摘要:
让深度网络意识到自己预测的质量是一个有趣但重要的问题。在实例分割的任务中,实例分类的置信度被用作大多数实例分割框架中的掩模质量分数。然而,掩模质量(量化为实例掩模与其基础事实之间的IoU)通常与分类得分没有很好的相关性。在本文中,我们研究了这个问题,并提出了Mask Scoring R-CNN,它包含一个网络块来学习预测实例掩码的质量。所提出的网络块将实例特征和对应的预测掩模一起用于对掩模IoU进行回归。掩模评分策略校准掩模质量和掩模评分之间的未对准,并通过在COCO AP评估期间优先化更准确的掩模预测来改善实例分割性能。通过对COCO数据集的广泛评估,Mask Scoring R-CNN为不同的模型带来了一致且显着的增益,并且优于最先进的Mask R-CNN。我们希望我们简单有效的方法将为改进实例细分提供新的方向。方法源代码地址https://github.com/zjhuang22/maskscoring_rcnn。
1、简介
深度网络正在极大地推动计算机视觉的发展,导致一系列最先进的任务,包括分类,对象检测,语义分割等。从计算机视觉深度学习的发展,我们可以观察到深度网络正逐渐从图像级预测到区域/盒级预测,像素级预测和实例/掩模级预测逐渐增长。进行细粒度预测的能力不仅需要更详细的标签,还需要更精细的网络设计。
在本文中,我们关注实例分割的问题,这是对象检测的自然下一步,从粗略的盒级实例识别转移到精确的像素级分类。具体来说,这项工作提出了一种新的方法来对实例分割假设进行评分,这对于例如分割评估非常重要。原因在于大多数评估指标是根据假设得分定义的,更精确的得分有助于更好地表征模型性能。例如,精确召回(P-R)曲线和平均精度(AP)通常用于具有挑战性的实例分割数据集COCO。如果一个实例分割假设未被正确评分,则可能被错误地视为假阳性或假阴性,导致AP减少。
但是,在大多数实例分割管道中,例如Mask R-CNN和MaskLab,实例掩码的分数与盒级分类置信度共享,这是由应用于提议特征的分类器预测的。 使用分类置信度来测量掩模质量是不合适的,因为它仅用于区分提议的语义类别,并且不知道实例掩码的实际质量和完整性。 分类置信度和掩模质量之间的不对准在图1中示出,其中实例分割假设获得准确的盒级定位结果和高分类分数,但是相应的掩模是不准确的。 显然,使用这种分类分数对掩模进行评分往往会降低评估结果。

图1:实例分割的示例性案例,其中边界框与地面实况具有高重叠并且在掩模不够好的 情况下具有高分类分数。Mask R-CNN和我们提出的MS R-CNN预测的分数被附加在它们相应的边界框上方。左侧四幅图像显示出良好的检测结果,具有高分类分数但掩模质量低。我们的方法旨在解决这个问题。最右边的图像显示了具有高分类分数的良好掩模的情况。我们的方法将重新训练高分。可以看出,我们模型预测的分数可以更好地解释实际的面罩质量。
与之前旨在获得更准确的实例定位或分割掩膜的方法不同,我们的方法侧重于对掩膜进行评分。为了实现这一目标,我们的模型学习每个掩膜的分数而不是使用其分类分数。为清楚起见,我们称学习得分为掩码得分。
受实例分割的AP度量的启发,该实例分割使用预测掩模与其地面实况掩模之间的像素级交叉联盟(IoU)来描述实例分割质量,我们建议网络直接学习IoU。 在本文中,该IoU表示为MaskIoU。 一旦我们在测试阶段获得预测的MaskIoU,则通过将预测的MaskIoU和分类得分相乘来重新评估掩模得分。 因此,掩码分数知道语义类别和实例掩码完整性。
学习MaskIoU与提案分类或掩码预测完全不同,因为它需要“比较”预测的掩码和对象特征。在Mask RCNN框架内,我们实现了一个名为MaskIoU head的MaskIoU预测网络。 它将掩模头的输出和RoI特征作为输入,并使用简单的回归损失进行训练。 我们将所提出的模型,即具有MaskIoU头的Mask R-CNN命名为Mask Scoring R-CNN(MS R-CNN)。我们已经对我们的MS R-CNN进行了大量实验,结果表明我们的方法提供了一致且显着的性能改善,这归因于掩模质量和得分之间的一致性。
总之,这项工作的主要贡献如下:
1.我们提出了Mask Scoring R-CNN,这是解决实例分割假设评分问题的第一个框架。 它探讨了提高实例分割模型性能的新方向。考虑到实例掩码的完整性,如果掩码不够好但是实例掩码的分数很高,则可能会受到惩罚。
2.我们的MaskIoU head非常简单有效。 在具有挑战性的COCO基准测试中的实验结果表明,当使用来自我们的MS R-CNN的掩模得分而不仅仅是分类置信度时,AP在各种骨干网络上始终如一地提高约1.5%。
2、相关工作
2.1 实例分割
当前实例分割方法可大致分为两类。一种是基于检测的方法,另一种是基于分割的方法。基于检测的方法利用最先进的检测器,如Faster R-CNN, R-FCN [8],得到每个实例的区域,然后预测每个区域的掩模。Pinheiro等人提出DeepMask以滑动窗口方式对中心对象进行分割和分类。Dai等人提出了实例敏感的FCNs来生成位置敏感的地图并将它们组合起来以获得最终的掩模。 FCIS采用具有内/外分数的位置敏感地图来生成实例分割结果。He等人通过添加实例级语义分段分支,提出了优于Faster R-CNN的Mask R-CNN。基于Mask RCNN,Chen等人提出MaskLab使用位置敏感分数来获得更好的结果。然而,这些方法的一个潜在缺点是掩模质量只由分类分数来衡量,从而导致了上面讨论的问题。
基于分割的方法首先预测每个像素的类别标签,然后将它们组合在一起以形成实例分割结果。 梁等人。 [24]使用谱聚类来聚类像素。 其他工作,例如[20,21],在聚类过程中添加边界检测信息。 Bai等人 [1]预测了像素级能量值和用于分组的分水岭算法。最近,有一些工作[30,11,14,10]使用度量学习来学习嵌入。具体而言,这些方法学习每个像素的嵌入,以确保来自相同实例的像素具有类似的嵌入。然后,对学习的嵌入执行聚类以获得最终实例标签。由于这些方法没有明确的分数来测量实例掩码质量,因此他们必须使用平均像素级分类分数作为替代。
上述两种方法都没有考虑掩模评分和掩模质量之间的对齐。由于掩模得分的不可靠性,IoU对ground truth越高的掩模假设,如果掩模得分越低,其优先级越低。在这种情况下,最终的AP因此降级。
2.2 检测成绩更正
目前有几种针对检测框分类分值进行校正的方法,其目的与我们的方法相似。Tychsen-Smith等人提出了Fitness NMS使用IoU之间检测到的边界框和他们的真实标签。将box IoU预测作为分类任务。**我们的方法与此方法的不同之处在于我们将掩模IoU估计表示为回归任务。Jiang等[19]提出IoU-Net直接对box IoU进行回归,预测的IoU用于NMS和边界框细化。 在[5]中,Cheng等人讨论了假阳性样本并使用分离的网络来校正这些样本的得分。SoftNMS [2]使用两个框之间的重叠来校正低分框。Neumann等[29]提出了Relaxed Softmax来预测标准softmax中的温度比例因子值,用于安全关键行人检测。
与专注于边界框级别检测的这些方法不同,我们的方法设计用于实例分割。在我们的Mask-IoU head中进一步处理实例掩码,以便网络可以知道实例掩码的完整性,并且最终掩码分数可以反映实例分段假设的实际质量。这是提高实例分割性能的一个新方向。
3、方法
3.1 动机
在当前的Mask R-CNN框架中,检测(即,实例分割)假设的分数由其分类分数中的最大元素确定。由于背景杂乱,遮挡等问题,分类得分可能高但掩模质量低,如图1所示的例子。为了定量分析这个问题,我们将Mask R-CNN的vanilla mask评分与预测的mask和它的真实标签掩码(MaskIoU)之间的实际IoU进行比较。具体来说,我们使用Mask R-CNN和ResNet-18 FPN在COCO 2017验证数据集上进行实验。然后我们在Soft-NMS之后选择MaskIoU和分类分数大于0.5的检测假设。MaskIoU在分类分数上的分布如图2(a)所示,每个MaskIoU区间的平均分类分数在图2(c)中以蓝色显示。这些图显示分类得分和MaskIoU在Mask R-CNN中没有很好地相关。
图2。比较掩模R-CNN和我们提出的MS R-CNN。(a)显示Mask R-CNN的结果,Mask score与MaskIoU的关系较小。(b)显示MS R-CNN的检测结果,我们用高评分和低MaskIoU来惩罚检测,掩模评分可以更好地与MaskIoU相关。©给出量化结果,将每个MaskIoU区间的得分取平均值,可以看出我们的方法与MaskIoU之间有更好的对应关系.
在大多数实例分割评估协议中,如COCO,低MaskIoU和高分数的检测假设是有害的。在许多实际应用中,确定检测结果何时可以信任,何时不能信任[29]非常重要。这促使我们学习一个校准的mask评分根据马斯基奥的每一个检测假设。在不失一般性的前提下,我们研究了Mask R-CNN框架,并提出了相应的解决方案Mask Scoring R-CNN (MS R-CNN),加上MaskIoU head 模块Mask R-CNN可以学到对应mask分数更高。我们框架预测到的mask得分显示在图2(b)和图2(c)的橙色直方图中。
3.2 Mask R-CNN中的掩膜得分
掩模评分R-CNN在概念上很简单:使用MaskIoU Head的 Mask R-CNN,它将实例特征和预测的掩模一起作为输入,并预测输入掩模和真实标签掩模之间的IoU,如图3所示。 以下部分中我们框架的详细信息。
图3. Mask Scoring R-CNN的网络架构。 输入图像被馈送到骨干网络,以通过RPN生成RoIs并且通过RoIAlign生成RoI。 RCNN head和mask head是Mask R-CNN的标准组件。 为了预测MaskIoU,我们使用预测的mask和RoI特征作为输入。 MaskIoU head有4个卷积层(所有都有内核= 3,最后一个使用stride = 2进行下采样)和3个完全连接的层(最后一个输出C类MaskIoU。)
Mask R-CNN:我们首先简要回顾一下Mask R-CNN [15]。Faster R-CNN [33],Mask R-CNN都由两个阶段组成。第一阶段是候选区域网络(RPN)。无论对象类别如何,它都会提出候选对象边界框。第二阶段称为R-CNN阶段,它使用RoIAlign为每个候选提取特征,并执行候选分类,边界框回归和掩模预测。
Mask scoring:我们将Smask定义为预测掩膜的得分。理想的Smask等于预测掩模与其匹配的真实标签掩模之间的像素级IoU,之前称为MaskIoU。理想的Smask也应该只对真实标签类别有正值,对于其他类别应该为零,因为掩模只属于一个类。这需要掩码得分在两个任务上表现良好:将掩码分类到正确的类别,并回归候选的MaskIoU用于前景对象类别。
仅使用单个目标函数很难训练这两个任务。为了简化,我们可以将掩码得分学习任务分解为掩码分类和IoU回归,表示为所有对象类别的Smask = Scls · Siou。Scls侧重于对属于哪个类的预测进行分类,并且Siou专注于回归MaskIoU。
至于Scls,Scls的目标是对属于哪个类的预测进行分类,这已经在R-CNN阶段的分类任务中完成。所以我们可以直接拿相应的分类得分。回归Siou是本文的目标,将在下一段中讨论。
MaskIoU head: MaskIoU head旨在回归预测掩模与其真实标签掩模之间的IoU。我们使用RoIAlign图层的特征串联和预测的掩模作为MaskIoU head的输入。在连接时,我们使用内核大小为2且步幅为2的最大池化层,以使预测的掩模具有与RoI特征相同的空间大小。我们只选择将MaskIoU回归到真实标签类(用于测试,我们选择预测的类)而不是所有类。我们的MaskIoU head由4个卷积层和3个完全连接的层组成。对于4个卷积层,我们遵循Mask head并将所有卷积层的内核大小和过滤器数分别设置为3和256。对于3个完全连接(FC)层,我们遵循RCNN head并将前两个FC层的输出设置为1024,将最终FC的输出设置为类的数量。
Training: 为了训练MaskIoU head,我们使用RPN预测作为训练样本。 训练样本需要在预测框和匹配的真实标签框之间具有大于0.5的IoU,这与Mask R-CNN的Mask head的训练样本相同。为了生成每个训练样本的回归目标,我们首先获得目标类的预测掩码,并使用阈值0.5对预测掩码进行二值化。
然后我们在二元掩模和它匹配的真实标签之间使用MaskIoU作为MaskIoU目标。我们使用L2损失来回归MaskIoU,并且将损失权重设置为1。预测的MaskIoU head被集成到Mask R-CNN中,并且整个网络是端对端训练的。
Inference: 在推理过程中,我们只使用MaskIoU head来校准从R-CNN生成的分类分数。具体地,假设Mask R-CNN的R-CNN级输出N个边界框,并且其中在选择SoftNMS [2]之后的top-k(即k = 100)得分框。然后将前k个盒子送入Mask head以生成多类掩码。这是标准的Mask R-CNN推理程序。 我们也遵循这个程序,并输入top-k个目标掩码来预测MaskIoU。 将预测的MaskIoU与分类分数相乘,以获得新的校准掩模分数作为最终的掩模置信度。
4、实验
所有实验都在COCO数据集[26]上进行,有80个对象类别。我们遵循COCO 2017设置,使用115k图像训练拆分进行训练,5k验证拆分进行验证,20k test-dev拆分进行测试。我们使用COCO评估指标AP(平均超过IoU阈值)来报告结果,包括AP @ 0.5,AP @ 0.75,和APS,APM,APL(不同规模的AP)。[email protected](或[email protected])表示使用IoU阈值0.5(或0.75)来确定评估中预测的边界框或掩模是否为正。除非另有说明,否则使用掩模IoU评估AP。
4.1 实现细节
我们使用我们的再生Mask R-CNN进行所有实验。我们使用基于ResNet-18的FPN网络进行消融研究,使用ResNet-18/50/101基于更快的RCNN / FPN / DCN + FPN [9],将我们的方法与其他基线结果进行比较。对于ResNet-18 FPN,输入图像的大小调整为沿短轴为600px,沿长轴最大为1000px,用于训练和测试。与标准FPN [25]不同,我们在ResNet-18中仅使用C4,C5作为RPN预测和特征提取器。对于ResNet-50/101,输入图像的长轴调整为800 px,长轴调整为1333px 用于培训和测试。ResNet-50/101的其余配置遵循Detectron [13]。我们训练了18个时期的所有网络,在14个时期和17个时期之后将学习率降低了0.1倍。具有动量0.9的同步SGD用作优化器。 为了进行测试,我们使用SoftNMS并保留每个图像的前100个分数检测。
4.2 定量结果
我们在不同的骨干网络上报告我们的结果,包括ResNet-18/50/101和不同的框架,包括Faster R-CNN / FPN / DCN + FPN [9],以证明我们的方法的有效性。结果显示在表1和表2中。我们使用APm报告实例分割结果,使用APb报告检测结果。我们报告了我们重现的Mask R-CNN结果和我们的MS R-CNN结果。如表1所示,与Mask R-CNN相比,我们的MS R-CNN对骨干网络不敏感,可以在所有骨干网络上实现稳定的改善:我们的MS R-CNN可以获得显着的改善(约1.5 AP)。特别是对于[email protected],我们的方法可以将基线提高约2个点。表2表明我们的MS R-CNN对于不同的框架是稳健的,包括Faster R-CNN / FPN / DCN + FPN。此外,我们的MS R-CNN不会损害边界框检测性能;实际上,它略微提高了边界框检测性能。test-dev的结果在表3中显示,仅报告实例分割结果。
表1.COCO 2017验证结果。 我们显示了检测和实例分割结果。 APm表示实例分割结果,APb表示检测结果。 没有✔的结果是Mask R-CNN,而有✔的则是我们的MS R-CNN。结果表明,我们的方法对不同的骨干网络不敏感。
表2.COCO 2017验证结果。我们显示了检测和实例分割结果。APm表示实例分割结果,APb表示检测结果。在结果区域中,第1行和第2行使用Faster R-CNN框架;第3行和第4行另外使用FPN框架;第5行和第6行另外使用DCN + FPN。结果表明,提出的MaskIoU head一致得到改进。
表3.比较COCO 2017 test-dev上的不同实例分割方法。
4.3 消融学习
我们在COCO 2017验证集上全面评估我们的方法。 我们使用ResNet-18 FPN进行所有消融研究实验。
MaskIoU head输入的设计选择: 我们首先研究MaskIoU head输入的设计选择,它是掩模头部的预测掩模得分图(28 28 C)与RoI特征的融合。有一些设计选择如图4所示,并解释如下:
(a)目标掩码连接RoI特征:获取目标类的分数图,最大化并与RoI特征连接。
(b)目标掩模乘以RoI特征:获取目标类的分数图,最大化并乘以RoI特征。
(c)所有掩码连接RoI特征:所有C类掩模分数图最大化并与RoI特征连接。
(d)目标掩模连接高分辨率RoI特征:获取目标类的分数图并与28 * 28个RoI特征连接。
结果显示在表4中。我们可以看到MaskIoU head的性能对于融合掩模预测和RoI特征的不同方式是稳健的。在各种设计中都观察到性能提升。由于连接目标分数图和RoI特征可获得最佳结果,因此我们将其用作默认选项。

图4. 不同的设计选择的MaskIoU head输入。
表4. MaskIoU head输入的不同设计选择的结果。

表5. 使用不同训练目标的结果。
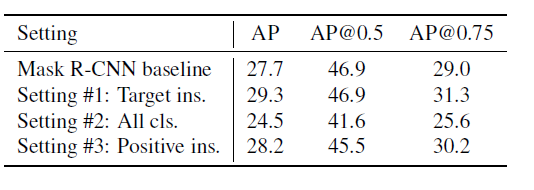
训练目标的选择: 如前所述,我们将掩码分数学习任务分解为掩码分类和MaskIoU回归。 是否可以直接学习掩膜评分? 此外,RoI可以包含多个类别的对象。我们应该为所有类别学习MaskIoU吗?如何设置MaskIoU head的训练目标仍需要探索。训练目标有很多不同的选择:
1.学习目标类别的MaskIoU,同时忽略提案中的其他类别。这也是本文中的默认训练目标,以及本段中所有实验的对照组。
2.学习所有类别的MaskIoU。如果类别未出现在RoI中,则其目标MaskIoU设置为0。此设置表示仅使用回归来预测MaskIoU,这要求回归量知道不存在不相关的类别。
3.学习所有正类别的MaskIoU,其中正类别表示该类别出现在RoI区域。并且忽略了预测中的其余类别。此设置用于查看对RoI区域中更多类别执行回归是否更好。
表5显示了上述训练目标的结果。通过比较设置#1和设置#2,我们可以发现所有类别的训练MaskIoU(仅基于回归的Mask-IoU预测)将大大降低性能,这验证了我们对训练的看法 使用单一目标函数进行分类和回归是困难的。
设置#3的性能不如设置#1是合理的,因为对所有正类别回归MaskIoU会增加MaskIoU head的负担。因此,学习目标类别的MaskIoU将用作我们的默认选择。
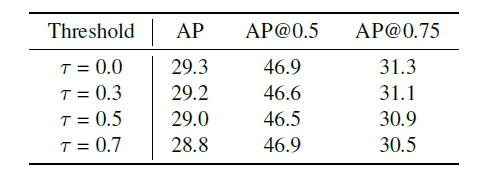
如何选择训练样本: 由于所提出的MaskIoU head建立在Mask R-CNN框架之上,因此MaskIoU头部的所有训练样本都具有大于0.5的盒级IoU,其地面实况边界框根据Mask R-CNN中的设置。 但是,他们的MaskIoU不得超过0.5。
给定阈值,我们使用Mask-IoU大于训练MaskIoU head的样本。表6显示了结果。结果表明,使用所有示例的训练获得最佳性能。
表6. MaskIoU head选择不同训练样本的结果。
4.4 讨论
在本节中,我们将首先讨论预测的MaskIoU的质量,然后如果MaskIoU的预测是完美的,则研究Mask Scoring R-CNN的上界性能,并最后分析MaskIoU head的计算复杂度。在讨论中,使用弱骨干网络(即ResNet-18 FPN和强骨干网络,即ResNet-101 DCN + FPN)在COCO 2017验证集上获得所有结果。
预测MaskIoU的质量: 我们使用真实标签和预测的Mask-IoU之间的相关系数来测量我们的预测质量。回顾我们的测试程序,我们根据分类分数选择SoftNMS之后的前100个评分框,将检测到的框输入到Mask head并获得预测的掩模,然后使用预测的掩模和RoI特征作为MaskIoU头的输入。MaskIoU head的输出和分类得分进一步整合到最终的面具得分中。
我们在COCO 2017验证数据集中为每个图像保留100个预测的MaskIoU,从所有5,000张图像中收集500,000个预测。 我们在图5中绘制每个预测及其相应的基本事实。我们可以看到MaskIoU预测与它们的基本事实具有良好的相关性,特别是对于那些具有MaskIoU的预测。对于ResNet-18 FPN和ResNet-101 DCN + FPN骨干网,预测与其基本事实之间的相关系数约为0.74。它表明预测的质量对骨干网的变化不敏感。这个结论也与表1一致。由于之前没有方法可以预测MaskIoU,我们参考之前关于预测边界框IoU的工作[19]。 [19]得到0.617相关系数,不如我们的。

图5. MaskIoU预测的可视化及其基本事实。(a)ResNet-18 FPN骨干的结果和(b)ResNet-101 DCN + FPN骨干的结果。x轴表示基础真值MaskIoU,y轴表示所提出的MaskIoU头的预测Mask-IoU。
MS R-CNN的上限性能: 这里我们将讨论我们方法的上限性能。 对于每个预测的掩模,我们可以找到它匹配的真实标签掩模;然后,当真实标签MaskIoU大于0时,我们只使用地面实例Mask-IoU来替换预测的MaskIoU。结果如表7所示。结果表明,Mask Scoring R-CNN始终优于Mask R-CNN。与掩模评分R-CNN的理想预测相比,仍然存在改进实际掩模评分R-CNN的空间,其对于ResNet-18 FPN骨干为2.2%AP,对于ResNet-101 DCN + FPN骨干为2.6%AP。
表7. 掩模R-CNN,MS R-CNN和使用ResNet-18 FPN和ResNet-101 DCN + FPN作为COCO 2017验证集的主干的MS R-CNN(MS R-CNN?)的理想情况的结果。
型号大小和运行时间: 我们的MaskIoU head有大约0.39G FLOP,而Mask head每个预测大约有0.53G FLOP。我们使用一个TITAN V GPU来测试速度(秒/图像)。至于ResNet-18 FPN,Mask R-CNN和MS R-CNN的速度约为0.132。 对于ResNet-101 DCN + FPN,Mask R-CNN和MS R-CNN的速度约为0.202。掩模评分R-CNN中MaskIoU头的计算成本可以忽略不计。
- 结论
在本文中,我们研究了对实例分割掩码进行评分的问题,并提出了掩码评分RCNN。通过在掩码R-CNN中添加MaskIoU头,掩码的分数与MaskIoU对齐,这在大多数实例分割框架中通常被忽略。 所提出的MaskIoU头非常有效且易于实现。在COCO基准测试中,大量结果表明,Mask Scoring R-CNN始终明显优于Mask R-CNN。 它还可以应用于其他实例分割网络以获得更可靠的掩模分数。 我们希望我们简单有效的方法将作为基准,并有助于未来在实例分割任务中的研究。