前言
在日常键值对的容器应用中,我们最习惯的是使用HashMap,但熟系这个容器的人应该都知道它是线程不安全的,那么我们在并发编程中就必须使用另外一个Map的实现—ConcurrentHashMap.
1.在介绍ConcurrentHashMap之间我们先了解一下为什么多线程环境下不能使用HashMap?
HashMap在多线程下的put()操作会引起死循环,它会使HashMap里的Entry链表会产生环形的数据结构(即首尾相连),当我们使用next()时就永远找不到结尾了。
2.了解ConcurrentHashMap时,我们应该有几个基础知识的储备
1)Hash:散列,哈希:把任意长度的输入通过一个算法(散列),变换为固定长度的输出,这个输出值就是我们的散列值,属于压缩映射,不过这种方法下也容易产生哈希冲突。Hash算法在应用中最常用的方法就是直接取余法。
解决Hash冲突的方法:开放寻址 再散列 链地址法
在现实生活的应用中md4,md5,sha都属于hash算法,也称摘要算法(该算法是不可逆的)
2)位运算:位余,位或,位非,位异或,有符号左移,有符号右移,无符号右移,取摸操作(在源码中经常会看到)
详情可以参考:位运算的相关了解
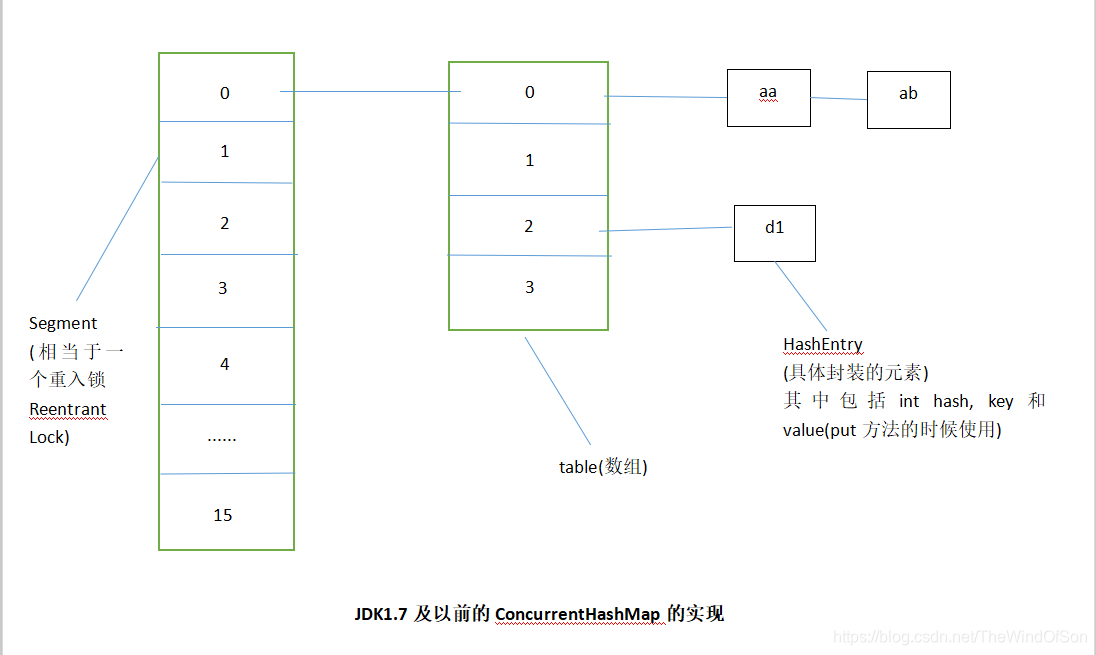
3 在Jdk1.7及其以前和Jdk1.8以后对ConcurrentHashMap的实现有很大的区别,今天我们先来了解一下在1.7版本及其以前的实现。
(1)先来看一下它的内部结构图
(2)了解一下它的构造方法:

它有三个初始化的参数:
1)initalCapacity:初始化容量的大小,默认为16
2) loadFactor:扩容因子,默认为0.75,当一个Segment存储的元素数量大于initalCapacity*loadFactor时,该Segment就会进行一次扩容。
3) concurrentLevel:并发度,默认为16,并发度可以理解为程序运行时能够同时更新ConcurrentHashMap且不产生锁竞争的最大线程数,实际上就是ConcurrentHashMap中分段锁的个数,即Segment [] 的数组长度,如果并发度设置过小,会带来严重的锁竞争问题,如果并发度设置过大,原本位于一个Segment内的访问扩散到不同的Segment中,CPU的cache命中率会下降,从而引起程序的性能下降。
(注意在进行扩容的时候,Segment是不扩容的,而只是扩容下面的table数组,数组都是进行翻倍扩容。)
构造方法中部分代码疑惑:(Jdk1.7中的)
a.
while (ssize < concurrentLevel){
++ sshift;
ssize <<=1;
}
解释说明:保证Segment数组的大小,一定为2的幂,例如用户设置并发度为17,则实际Segmnet数组大小为32。
b.
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c) cap << =1;
解释说明:保证每个Segment中table数组的大小,一定为2的幂,初始化的三个参数取默认值的时候,table数组的大小为2。
(3)两个常用方法get()和put()方法的实现:

v get(Object key, int hash); 获取相应元素
注意:此方法并不加锁,因为只是读操作,
V put(K key, int hash, V value, boolean onlyIfAbsent)
注意:此方法加锁
get() :
1)定位Segment:先对key取hashcode,再对该值进行再散列值的高位,然后和该Segment的长度取模。
2)定位table:先对key去hashcode,再对该值进行再散列,然后和table的长度取模。
3)依次扫描链表,要么找到元素,要么返回null
源码:
// 外部类方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash); // 第一次hash 确定段的位置
}
//以下方法是在Segment对象中的方法;
//确定段之后在段中再次hash,找出所属链表的头结点。
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
put():1)首先定位Segment,当这个Segment在map初始化后,还为null,它会由ensureSegment()方法负责填充这个Segment.
2)对Segment进行加锁
3)定位所在的table元素,并扫描table下的链表,找到这个元素时,put() 操作会覆盖原来的值,putIfAbsent()方法不会覆盖原来的值,然后中断循环,返回原来的值给调用者。如果没有找到的时候,将其放置链表尾部。
源码:
//外部类方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false); //先确定段的位置
}
// Segment类中的方法
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // 如果当个数超过阈值,就重新hash当前段的元素 ,
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
(4)size()方法:
进行size()方法的时候,进行两次不加锁的统计,一致直接返回结果。不一致,重新进行加锁再次统计(这样可以在很大程度上提高运行效率,不过得到这个容器的大小只是一个大概值)
(注:这也体现了该容器的弱一致性;在该容器中的get()和 containsKey() 方法都没有加锁,这样有可能在取值的过程中,别的线程对它进行了操作,造成了结果的不一致性。)
那很多人就有疑问了,这样的容器岂不是很不安全,很不合理吗?
其实不然,JDK的开发人员通过volatile这个关键字进行了巧妙的设计保证取得的元素是最新的。
实现上,用于存储键值对的数据HashEntry,再设计上它的成员变量value等都是volatile类型的,这样保证别的线程对value值的修改,进行别的操作的线程也可以马上看到,这样就很好的解决了get() 等方法的弱一致性的问题了。
源码:
static final class HashEntry<K, V>{
final int hash;
final K key;
volatile V value;
volatile HashEntry<K, V> next;
}
总结
在JDK1.7中对于ConcurrentHashMap的实现上,有很多细节还是很难搞懂的,但是我们只要了解它的构造方法,put(),get()和size()的简单使用及其原理,就能很好地应对面试和我们的日常使用。千万不要一行一行的抠源码,这样我们只会陷入其中,并且感到头大。
