本文为课程对应的学习笔记
地址http://www.auto-mooc.com/mooc/detail?mooc_id=F51511B0209FB73D81EAC260B63B2A21
课件资料存放地址:待更新
修订:补充“前馈神经网络”-2月14
文章目录
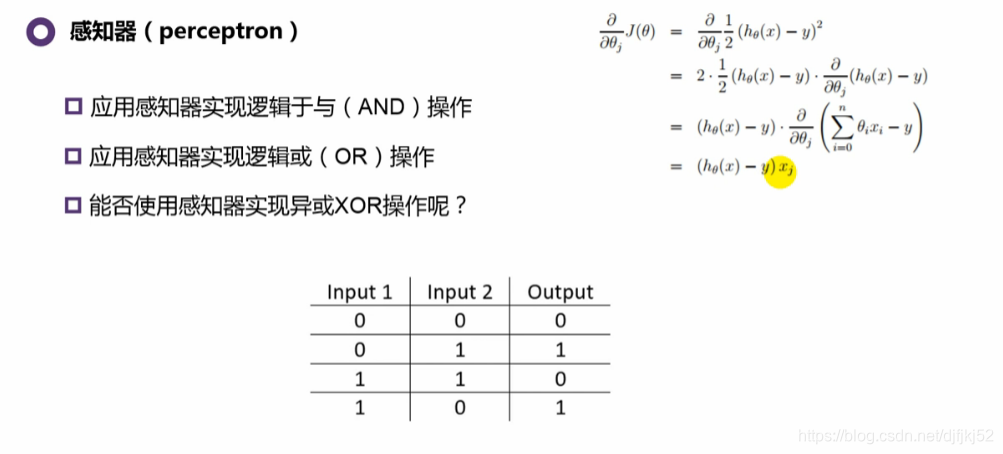
7.0感知器
重点理解:
- 感知器
- 浅层神经网络
- BP反向传播
SVM与逻辑回归,适当应用可以解决很多非线性问题。
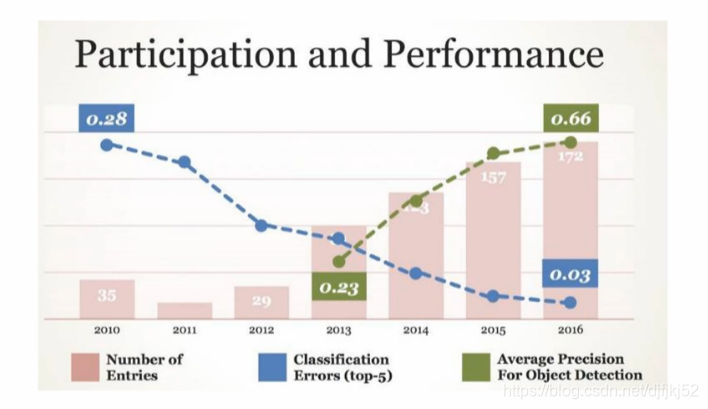
2010年Google科学家李飞飞举行图像分类比赛,2012多伦多大学教授Geoffry Hinton和他的团队带着 AlexNet,深度卷积神经网络参加了那一年的 ImageNet ILSVRC 挑战赛,以惊人的优势获胜(错误率比第二名低了足足 10%)。这篇被 NIPS 2012 收录的论文被认为是深度学习热的开启。神经网络的春天。
2017年10月26日,Hinton发表了一篇在AI圈掀起轩然大波的论文——Capsule Networks(胶囊网络)。Hinton高喊,“卷积神经网络(CNN)的时代已经过去了!”,将他过去几十年的研究翻了过去。
7.1 感知器
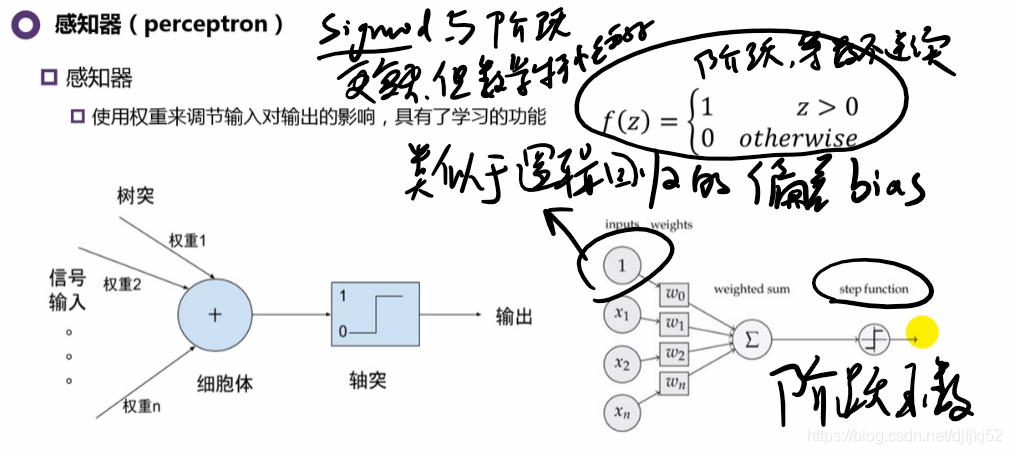
感知器 和 逻辑回归很相似,(逻辑回归更像是感知器的改进)。上个世纪50年度就有的概念,60年代就有的应用。
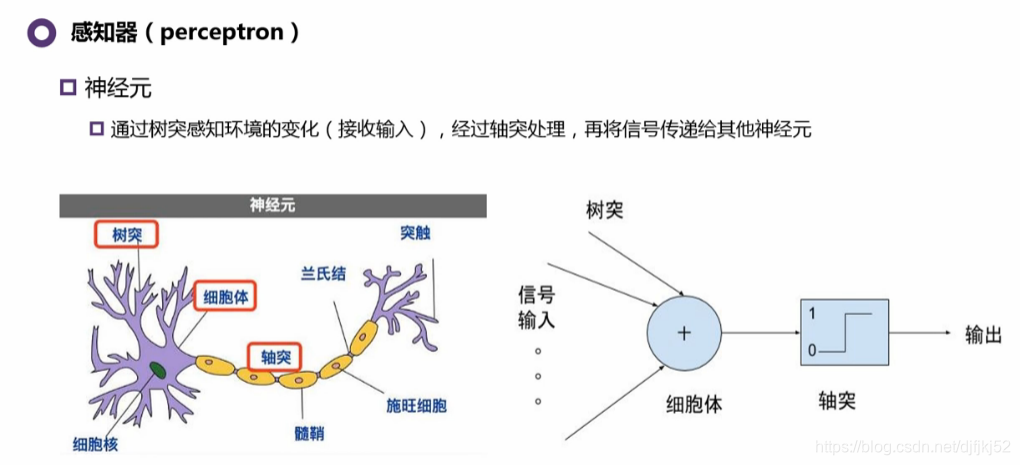
1943年就有人根据人脑神经的工作方式提出感知器。但是其问题是:工作模式是固定的,(细胞体处理问题是固定的)。
引入权重的概念,1956年:
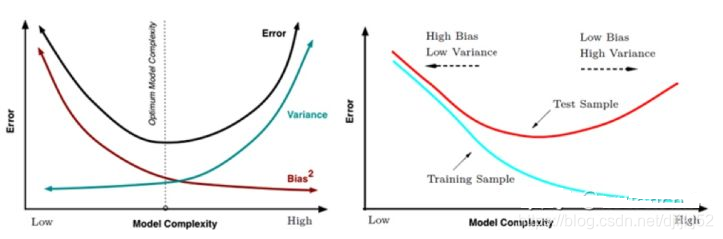
7.2 偏差(Bias)和方差(Variance)(新增)
参考:https://zhuanlan.zhihu.com/p/38471518
偏差表示模型的期望输出与真实值的差异。
方差表示模型对于给定观测点进行预测时的可变性或者说稳定性。
下面是枪手打靶的例子。偏差反映了枪手瞄准点与靶心之间的偏差,而方差则是枪手的稳定性。实际射击过程中还有不可控因素,例如风的影响等,我们称之为噪音(noise)。
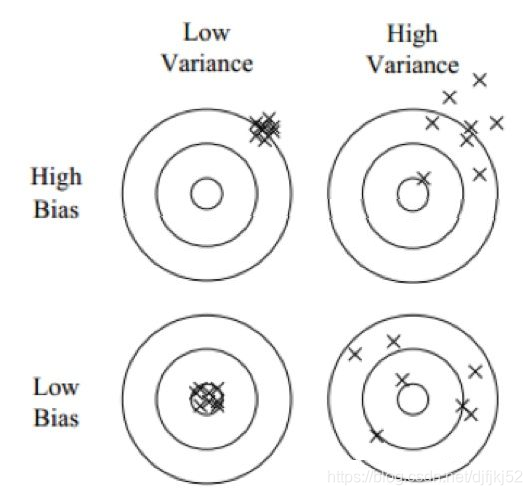
低偏差 Bias 与低方差 Variance 才会得到理想的结果,但低Bias 与低Variance 往往是不能兼得的。**如果要降低模型的 Bias,就一定程度上会提高模型的Variance,反之亦然。**这里以 K-NN 为例,看一些 K-NN 中 Bias 与Variance 与其参数 K 的关系,在 K-NN 中,误差形式如下,这里 x1,x2,…xk 是x 在训练数据集中最近的 k 个邻居,当K 取值很小时Bias 很低,但Variance很大。随着K 的增大,Bias明显会增大,但Variance 会减小,这便是 Bias 与Variance 之间的一个关系。

因为预测模型试图用有限的训练数据集去得到一个用来预测全数据集的模型,为了降低模型的误差率,就要尽量使模型在训练数据集上更加“准确”,这样做往往会增加模型复杂度,但却降低了模型在全数据集的泛化能力,对于新数据,模型对就会很不稳定,这样就会造成高Variance,也就是过拟合。为了避免过拟合,就不能完全依赖于有限的训练数据,需要会增加一些限制(例如泛化)来提高模型的稳定程度降低Variance。但是这样做的后果是,模型的Bias 增大,拟合能力不够造成欠拟合,所以需要要Bias 与Variance 之间寻找一个tradeoff。
7.3感知器流程与适用范围

感知器实验: Calculate weights
#dataset = [[0,0,0],[0,1,0],[1,0,0],[1,1,1]]
dataset = [[0,0,0],[0,1,1],[1,0,1],[1,1,1]] #数据集的前两个参数是输入,第三个是输出
#dataset = [[0,0,0],[0,1,1],[1,0,1],[1,1,0]]
一眼可以看出:这是逻辑与、逻辑或、逻辑异或三种关系的数据集

import matplotlib.pyplot as plt
import numpy as np
def predict(row, weights):
activation = weights[0] #weights[0]是bias,偏差
for i in range(len(row) - 1): #循环相加
activation += weights[i + 1] * row[i]
#return 1.0 if activation >= 0.0 else 0.0
return 1.0 if activation >0 else 0.0
#使用随机梯度下降进行感知器参数的估计
def train_weights(train, l_rate, n_epoch):
weights = [0.0 for i in range(len(train[0]))] #初始值为0
for epoch in range(n_epoch): #每一轮,使用所有的训练值更新参数
sum_error = 0.0
print("当前参数值:")
print(weights)
for row in train:
print("训练值: ")
print(row)
prediction = predict(row, weights) #对每一个训练值使用当前的权重进行预测
print("Expected=%d, Predicted=%d" % (row[-1], prediction))
error = row[-1] - prediction #使用训练值减去预测值
sum_error += error ** 2 #错误的个数需要对错误值进行平方;防止正负抵消
weights[0] = weights[0] + l_rate * error #更新参数,直接使用错误值; bias
for i in range(len(row) - 1): #对每一个错误,更新所有的参数
weights[i + 1] = weights[i + 1] + l_rate * error * row[i] #梯度下降
print("训练后参数:")
print(weights)
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
print(weights)
return weights
# Calculate weights
#dataset = [[0,0,0],[0,1,0],[1,0,0],[1,1,1]]
dataset = [[0,0,0],[0,1,1],[1,0,1],[1,1,1]]
#dataset = [[0,0,0],[0,1,1],[1,0,1],[1,1,0]]
l_rate = 0.1
n_epoch = 5
#n_epoch = 5
weights = train_weights(dataset, l_rate, n_epoch)
print(weights)
for row in dataset:
prediction = predict(row, weights)
print("Expected=%d, Predicted=%d" % (row[-1], prediction))
for data in dataset:
print(data)
if data[-1] == 1:
plt.scatter(data[0],data[1],25,'r')
else:
plt.scatter(data[0], data[1], 25,'g')
X = np.arange(-2, 2, 0.1)
Y = [-(weights[0]+weights[1]*x)/weights[2] for x in X]
plt.plot(X, Y, 'y*')
plt.show()
简单的感知器不能解决非线性可分的问题,例如“异或问题”,就无能为力。对于逻辑AND和逻辑OR线性可分类问题较好的效果。所以,前几
十年,这也是感知器被打入冷宫的原因。
8.1 浅层神经网络
浅层神经网络包括:
- 隐藏层
- 激活函数
- 前馈神经网络
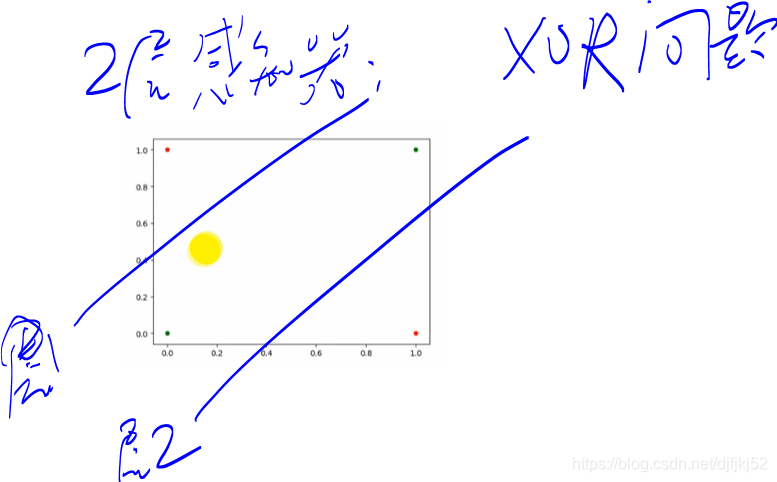
单个感知器无法解决“异或XOR”问题。于是,扩展单层感知器!!!
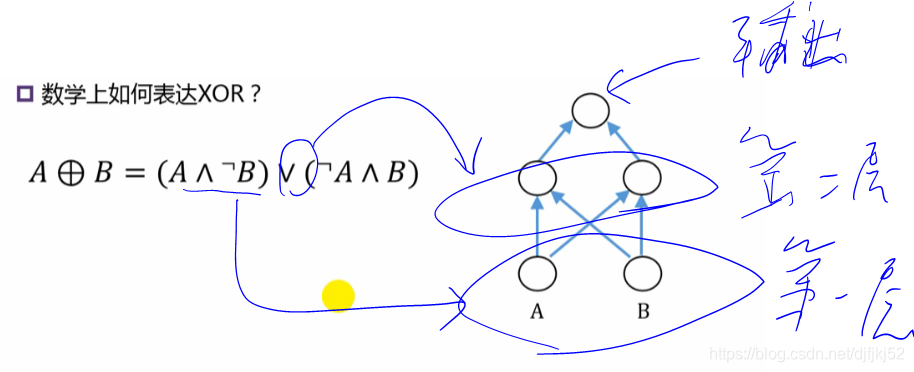
多层神经网络中,我们就不称运算个体是感知器,称为“神经元”
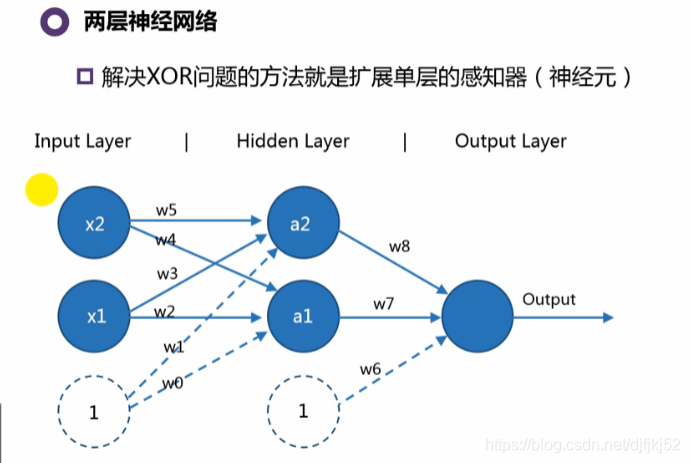
权重的维度:
| input与hidden | hidden与output |
|---|---|
| 例题中是2*3;通用公式是:hidden维度Xinput维度 | 例题中是1*3;通用公式是:input维度Xhidden维度 |

前馈神经网络:输出不影响输入。
多层神经网络可以解决非线性问题了。
补充“前馈神经网络”-2月14


其他的神经网络结构:ART,SOM
8.2 BP反向传播:更新权值

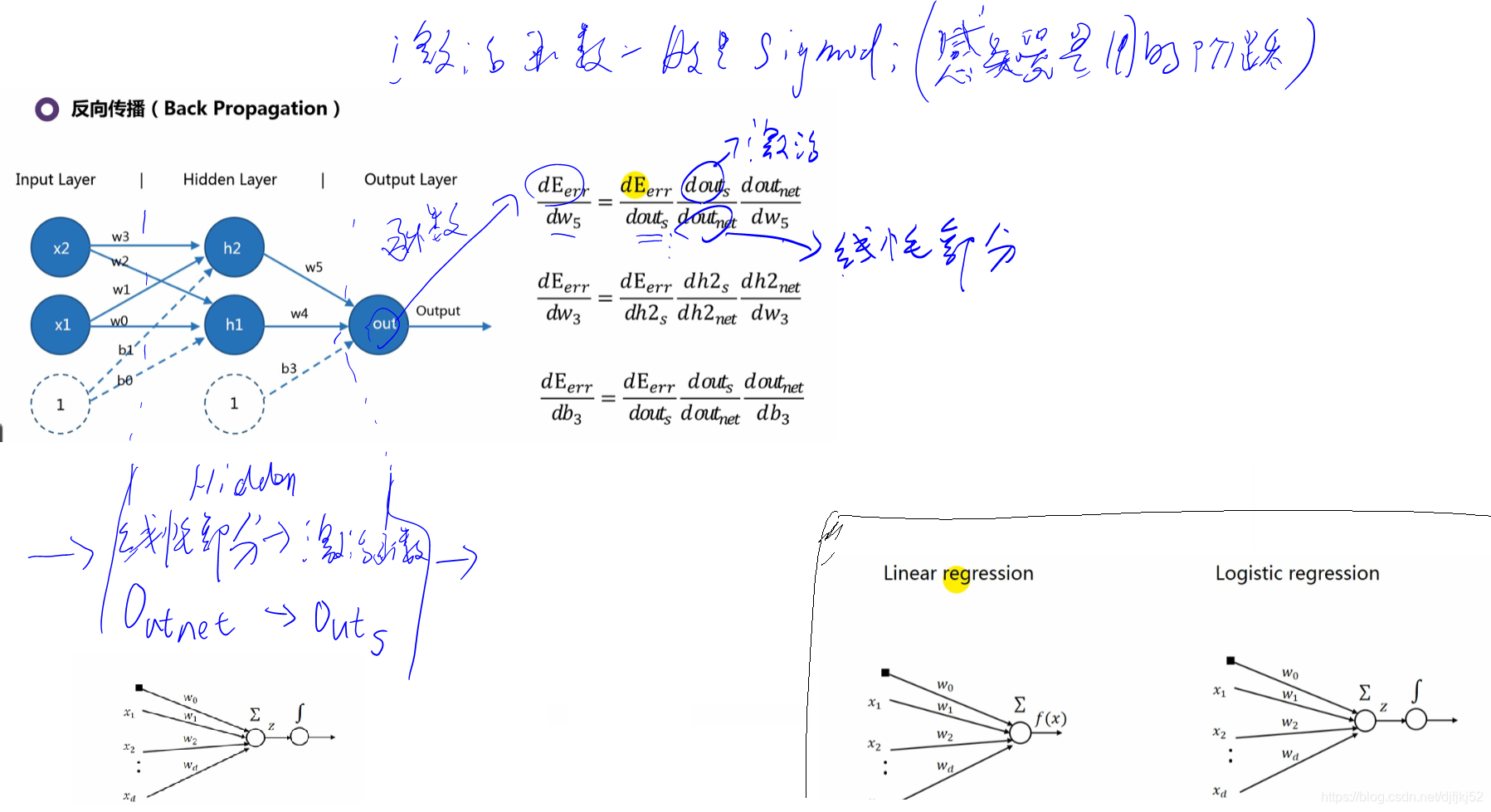


XOR问题利用两层神经网络解决:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x): #转换函数;在隐藏层和输出层使用
return 1/(1+np.exp(-x))
def s_prime(z):
return np.multiply(z, 1.0-z) #sigmoid函数的导数形式
#return np.multiply(sigmoid(z) , (1 - sigmoid(z)))
def init_weights(layers, epsilon):
weights = []
for i in range(len(layers)-1): #对每一层生成参数;每一个输入值与下一层的所有节点连接
w = np.random.rand(layers[i+1], layers[i]+1) #layers[i+1] 下一层节点的个数;layers[i]+1 有bias
w = w * 2*epsilon - epsilon #rand生成的值在0~1之间,epsilon=1,(2*w-1)可以将w的值范围变为-1~1
weights.append(np.mat(w))
print(weights)
return weights
#a_s 保存输入值、每一层经计算sigmoid的值;
def back(X, Y, w):
# now each para has a grad equals to 0
w_grad = ([np.mat(np.zeros(np.shape(w[i])))
for i in range(len(w))]) # len(w) equals the layer number
m, n = X.shape #训练集的大小 4*2
output = np.zeros((m, 1)) # 所有样本的预测值, 4个
for i in range(m): #对每个训练样本;X,Y都为矩阵
x = X[i]
y = Y[0,i]
# forward propagate
a = x #每个训练样本
a_s = []
for j in range(len(w)): #总共有3-1层;w的长度是神经网络的层数
a = np.mat(np.append(1, a)).T #1用于与bias相乘,weights向量的第一项是bias的值
a_s.append(a) # 这里保存了前L-1层的a值: 输入层;隐藏层
net = w[j] * a
a = sigmoid(net) #上一层的输出是下一层的输入
#print('a_s',a_s,)
output[i, 0] = a
# back propagate
delta = a - y.T #计算预测值和真实值之间的差;也是交叉熵和sigmoid求导之后的乘积
w_grad[-1] += delta * a_s[-1].T # L-1层的梯度
#print("delta:")
#print(delta)
# 倒过来,从倒数第二层开始
for j in reversed(range(1, len(w))): #len(2)= 2; 所以j仅取1
delta = np.multiply(w[j].T*delta, s_prime(a_s[j])) # #中间的每一层都使用了sigmoid函数;s_prime是sigmoid的导数形式;
#print(s_prime(a_s[j]))
#print('delta new:')
#print(delta)
#print(a_s[j-1])
w_grad[j-1] += (delta[1:] * a_s[j-1].T) #delta[0] = 0; 因为 s_prime(a_s[j][0]=1);常数项不会对权重产生影响
#print("weight")
#print(delta[1:] * a_s[j-1].T)
w_grad = [w_grad[i]/m for i in range(len(w))]
#print(w_grad)
cost = (1.0 / m) * np.sum(-Y * np.log(output) - (np.array([[1]]) - Y) * np.log(1 - output)) #交叉熵代价函数
return {'w_grad': w_grad, 'cost': cost, 'output': output}
X = np.mat([[0,0],
[0,1],
[1,0],
[1,1]])
print(X)
Y = np.mat([0,1,1,0])
print(Y)
layers = [2,2,1] #神经网络结构
epochs = 2000 #迭代次数
alpha = 0.5 #参数更新步长
w = init_weights(layers, 1)
result = {'cost': [], 'output': []}
w_s = {}
for i in range(epochs):
back_result = back(X, Y, w)
w_grad = back_result.get('w_grad')
cost = back_result.get('cost')
output_current = back_result.get('output')
result['cost'].append(cost)
result['output'].append(output_current)
for j in range(len(w)):
w[j] -= alpha * w_grad[j]
if i == 0 or i == (epochs - 1):
# print('w_grad', w_grad)
w_s['w_' + str(i)] = w_grad[:]
plt.plot(result.get('cost'))
plt.show()
print(w_s)
print('output:')
print(result.get('output')[0], '\n',result.get('output')[-1])
#绘制出异或的点
plt.figure()
X = np.asarray(X)
Y = np.asarray(Y)
for i in range(len(Y[0])):
#print(X[i])
#print(Y[0])
if Y[0][i] == 1:
plt.scatter(X[i][0],X[i][1],25,'r')
else:
plt.scatter(X[i][0],X[i][1], 25,'g')
#绘制出根据反向传播计算得出的参数
plt.show()
8.3 超参数

参考:https://zhuanlan.zhihu.com/p/41785031
layers = [2,2,1] #神经网络结构
epochs = 2000 #迭代次数
alpha = 0.5 #参数更新步长
超参数,也成为框架参数,是我们控制模型结构、功能、效率等的 调节旋钮。【超参数】是影响所求【参数】最终取值的参数,是学习模型的框架参数。【超参数】是手工指定并不断调整的。网络的效果,取决于超参数的取值。
learning rate
epochs(迭代次数,也可称为 num of iterations)
num of hidden layers(隐层数目)
num of hidden layer units(隐层的单元数/神经元数)
activation function(激活函数)
batch-size(用mini-batch SGD的时候每个批量的大小)
optimizer(选择什么优化器,如SGD、RMSProp、Adam)
用诸如RMSProp、Adam优化器的时候涉及到的β1,β2等等
......
太多了,上面是一些最常见的超参数,一般的深度学习框架就是调节这些框架参数。
另外,层数越多,越准确,但训练时间也越大,但是计算量越大;全连接层应该少,计算量太大
参数的定义:
【参数】是我们训练神经网络 最终要学习的目标,最基本的就是神经网络的权重 W和bias(b),我们训练的目的,就是要找到一套好的模型参数,用于预测未知的结果。这些参数我们是不用调的,是模型来训练的过程中自动更新生成的。
8.4 两层神经网络解决手写数字识别
#生成神经网络对象,神经网络结构为三层,每层节点数依次为(784, 30, 10)
net = Network([784, 30, 10])
#用(mini-batch)梯度下降法训练神经网络(权重与偏移),并生成测试结果。
#训练轮数=30, 用于随机梯度下降法的最小样本数=10,学习率=3.0
net.back(training_data, 30, 10, 3.0, test_data=test_data)
784:因为输入的图像是28像素x28像素
10:因为输出是0~9,十个数字
30:节点数目是30个,来自于经验。可以是:输入层与输出层数目乘积,然后开根号,或者log等待,来源于经验。
2层的神经网络,一层30个节点,也能得到很好的效果。
代码:
# %load network.py
import random
import numpy as np
import mnist_loader
class Network(object):
def __init__(self, sizes):
"""size是神经网络的大小;(784, 30, 10)即表示输入层是784个节点;隐藏层是30个节点;输出是10个节点"""
self.num_layers = len(sizes)
self.sizes = sizes
#为全连接网络生成随机初始的参数
#bias是对除输入层之外的所有层次都要生成
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
#weights相邻两层之间,每一个输入都对下一层的节点有一个权重
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
"""主要用于测试集,查看效果"""
def feedforward(self, a):
"""权重和值相乘,加上偏移,然后使用sigmoid计算"""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
def back(self, training_data, epochs, mini_batch_size, eta, #随机梯度下降
test_data=None):
"""使用Mini-batch的随机梯度方法来更新梯度"""
training_data = list(training_data)
n = len(training_data)
if test_data:
test_data = list(test_data)
n_test = len(test_data)
for j in range(epochs):
random.shuffle(training_data)
#挑选出一些输入点进行参数更新
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
#打印出正确分类的个数
if test_data:
print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test));
else:
print("Epoch {} complete".format(j))
def update_mini_batch(self, mini_batch, eta):
"""使用向后传播进行计算"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
#得出每一层的参数的大小
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # 所计算出的每一层(经过sigmoid计算)的值;在参数更新中会用到
zs = [] # 经过线性计算的每层的值
#对每一层进行前向计算
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# 向后计算,以下三行是更新最后一层的参数
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
#从倒数第二层开始,计算方法相同,可以进行循环
#bias和weights分开计算
#weights的值依赖于上一层的输出
for layer in range(2, self.num_layers):
z = zs[-layer]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-layer+1].transpose(), delta) * sp
nabla_b[-layer] = delta
nabla_w[-layer] = np.dot(delta, activations[-layer-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
"""统计出来正确分类的个数;argmax表示数组中最大的值的位置;因为最终output的结果是0,1向量,只有一个值为1,也就是判别的种类"""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
print(test_results)
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y): #使用的是均方误差;均方误差的微分形式
"""计算输出与真实值的差."""
return (output_activations-y)
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""sigmoid函数的微分."""
return sigmoid(z)*(1-sigmoid(z))
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
# 生成神经网络对象,神经网络结构为三层,每层节点数依次为(784, 30, 10)
net = Network([784, 30, 10])
# 用(mini-batch)梯度下降法训练神经网络(权重与偏移),并生成测试结果。
# 训练轮数=30, 用于随机梯度下降法的最小样本数=10,学习率=3.0
net.back(training_data, 30, 10, 3.0, test_data=test_data)
8.5 激活函数
对网络的性能有大影响

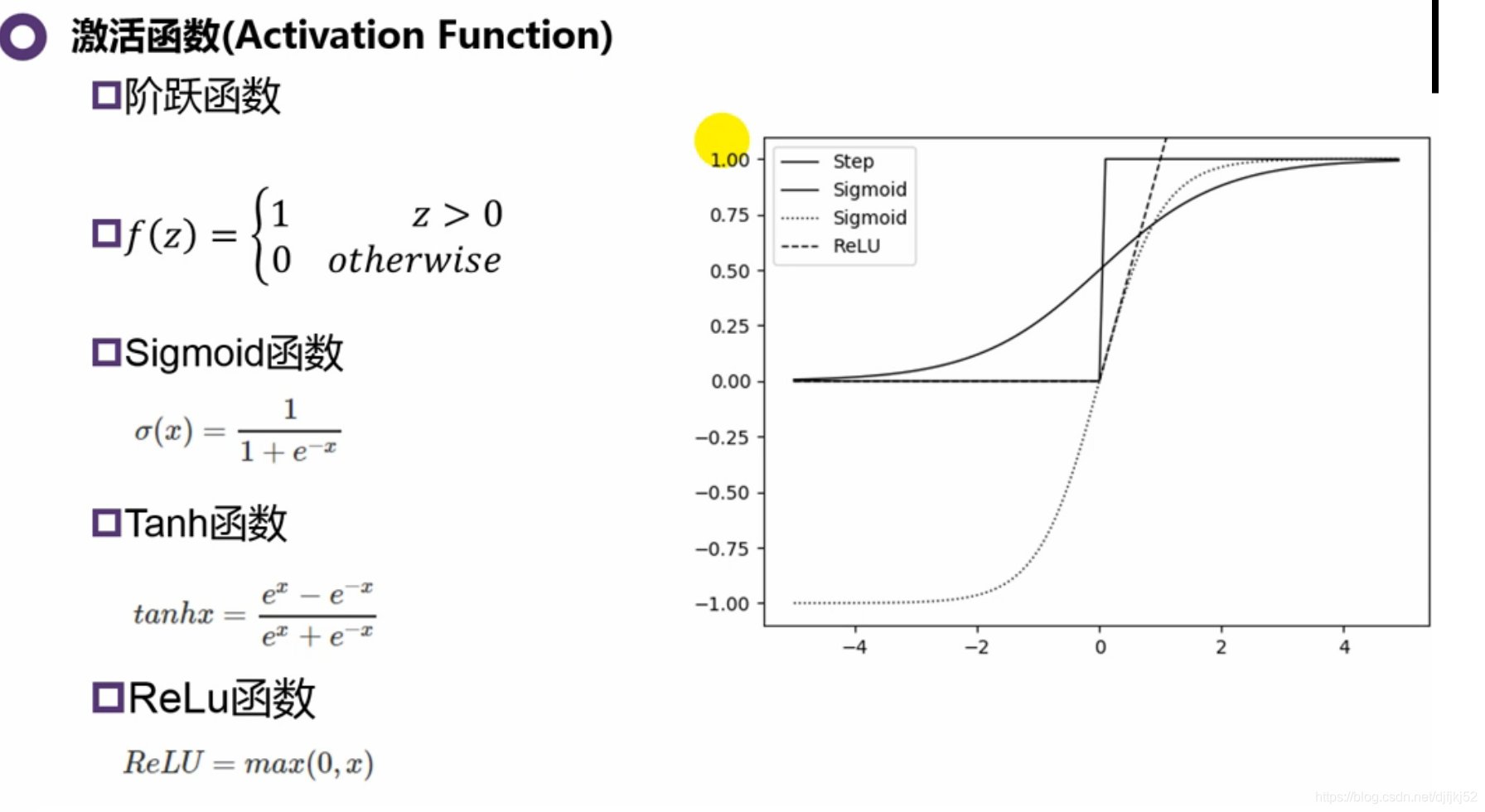
| 函数 | 有点 | 缺点 |
|---|---|---|
| step | 很好的模拟了神经元 | 1、不是连续可导,BP过程更新W是需要对激活函数求导;2、输入的扰动对输出的影响巨大 |
| sigmoid | 早期运用广泛 | sigmoid函数值恒大于零,导致模型收敛速度变慢,对于更新状态可能导致锯齿状,更新效果不是很好;sigmoid计算量大;导致梯度消失!!!!! |
| tanh | 改进sigmoid;范围是(-1,+1);倒数(0,1) | 计算量大,网络足够深,也会有梯度消失问题 |
| ReLu | 可以解决梯度消失问题 | 存在大梯度的样本,导致一些神经元处于“死”的状态 |

9.1 tensorflow(很像一种语法)
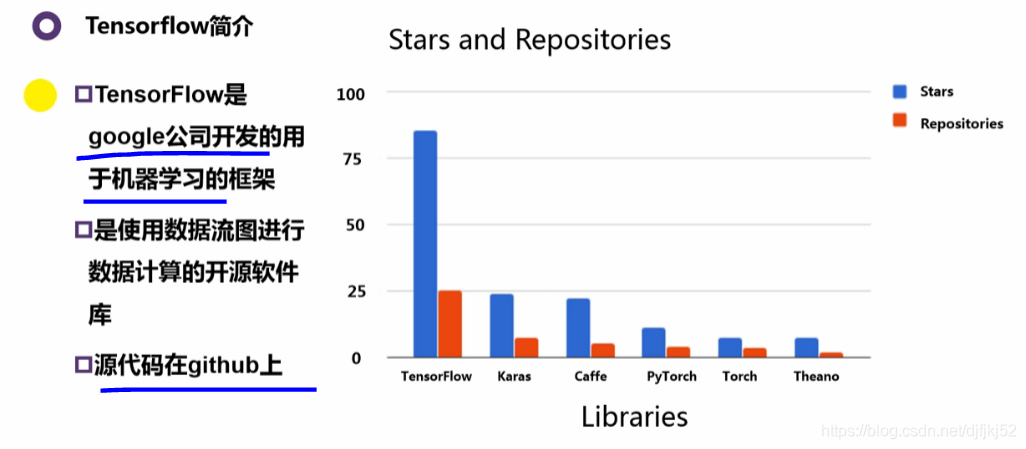



9.2 数据流



交互式环境下面:
定义数据:创建Tensor,添加Op

执行计算:
在会话session中执行图,session 会占用系统资源,使用完毕后需要释放资源
- sess= tf.InteractiveSession()
with tf.Session() as s:
print(s.run(x))
#print(z.eval())
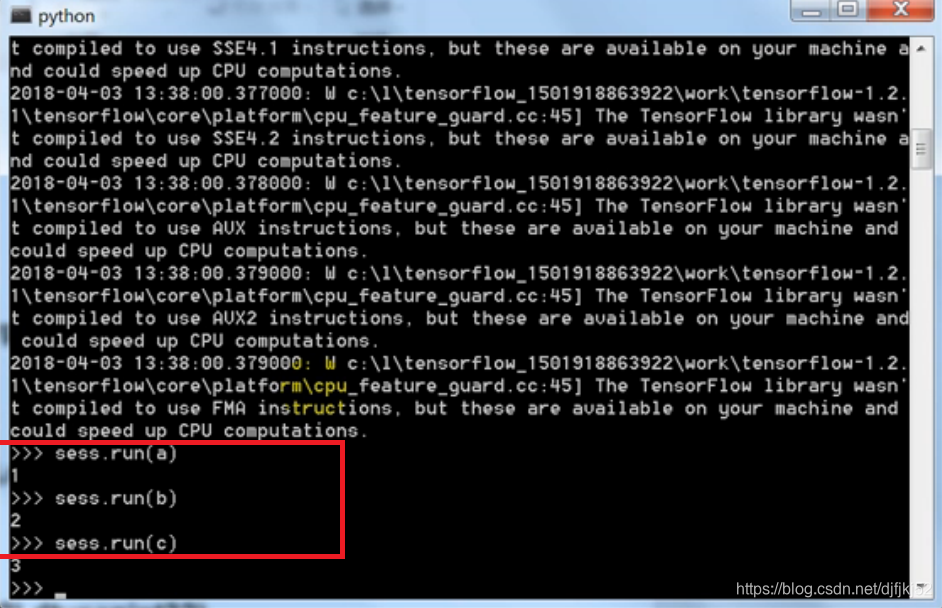
代码示例:
import tensorflow as tf
a = tf.constant(1)
b = tf.constant(2)
c = tf.constant(3)
x = tf.add(a,b)
y = tf.add(x,c)
z = tf.add(x,y)
#print(y.graph)
#print(x.graph)
with tf.Session() as s:
print(s.run(x))
#print(z.eval())
writer = tf.summary.FileWriter('./graph/',tf.get_default_graph())
writer.add_graph(s.graph)
writer.close()
变量

- 注意: 使用变量之前,需要初始化变量:w.initializer,然后sess.run(op)
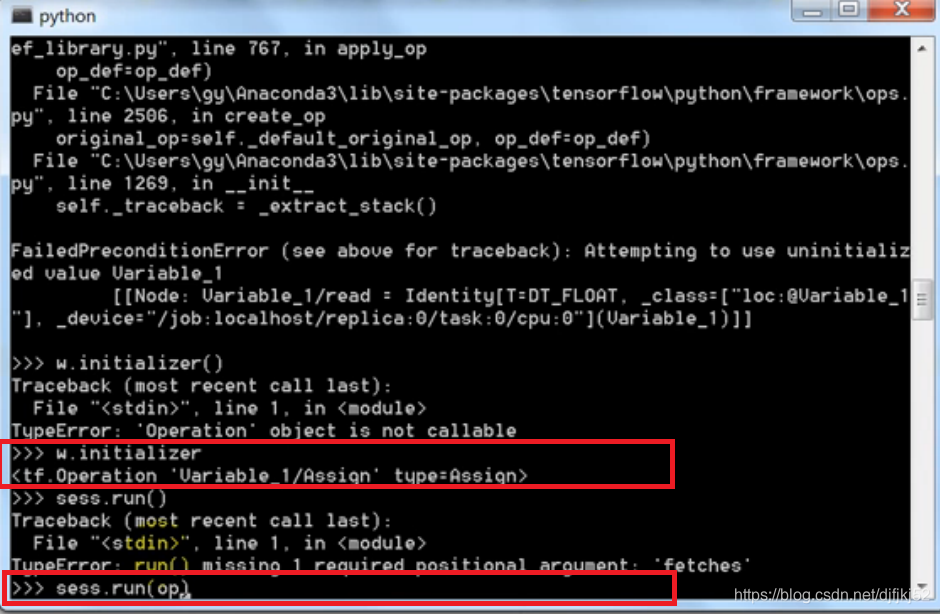
也可以采用:
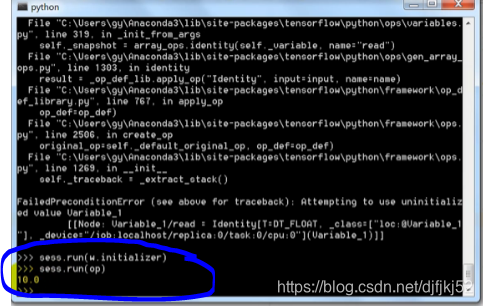
变量的初始化非常重要,operation一定要在sessions中运算。
import tensorflow as tf
w = tf.Variable([[1,2,4],[3,4,6]])
v = tf.Variable([[3,4],[1,2],[5,6]])
y = tf.Variable(5.0)
op = w.assign(w * 2)
u = tf.matmul(w,v)
t = tf.sigmoid(y)
**x = tf.global_variables_initializer()**# 一次性全部初始化变量
with tf.Session() as s:
#s.run(w.initializer)
#s.run(v.initializer)
#s.run(y.initializer)
s.run(x)
s.run(op)
print(w.value())
print(w.eval())
print(u.eval())
print(s.run(t))

占位符

import tensorflow as tf
x = tf.placeholder(tf.string)
u = tf.placeholder(tf.string)
y = tf.placeholder(tf.int32)
z = tf.placeholder(tf.float32)
t = tf.placeholder(tf.int32)
w = tf.Variable(1)
op = w.assign(y+t)
with tf.Session() as sess:
output = sess.run(x, feed_dict={x: 'Hello World'})
output1, o2, o3 = sess.run([u, y, z], feed_dict={u: 'Test String', y: '123', z: 45})
#o3 = sess.run(u, feed_dict={u: 'Test String', y: 123.45, z: 45})
print(output1,o2,output,o3)
#print(o2+o3)
print(type(o3))
print(tf.string_join([output,output]).eval())
print(sess.run(op,{y:1,t:2}))
#print(sess.run(op,{t:2}))
#result = sess.run(op)
print(x.eval()) #error
权值、偏置、导数等数据一般用变量表示,因为需要变动且要保留;但是训练数据用占位符,不用保存,只是一个传递作用
Graph

import tensorflow as tf
c=tf.constant(value=1)
print(c.graph)
print(tf.get_default_graph())
#生成新图
g1=tf.Graph()
print("g1:",g1)
with g1.as_default():
d=tf.constant(value=2)
print(d.graph)
#生成新图
g2=tf.Graph()
print("g2:",g2)
g2.as_default()
e=tf.constant(value=15)
print(e.graph)
with g1.as_default():
c1 = tf.constant([1.0])
with tf.Graph().as_default() as g2:
c2 = tf.constant([2.0])
with tf.Session(graph=g1) as sess1:
print(sess1.run(c1))
print(sess1.run(c2))
#print(sess1.run(c))
with tf.Session(graph=g2) as sess2:
print(sess2.run(c2))
writer = tf.summary.FileWriter('./graph/',tf.get_default_graph())
writer.add_graph(sess1.graph)
writer.close()
TensorBoard
暂时结束!!明天继续
