参考自
简介
EM算法,即期望极大算法,用于含有隐变量的概率模型的极大似然估计或极大后验概率估计,它一般分为两步:第一步求期望(E),第二步求极大(M)。
如果概率模型的变量都是观测变量,那么给定数据之后就可以直接使用极大似然法或者贝叶斯估计模型参数。
但是当模型含有隐含变量的时候就不能简单的用这些方法来估计,EM就是一种含有隐含变量的概率模型参数的极大似然估计法。
应用到的地方:混合高斯模型、混合朴素贝叶斯模型、因子分析模型。
算法推导


上述公式相当于决定了

算法流程
算法流程如下所示:

收敛性
收敛性部分可以主要看(EM算法)The EM Algorithm的推导,最终可以推导得到如下公式:
特点
- 最大优点是简单性和普适性
- EM算法不能保证找到全局最优点,在应用中,通常选取几个不同的初值进行迭代,然后对得到的几个估计值进行比较,从中选择最好的
- EM算法对初值是敏感的,不同初值会得到不同的参数估计值
使用例子
EM算法一个常见的例子就是GMM模型,即高斯混合模型。而高斯混合模型的定义如下:
高斯混合模型是指具有如下形式的概率分布模型:
>P(y|θ)=∑k=1Kαkϕ(y|θk)>其中,αk是系数,αk≥0,∑k=1Kαk=1;ϕ(y|θk)是高斯分布密度,θk=(μk,σ2k),>ϕ(y|θk)=12π−−√σkexp(−(y−μk)22σ2k)>
每个样本都有可能由
GMM的E步公式如下(计算每个样本对应每个高斯的概率):
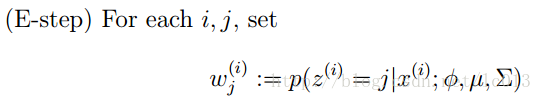
更具体的计算公式为:
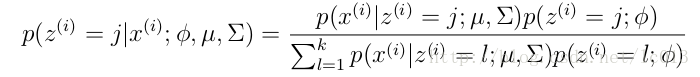
M步公式如下(计算每个高斯的比重,均值,方差这3个参数):
