最近,社区开源了一款语音克隆 TTS 模型 - F5-TTS,效果非常惊艳,不到一周,HuggingFace 模型下载量高达 49K!
实操只需 2 秒音频即可合成超拟人的语音,推理速度优于前段时间和大家分享的:
最近打算在项目中用到它,顺便做一个测评,分享给大家。
1. F5-TTS 简介
老规矩,先来简单介绍下~
F5-TTS 有哪些亮点?
- 在 E2-TTS 的基础上改进:文本表示细化和推理采样策略。
- 在保持简单架构的同时,提供了更好的性能和更快的推理速度。
- 零样本能力更强,也就是语音克隆效果更加惊艳(文末有实测)
官方实测,不管在英文和中文数据集上,均优于阿里开源的 CosyVoice:

2. 在线体验
在线体验地址:https://www.modelscope.cn/studios/modelscope/E2-F5-TTS
F5-TTS 已上线 ModelScope,无需本地部署,即刻在线体验!
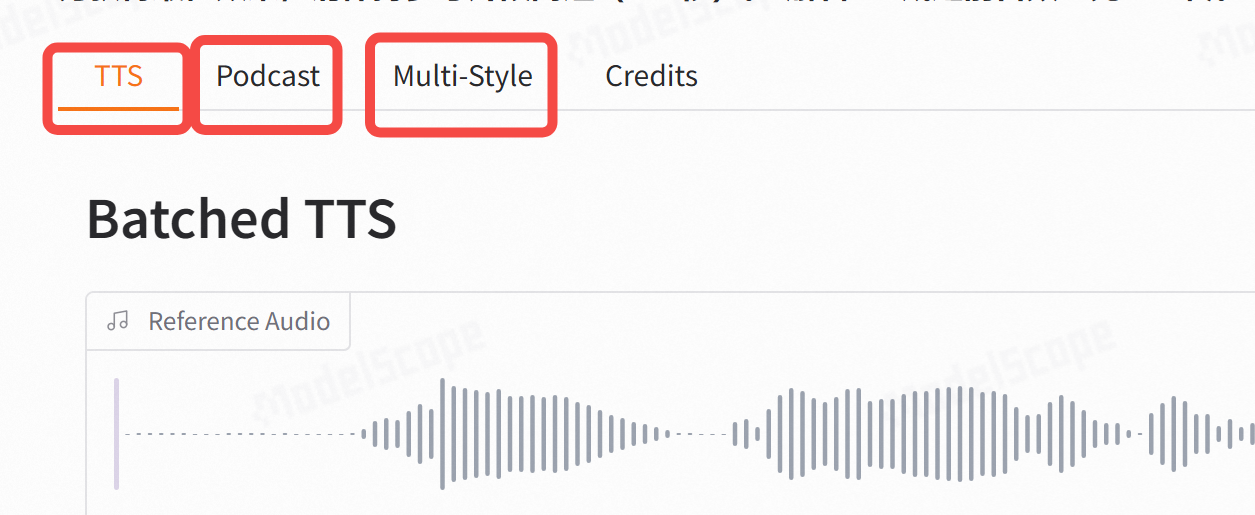
支持三种形式:
- TTS:标准的单音色语音克隆;
- Podcast:多音色克隆:有声读物制作者的福音;
- Multi-Style:多种说话情绪,例如 Shouting…
当然,如果需要在生产环境使用,那就少不了要本地部署服务。
3. 本地部署
3.1 环境准备
首先准备 F5-TTS 环境:
git clone https://github.com/SWivid/F5-TTS.git
cd F5-TTS
conda create -n f5tts python=3.10 -y
conda activate f5tts
pip install -r requirements.txt
然后,把模型下载到本地,方便调用:
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download SWivid/F5-TTS --local-dir ckpts/
huggingface-cli download charactr/vocos-mel-24khz --local-dir ckpts/vocos
3.2 推理测试
先来测试下单音色语音克隆:
python inference-cli.py \
--model "F5-TTS" \
--ref_audio "tests/ref_audio/test_en_1_ref_short.wav" \
--ref_text "Some call me nature, others call me mother nature." \
--gen_text "I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring. Respect me and I'll nurture you; ignore me and you shall face the consequences." \
--load_vocoder_from_local
相关参数说明:
- –model 代表对应的模型,这里指定 F5-TTS;
- –ref_audio 待克隆的音频;
- –ref_text 待克隆的音频对应的文本,如果不提供的话会默认下载
openai/whisper-large-v3-turbo进行语音识别; - –gen_text 希望合成的文本;
多音色克隆:
python inference-cli.py -c samples/story.toml
项目采用 tomli 管理配置信息,我们来看下配置文件,这里的 voices.town 用来指定不同的音色:
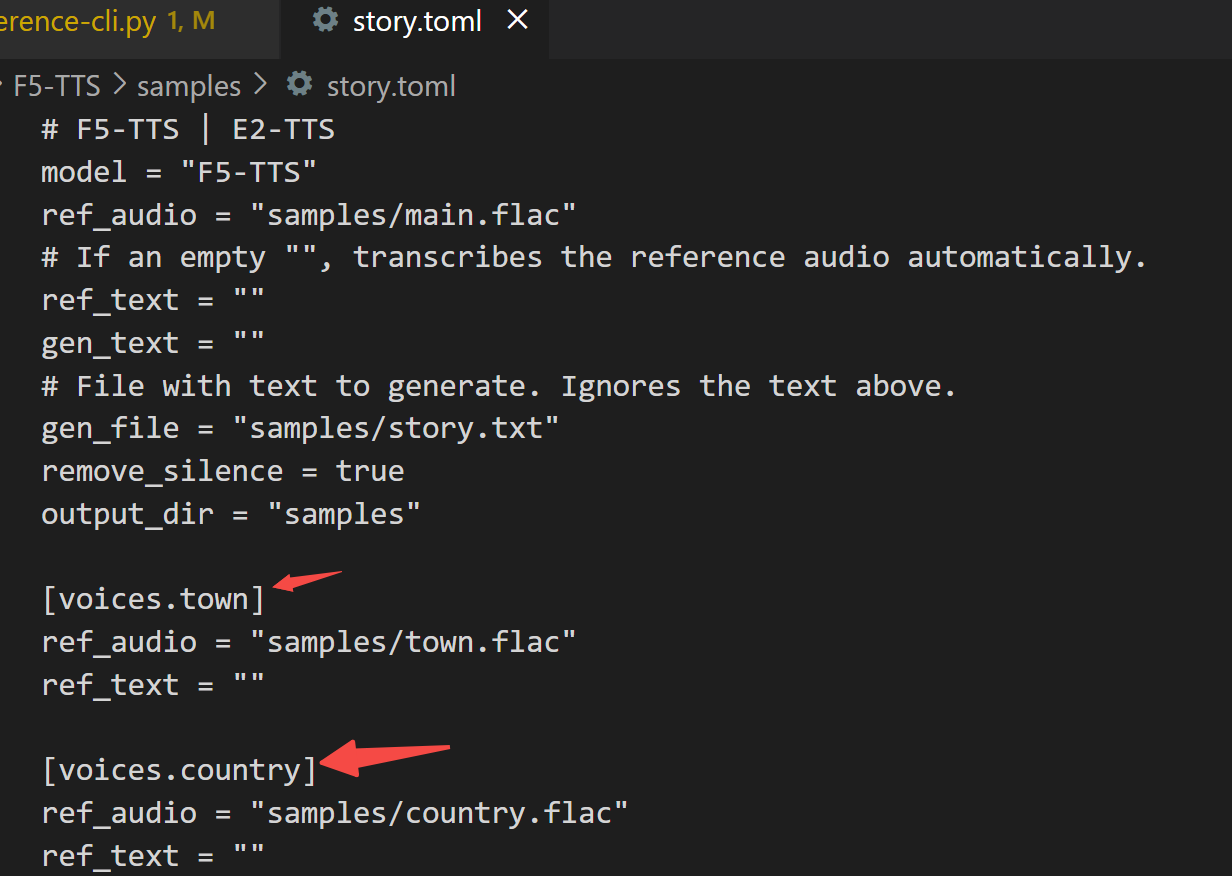
3.3 服务端部署
项目仓库中没有实现后端,因此我们采用 fastapi 完成后端部署。
首先,新建一个配置文件,把后端支持的音色,都放进来:
[voices.zh]
ref_audio = "tests/ref_audio/test_zh_1_ref_short.wav"
ref_text = "对,这就是我,万人敬仰的太乙真人。"
[voices.zh-CN-XiaoxiaoNeural]
ref_audio = "tests/ref_audio/zh-CN-XiaoxiaoNeural.wav"
ref_text = "曾经有一份真诚的爱情放在我面前,我没有珍惜。"
[voices.zh-CN-XiaoyiNeural]
ref_audio = "tests/ref_audio/zh-CN-XiaoyiNeural.wav"
ref_text = "曾经有一份真诚的爱情放在我面前,我没有珍惜。"
[voices.zh-CN-YunjianNeural]
ref_audio = "tests/ref_audio/zh-CN-YunjianNeural.wav"
ref_text = "曾经有一份真诚的爱情放在我面前,我没有珍惜。"
此外,还应该支持客户端上传待克隆的音频文件,因此数据模型定义如下:
class TTSRequest(BaseModel):
voice_name: str = '' # 目标语音名称
ref_audio: str = '' # 参考语音 base64编码的音频文件
ref_text: str = '' # 参考语音的文本
ref_tag: str = '' # 参考语音的标签
gen_text: str = '' # 待合成的文本
如果客户端指定了 voice_name 则采用配置文件中的音色进行克隆,如果客户端上传了ref_audio,则参考ref_audio进行克隆。
实现逻辑如下,供大家参考:
@app.post("/f5tts")
async def f5tts(request: TTSRequest):
if request.voice_name:
ref_voice = target_voices[request.voice_name]
ref_audio, ref_text = ref_voice['ref_audio'], ref_voice['ref_text']
else:
ref_audio, ref_text = request.ref_audio, request.ref_text
if not ref_audio:
return {"msg": "Please provide voice name or reference audio"}
ref_audio = save_audio(ref_audio, request.ref_tag)
if not ref_text:
ref_text = asr_sensevoice(ref_audio)
final_wave = infer_batch(ref_audio, ref_text, gen_text)
最后,调用 F5-TTS 模型将生成的音频文件返回,就 OK 了!
4. 性能实测
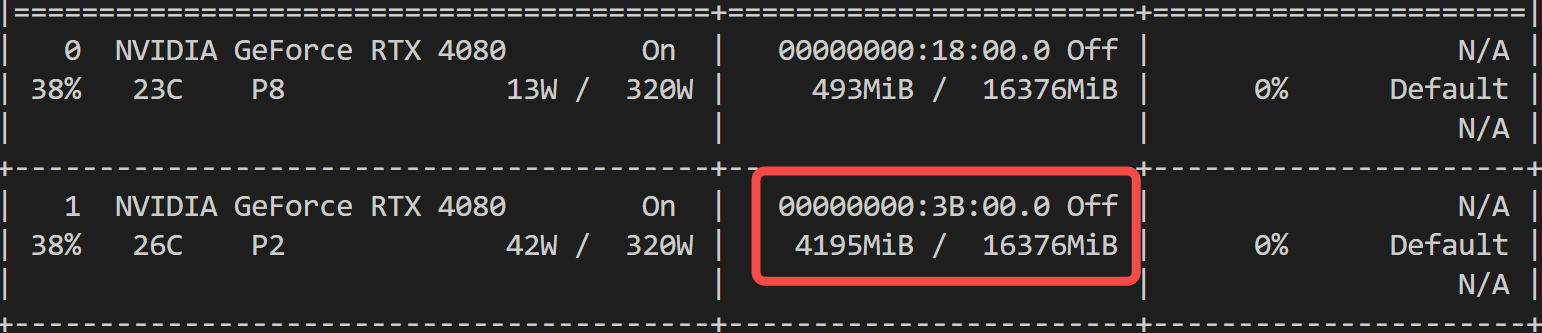
4.1 显存占用
模型加载后的显存占用情况:
语音合成的显存占用情况:
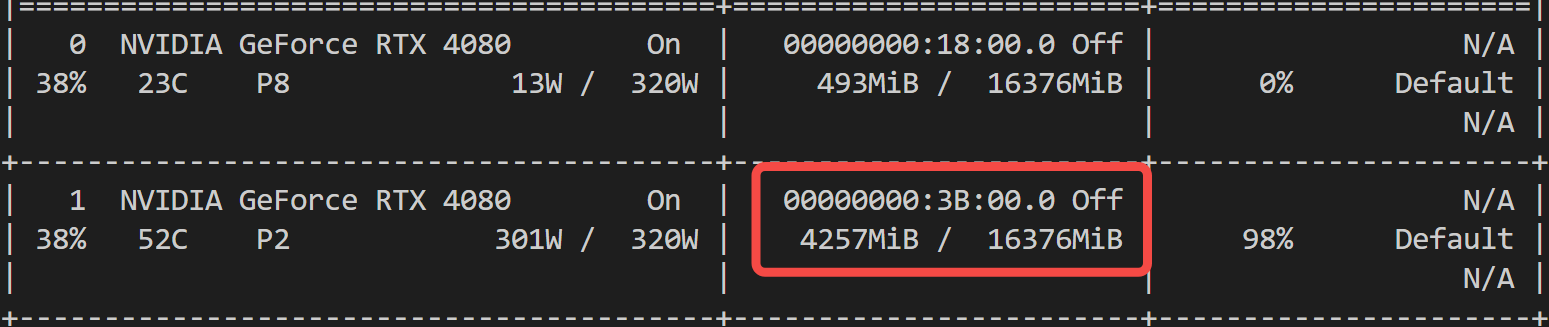
一张消费级显卡,妥妥够了!相比 CosyVoice 的 6G 显存,优势显著~
生成 13 秒的音频,只需 4.1 秒!
4.2 合成效果
最后,一起来感受一下合成效果:
参考音频1:
ref_audio_1
语音克隆效果:
gen_audio_1
参考音频2:
ref_audio_2
语音克隆效果:
gen_audio_2
写在最后
本文带大家本地部署并实测了最新开源的语音合成/克隆工具 - F5-TTS。
AI 应用大体可分为:文本、语音、图片、视频,其中语音已被硅基生物攻破。从 GPT-SoVITS 到 F5-TTS,语音克隆的难度已经极大降低,不得不说,一个人人有嘴替的时代已经到来。
如果对你有帮助,欢迎点赞收藏备用。
为方便大家交流,新建了一个 AI 交流群,欢迎感兴趣的小伙伴加入。
最近打造的微信机器人小爱(AI)也在群里,公众号后台「联系我」,拉你进群。