转载自:https://www.cnblogs.com/skywang12345/p/3711483.html
1. 介绍
图的深度优先搜索(Depth First Search),是图的一种搜索方法,和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
显然,深度优先搜索是一个递归的过程。
2. 原理
通过对有向图与无向图的遍历过程来说明深度优先的原理
2.1 无向图

通过深度优先的方式遍历上图的流程如下:
- 第1步:访问A。
- 第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在"D和F"的前面,因此,先访问C。 - 第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。 - 第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。 - 第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问A的另一个邻接点F。 - 第6步:访问(F的邻接点)G。
- 第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
2.2 有向图
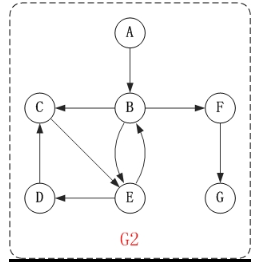
通过深度优先的方式遍历上图的流程如下:
- 第1步:访问A。
- 第2步:访问B。
在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。 - 第3步:访问C。
在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG按照顺序存储,因此先访问C。 - 第4步:访问E。
接下来访问C的出边的另一个顶点,即顶点E。 - 第5步:访问D。
接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。 - 第6步:访问F。
接下应该回溯"访问A的出边的另一个顶点F"。 - 第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
3. 实现
# -*- coding:utf-8 -*-
# @Author:sunaihua
# 深度优先算法
# 边节点
class EdgeNode:
def __init__(self, adjvex, weight=0):
self.adjvex = adjvex
self.weight = weight;
def __str__(self):
return '%s-%s' % (self.adjvex, self.weight)
# 顶点节点
class VertexNode:
def __init__(self, data, adjvex, edge_list=None):
self.adjvex = adjvex
self.data = data
self.edge_list = edge_list
def __str__(self):
edge_str = '_'.join([edge.adjvex.data for edge in self.edge_list])
# print edge_str
# print [edge.adjvex for edge in self.edge_list]
return "%s-%s-(%s)" % (self.adjvex, self.data, edge_str)
class GraphAdjList:
def __init__(self):
self.adj_list = []
def add_vertex(self, vertex_node):
self.adj_list.append(vertex_node)
graph_data = {'A': ['B', 'G', 'F'], 'B': ['C', 'I', 'G', 'A'], 'C': ['D', 'I', 'B'], 'D': ['E', 'H', 'G', 'I', 'C'],
'E': ['F', 'H', 'D'], 'F': ['A', 'G', 'E'], 'G': ['F', 'B', 'D', 'H'], 'H': ['D', 'E', 'G'],
'I': ['B', 'C', 'D']}
visited_vertex_list = []
vertex_size = 9
# 根据数据初始化图
def create_al_graph():
graph_adjvex_list = GraphAdjList()
adjvex_map = {}
for i, data in enumerate(graph_data.iterkeys()):
vertex_node = VertexNode(data, i)
adjvex_map[data] = vertex_node
graph_adjvex_list.add_vertex(vertex_node)
for vertex_node in graph_adjvex_list.adj_list:
adjvex_list = graph_data[vertex_node.data]
vertex_node.edge_list = [EdgeNode(adjvex_map[adjvex]) for adjvex in adjvex_list]
return graph_adjvex_list
# 深度优先遍历
def dfs(adjvex):
if len(visited_vertex_list) <= vertex_size:
# 处理顶点信息
if adjvex.data not in visited_vertex_list:
visited_vertex_list.append(adjvex.data)
print adjvex.data
# 处理边
for edge in adjvex.edge_list:
if edge.adjvex.data not in visited_vertex_list:
visited_vertex_list.append(edge.adjvex.data)
print edge.adjvex.data
dfs(edge.adjvex)
else:
return
if __name__ == '__main__':
graph = create_al_graph() # 创建图
dfs(graph.adj_list[0]) # 从第一个节点开始遍历