本文梳理内容:在处理时序数据时,遇到(概率分布函数和概率密度函数,或者累计概率分布等等这些概念,很混乱)这一问题,根据这篇前辈文章梳理了下。
文章目录
为什么关于”概率”的研究那么重要?
在这里,直接引用陈希孺老师在他所著的《概率论与数理统计》这本书中说的:
研究一个随机变量,不只是要看它能取哪些值,更重要的是它取各种值的概率如何!
1 理解 离散型随机变量和连续性随机变量
在贾俊平老师的《统计学》教材中,给出了这样的区分:
如果随机变量的值都可以逐个列举出来,则为离散型随机变量。如果随机变量X的取值无法逐个列举则为连续型变量。
进一步解释,离散型随机变量是指其数值只能用自然数或整数单位计算的则为离散变量。例如,企业个数,职工人数,设备台数等,只能按计量单位数计数,这种变量的数值一般用计数方法取得。反之,在一定区间内可以任意取值的变量叫连续变量,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。例如,生产零件的规格尺寸,人体测量的身高,体重,胸围等为连续变量,其数值只能用测量或计量的方法取得。那么土壤水分的观测值取值区间在[0,1],是连续性随机变量。
形象点来解释:
画一幅画,左边是梯子,右边是斜坡。
像梯子一样能说出有多少层的,可描述的,是离散型随机变量;
像斜坡一样不能说出有多少层阶梯,不可描述的,是连续性随机变量。
(在第一章中注意区分离散型随机变量和连续性随机变量,因此,第二章来写离散型随机变量,第三章来写连续性随机变量)
2离散型随机变量的“概率函数”,“概率分布”和“分布函数”
2.1 概率函数
概率函数,就是用函数的形式来表达概率。
pi=P(X=ai)(i=1,2,3,4,5,6)
在这个函数里,自变量(X)是随机变量的取值,因变量(pi)是取值的概率。它就代表了每个取值的概率,所以顺理成章的它就叫做了X的概率函数。从公式上来看,概率函数一次只能表示一个取值的概率。比如P(X=1)=1/6,这代表用概率函数的形式来表示,当随机变量取值为1的概率为1/6,一次只能代表一个随机变量的取值。
2.2 概率分布
概率——的——分布!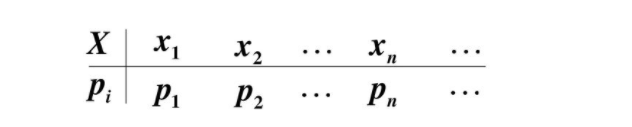
这样的列表被叫做离散型随机变量的“概率分布”。这个列表,上面是全部可能的取值(一定一定是全部),下面是这个取值相应取到的概率,所以可以理解为叫“离散型随机变量的值分布和值的概率分布列表”。
例子:一颗6面的骰子,有1,2,3,4,5,6这6个取值,每个取值取到的概率都为1/6。
2.3 累积概率函数
我的理解就是“累积概率分布”。
看看下图

3 连续型随机变量的“概率密度函数”,“概率分布函数”
3.1概率密度函数
连续型随机变量的“概率函数”换了一个名字,叫做“概率密度函数”。
为啥要这么叫呢?在陈希孺老师所著的《概率论与数理统计》这本书中是如下定义的,

概率密度函数用数学公式表示就是一个定积分的函数,定积分在数学中是用来求面积的,而在这里,你就把概率表示为面积即可!如下图:
3.2 概率分布函数
(连续型随机变量当然列不出来所有的取值,所以跳过概率分布,直接画出来概率分布函数啦,下面右图)
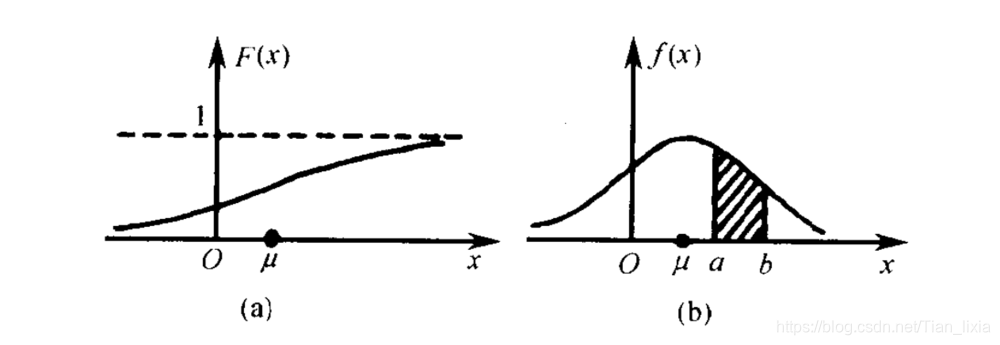
左边是F(x)连续型随机变量分布函数画出的图形,右边是f(x)连续型随机变量的概率密度函数画出的图像,它们之间的关系就是,概率密度函数是分布函数的导函数。
两张图一对比,你就会发现,如果用右图中的面积来表示概率,利用图形就能很清楚的看出,哪些取值的概率更大!所以,我们在表示连续型随机变量的概率时,用f(x)概率密度函数来表示,是非常好的!
但是,可能读者会有这样的问题:
Q:概率密度函数在某一点的值有什么意义?
A:比较容易理解的意义,某点的 概率密度函数 即为 概率在该点的变化率(或导数)。很容易误以为 该点概率密度值 为 概率值.
所以, 概率也需要有个区间.
这个区间可以是x的邻域(可以无限趋近于0)。对x邻域内的f(x)进行积分,可以求得这个邻域的面积,就代表了这个邻域所代表这个事件发生的概率。
