版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38038143/article/details/83895851
GitHub:https://github.com/GYT0313/Hadoop-JavaAPI-Code/tree/master/chapter4/wordcount
1.创建项目
创建三个类:
Mapper、Reducer、Main驱动类(需要导入 jar包)
2.代码
- WordMapper.java:
package wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author: Gu Yongtao
* @Description:
* @date: 2018年11月6日 下午4:17:05
* @Filename: WordMapper.java
*/
public class WordMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// Mapper类的核心方法
/**
* key 首字符偏移量
* value 文件的一行内容
* context Mapper端的上下文
* @throws InterruptedException
* @throws IOException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); // 分割输入行为key,默认以空格/回车...分割
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
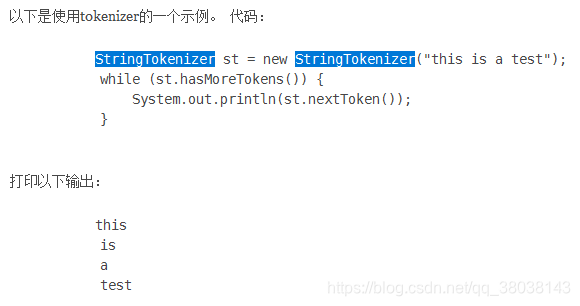
分析:StringTokenizer itr = new StringTokenizer(value.toString());
- WordReducer.java:
package wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author: Gu Yongtao
* @Description:
* @date: 2018年11月6日 下午4:40:16
* @Filename: WordReducer.java
*/
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); // 记录词的频数
// Reducer抽象类的核心方法
public void reduce (Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 遍历values 将 list<value> 叠加
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
- WordMain.java:(IP地址根据自身集群配置)
package wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* @author: Gu Yongtao
* @Description:
* @date: 2018年11月6日 下午4:53:59
* @Filename: WordMain.java
*/
public class WordMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// Configuration类:读取配置文件内容-core-site.xml
Configuration conf = new Configuration();
// 读取命令行参数,并设置到conf
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) { // 输入目录 输出目录
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
Job job = new Job(conf, "word count"); // 新建一个job
job.setJarByClass(WordMain.class); // 设置主类
job.setMapperClass(WordMapper.class); // 设置Mapper类
job.setCombinerClass(WordReducer.class); // 设置作业合成类
job.setReducerClass(WordReducer.class); // 设置Reducer类
job.setOutputKeyClass(Text.class); // 设置输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置输出值类
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
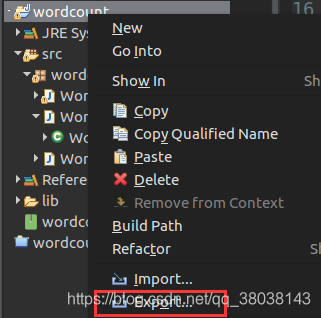
3.导出jar包:
右键项目,点击Export:
选择 JAR file:
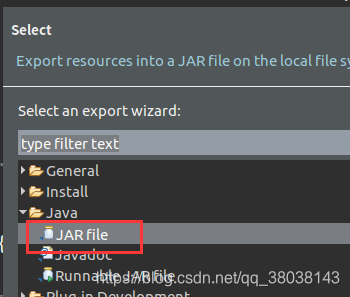
点击Next,勾选wordcount工程中的 src,并选择保存的路径名(包含最终的文件名),点击Finish:
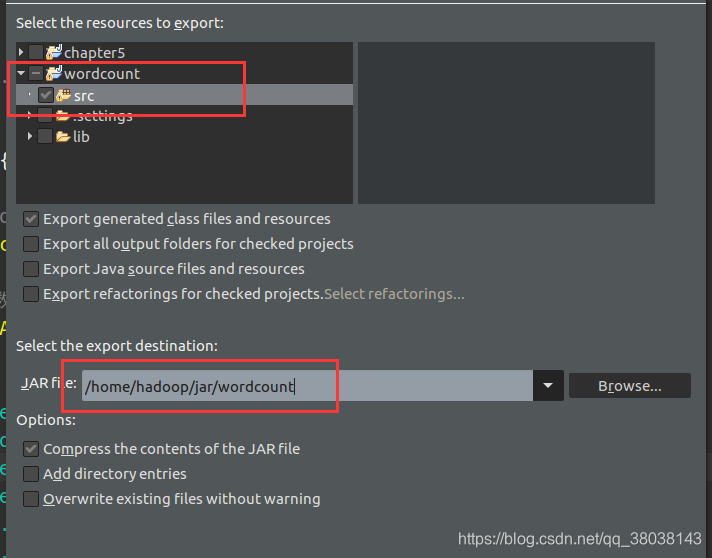
导出的jar包:

4.运行jar包
运行格式:
hadoop jar [jar 文件位置] [jar 主类] [HDFS 输入路径] [HDFS 输出路径]
准备输入文件:使用hdfs shell命令写入文件内容(-appendToFile使用ctrl + c结束 | 也可以使用-put 上传本地文件)
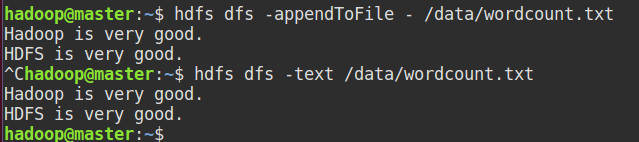
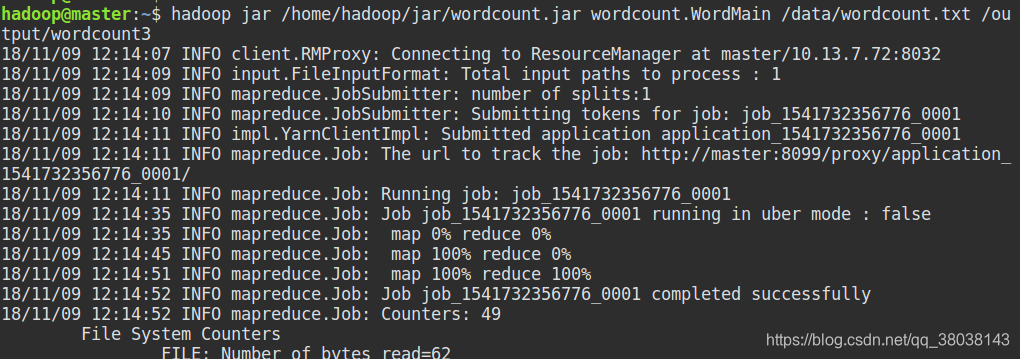
执行任务:
hadoop jar /home/hadoop/jar/wordcount.jar wordcount.WordMain /data/wordcount.txt /output/wordcount3
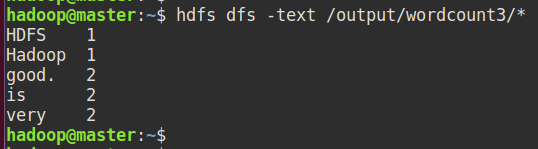
查看输出:
总结:
使用JavaAPI编写wordcount实例,可以根据自己需要设置分隔符,而不再单纯的以空格/回车… 为分割。
只需要设置StringTokenizer的实例即可,如:
