文章目录
第一部分:折半查找
折半查找也叫二分查找,是一种效率较高的查找方法。但是折半查找要求线性表必须是顺序存储结构,而且表中元素按关键字有序排列(常用大小)。
1、查找的主要步骤
- 设置初始查找范围:
low=0,high=n-1(设置初始区间); - 查找范围中间项:
mid=(low+high)/2(取中间点位置,当low+high和为奇数时,mid向下取整,如2.5取2); - 将给定的关键字 k 与 mid 所指向的中间项的关键字进行比较:
- 若相等,查找成功,找到数据元素此时mid指向的位置;
- 若k小于中间项关键字,查找范围的低端数据元素low不变,高端数据元素指针high更新为mid-1;
- 若k大于中间项关键字,查找范围的高端数据元素high不变,低端数据元素指针low更新为mid+1;
- 重复以上步骤直到查找成功或查找范围为空(low>high,查找失败)。
2、折半查找的判定树
折半查找过程可用二叉树来描述。树中每一个结点对应表中一个记录,但结点值不是记录的关键字,而是记录在表中的位置序号。
把当前查找区间的中间位置作为根,左子表和右子表分别作为根的左子树和右子树,由此得到的二叉树称为折半查找的判定树。

利用折半查找法从上面的序列中找出元素16对应的下标:
- 此时低端元素对应下标 low=0,高端元素对应下标 high=10,中间项的下标为: m i d = ( l o w + h i g h ) / 2 = 5 mid=(low+high)/2=5 mid=(low+high)/2=5将16与mid指针指向的元素29比较(16<29),此时令: h i g h = m i d − 1 = 4 high=mid-1=4 high=mid−1=4
- 此时低端元素对应下标 low=0,高端元素对应下标 high=4,中间项的下标为: m i d = ( l o w + h i g h ) / 2 = 2 mid=(low+high)/2=2 mid=(low+high)/2=2将16与mid指针指向的元素13比较(16>13),此时令 l o w = m i d + 1 = 3 low=mid+1=3 low=mid+1=3
- 此时低端元素对应下标 low=3,高端元素对应下标 high=4,中间项的下标为: m i d = ( l o w + h i g h ) / 2 = ⌊ 3.5 ⌋ = 3 mid=(low+high)/2=\lfloor 3.5 \rfloor =3 mid=(low+high)/2=⌊3.5⌋=3将16与mid指针指向的元素16比较(16==16),查找成功,返回当前项的下标,此时返回3
为了方便观察,下面采用关键字作为结点值搭建了一颗判定树,实际在代码中结点存储的是各关键字在数组中的下标,当在树中“走”到某一结点,mid指针就指向该结点值对应的数组位置。
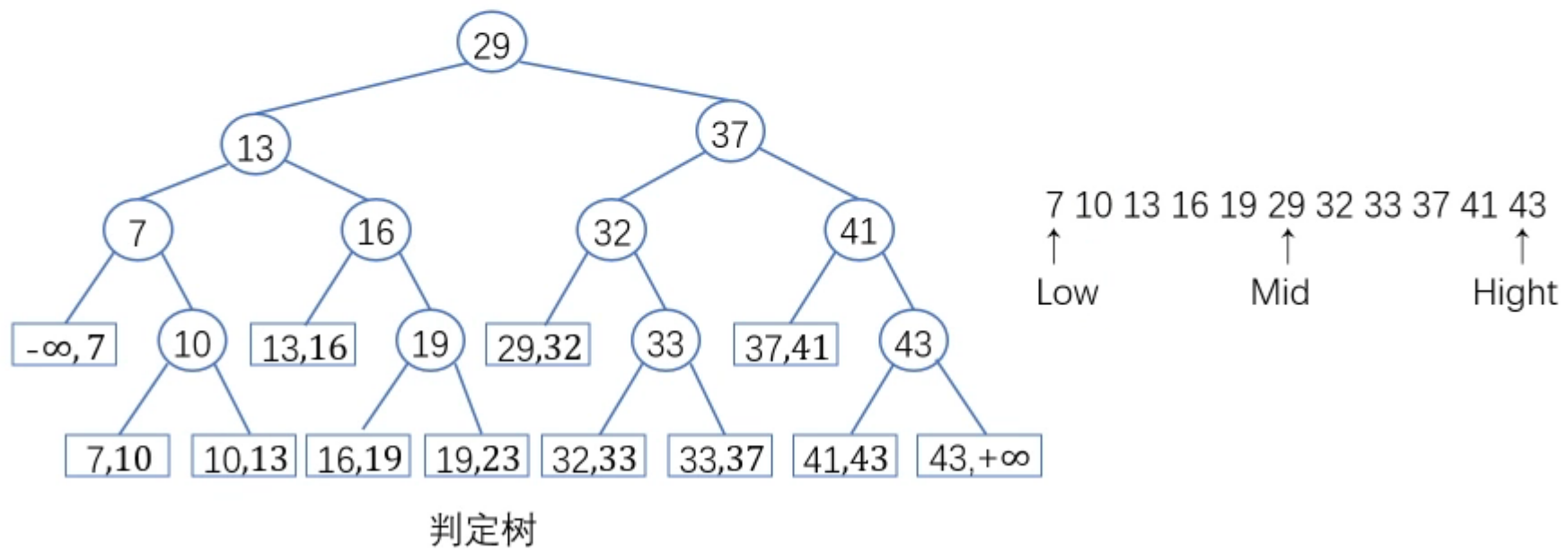
将查找过程视为二叉树上从根结点到被查节点的路径,那么所经历的关键字比较次数恰为该结点在判定树中的层次,如关键字16所在层次为3,刚好需要比较3次可以查找到。
用判定树对上面长度为11的有序表进行折半查找,查找成功/失败的平均查找长度为: { A S L 成功 = ( 1 ∗ 1 + 2 ∗ 2 + 3 ∗ 4 + 4 ∗ 4 ) / 11 = 3 A S L 失败 = ( 3 ∗ 4 + 4 ∗ 8 ) / 12 = 11 / 3 \begin{cases} ASL_{成功}=(1*1+2*2+3*4+4*4)/11= 3 \\ ASL_{失败}=(3*4+4*8)/12 = 11/3 \end{cases} {
ASL成功=(1∗1+2∗2+3∗4+4∗4)/11=3ASL失败=(3∗4+4∗8)/12=11/3【说明】在比较了三次后若发现小于第3层的结点,那么明显查找失败,所以乘以4;在比较了四次后若发现不等于第4层的结点,那么无论大于小于都明显查找失败,所以乘以8。
第一部分习题
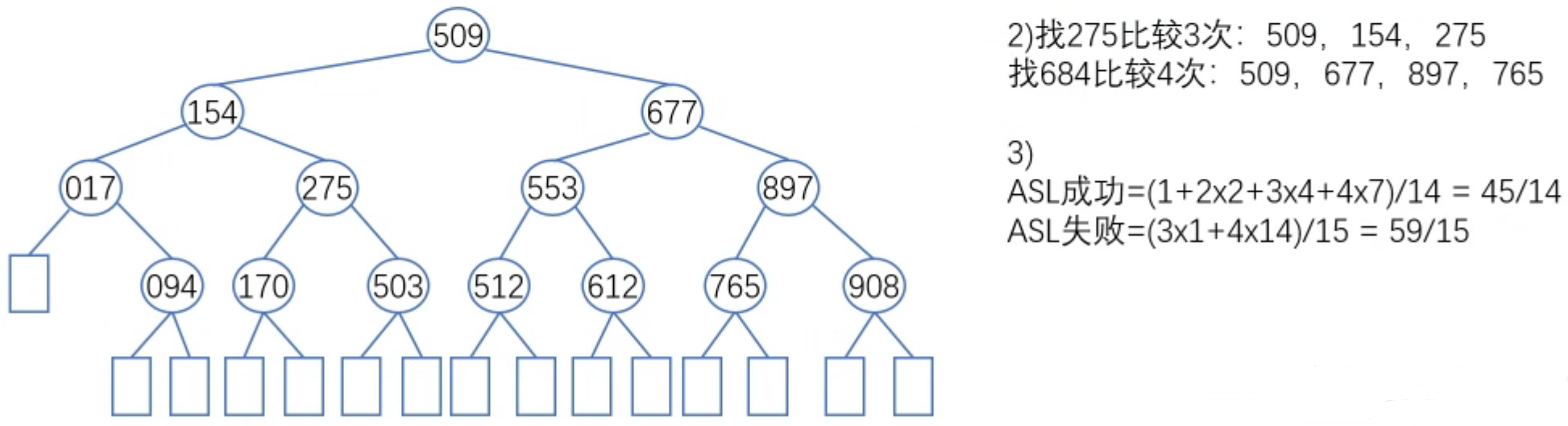
设有序顺序表中的元素依次为017,094,154,170,275,503,509,512,553,612,677,765,897,908。
(1)试画出对其进行折半查找的判定树。
(2)若查找275或684的元素,将依次与表中的哪些元素比较?
(3)计算查找成功的平均查找长度和查找不成功的平均查找长度。
第二部分:分块查找
分块查找也叫索引顺序查找,顾名思义,除表本身以外还需要额外建立一个索引表。索引表按顺序存储了各块中的最大关键字以及各块的起始地址(指示子表的第一个元素在原表中的位置)
基本思想:将查找表分为若干子块。块内的元素可以无序,但各分块之间是有序的。

在查找时需要分两步进行:
- 先确定待查记录所在的块;
- 然后再块中进行顺序查找。
分块查找的效率在顺序查找和折半查找之间,不如折半查找效果好且需要占用更多的空间,所以了解即可。
第三部分:散列查找
散列查找法也叫杂凑法或散列法。之前基于线表、树表的查找法都是以关键字的比较为基础的,查找过程中只考虑个元素关键字之间的相对大小;而散列查找法希望在元素的存储位置与关键字之间建立某种直接关系,就可以无需做比较或者做很少次的比较,依靠这种关系直接用关键字找到相应记录。
1、散列查找的常用术语
- 散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为
Hash(key)=Addr。其中Hash(哈希)函数称为散列函数,Addr称为散列地址; - 散列(Hash)表:一个有限连续的地址空间,用以存储按散列函数计算得到相应散列地址的数据记录。通常采用一维数组存储散列表,使散列地址能直接对应数组下标。
- 冲突和同义词:不同的关键字可能得到同一散列地址,这种现象称为冲突。具有相同函数值(散列地址)的关键字对该散列函数来说称作同义词。
2、常用的散列函数:
散列函数的选取要依据关键字的实际情况来决定,所以不能笼统的说哪种散列函数最好。但无论选择哪种散列函数,目标都是减少冲突产生的可能性。
- 直接定址法:
H(key) = a*key+b
式中a和b是常数,这种计算方法最简单且不会产生冲突。但它更适合于关键字的分布基本连续的情况,若关键字分布不连续,则空位较多,会浪费存储空间。 - ★★除留余数法:
H(key) = key%p
假定散列表表长为m,式中的p是一个不大于m但最近或等于m的质数。该方法类似于循环表的运作原理,当关键字“大于”表长时,从表头开始再寻找合适的存储位置。关键是要选好p,使得每个关键字通过函数后等概率的映射到散列空间上的任一地址,从而尽可能减少冲突。 - 数字分析法:
假设关键字是r进制数,从而关键字每一位上都有r种数码(如十进制的0-9就是10种数码),我们只选择其中数码分布较均匀(每种数码出现机会均等)的若干位作为散列地址。这种方法只适合于已知关键字的集合,更换关键字则需重新构造散列函数。 - 平方取中法:
顾名思义就是将关键字的平方值取中间几位作为散列地址。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀。适用于不能事先了解关键字的所有情况,或散列地址每位上的数码都不够均匀(难于从关键字中找出分布均匀的位数,两种都是数字分析法不适用的情况)。
3、处理冲突的方法:
3.1 开放定址法
可存放某一新表项的空闲地址,即向它的同义词开放,也向它的非同义词开放。通常有以下4种取法:
① 线性探测法:
该方法可以将散列表假想为一个循环表,当发生冲突时,从冲突地址的下一单元顺序寻找空单元,如果直到散列表的最后一个位置也没找到空单元,就回到表头开始继续找。如果找不到空位,说明散列表已满,报溢出错误。
【经典例题】设散列表长m=14,散列函数为H(key)=key%11(注意:若没说表长,则表长为11),表中仅有4个结点H(15)=4,H(38)=5,H(61)=6,H(84)=7。若采用线性探测法处理冲突,则关键字为49的结点地址是(A)。
A.8 B.3 C.5 D.9
【分析】查找成功/失败的平均查找长度 { A S L 成功 = ( 1 + 1 + 1 + 1 + 4 ) / 5 = 8 / 5 A S L 失败 = ( 1 + 1 + 1 + 1 + 6 + 5 + 4 + 3 + 2 + 1 + 1 ) / 11 = 26 / 11 \begin{cases} ASL_{成功}=(1+1+1+1+4)/5= 8/5 \\ ASL_{失败}=(1+1+1+1+6+5+4+3+2+1+1)/11 = 26/11 \end{cases} { ASL成功=(1+1+1+1+4)/5=8/5ASL失败=(1+1+1+1+6+5+4+3+2+1+1)/11=26/11查找成功的平均查找长度是分析已知的关键字在计算出散列函数值以后,需要比较几次才能找到正确的散列地址,所以表中有几个关键字记录就有几个求和项;
查找失败的平均查找长度是分析任意的关键字在计算出某一散列函数值后,需要比较几次才会遇到空单元,从而输出比较失败,所以函数取值范围是多少(除留取余法中等于除数值,小于等于表长值)就有多少个求和项,且仅仅在散列表存在空单元的情况下才会出现查找失败。

该方法的缺点是当第i个散列元素存入第i+1个散列地址时,原本在第i+1个地址的元素有要去争抢第i+2个散列地址,从而造成大量元素在相邻位置堆积,大大降低查找效率(从第i+1位的元素开始第一次都可能查找失败,然后要顺序向后比较)
② 平方探测法(二次探测法):
增量序列由①中的 d i = 0 , 1 , 2 , … , m − 1 d_{i}=0,1,2,…,m-1 di=0,1,2,…,m−1变为了 d i = 0 , 1 2 , − 1 2 , 2 2 , − 2 2 , … , k 2 , − k 2 d_{i}=0,1^2,-1^2,2^2,-2^2,…,k^2,-k^2 di=0,12,−12,22,−22,…,k2,−k2,也就是说此时在把关键字放入初始计算到的散列地址失败后,按平方序列一后一前的逐渐增大步长寻找散列表的空单元。需要注意散列表的长度m必须是一个可以表示成4k+3的质数,且k值小于等于m/2(因为一正一负,一个值产生两个增量,所以控制k值为一半保证了总增量个数不溢出)。
- 当加上负增量导致 H(key) 为负值时,需要再加上表长 m 将负值变为正值,该正值即为本次访问的位置。例如: 0 − 1 2 = − 1 0-1^2=-1 0−12=−1,表长为13,那么下一次应访问的下标为 − 1 + 13 = 12 -1+13=12 −1+13=12。
【经典例题】设散列表长m=14,散列函数为H(key)=key%11,表中仅有4个结点 H(15)=4,H(38)=5,H(61)=6,H(84)=7,若采用平方探测法处理冲突,则关键字为49的结点地址是(D)。
A.8 B.3 C.5 D.9

该方法的缺点是不能探测到散列表上的所有单元,但至少能探测到一半单元。
③ 再散列法:
当 d i = H a s h 2 ( k e y ) d_{i}=Hash_2(key) di=Hash2(key)时,称为再散列法,又称双散列法。需要使用两个散列函数,当通过第一个散列函数 H ( k e y ) H(key) H(key)得到的地址发生冲突时,则利用第二个散列函数 H a s h 2 ( k e y ) Hash_2(key) Hash2(key)计算该关键字的地址增量。它的具体散列函数形式如下: H i = ( H ( k e y ) + i ∗ H a s h 2 ( k e y ) ) % m H_i=(H(key)+i*Hash_2(key))\%m Hi=(H(key)+i∗Hash2(key))%m,其中 i 是冲突的次数,初始为0。
【经典例题】设有两含散列函数 H1(K)=K mod 13 和 H2(K)=K mod 11+1,散列表为T[0 … 12],用二次散列法解决冲突。函数 H1 用来计算散列地址,当发生冲突时,H2 作为计算下一个探测地址的地址增量。假定某一时刻散列表的状态为下图,下一个被插入的关键码为42,其插入位置应是(0)。

【分析】由第一个散列函数计算得到散列值 H ( 42 ) = 42 % 13 = 3 H(42)=42\%13=3 H(42)=42%13=3,散列表下标为3的位置已经存储了一个关键字,所以用第二个散列函数计算得到散列值 H a s h 2 ( 42 ) = 42 % 11 + 1 = 10 Hash_2(42)=42\%11+1=10 Hash2(42)=42%11+1=10;由于是第一个冲突,i 的值为1,计算得到插入位置 H 4 = ( 3 + 1 ∗ 10 ) % 13 = 0 H_4=(3+1*10)\%13=0 H4=(3+1∗10)%13=0。查找成功/失败的平均查找长度的计算方法同上。
④ 伪随机序列法:
当 d i = d_{i}= di=伪随机数序列时,称为伪随机序列法。可以理解为和双散列法类似,但第二个散列函数是用于生成一个伪随机数。
3.2 拉链法(链接法、链地址法)
不同于前面的开放定址法仅仅采用顺序结构存储,拉链法中为了避免非同义词发生冲突,把所有的同义词存储在一个线性链表中,这个线性链表由其散列地址唯一标识,即线性表的首元素地址存储在散列表中散列函数值对应的数组下标位置(散列表中对应下标的元素指向一个线性链表)。
【经典例题】关键字序列为 { 19,14,23,01,68,20,84,27,55,11,10,79 },散列函数 H(key)=key%13,用拉链法处理冲突,建立的表如下图所示。

【分析】由第一个散列函数计算得到散列值 H ( 42 ) = 42 % 13 = 3 H(42)=42\%13=3 H(42)=42%13=3,散列表下标为3的位置已经存储了一个关键字,所以用第二个散列函数计算得到散列值 H a s h 2 ( 42 ) = 42 % 11 + 1 = 10 Hash_2(42)=42\%11+1=10 Hash2(42)=42%11+1=10;由于是第一个冲突,i 的值为1,计算得到插入位置 H 4 = ( 3 + 1 ∗ 10 ) % 13 = 0 H_4=(3+1*10)\%13=0 H4=(3+1∗10)%13=0。查找成功/失败的平均查找长度的计算方法同上。
第三部分习题
-
使用散列函数 H(key)=key%7,把一个整数值转换成散列表下标,现要把数据 { 1,13,12,34,38,33,27,22 } 依次插入到表长为11的散列表中。使用线性探测法来构造散列表,并求查找成功及查找不成功所需的平均查找长度。

【分析】本题中采用了除留取余法,除数为7意味着计算出的散列函数值不可能在0-6这7个数以外,所以查找失败时有7个求和项;表中一共记录了8个关键字,我们分别计算出正确查找到每个关键字的比较次数,从而有8个求和项 -
使用散列函数 H(key)=key%8,把一个整数值转换成散列表下标,现要把数据 { 1,13,12,34,38,33,27,22 } 依次插入到表长为11的散列表中。
1)使用平方探测法来构造散列表。
2)求查找成功所需的平均查找长度,及查找不成功所需的平均查找长度。

【分析】本题中采用了除留取余法,除数为8意味着计算出的散列函数值不可能在0-7这8个数以外,所以查找失败时有8个求和项;表中一共记录了8个关键字,我们分别计算出正确查找到每个关键字的比较次数,从而有8个求和项 -
使用散列函数日(key)=key%11,把一个整数值转换成散列表下标,现要把数据 { 1,13,12,34,38,33,27,22 } 依次插入到散列表中。使用链地址法构造散列表。并(尝试)求查找成功所需的平均查找长度,及查找不成功所需的平均查找长度。

【分析】本题中采用了除留取余法,除数为11意味着计算出的散列函数值包含0-10这11个数,所以查找失败时有11个求和项;表中一共记录了8个关键字,我们分别计算出正确查找到每个关键字的比较次数,从而有8个求和项。
需要注意区别的是,链地址法中分析查找成功是逐层统计(和树中的查找类似,在第几层就需要比较几次),上图中第一层有4个、第二层有3个、第三层有1个;分析查找失败就是统计函数取值范围内,每个散列地址下第几次比较时指向NULL。 -
现有长度为7、初始为空的散列表 HT,散列函数 H(K)=k%7,用线性探测法解决冲突。将关键字 22,43,15 依次插人到 HT 后,查找成功的平均查找长度是(C)。
A.1.5
B.1.6
C.2
D.3
【分析】 H ( 22 ) = 22 % 7 = H ( 43 ) = 43 % 7 = H ( 15 ) = 15 % 7 = 1 H(22)=22\%7=H(43)=43\%7=H(15)=15\%7=1 H(22)=22%7=H(43)=43%7=H(15)=15%7=1,三个同义词按照线性探测法,分别存储在下标为1、2、3的三个位置,所以三个关键字的平均查找长度为: A S L 成功 = ( 1 + 2 + 3 ) / 3 = 2 ASL{成功}=(1+2+3)/3=2 ASL成功=(1+2+3)/3=2。 -
将关键字序列 { 7,8,30,1,18,9,14 } 散列存储到散列表中,散列表的存储空间是一个下标从0开始一维数组,散列函数为 H(key)=(key×3) MOD 7,处理冲突采用线性探测法,要求装载因子为 0.7。
(1)请画出所构造的散列表。
(2)分别计算等概率情况下,查找成功和查找不成功的平均查找长度。

【分析】装载因子a=表中记录数n/散列表长度m,定义为一个表的装满程度。题中由表中记录数为7,可知表长因该是10。
第一到三部分小结
折半查找是较常用的查找方法;
散列表的重点是五种冲突的解决方法,对应两个大类。

第四部分:串的模式匹配
1、串的定义
字符串简称串,即串是由零个或多个字符组成的有限序列。一般记为: S = ′ a 1 a 2 … a n ′ ( n ≥ 0 ) S='a_1a_2…a_n'(n \geq 0) S=′a1a2…an′(n≥0)其中 S 是串名,单引号内部是串的值,n 是串的长度, a i a_i ai 可以是字母、数字或其他字符。
串中任意多个连续字符组成的子序列称为该串的子串;包含子串的串称为主串;某个字符在串中的序号称为该字符在串中的位置。
2、简单的模式匹配算法——BF算法
子串的定位操作称为串的模式匹配,求的是子串(常称模式串,即用于模式匹配的串)在主串中的位置。
BF(Brute-Force)算法其实就是暴力匹配算法:(以定长顺序存储结构为例)
- 从主串和子串的第一个字符开始比较,若相等则继续比较主串和子串的第二个字符;若不相等则用主串的第二个字符与子串的第一个字符进行比较,依此类推。(也可以从某一个指定位置而非第一个字符开始比较)
- 当从主串的第 i 个字符开始,比较到中间某一字符不相等时,回溯到主串的第 i+1 个字符重新与子串的第一个字符开始比较。
- 直到在主串中有一个连续的字符序列与子串相等,则称为匹配成功,子串的位置(即返回的函数值)为第一个字符在主串中的序号;若不存在这样的字符序列则称为匹配失败。

3、改进的模式匹配算法——KMP算法
在暴力匹配算法中,每次匹配失败时都要进行回溯(子串后移一位对齐,重新开始比较),这种频繁的重复比较是导致BF算法低效的根源。而在KMP算法中,通过记录已经匹配的字符序列后方是否有和前方相同的部分,从而避免对相同的部分进行重复的比较,同时还跳过了对中间无关部分进行无意义的比较。
例如在上图中,第三趟匹配时成功匹配了序列“abca”,其中仅最后方与最前方均为“a”,所以匹配时应当跳过中间的“bc”而从“a”后继续开始主串和子串的比较。显然BF算法中第四、五趟匹配就是多余的,而KMP算法则可以完美的跳过第四、五趟匹配,并且在第六趟匹配中直接从子串的第二位“b”开始比较。
3.1 KMP算法中的几个概念
① 前缀:
除去最后一个字符外,其余的所有头部子串(包含第一个字符的子串)的集合。例如:字符串“a”的前缀为空集;字符串“ab”的前缀为 { a };字符串“abc”的前缀为 { a,ab }。
② 后缀:
除去第一个字符外,其余的所有尾部子串(包含最后一个字符的子串)的集合。例如:字符串“a”的后缀为空集;字符串“ab”的后缀为 { b };字符串“abc”的后缀为 { c,bc }。
③ 部分匹配值:
前缀与后缀的交集中,最长子串的长度作为该字符串最后一个字符的部分匹配值(PM),即前缀与后缀的最大匹配长度(maxL)。若为空集则视长度为0,即部分匹配值为0。
例如:字符串“ababa”的前缀 { a,ab,aba,abab };字符串“ababa”的后缀为 { a,ba,aba,baba };两者的交集{ a,aba }中最长子串“aba”的长度为3,所以原字符串“ababa”中最后一个字符“a”的部分匹配值为3。同理用其子串“a”、“ab”等可求得整个字符串“ababa”的部分匹配值为00123。
3.2 过渡值和next值
下面提到的子串就是模式串,个人认为叫子串比较方便理解记忆。
① 移动位数:
在上面介绍了部分匹配值之后,我们可以通过公式移动位数 = 已匹配的字符数 - (匹配成功的最后一个字符) 对应的部分匹配值PM算出子串需要向后移动的位数。
其原理是子串上一次从第 1 个字符开始成功匹配了 j-1 个字符,这时我们先将子串后移 j-1 个字符到原本的第 j 个字符处(该字符匹配失败),即先加上“已匹配的字符数”;然后由于这 j-1 个字符的后PM[j-1]个字符与前PM[j-1]个字符相同,所以我们再将其前移PM[j-1]个字符,即再减去“第 j-1 个字符对应的部分匹配值”。
② 过渡值:
由于在实际代码中,记录的 j 值是首个匹配失败的字符序号,而此时需要读取它前一个字符的部分匹配值来计算移动位数,这样有些不方便。因此我们将PM表整体右移一位,舍去最后一个字符的部分匹配值,将第一个字符的部分匹配值设为 -1,从而得到了匹配失败的字符直接可以使用的过渡值(过渡值[j] == PM[j-1])。
- 之所以舍去最后一个字符的部分匹配值,是因为部分匹配值是供给下一个字符使用的,而最后一个字符显然不会再有下一字符;
- 之所以用 -1 填补第一个字符的部分匹配值,是因为若第一个字符匹配失败,需要右移一位,而此时已匹配的字符个数为 0(0-(-1)=1)。
此时公式变为:移动位数 = 已匹配的字符数 - 匹配失败的字符对应的过渡值,即move = (j-1) - 过渡值[j]
③ next值:
在实际代码中,子串的存储位置是固定的,上面我们所说的子串“向后移动”其实是通过指针“回退”来实现的。简单来说,就是当子串在第 j 个字符匹配失败时,在主串中的指针保持在当前位置不动,而子串中的指针回退到一个合适的位置 k,在逻辑上就相当于把子串的这个位置和主串上一次比较失败的位置对齐了。这个合适的位置 k 可以通过公式:k = j-Move = j-(j-1)-过渡值[j] = 过渡值[j]+1得到,由此可知我们将过渡值全部加上1,就得到了当子串在第 j 个字符匹配失败时,指针下一次需要指向的位置(注意 k 值代表的是第 k 个字符,不是下标值),我们将该值称为next值(即next[j] = 过渡值[j]+1)。
- 我们会发现当 j=1 时 next[1] = -1+1 = 0,这里在逻辑上指的是子串指针指向第1个字符的前一个位置,然后在开始比较时主串和子串的指针各前进一个字符(使子串指针指向字符)。实际在代码中需要增加一个判定分支,当
next[j] == 0时主串指针前进一位,子串指针不变。 - 我们这里说的指针指向位置都是从下标1开始的,实际代码中采用的数组(数组操作实质是指针操作)是从下标0开始的,也就是说我们需要使用:
数组名[next[j]-1]来跳转到第 next[j] 个字符在数组中的位置。为了更方便,有些代码就把上面的过渡值数组作为next数组,此时直接可以通过数组名[next[j]]跳转到相应字符;前面判定第 1 个字符的分支条件可以改成next[j] == -1。
④ nextval值:
如果子串在第 j 个字符(j不等于1)匹配失败时,我们会让子串的比较指针指向next[j]位置,但是如果第 next[j] 个字符和第 j 个字符是一样的,那么将产生一次无意义的比较。为此我们改进了一个新的nextval数组以避免这样的情况:当第 j 个字符等于第 next[j] 个字符时,令nextval[j]=next[next[j]],以此跳过这次无意义的比较;当第 j 个字符不等于第 next[j] 个字符时,令nextval[j]=next[j],即保留原本的next值。

第四部分习题
-
串 ‘ababaaababaa’ 的 next 值和 nextval 值是多少?

-
设字符串 S = ‘aabaabaabaac’,P = ‘aabaac’。
(1)给出S和P的next数组。

(2)若S作主串,P作模式串,试给出利用BF算法和KMP算法的匹配过程。

第四部分小结
在串的模式匹配中,主要考察KMP算法。
