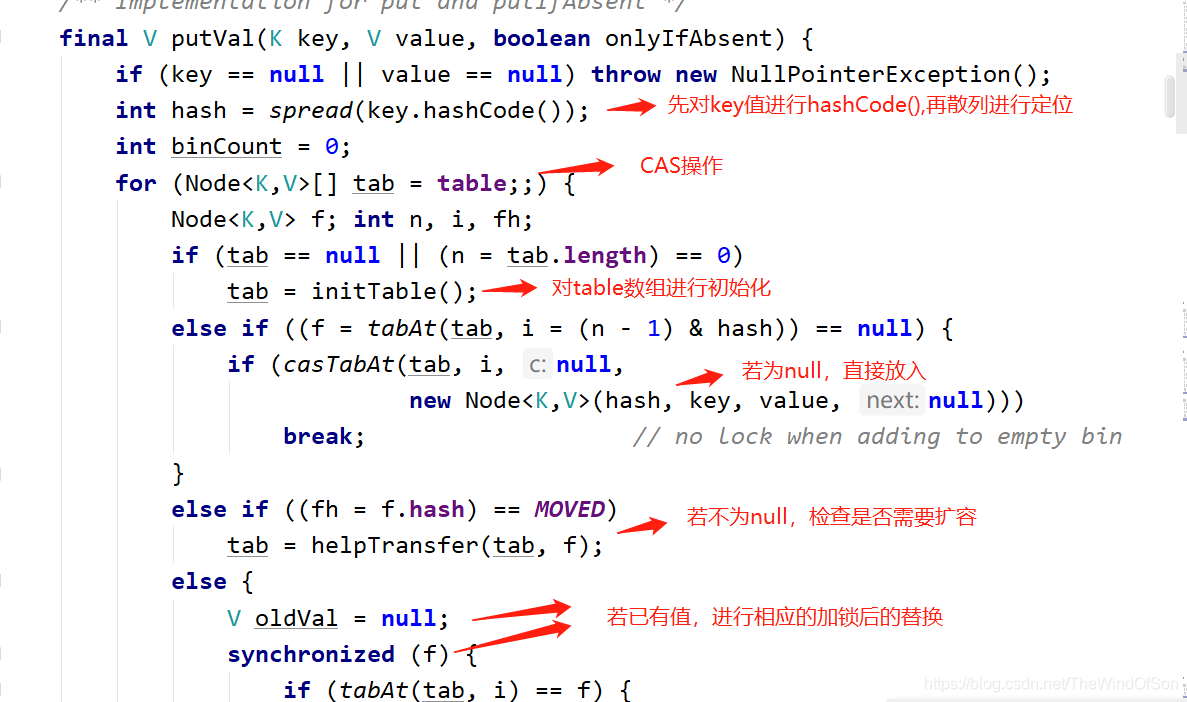
put()操作:
(1)先对key值进行hashCode(),再散列进行定位
(2)使用initTable()对数组进行初始化(其中有个关键参数为sizeCtl,通过循环CAS设置sizeCtl.直到初始化table成功)
(3)初始化成功后,把值放到数组里面。若table数组上这个元素为null,直接放到数组里;若该元素不为空,同过helpTransfer()检查是否需要扩容,然后再把该值进行相应的替换。(若个数超过8个,则由链表转化为红黑树)
部分源码:
4.其他相关方法和操作:
(1)扩容操作:transfer()方法进行实际的扩容操作,table大小也是翻倍的进行。
(2)size()方法:估计的大概数量,不是精确的数量。(在实现上是使用了一个for循环对数量进行统计,但是在统计的过程中可能有别的线程改变了该容器的大小)
(3)一致性上:弱一致性
5.面试常问:
ConcurrentHashMap实现原理是怎样的?或者问ConcurrentHashMap如何在保证高并发下线程安全的同时实现性能的提升?
ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术,它使用了多个锁来控制对hash表不同部分进行的修改,内部使用了段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,只要多个修改操作发生在不同的段上,它就可以并发进行。
总结
了解1.8版本ConcurrentHashMap的实现,我们不难发现它虽然在结构上进行了优化,可代码的数量和方法的操作上的复杂度都有很大程度的提高。所有我们只需要了解它的基础的结构,还有相关put()和get() 方法的实现,以及一些相关的基础知识即可。毕竟1.8的实现上有6000多行的代码,无论是谁都没有这个时间,没有这个精力去了解全部的实现。
