Q − l e a r n i n g Q-learning Q−learning与 S a r s a Sarsa Sarsa都是基于 Q t a b l e Q table Qtable的算法, Q − l e a r n i n g Q-learning Q−learning属于离线学习策略, S a r s a Sarsa Sarsa属于在线学习策略。
Q-learning
Q − l e a r n i n g Q-learning Q−learning算法伪代码:
Sarsa
S a r s a Sarsa Sarsa算法伪代码:

二者主要区别
Q − l e a r n i n g Q-learning Q−learning与 S a r s a Sarsa Sarsa的唯一区别在于 Q t a b l e Q table Qtable的更新方式。
Q − l e a r n i n g Q-learning Q−learning更新 Q Q Q值的方式:
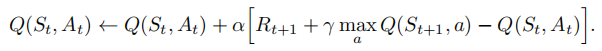
S a r s Sars Sarsa更新 Q Q Q值的方式:
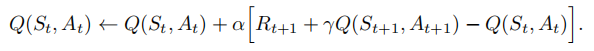
区别详解
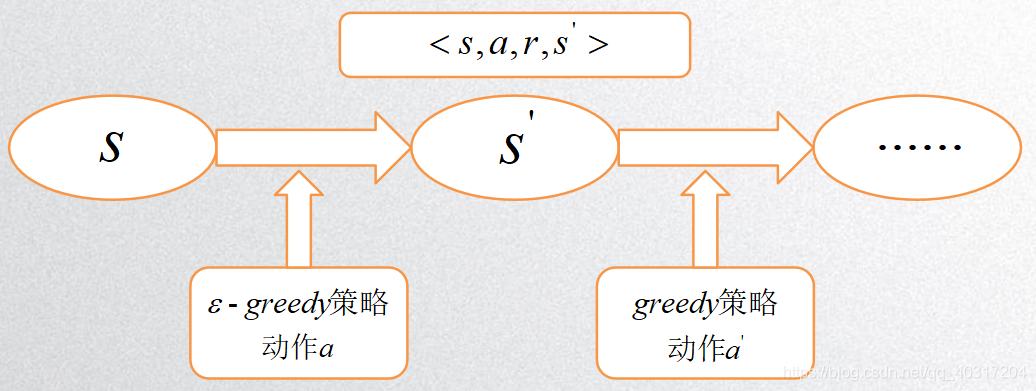
① 对于 Q − l e a r n i n g Q-learning Q−learning来说:在状态 S t S_t St下,根据某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略)执行动作 A t A_t At到达状态 S t + 1 S_{t+1} St+1之后,利用在状态 S t + 1 S_{t+1} St+1下采取所有动作中最大的那个 Q ( S t + 1 , a ) Q(S_{t+1},a) Q(St+1,a),来更新 Q ( S t , a ) Q(S_t,a) Q(St,a),但是其并不真正采取 ( S t + 1 , a ) (S_{t+1},a) (St+1,a)。对于在状态 S t + 1 S_{t+1} St+1出选择要执行的动作可以理解为 S t = S t + 1 S_t=S_{t+1} St=St+1,即在状态 S t + 1 S_{t+1} St+1下选择要执行的动作依然要使用相同的某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略)。
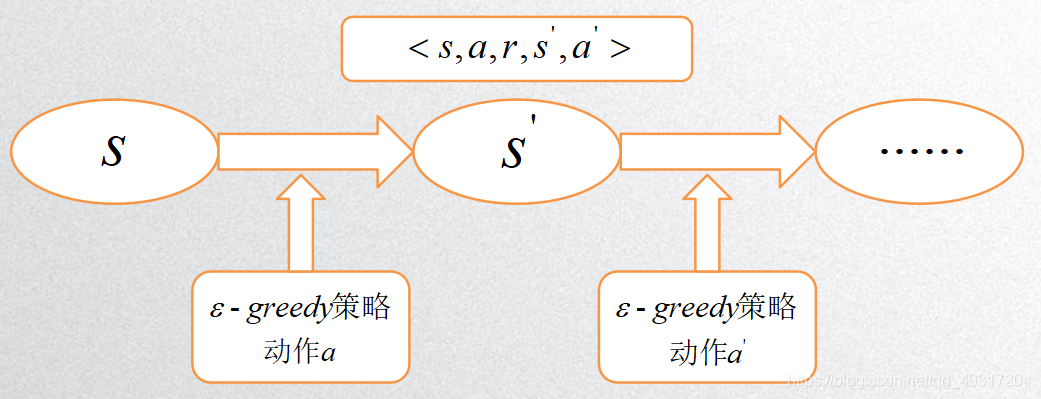
② 对于 S a r s a Sarsa Sarsa来说:在状态 S t S_t St下,根据某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略)执行动作 A t A_t At到达状态 S t + 1 S_{t+1} St+1之后,此时用来更新 ( S t , a ) (S_t,a) (St,a)的 Q Q Q值的方法依然采用某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略),并且真正采取 ( S t + 1 , a ) (S_{t+1},a) (St+1,a)。
③ 我们要把选取动作和更新 Q Q Q表值区分开来,对于两个算法来说,选择动作都是采用某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略),区别就在于 Q − l e a r n i n g Q-learning Q−learning更新 Q Q Q值的方式为贪婪策略,即直接选择最大的 Q ( S t + 1 , a ) Q(S_{t+1},a) Q(St+1,a),而 S a r s a Sarsa Sarsa更新 Q Q Q值的方式依然为某策略(如 ϵ − g r e e d y \epsilon-greedy ϵ−greedy策略)。
④ Q − l e a r n i n g Q-learning Q−learning选取动作和更新 Q Q Q表值的方法不同,而 S a r s a Sarsa Sarsa选取动作和更新 Q Q Q表值的方法相同。
⑤ Q − l e a r n i n g Q-learning Q−learning每次选取动作和更新 Q t a b l e Q table Qtable后就会生成一个 < s , a , r , s ′ > <s,a,r,s'> <s,a,r,s′>序列,成为一个sample。同理, S a r s a Sarsa Sarsa每次选取动作和更新 Q t a b l e Q table Qtable后会生成另一个 < s , a , r , s ′ > <s,a,r,s'> <s,a,r,s′>序列,成为另一个sample。

Q-learning与Sarsa图解
Q − l e a r n i n g Q-learning Q−learning:
S a r s a Sarsa Sarsa:
cliff-walking代码实例
Sutton的《强化学习》例题6.6的代码。
运用Q-learning和Sarsa两种算法进行训练,并进行对比。