本文转载自TimingSpace 发表在CSDN上的文章 原文链接:https://blog.csdn.net/Timingspace/article/details/50963564
1. 前言:
细微之处,彰显本质;不求甚解,难以理解。
一直以来,我都认为,梯度下降法就是最速下降法,反之亦然,老师是这么叫的,百度百科上是这么写的,wiki百科也是这么说的,这么说,必然会导致大家认为,梯度的反方向就是下降最快的方向,然而最近在读Stephen Boyd 的凸优化的书,才发现事实并非如此,梯度下降和最速下降并不相同,梯度方向也不一定总是下降最快的方向。
2. 梯度下降法
梯度下降法是一种优化方法,用来求解目标函数的极小值。梯度下降法认为梯度的反方向就是下降最快的方向,所以每次将变量沿着梯度的反方向移动一定距离,目标函数便会逐渐减小,最终达到最小。
f(x)=f(x0)+∇f(x)(x−x0)+12(x−x0)T∇2f(x)(x−x0)+…
f(x)≈f(x0)+∇f(x)(x−x0)
所以如果x-x_0和 ∇f(x)的方向相反,那么相同距离的移动, f(x)
的减小最大。
所以梯度下降法的核心步骤就是
xk+1=xk−a∇f(x)
其中,a是步长,可以通过精准线性查找或非精准线性查找确定。
3. 最速下降法
最速下降法在选取x的变化方向时与梯度下降法有细微的差别。
△nsd=argminv(∇f(x)Tv∣∥v∥<=1)
表示下降最快的方位方向(normalized sleepest descent direction)。
4. 差异
看到这里,可能觉得最速下降的方向和梯度下降法的方向并没有差别,都是移动单位步长,下降最多的方向。而差别就在单位步长这里,如果△nsd=argminv(∇f(x)Tv∣∥v∥<=1)
中 ∥v∥是欧式范数,那么最速下降法就是梯度下降法,也就是说梯度下降法是最速下降法使用欧式范数的特殊情况。
5. 为什么会有不用欧式范数的情况
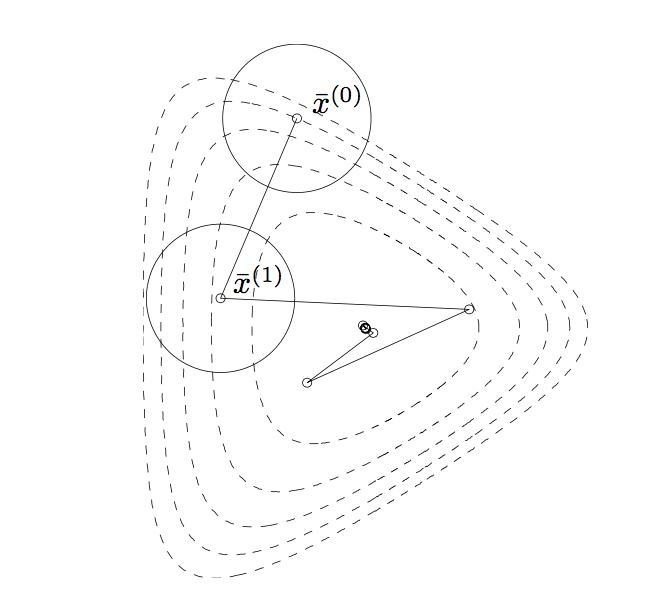
原因其实很简单,因为使用欧式范数的最速下降法(也就是梯度下降法)得到下降方向并非永远都是下降最快的方向。读到这里,你可能有些吃惊,可能会问,难道梯度的反方向是下降最快的方向吗?如果你有这样的疑问和思考,那么恭喜你,你对梯度有着一定的理解。
然而实际情况是这样的:梯度是变化的,而梯度下降在一次迭代的过程中假设梯度是固定不变的,所谓的梯度方向只是起始点(xk
),所以梯度方向不一定是下降最快的方向,所以为了得到更快的下降方向,我们有时并不适用欧式范数。
图片来自Stephen Boyd的凸优化。
6. 什么时候会不用欧式范数?
我们知道梯度是函数对每个因子求偏导得到的列向量,表示着函数的变化趋势,
∇f(x)=(∂f∂x1,∂f∂x2,…,∂f∂xn)
提到梯度的变化,很自然的想到了函数的二阶导数,对于多变量函数,也就是函数的Hessian矩阵。
H=
这里首先讨论一个简单的情况,就是f(x)的各个变量相互独立,此时Hessian矩阵是一个对角阵,
如果 ∂2f∂xi∂xii=1,2...n相差不多,也就是 f(x)梯度在各个方向的变化基本一致,那么梯度方向基本不会发生变化,此时梯度下降法会得到很好的结果,想法如果 ∂2f∂xi∂xii=1,2...n相差很大,那么梯度方向变化就会较大,当然梯度下降的方向便不再是最好的方向。
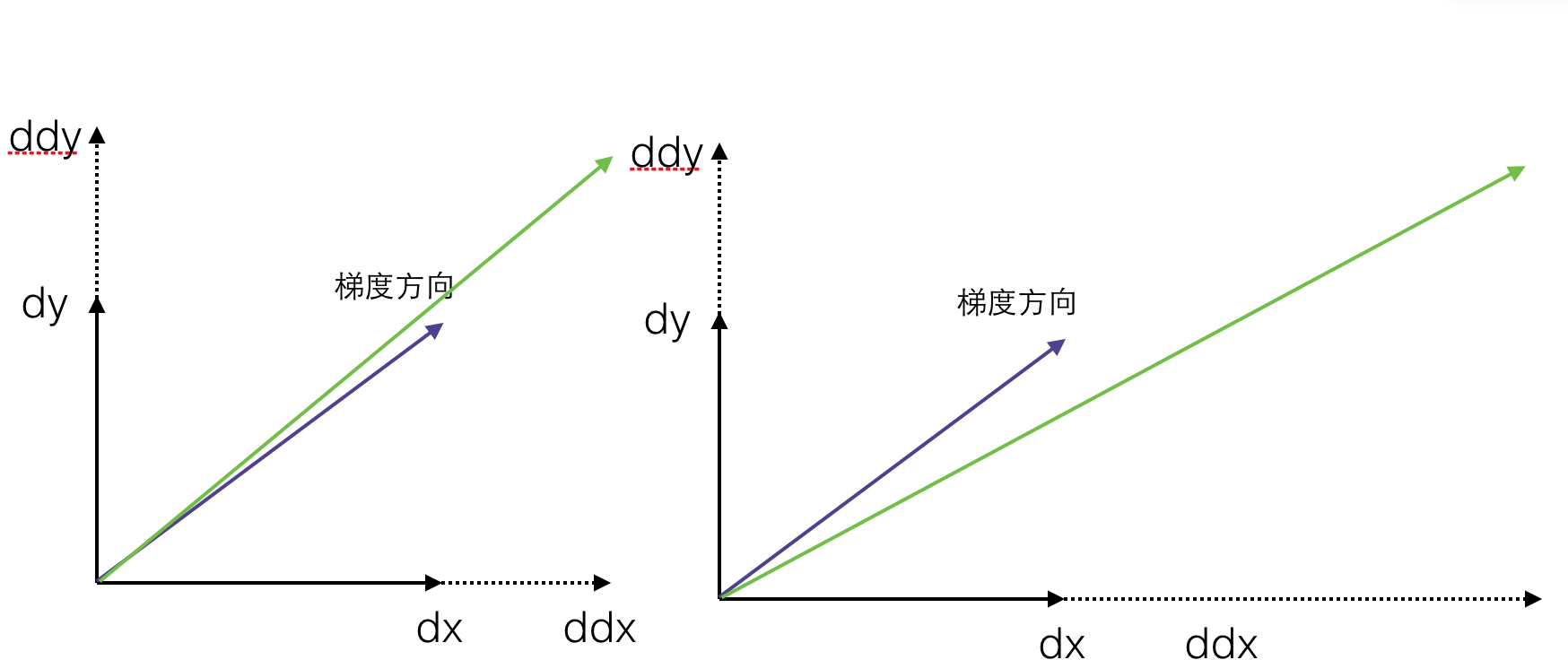
如果,Hessian矩阵不是对角阵,那么我们需要求出矩阵的特征值,最大特征值和最小的特征值之比(这个值叫做condition number)如果不大,则梯度下降法会有很好的效果。
6. 不用欧式范数用什么范数?
使用Hessian范数,牛顿法正是使用Hessian范数的最速下降法,所以牛顿法会比梯度下降法收敛更快!
hessian 范数为
∥x∥∇2f(x)=xT∇2f(x)x
(求解 △nsd=argminv(∇f(x)Tv∣∥v∥<=1) 便会得到 △nsd=H−1∇f(x))