ResNet模型是 2015 年 ImageNet 挑战赛的获胜者。ResNet 的根本性突破是它使我们能够成功训练 150 层以上的极深神经网络。 此处我们使用ResNet模型来讲解一些迁移学习,使用的也是我硕士的研究方向图像质量评价的例子, 其他视觉任务也可以自己改动一下。
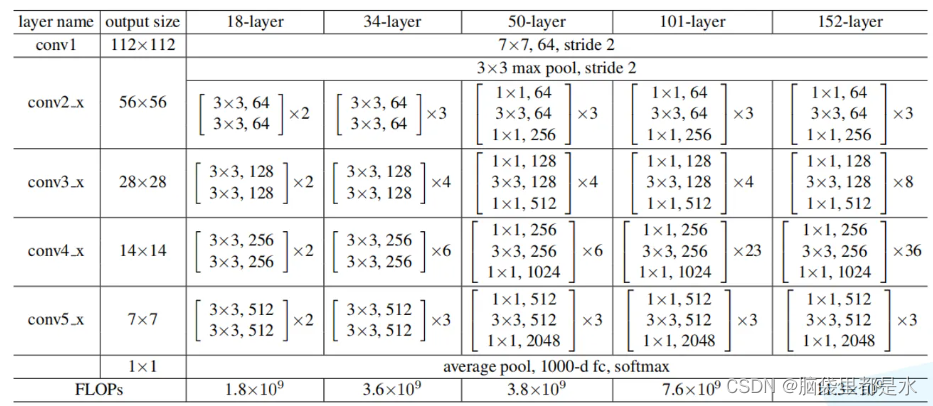
ResNet网络结构
迁移学习的优势
- 能够快速的训练出一个理想的结果
- 当数据集较小时也能训练出理想的结果
迁移学习方法
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
代码
ResNet50模型搭建
import torch
import torch.nn as nn
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
'wide_resnet50_2', 'wide_resnet101_2']
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class BasicBlock(nn.Module):
expansion = 1
__constants__ = ['downsample']
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=20, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
pretrained_dict = torch.load('pretrained/resnet50-19c8e357.pth')
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if
(k in model_dict and 'fc' not in k)} # 将'fc'这一层的权重选择不加载即可。
model_dict.update(pretrained_dict) # 更新权重
model.load_state_dict(model_dict)
# state_dict = load_state_dict_from_url(model_urls[arch],
# progress=progress)
# model.load_state_dict(state_dict)
return model
def resnet18(pretrained=False, progress=True, **kwargs):
r"""ResNet-18 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
def resnet34(pretrained=False, progress=True, **kwargs):
r"""ResNet-34 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet50(pretrained=False, progress=True, **kwargs):
r"""ResNet-50 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet101(pretrained=False, progress=True, **kwargs):
r"""ResNet-101 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
**kwargs)
def resnet152(pretrained=False, progress=True, **kwargs):
r"""ResNet-152 model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
**kwargs)
def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-50 32x4d model from
`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 4
return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
r"""ResNeXt-101 32x8d model from
`"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['groups'] = 32
kwargs['width_per_group'] = 8
return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-50-2 model from
`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
pretrained, progress, **kwargs)
def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
r"""Wide ResNet-101-2 model from
`"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_
The model is the same as ResNet except for the bottleneck number of channels
which is twice larger in every block. The number of channels in outer 1x1
convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
channels, and in Wide ResNet-50-2 has 2048-1024-2048.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
kwargs['width_per_group'] = 64 * 2
return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
pretrained, progress, **kwargs)
上面这段代码是ResNet的源代码,值得注意的是 下列这段代码段:
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
pretrained_dict = torch.load('pretrained/resnet50-19c8e357.pth')
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if
(k in model_dict and 'fc' not in k)} # 将'fc'这一层的权重选择不加载即可。
model_dict.update(pretrained_dict) # 更新权重
model.load_state_dict(model_dict)
return model
因为我们要做微调,所以原ResNet的最后一层我们需要更改成自己的视觉任务,比如我这里要实现图像质量评价任务,我不需要最后一层的fc层。
模型训练
import argparse
import math
from statistics import mean
from datetime import datetime
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import config
import torch
import os
import numpy as np
import torchvision
import cv2
from scipy import stats
import yaml
from argparse import ArgumentParser
import random
from torch.optim import Adam
import torch.nn.functional as F
import torch.nn as nn
from tqdm import tqdm
from IQADatasets import IQAdatasets
import models
log_dir = None
if log_dir is None:
log_dir = os.path.join('./runs', datetime.now().strftime('%b%d_%H-%M-%S'))
writer = SummaryWriter(log_dir=log_dir)
def get_indexNum(config, index, status):
test_ratio = config['test_ratio']
train_ratio = config['train_ratio']
# live :trainindex = index[0:21]
trainindex = index[:int(train_ratio * len(index))]
# live :testindex = index[24:]
testindex = index[int(train_ratio * len(index)):]
if status == 'train':
index = trainindex
if status == 'test':
index = testindex
return len(index)
def get_entropy(img_):
img_ = np.array(img_)
x, y = img_.shape[0:2]
print(x)
print(y)
print(img_.shape)
# img_ = cv2.resize(img_, (100, 100)) # 缩小的目的是加快计算速度
tmp = []
for i in range(256):
tmp.append(0)
val = 0
k = 0
res = 0
img = np.array(img_)
for i in range(len(img)):
for j in range(len(img[i])):
val = img[i][j]
tmp[val] = float(tmp[val] + 1)
k = float(k + 1)
for i in range(len(tmp)):
tmp[i] = float(tmp[i] / k)
for i in range(len(tmp)):
if(tmp[i] == 0):
res = res
else:
res = float(res - tmp[i] * (math.log(tmp[i]) / math.log(2.0)))
return res
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', dest='dataset', type=str, default='espl-live',
help='Support datasets: livec|koniq-10k|bid|live|csiq|tid2013')
parser.add_argument('--train_patch_num', dest='train_patch_num', type=int, default=25,
help='Number of sample patches from training image')
parser.add_argument('--test_patch_num', dest='test_patch_num', type=int, default=25,
help='Number of sample patches from testing image')
parser.add_argument('--lr', dest='lr', type=float, default=0.001, help='Learning rate')
parser.add_argument('--weight_decay', dest='weight_decay', type=float, default=5e-4, help='Weight decay')
parser.add_argument('--lr_ratio', dest='lr_ratio', type=int, default=10,
help='Learning rate ratio for hyper network')
parser.add_argument('--batch_size', dest='batch_size', type=int, default=32, help='Batch size')
parser.add_argument('--epochs', dest='epochs', type=int, default=50, help='Epochs for training')
parser.add_argument('--patch_size', dest='patch_size', type=int, default=224,
help='Crop size for training & testing image patches')
args = parser.parse_args()
sel_num = config.img_num[args.dataset]
random.shuffle(sel_num)
train_index = sel_num[:int(0.8 * len(sel_num))]
test_index = sel_num[int(0.8 * len(sel_num)):]
# train_index = sel_num[:8]
# test_index = sel_num[-5:]
train_transforms = transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(size=args.patch_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
transforms_gray = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(size=args.patch_size),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.5),
std=(0.5))
])
test_transforms = transforms.Compose(
[
transforms.ToTensor()
])
train_data = IQAdatasets(
root=config.folder_path[args.dataset], index=train_index, transform=train_transforms, transform_gray = transforms_gray , patch_num=args.train_patch_num)
# for i , j in train_data:
# print(len(i))
train_loader = torch.utils.data.DataLoader(train_data,
batch_size=args.batch_size,
shuffle=True,
pin_memory=True,
num_workers=0)
test_data = IQAdatasets(
root=config.folder_path[args.dataset], index=test_index, transform=test_transforms,transform_gray = transforms_gray , patch_num=args.test_patch_num)
# for i , j in train_data:
# print(len(i))
test_loader = torch.utils.data.DataLoader(test_data)
# torch.nn.MSELoss
seed = random.randint(10000000, 99999999)
torch.manual_seed(seed)
np.random.seed(seed)
print("seed:", seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.resnet50(pretrained=True)
# print('before:{%s}\n' % model)
for param in model.parameters():
param.requires_grad = False
fc_inputs = model.fc.in_features
model.fc= nn.Sequential(
nn.Linear(fc_inputs, 1024),
nn.Linear(1024, 512),
nn.Linear(512, 1)
)
# print('after:{%s}\n' % model)
#多卡同时训练
if torch.cuda.device_count() > 1: # 检查电脑是否有多块GPU
# print(f"Let's use {torch.cuda.device_count()} GPUs!")
model = nn.DataParallel(model) # 将模型对象转变为多GPU并行运算的模型
model.to(device) # 把并行的模型移动到GPU上
# def criterion(input, target, weight):
# return ((target - input).pow(2).sum()) * weight
optimizer = torch.optim.Adam(
model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
criterion = nn.L1Loss()
best_SROCC = -1
train_SROCC = []
train_PLCC = []
train_rmse = []
for epoch in range(args.epochs):
# train
y_pred = []
y_test = []
model.train()
LOSS = 0
train_bar = tqdm(enumerate(train_loader))
for i, (img, label) in train_bar:
x_rgb = img[0].to(device)
x_gray = img[1].to(device)
# print("训练的label.item:", label.item())
# y_train = label
label = label.to(device)
optimizer.zero_grad()
# print("x_rgb:",x_rgb.shape)
# print("x_gray:",x_gray.shape)
outputs = model((x_rgb , x_gray))
outputs = outputs.squeeze(-1)
loss = criterion(outputs, label)
loss.backward()
optimizer.step()
# score = outputs.mean()
LOSS = LOSS + loss.item()
train_bar.desc = f"train epoch [{epoch + 1}/{args.epochs}] loss= {LOSS:.3f}"
# print("rmse:",rmse)
train_loss = LOSS / (i + 1)
# test
with torch.no_grad():
model.eval() # 验证
L = 0
y_pred = []
y_test = []
test_loss = 0
for i, (img, label) in tqdm(enumerate(test_loader)):
y_test.append(label.item())
x_rgb = img[0].to(device)
x_gray = img[1].to(device)
label = label.to(device)
outputs = model((x_rgb , x_gray))
score = outputs.mean()
y_pred.append(score.cpu())
score = score.reshape(1)
loss = criterion(score, label)
L = L + loss.item()
test_loss = L / (i + 1)
SROCC = stats.spearmanr(y_pred, y_test)[0]
PLCC = stats.pearsonr(y_pred, y_test)[0]
KROCC = stats.kendalltau(y_pred, y_test)[0]
RMSE = np.sqrt(((np.array(y_pred) - np.array(y_test)) ** 2).mean())
writer.add_scalar('loss/train_loss', train_loss, epoch + 1)
writer.add_scalar('loss/test_loss', test_loss, epoch + 1)
# print("Epoch {} train Results: loss={:.3f} SROCC={:.3f} PLCC={:.3f} KROCC={:.3f} RMSE={:.3f}".format(epoch,
# train_loss,
# train_SROCC,
# train_PLCC,
# train_KROCC,
# train_RMSE))
print("Epoch {} Test Results: loss={:.3f} SROCC={:.3f} PLCC={:.3f} KROCC={:.3f} RMSE={:.3f}".format(epoch,
test_loss,
SROCC,
PLCC,
KROCC,
RMSE))
if SROCC > best_SROCC and epoch>50:
print("Update Epoch {} best valid SROCC".format(epoch))
print("Test Results: loss={:.3f} SROCC={:.3f} PLCC={:.3f} KROCC={:.3f} RMSE={:.3f}".format(test_loss,
SROCC,
PLCC,
KROCC,
RMSE))
torch.save(model.state_dict(), './savamodel/live-densenet.pth')
best_SROCC = SROCC
# final test
model.load_state_dict(torch.load('./savamodel/live-densenet.pth'))
model.eval()
with torch.no_grad():
y_pred = []
y_test = []
L = 0
for i, (img, label) in enumerate(test_loader):
y_test.append(label.item())
x_rgb = img[0].to(device)
x_gray = img[1].to(device)
label = label.to(device)
outputs = model((x_rgb , x_gray))
score = outputs.mean()
y_pred.append(score.cpu())
score = score.reshape(1)
loss = criterion(score, label)
L = L + loss.item()
test_loss = L / (i + 1)
SROCC = stats.spearmanr(y_pred, y_test)[0]
PLCC = stats.pearsonr(y_pred, y_test)[0]
KROCC = stats.stats.kendalltau(y_pred, y_test)[0]
RMSE = np.sqrt(((y_pred - y_test) ** 2).mean())
print("Final test Results: loss={:.3f} SROCC={:.3f} PLCC={:.3f} KROCC={:.3f} RMSE={:.3f}".format(test_loss,
SROCC,
PLCC,
KROCC,
RMSE))
这段训练模型的代码中值得注意的是:
model = models.resnet50(pretrained=True)
# print('before:{%s}\n' % model)
for param in model.parameters():
param.requires_grad = False
fc_inputs = model.fc.in_features
model.fc= nn.Sequential(
nn.Linear(fc_inputs, 1024),
nn.Linear(1024, 512),
nn.Linear(512, 1)
)model = models.resnet50(pretrained=True)表示使用resnet的预训练参数,我们重写原Resnet模型最后的fc层。
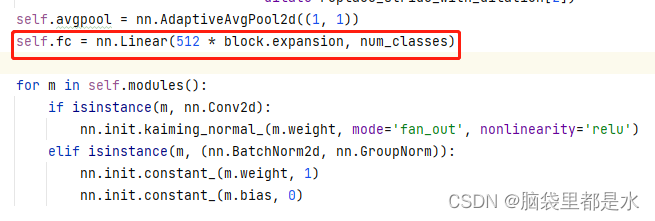
原代码里的fc层是做分类的任务,这里我们只需要重写fc,将最后的分类数写成1,再使用SROCC、PLCC等做图像质量的评价指标。