EM(Exception Maximization)算法
引言:在动笔之前,我在网上翻阅了许多的资料,生怕自己理解的不透彻,网上也有许多良心之作,对我理解该算法起到了巨大的帮助作用,EM算法既简单又复杂,简单在于它的思想是非常简单的,仅包含两个步骤就能完成强大的功能,复杂在于它对数学基础要求比较高,公式推导相对比较繁琐,可能世界上最伟大的东西都是这样吧,越是简单的东西却有着复杂的机理,但是越复杂的东西有时又蕴含着简单的道理。下面就把我在学习该算法的过程写下来,希望对后面的人学习有所帮助!
一、极大似然估计
在介绍EM算法之前,需要先复习一下极大似然估计,什么是极大似然估计呢?举个例子,假定现在需要调查我们学校男生和女生的身高分布,这么多学生怎么办,不可能一个一个去问吧,所以就需要抽样。现在在学校随机抽取了100位男生和100位女生,分别统计他们的身高,从统计学角度可以知道男生和女生的身高分别是服从高斯分布的,但是这两个分布的均值和方差
都不知道,所以我们就需要从这些样本中来估计这两个参数,记作
。下面先以男生的身高分布说明,女生的同理。
在学校这么多男生中,我们独立的按照概率密度抽取了100个人,组成了样本集X,我们想通过样本集X来估计出参数
,这里的概率密度
是高斯分布
的概率密度函数,其中的未知参数是
,抽到的样本集是
,其中
表示抽到的第i个人的身高,i在这里最大值取100,表示抽到的样本个数。这些样本都是独立选择的,所以同时抽到这100个男生的概率就等于他们各自的概率乘积,即从分布是
的总体样本中抽取到这100个样本的概率,就是样本集X中各个样本的联合概率,用下式表示:
就是我们的样本值,是已知的,那么上式就表示在参数
已知的情况下抽取得到的这个样本的概率,这里的
就是参数
相对样本集的似然函数(likehood function)。
似然函数在这里可以这样理解,X样本代表一个目标函数或者是一个事实,现在的目标是通过调整参数使得刚才的这些样本出现的概率最大。这是一个反推过程,就是已经知道一个结果,就是找到了出现这个结果的最大概率。
的极大似然估计量,记为:
为了方便分析,可以定义对数似然函数,将其变为连加的形式:
ok,现在我们知道,要求,只需要使
的似然函数
最大化,然后极大值对应的
就是我们的估计。问题这个时候就转化为怎么样求解函数
的极值,当然就是利用求导,令导数值为0,此时解出
就可以了,但是前提必须是函数
是连续可导的。如果
是包含多个参数的向量,那么就对所有的参数求偏导,有n个未知的参数,就有n个方程,方程组的解就是似然函数的极值点了。
总结一下求最大似然估计值得一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然函数;
(4)解似然方程,得到的参数即为所求;
好了,说到这里,还不知道似然函数和EM算法有什么联系,我们注意到这里的参数只是对应了一个类别,即男生的身高或者女生的身高,就是在已知这一群人都是男生或者女生的情况下,获得这个类别的参数。如果我抽取的100个样本中既有男生又有女生,相当于两个高斯分布混合在一起,这个时候要想估计参数,就要用到下面介绍的EM(期望值最大化)算法了。
二、EM(期望值最大化)算法
1.Jensen不等式
这里有一些优化理论的概念,没听过的也不用担心。设f是定义域为实数的函数,对于所有的实数x,,那么f函数是凸函数。如果x是向量时,如果其hessian矩阵H是半正定的
,那么f是凸函数,如果
或者
,称f是严格的凸函数。
Jensen不等式可以表述如下:
如果f是凸函数,X是随机变量,那么:
特别地,如果f是严格的凸函数,那么当且仅当
,即X是常量时成立。
用图表示会比较直观:
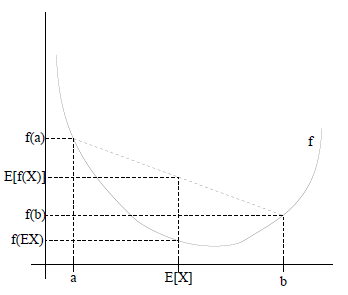
图中,灰色实线f是凸函数,X是随机变量,有0.5的概率取a,有0.5的概率取b,X的期望值就是a和b的中值了,从图中可以看到成立。
Jensen不等式应用于凹函数是,不等号方向相反,即
2.EM算法的推导
给定一组训练样本,样本间独立,我们想找到每个样本间隐含的类别z,能使
最大,
的最大似然估计如下:
式中第一个等号是对极大似然估计取对数,第二步是对每个样例间的每个可能类别z求联合分布概率和,直接求一般比较困难,因为有隐含变量z的存在,但是在确定了z之后,求解就相对比较容易了。
EM是一种解决存在隐含变量优化问题的有效方法,不能直接最大化,但是可以不断的建立
的下界(E步),然后优化下界(M步),具体是怎么操作的,我们继续往下走。
对于每一个样本,用
表示该样本隐含变量z的某种分布,若z是离散的,那么
满足条件是:
如果z是连续变量,那么表示的是概率密度,此时需要将求和改写为积分,即:
举一个例子,比如要将班上同学聚类,假设隐藏变量z是身高,那么就是连续的高斯分布,但是如果隐藏变量z是男女性别,那么就是伯努利分布了。
由前面的内容可以得到下面的公式:
上面的式子中(1)到(2)比较直接,乘一项除一项,结果不变。而(2)到(3)就用到了上面介绍的Jensen不等式,这里函数是凹函数(二阶导数小于0)。
这里的就是变量
的期望。
这里如果不懂的话,请看下面的这个期望公式。

对应于上面的问题,Y是,X对应于
,
是
,g是
到
的映射,这样就解释了式子(2)中的期望,再根据凹函数的Jensen不等式:
得到(3)式。
上面的(2)式和(3)式可以写成:似然函数,那么我们可以通过不断最大化这个下界,来使得
不断提高,最终达到它的最大值。

式(2),(3)过程可以看作是对求了下界,对于
的选择,有许多种可能,那么哪一种更好呢?不妨假定
已经给定,那么
的值就取决于
和
了。通过调整这两个参数使得下界不断上升,以逼近
的真实值,那么什么时候算是调整好了呢?当然是当等号成立时,说明调整后的值等价于
了。按照这个思路,我们要找到等式成立的条件,根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,所以可以得到:
其中c为常数,并不依赖于,对此式进行进一步推导,我们已知
,那么也就有
,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c)。那么可以得到:
至此,我们在固定参数 后,
的计算公式就是后验概率,解决
如何选择的问题,这一步就是E步,建立
的下界,接下来就是M步,就是在给定
后,调整
,去极大化
的下界。那么一般EM算法的步骤归纳起来如下:
| 循环重复直到收敛{ (E步)对于每一个i,计算 (M步) 计算 } |
那么究竟怎么样确保EM算法收敛了呢?假定和
是EM第t次和第t+1次迭代后的结果,如果证明了
,也就是说极大似然估计单调增加,最终我们会到达最大似然估计的最大值,下面来证明一下,当选定
后,得到E步:
这一步保证了在给定时,Jensen不等式中的等式成立,也就是说
然后进行M步,将看作是变量,最大化等式右侧可以得到
,于是有:
(4)式来自于之前得到这个公式,对所有和
都成立:
我们在得到时,只是最大化
,也就是
的下界,此时等式还未成立,等式成立只有是在固定
,并按照E步得到
时才能成立。第(5)步利用了M步定义,M步就是将
调整到
,使得下界最大化,因此(5)式成立,(6)是之前定义的。
至此就证明了会单调增加,一种收敛方法是
不在变化,还有一种就是变化的幅度很小。
这里有必要在解释一下(4)(5)(6),首先(4)对所有的参数成立,而其等号成立的条件只是在固定,并调整好
时成立,而第(4)步只是固定
,调整
,不一定保证等式一定成立。(4)到(5)式就是M步的定义,(5)到(6)是前面E步所保证等式成立条件,也就是说E步会将下界拉到与
一个特定值(这里
)一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升了,但达不到与
的另外一个特定值(
)一样的高度,之后在经过E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
如果我们定义:
从前面我们可以知道,EM算法可以看作是坐标上升法,E步固定
,优化
,M步固定
,优化
。
坐标上升法:

图中的直线是迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
这犹如在x-y坐标系中找到一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降法就不适用了,但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外一个求极值,最后逐步逼近极值。对应到EM上,E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
3. 代码实现(模拟两个正态分布的均值估计)
本代码用于模拟k=2个正态分布的均值估计,其中ini_data(Sigma,Mu1,Mu2,k,N)函数用于生成训练样本,此训练样本是从两个高斯分布中随机生成的,其中高斯分布a均值Mu1=40、均方差Sigma=6,高斯分布b均值Mu2=20、均方差Sigma=6,生成的样本分布如下图。本问题实现两个无法直接从样本数据中获知的两个高斯分布参数,因此需要使用EM算法估算出具体的·Mu1,Mu2取值。

图 样本数据分布
在图1的样本数据下,在第11步时,迭代终止,EM估计结果为:Mu=[19.63731306 40.32233867]
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
isdebug = False
# 指定k个高斯分布参数,这里指定k=2。注意2个高斯分布具有相同均方差Sigma,分别为Mu1,Mu2。
def ini_data(Sigma,Mu1,Mu2,k,N):
global X
global Mu
global Expectations
X = np.zeros((1,N))
Mu = np.random.random(2)
Expectations = np.zeros((N,k))
for i in range(0,N):
if np.random.random(1) > 0.5:
X[0,i] = np.random.normal()*Sigma + Mu1
else:
X[0,i] = np.random.normal()*Sigma + Mu2
if isdebug:
print ("***********")
print (u"初始观测数据X:")
print (X)
# EM算法:步骤1,计算E[zij]
def e_step(Sigma,k,N):
global Expectations
global Mu
global X
for i in range(0,N):
Denom = 0
for j in range(0,k):
Denom += math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
for j in range(0,k):
Numer = math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
Expectations[i,j] = Numer / Denom
if isdebug:
print ("***********")
print (u"隐藏变量E(Z):")
print (Expectations)
# EM算法:步骤2,求最大化E[zij]的参数Mu
def m_step(k,N):
global Expectations
global X
for j in range(0,k):
Numer = 0
Denom = 0
for i in range(0,N):
Numer += Expectations[i,j]*X[0,i]
Denom +=Expectations[i,j]
Mu[j] = Numer / Denom
# 算法迭代iter_num次,或达到精度Epsilon停止迭代
def run(Sigma,Mu1,Mu2,k,N,iter_num,Epsilon):
ini_data(Sigma,Mu1,Mu2,k,N)
print ("初始<u1,u2>:", Mu)
for i in range(iter_num):
Old_Mu = copy.deepcopy(Mu)
e_step(Sigma,k,N)
m_step(k,N)
print (i,Mu)
if sum(abs(Mu-Old_Mu)) < Epsilon:
break
if __name__ == '__main__':
run(6,40,20,2,1000,1000,0.0001)
plt.hist(X[0,:],50)
plt.show()4、EM算法的应用
如果将样本看作观察值,潜在类别看作是隐藏变量,那么聚类问题也就是参数估计问题,只不过聚类问题中参数分为隐含类别变量和其他参数。EM算法及其改进版本被用于机器学习算法的参数求解,常见的例子包括高斯混合模型(Gaussian Mixture Model, GMM) 、概率主成份分析(probabilistic Principal Component Analysis) 、隐马尔科夫(Hidden Markov Model, HMM)等非监督学习算法。EM算法可以给出隐变量,即缺失数据的后验分布 ,因此在缺失数据问题(incomplete-data probelm)中有重要应用。
5、参考文献
[1] https://blog.csdn.net/zouxy09/article/details/8537620
[2] https://blog.csdn.net/fuqiuai/article/details/79484421
[3] http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html#!comments
[4] http://cs229.stanford.edu/notes/cs229-notes8.pdf
2019年3月29日