KMP算法——六步搞定KMP
1.什么是KMP
KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位大佬共同提出的,称之为 Knuth-Morria-Pratt 算法,简称 KMP 模板匹配算法。该算法相对于 Brute-Force(暴力)算法有比较大的改进,主要是消除了主串指针的回溯,提高时间效率。(空间换时间)
2.KMP与朴素模板匹配(Brute-Force)
暴力法Brute-Force
这个就是超级简单的逐一遍历比较。。。。
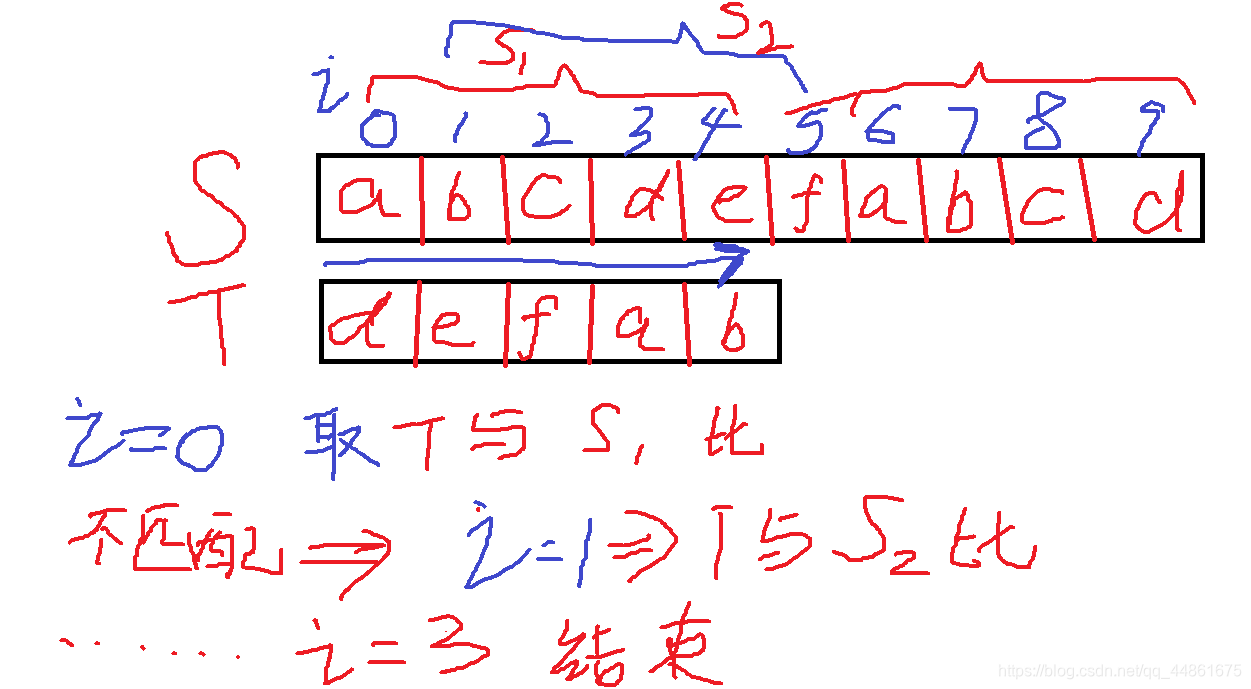
给定字串S,T,
将T与S的第一个长度与T一样的字串比较,成功就返回匹配的第一个索引
不成功,则继续匹配S的下一个长度与T一样的字串
……重复遍历每一个长度与T一样的字串,并匹配
这样的时间复杂度是O(n*m)。
KMP模板匹配算法——可以实现复杂度为O(m+n)
第一步:先了解什么是前缀后缀字串
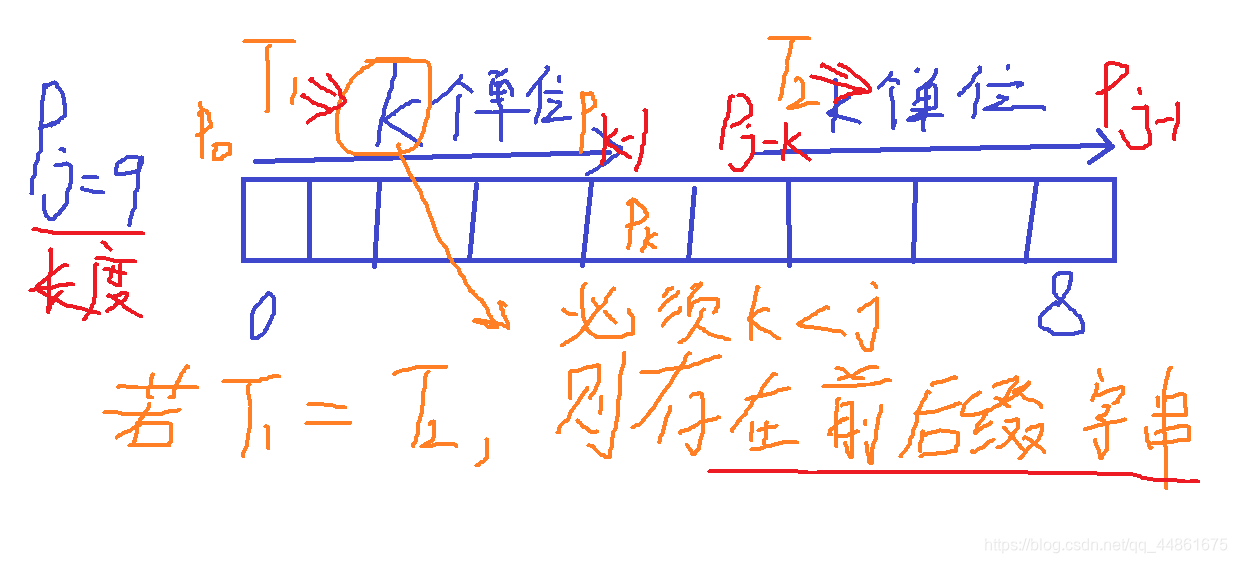 比如:
比如:
abcjkdabc,那么这个数组的最长前缀和最长后缀相同——必然是abc。
cbcbc,最长前缀和最长后缀相同——是cbc。
abcbc,最长前缀和最长后缀相同,是不存在的。
注意最长前缀:是说以第一个字符开始,但是不包含最后一个字符。
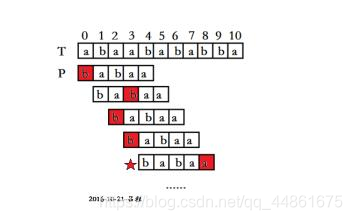
第二步,理解关于字符串匹配的规则
假设S与T要进行匹配,匹配规则如图
这里aba就是最长前缀字串,然后下一次a是最长前缀字串
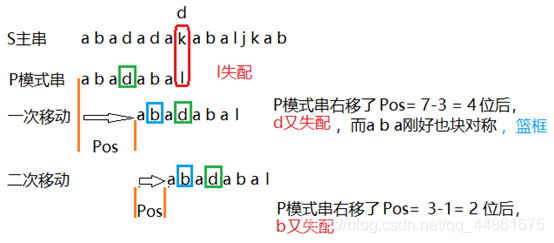
借别人的图示意:
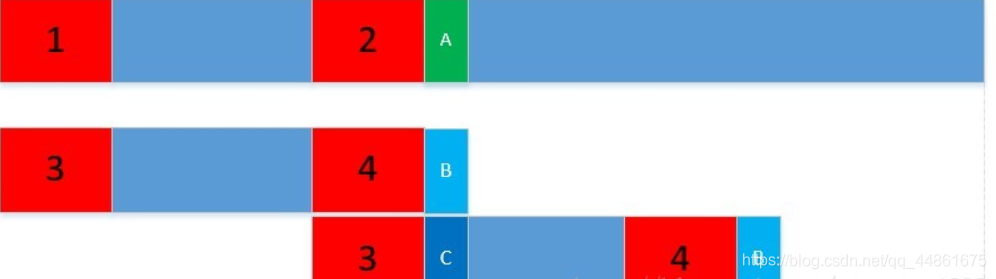
第三步,如何得出j的更新规则——即计算next数组
我看了数据结构(java)第四版,讲的很好。
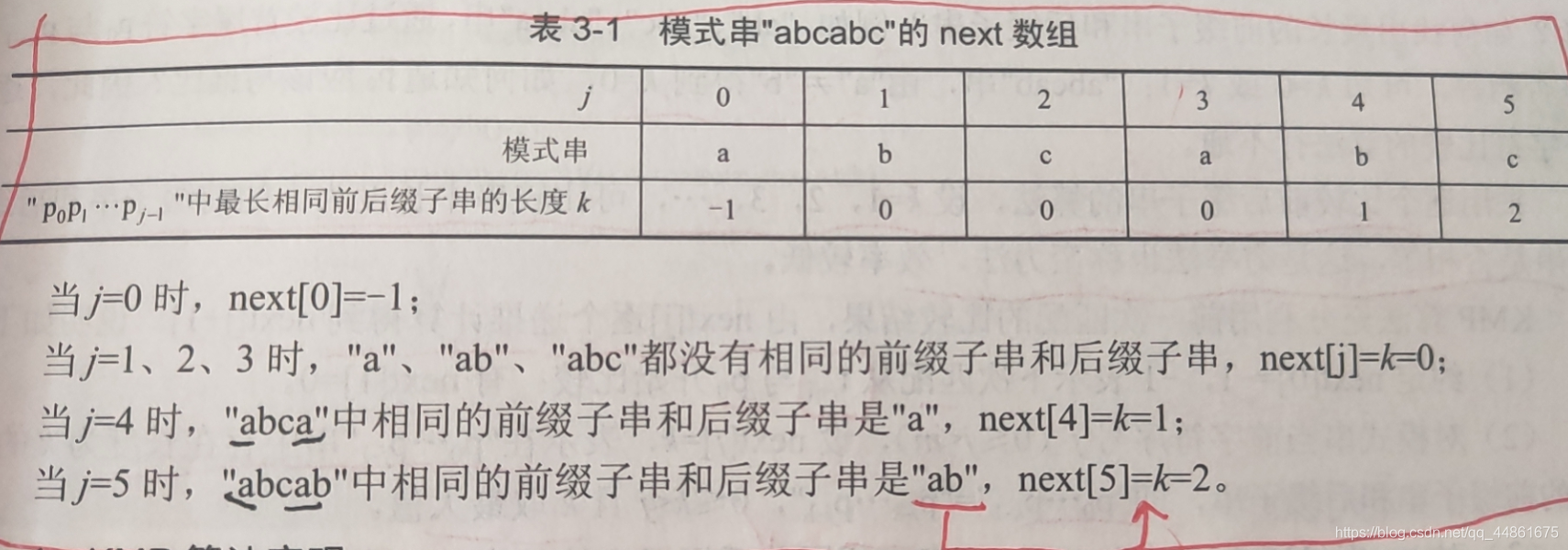
公式:
例子演示:
第四步,上计算next数组的代码
int get_next(string t,int * next) {
//先定义一个数组
int length = t.length();
int j=0,k=-1;
next[0] = -1;
while(j<length-1)//因为我们是在找最长前缀字串,这里得减一。
if(k==-1||t[j]==t[k]) { //当前的字串最新的字符相等或者字串总长度1
k++;
j++;//比较下一个字符
next[j] = k;//最长前缀字串记录下来,因为前面的k,j都加了1
} else
k = next[k];//重新在k长度的前缀字串找当前j长度字串的最长前缀字串,更新索,听说这里是最难理解的
return 1;
}
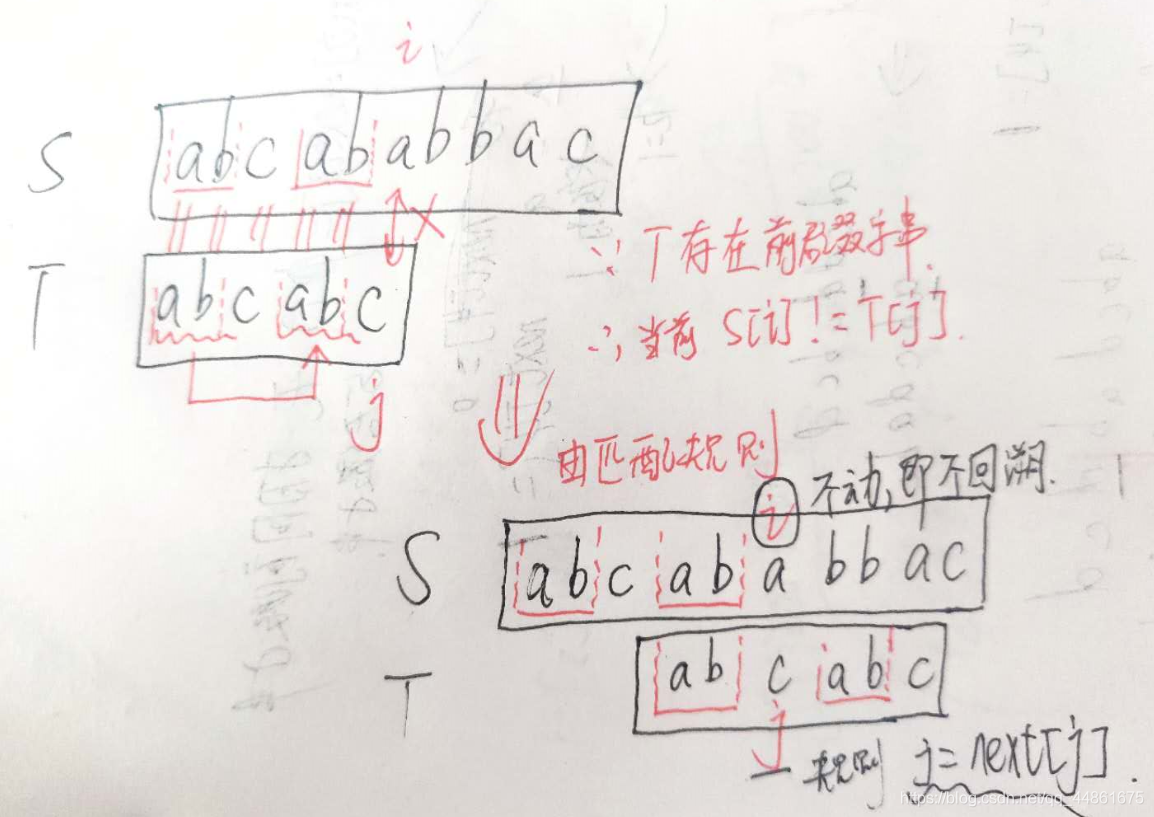
第五步,理解 k = next[k]
k = next[k];//重新在k长度的前缀字串找当前j长度字串的最长前缀字串,
这里我给例子演示,反正我是一下子就理解了。
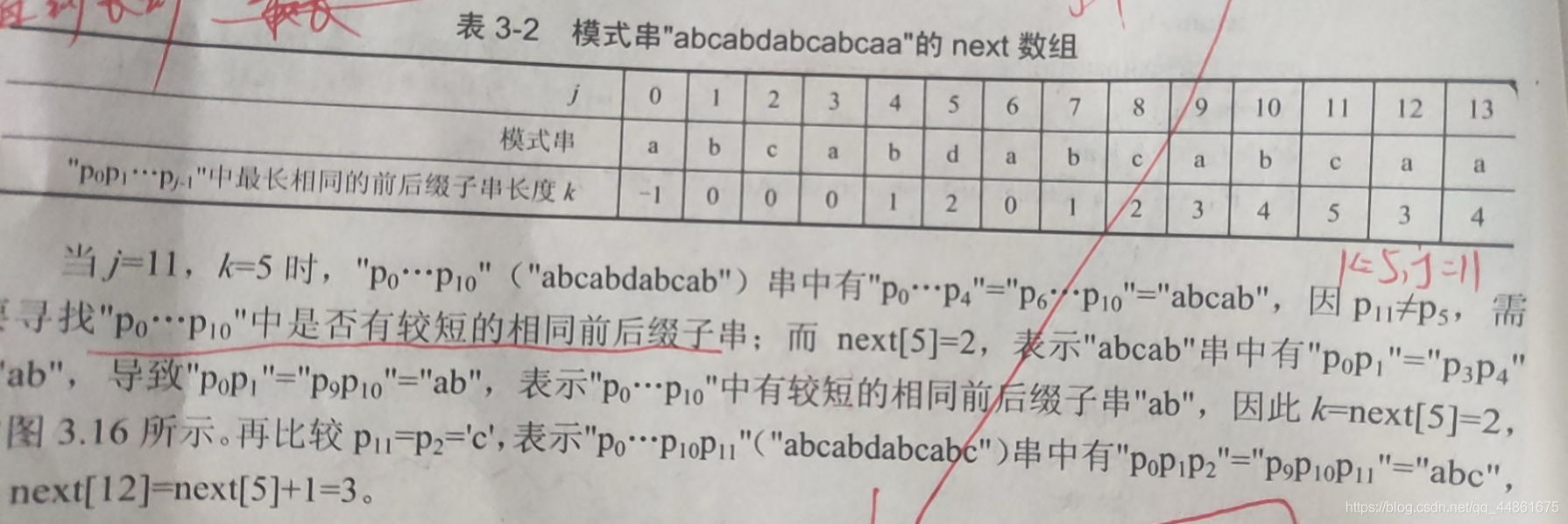
图示:因为p5!=p11,这个时候,最长前缀字串肯定不会比上次的大了,不可能是6,我们只能重新寻找,而重新寻找的规则就是k = next[k]=2

第六步,最后一步,上匹配字串的代码
#include<iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
//建立next数组
int get_next(string t,int * next) {
//先定义一个数组
int length = t.length();
int j=0,k=-1;
next[0] = -1;//这里是为了
while(j<length-1)//因为我们是在找最长前缀字串,这里得减一。
if(k==-1||t[j]==t[k]) { //当前的字串最新的字符相等或者字串总长度1
k++;
j++;//比较下一个字符
next[j] = k;//最长前缀字串记录下来
} else
k = next[k];//重新在k长度的前缀字串找当前j长度字串的最长前缀字串,更新索
return 1;
}
int compare_str(string s,string t,int pos) {
int n=s.length();
int m = t.length();
if(n<m||pos>=n||n==0) { //不合理的输入
return 0;
}
if(pos<=0) {
pos=0;//提高容错率
}
int next[m];
//生成next数组
get_next(t,next);
int i=pos,j=0;
while(i<n&&j<m)
if(j==-1||s[i]==t[j]) { //当前匹配成功,继续匹配下一个字符
i++;
j++;
} else { //i是不回溯,匹配规则更新匹配的j
j = next[j];//这里就是我们说的匹配规则
if(n-i+1<m-j+1)//剩下的字串不够t的长度,就不用比较了
break;
}
if(j==m)
return i-j;//成功匹配。,返回对应的索引
return -1;//否则退出
}
int main() {
string t,s;
cin>>s;
cin>>t;
int pos =compare_str(s,t,0);
cout<<pos;
return 0;
}
更新改进KMP算法。
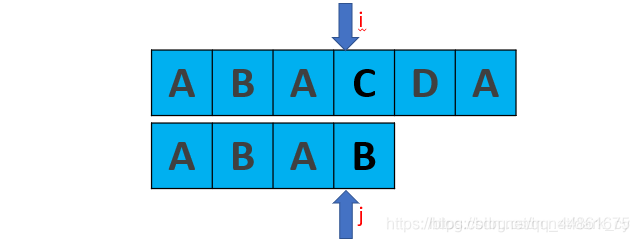
现在我们比较的是C和B,不匹配。
显然,当我们上边的算法得到的next数组应该是[ -1,0,0,1 ]
所以next[3] = 1。下一步的匹配:明显我们又来比较C和B,这是是多余的
所以我们应该改进计算next数组匹配
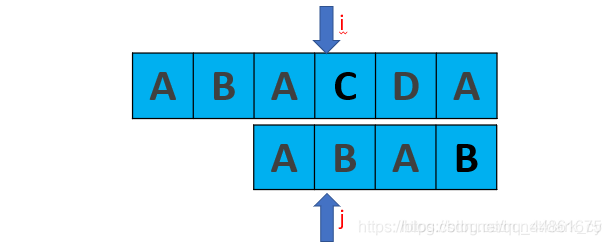
改进的算法 就是避免这种情况,代码演示
int get_next(string t,int * next) {
//先定义一个数组
int length = t.length();
int j=0,k=-1;
next[0] = -1;
while(j<length-1)//因为我们是在找最长前缀字串,这里得减一。
if(k==-1||t[j]==t[k]) { //当前的字串最新的字符相等或者字串总长度1
k++;
j++;//比较下一个字符
//使用改进的算法
if(t[j]!=t[k])
next[j] = k;//最长前缀字串记录下来
else next[j] = next[k];//直接跳到上次找到的后缀字串,改进的代码结束
} else
k = next[k];//重新在next[k]长度的前缀字串找当前j长度字串的最长前缀字串,更新索引
return 1;
}
参考博客
https://blog.csdn.net/dark_cy/article/details/88698736:
https://blog.csdn.net/starstar1992/article/details/54913261?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
