● 每周一言
动嘴,动脑,都不如动手去做。
导语
在分析样本数据情况时,都需要看一看方差。在概率统计学中,方差是衡量数据离散程度的一种度量,样本的方差越大,样本间的偏离程度就越大,反之越小。而在数据量巨大或者较难获得总体样本时,按照方差标准公式计算出来的实际方差,通常并非样本的真实方差。
因此,为了保证无偏计算,大数据量下用采样数据计算方差时,是除以n-1而不是n。那么,为什么除以n-1就能保证计算出来的方差是真实方差?
方差
在详细推导过程前,我们先明确以下几个数学符号的概念。n表示可采样的样本数量,xi表示样本数据,x拔表示样本均值,μ表示样本的真实均值,S平方表示样本实际方差,σ平方表示样本真实方差,D(x)表示随机变量x的方差。
根据方差的标准计算公式,有如下推导:
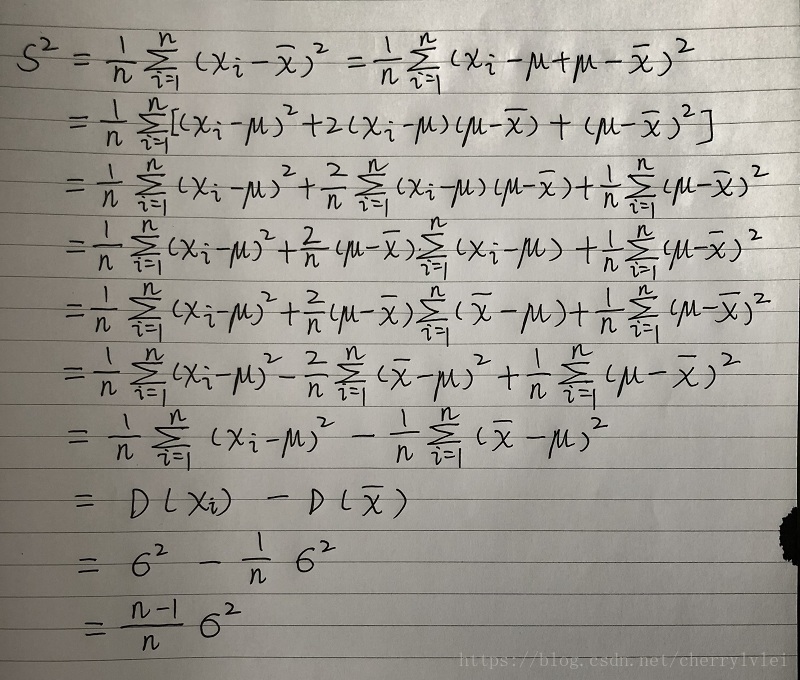
上式第一个比较关键的变换是第四行到第五行。由于第四行中间式子的后半段是样本数据累加,因此可以把xi替换成x拔,使累加结果不改变。
此外,由于μ和x拔在既定样本集上是固定的,第三行到第四行和第五行到第六行的推导,可以这样把 (μ - x拔) 先提出来又放进累加操作。
第二个比较关键的变换是平均数x拔的方差,是样本方差的n分之一。这个可以利用方差变换公式来推导,如下:
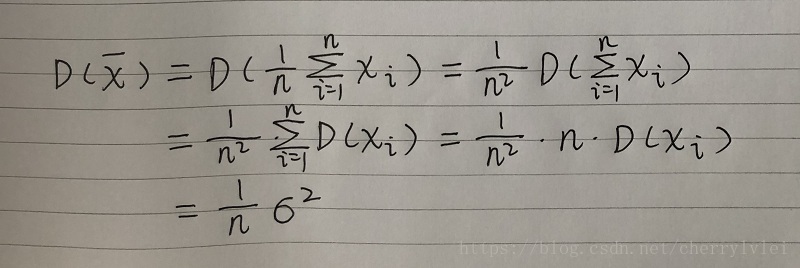
这里解释一下为什么每一个样本xi的方差,都等于样本的总体方差。
样本xi代表所有可能出现的情况,每一个x1、x2、x3…都分别可以看作是一个随机变量,而这些随机变量之间没有差别,其分布也跟样本总体分布相同,所以它们的方差自然也是相同的。

上面的推导是针对一维数据的方差推导,当然,推广到多维数据也是同样适用的。
这里顺便介绍一下多维数据的方差,多维数据的方差称为 协方差。协方差是衡量样本数据不同维度之间变化关系的度量,具体计算公式如下:
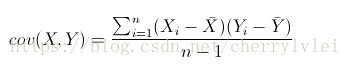
虽然叫协方差,但是意义和方差不同。协方差大于0表示X和Y正相关,小于0则表示负相关,等于0则不相关,值越大或越小表示它们的相关程度越高。协方差还能得出皮尔森相关系数的计算公式。
在多维数据情况下,通常使用协方差矩阵来表示不同维度之间的协方差。
以上便是方差的讲解,敬请期待下节内容。
结语
感谢各位的耐心阅读,后续文章于每周日奉上,敬请期待。欢迎大家关注小斗公众号 对半独白!
