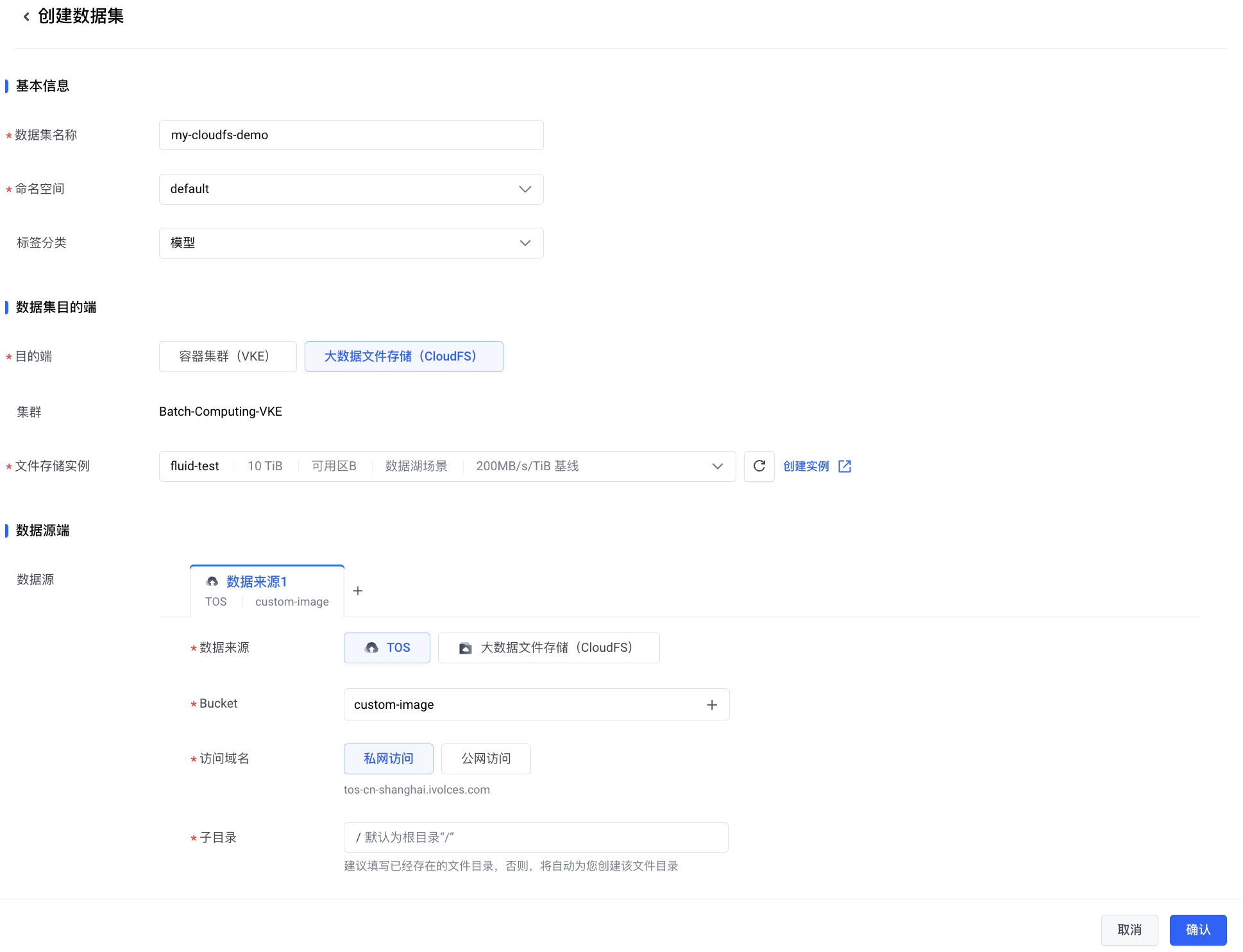
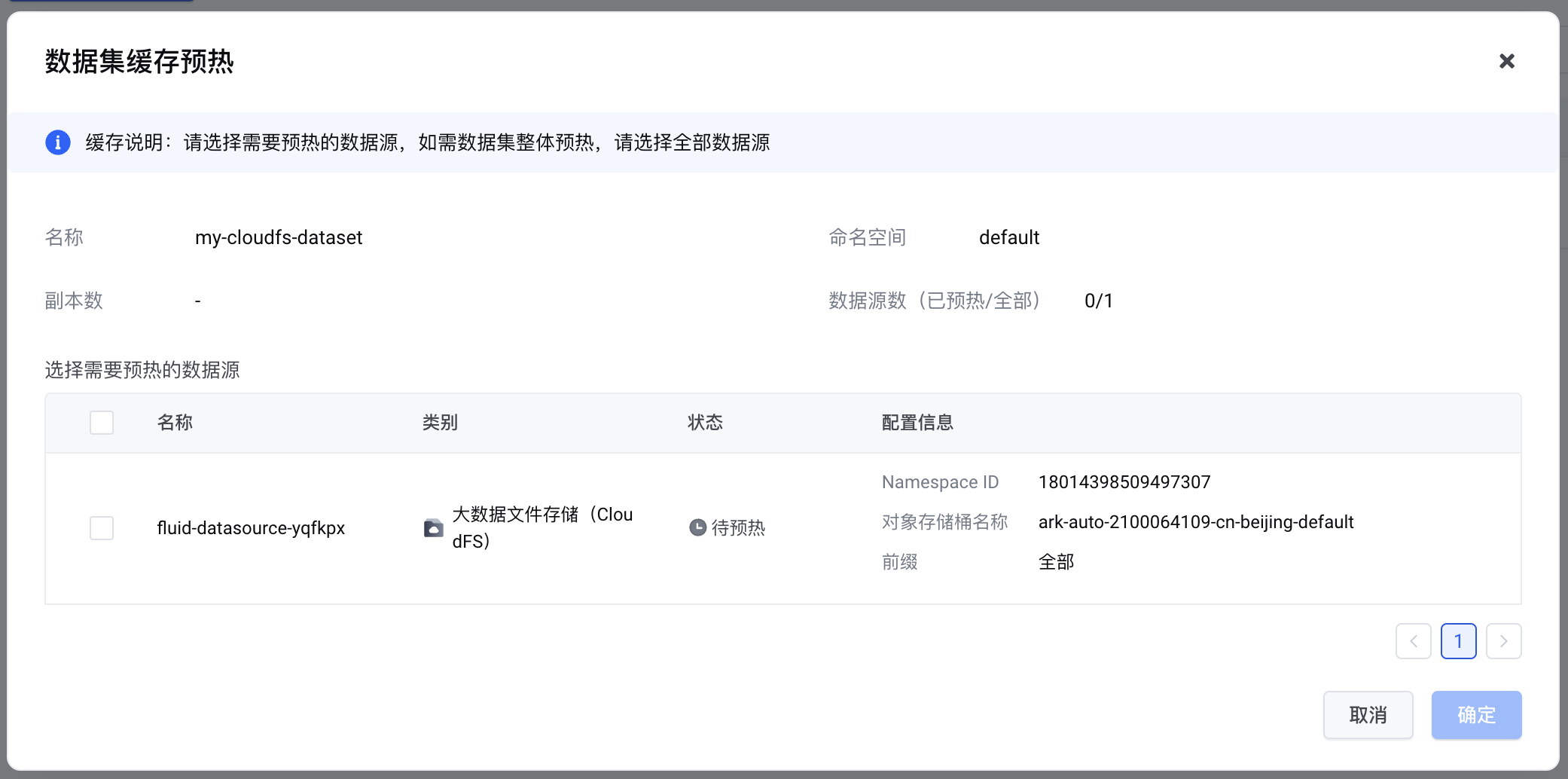
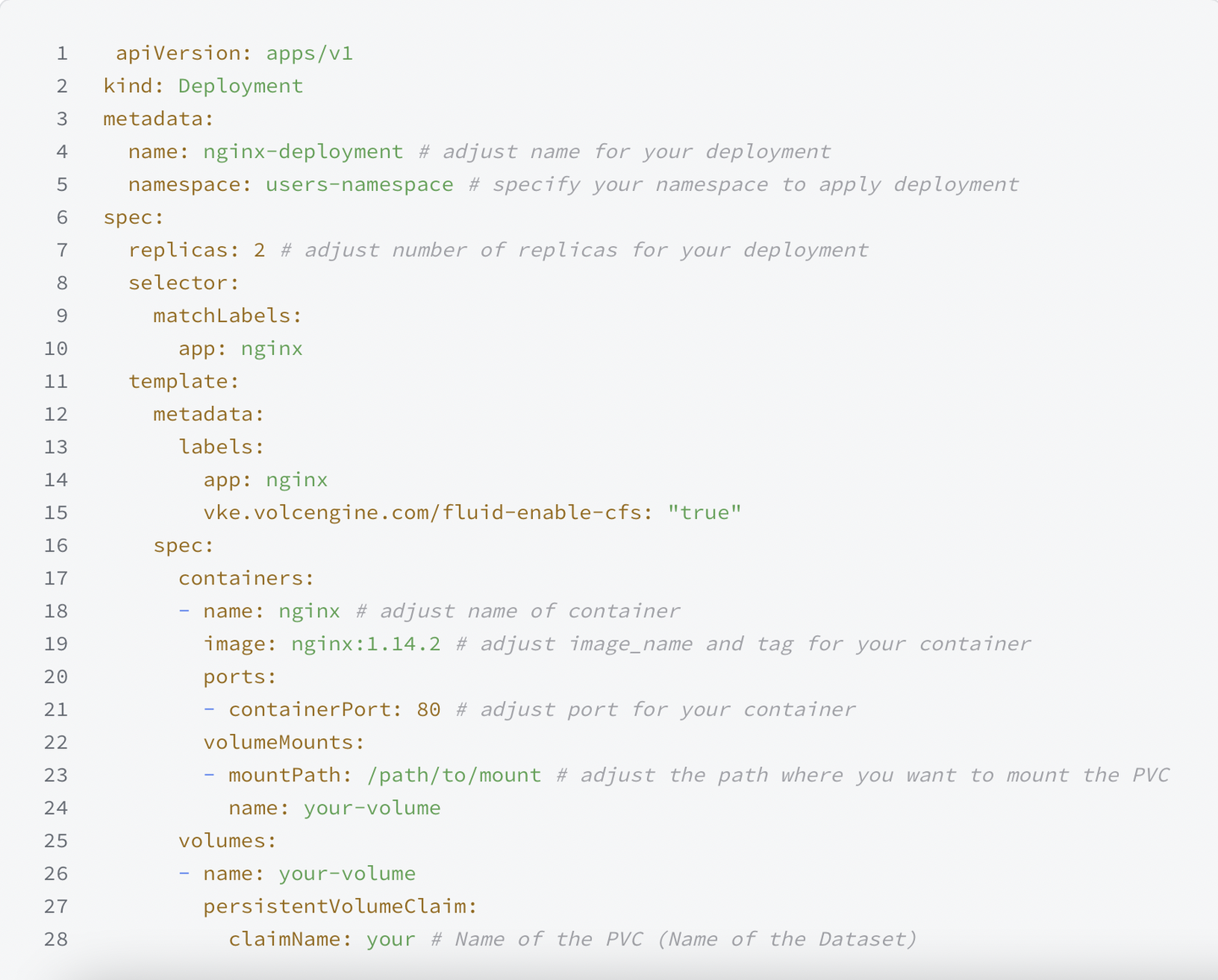
本文将介绍两种在火山引擎云上部署 DeepSeek-R1 全尺寸模型服务的方案,涵盖 大模型 推理服务的 Terraform 一键部署、 容器化 部署、资源弹性伸缩和模型可观测。
-
性能与精度 : 企业级应用(如金融分析、医疗诊断、智能客服等)通常需要处理复杂任务,对模型的精度和性能要求极高,DeepSeek-R1 作为更大的模型,参数量更多,能够捕捉更复杂的模式和特征,因此在处理高难度任务时表现更优;
-
处理复杂任务: 企业级场景通常涉及更复杂的推理任务(如语义理解、决策支持等),DeepSeek-R1 的强大计算能力和更大的容量使其更适合处理这些任务;
-
资源环境支持: 企业级用户通常拥有强大的计算资源(如高性能服务器、GPU 集群等),能够支持更大模型的部署和运行,DeepSeek-R1 虽然计算开销大,但在企业级环境中,资源通常不是瓶颈;
-
模型的可扩展性 : 企业级用户可能需要根据业务需求对模型进行微调或扩展,DeepSeek-R1 的更大容量和更强的表达能力使其更容易适应新的任务或领域。
-
方案一:基于 Terraform 实现在 GPU 云服务器上的大模型一键部署,优势是简单、易操作;
-
方案二:基于 GPU 云服务器、容器服务 VKE 的多机分布式推理方案,通过优化云上架构设计支持大规模模型的推理,提高吞吐量和性能,大幅提升模型加载速度,使更大化资源利用率、提高可用性和容错性成为可能。
方案一:Terraform 双机一键部署
-
易用性: 基于开源 Terraform 的方案,脚本内置了常用参数,用户只需下载 Terraform 脚本代码并执行,即可安全、高效地完成基于 GPU 云服务器的部署,避免手工操作的繁琐;
-
模型下载快速、稳定、低成本:同一 Region 的机器走内网快速拉取模型,带宽稳定在 300MB/s 以上,并且避免了公网流量费用。
资源配置推荐

Step1:Terraform 环境准备
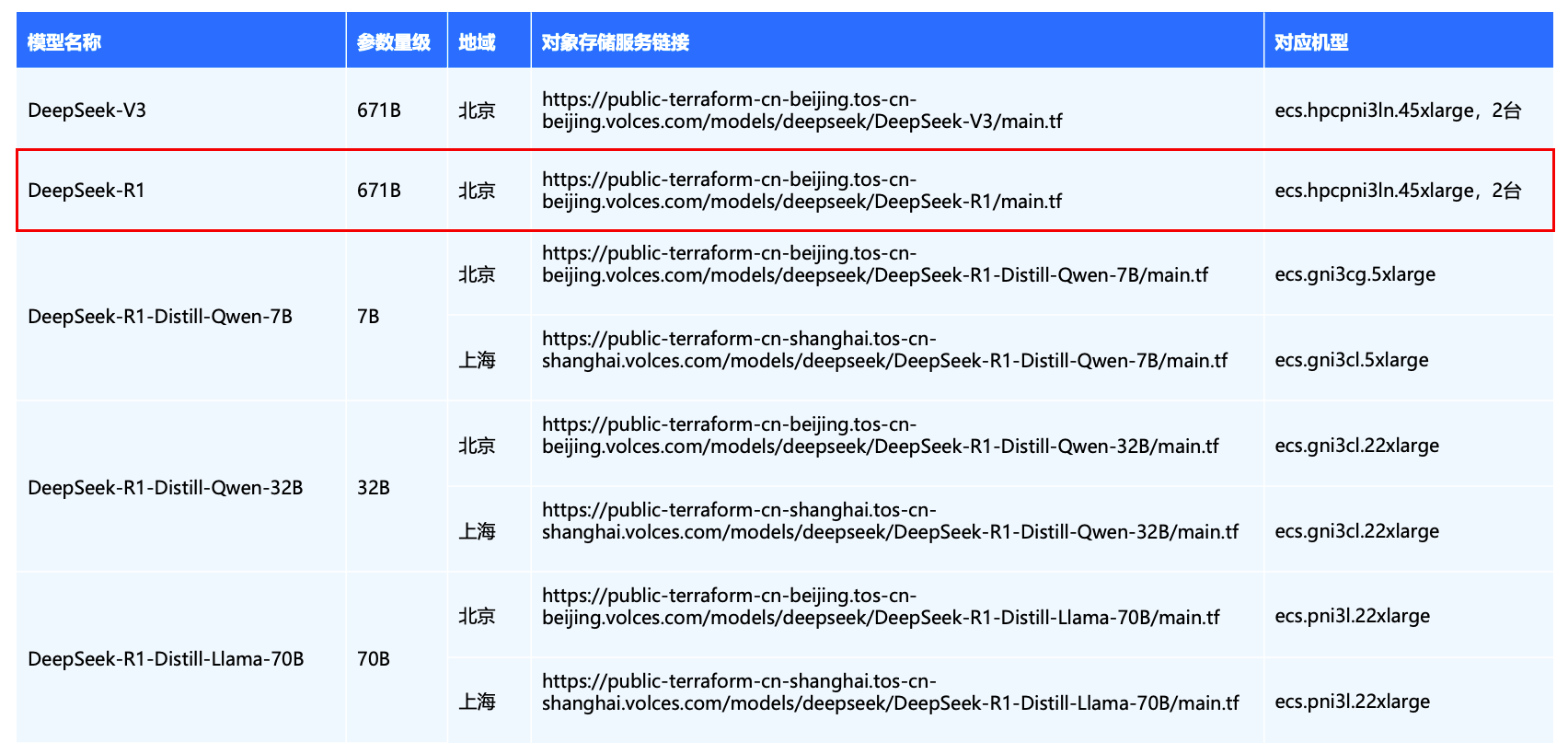
Step2:下载并执行 Terraform 脚本
wget https://public-terraform-cn-beijing.tos-cn-beijing.volces.com/models/deepseek/DeepSeek-R1/main.tf

terraform init
Terraform has been successfully initialized!
terraform plan
terraform plan
命令的输出是在应用配置时 Terraform 预配的资源列表。
terraform apply
Step3:测试验证
CONTAINER_ID
查看容器是否拉取到模型和权重,当 docker logs 显示如下内容时表示服务已成功启动(全尺寸模型和权重拉取时间较长,请耐心等待)。


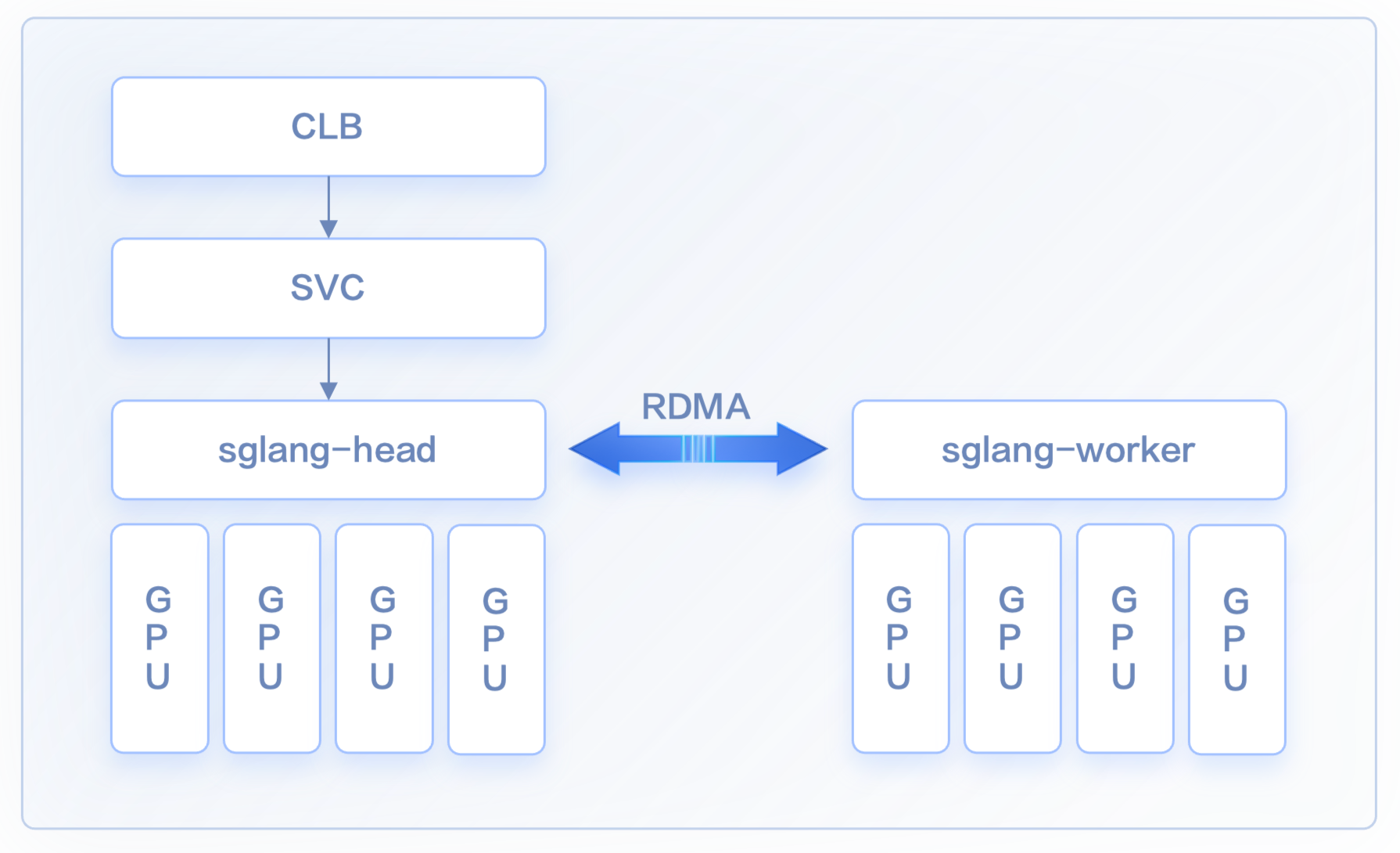
方案二:云原生多机分布式推理 @杨欣然
-
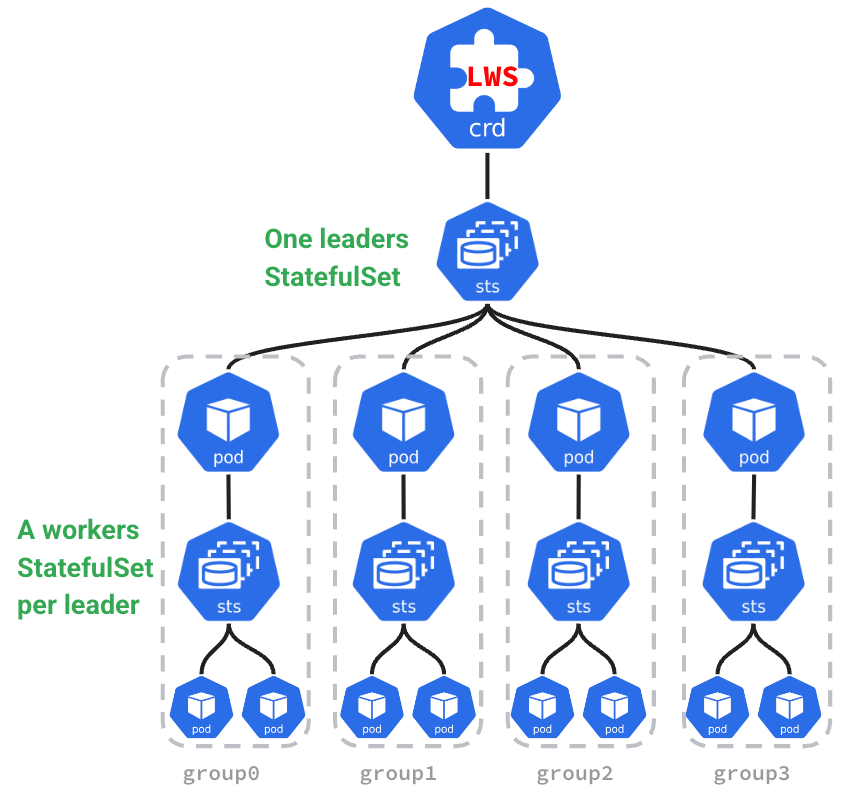
简化分布式推理的部署:通过 LWS API,提供了一个声明式的 API,用户只需定义 Leader 和 Worker 的配置,Kubernetes 控制器会自动处理其生命周期管理。用户可以更轻松地部署复杂的分布式推理工作负载,而无需手动管理 Leader 和 Worker 的依赖关系和副本数量。
-
无缝水平扩容:上文中提到分布式推理的服务需要多个POD 共同提供服务,在进行扩容时也需要以多个Pod 一组为原子单位进行扩展, LWS 可以与 k8s HPA 无缝对接,将 LWS 作为HPA 扩容的Target,实现推理服务整组扩容
-
拓扑感知调度:在分布式推理中,不同 Pod 需要进行大量数据交互。为了减少通信延时 LWS API 结合了拓扑感知调度,保证能够保证 Leader 和 Worker Pod 能够调度到 RDMA 网络中拓扑距离尽可能接近的节点上。
环境配置推荐
GPU 资源配置

RDMA 组网
分布式推理引擎
Step1:模型拉取
tosutil config -e=tos-cn-beijing.volces.com -i=${AK} -k=${SK} -re=cn-beijing
tosutil cp -r -j 6 -p 6 ${SOURCE_MODEL_TOS_PATH} tos://${TOS_BUCKET}
-
SOURCE_MODEL_TOS_PATH 为预置模型的 TOS 路径。以 DeepSeek-R1 模型为例,SOURCE_MODEL_TOS_PATH 即为:tos:// ai-public-models-cn-beijing/models/DeepSeek-R1/
-
TOS_BUCKET 为用户创建的 TOS 桶的名称,具体可以在桶概览页查看
Step2:模型部署
创建高性能计算集群
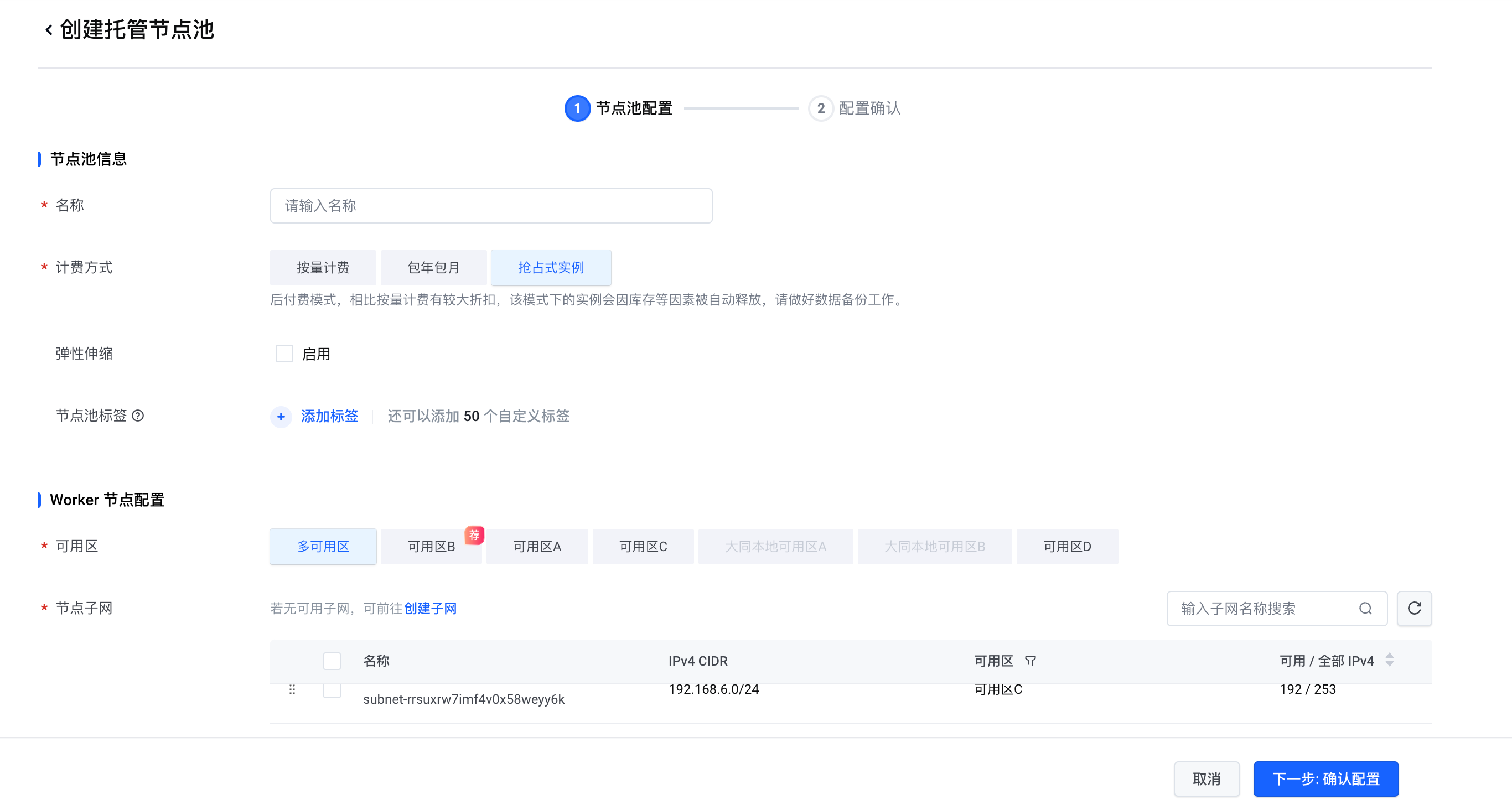
创建 VKE 集群

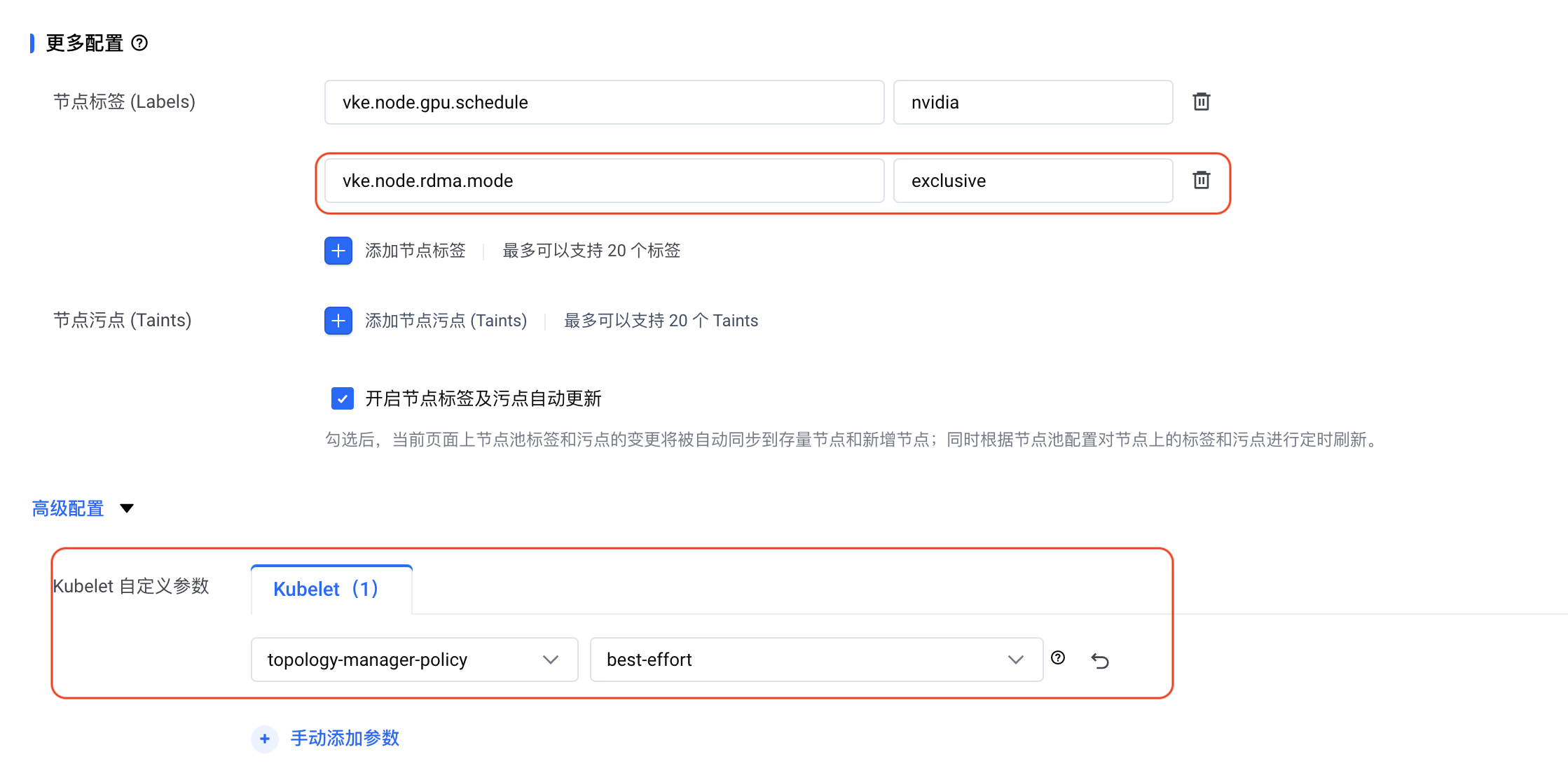

安装 LeaderWorkerSet
-
安装CRD
kubectl apply --server-side -f manifest.yaml
通过 LeaderWorkerSet 部署模型
sglang.yaml
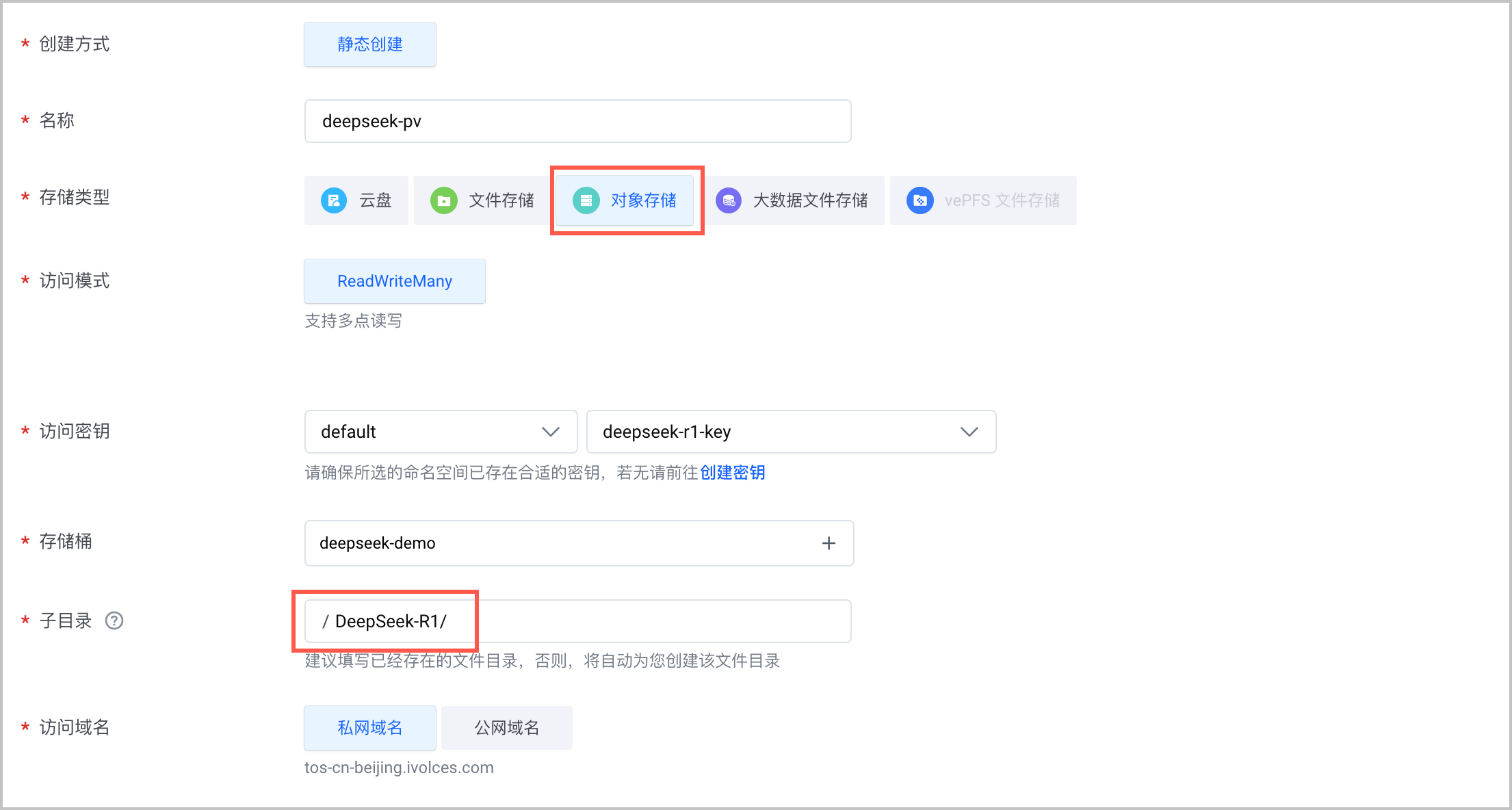
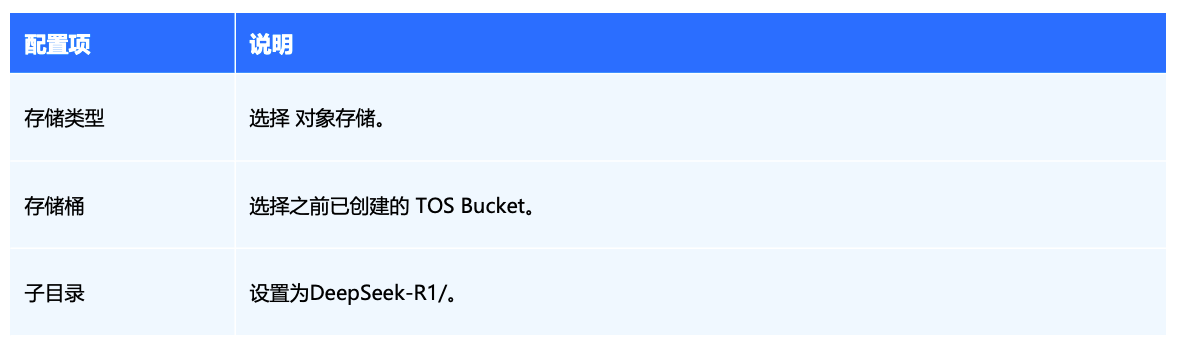
如下所示,需要注意的是, persistentVolumeClaim.claimName 需要和之前创建模型 PV/PVC 步骤中创建的 PVC 名称对应:
apiVersion: http://leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
metadata:
name: sglang
spec:
replicas: 1 # pod group 数量
startupPolicy: LeaderCreated
rolloutStrategy:
type: RollingUpdate
rollingUpdateConfiguration:
maxSurge: 0
maxUnavailable: 2 # 需要开启 MaxUnavailableStatefulSet feature gate 生效
leaderWorkerTemplate:
size: 2
restartPolicy: RecreateGroupOnPodRestart
leaderTemplate:
metadata:
labels:
role: leader
annotations:
http://k8s.volcengine.com/pod-networks: |
[
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
}
]
spec:
containers:
- name: sglang-head
image: http://ai-containers-cn-beijing.cr.volces.com/deeplearning/sglang:v0.4.2.post2-cu124
imagePullPolicy: IfNotPresent
workingDir: /sgl-workspace
command:
- bash
- -c
- 'cd /sgl-workspace && GLOO_SOCKET_IFNAME=eth0 NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_IB_HCA=mlx5_ python3 -m sglang.launch_server --model-path /models/deepseek --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank 0 --trust-remote-code --context-length 131072 --mem-fraction-static 0.7 --enable-metrics --host 0.0.0.0 --port 8080'
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 20000
name: distributed
protocol: TCP
resources:
limits:
http://nvidia.com/gpu: "8"
http://vke.volcengine.com/rdma: "4"
requests:
http://nvidia.com/gpu: "8"
http://vke.volcengine.com/rdma: "4"
securityContext:
capabilities:
add:
- IPC_LOCK
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /models/deepseek
name: models
- mountPath: /dev/shm
name: shared-mem
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
volumes:
- name: models
persistentVolumeClaim:
claimName: deepseekr1
- emptyDir:
medium: Memory
name: shared-mem
dnsPolicy: ClusterFirst
workerTemplate:
metadata:
annotations:
http://k8s.volcengine.com/pod-networks: |
[
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
},
{
"cniConf":{
"name":"rdma"
}
}
]
spec:
containers:
- name: sglang-worker
image: http://ai-containers-cn-beijing.cr.volces.com/deeplearning/sglang:v0.4.2.post2-cu124
imagePullPolicy: IfNotPresent
workingDir: /sgl-workspace
command:
- bash
- -c
- 'cd /sgl-workspace && GLOO_SOCKET_IFNAME=eth0 NCCL_SOCKET_IFNAME=eth0 NCCL_IB_DISABLE=0 NCCL_IB_HCA=mlx5_ python3 -m sglang.launch_server --model-path /models/deepseek --tp 16 --dist-init-addr $LWS_LEADER_ADDRESS:20000 --nnodes $LWS_GROUP_SIZE --node-rank $LWS_WORKER_INDEX --trust-remote-code --context-length 131072 --enable-metrics --host 0.0.0.0 --port 8080'
env:
- name: LWS_WORKER_INDEX
valueFrom:
fieldRef:
fieldPath: metadata.labels['http://leaderworkerset.sigs.k8s.io/worker-index']
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 20000
name: distributed
protocol: TCP
resources:
limits:
http://nvidia.com/gpu: "8"
http://vke.volcengine.com/rdma: "4"
requests:
http://nvidia.com/gpu: "8"
http://vke.volcengine.com/rdma: "4"
securityContext:
capabilities:
add:
- IPC_LOCK
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /models/deepseek
name: models
- mountPath: /dev/shm
name: shared-mem
dnsPolicy: ClusterFirst
volumes:
- name: models
persistentVolumeClaim:
claimName: deepseekr1
- emptyDir:
medium: Memory
name: shared-mem
kubectl apply -f sglang.yaml
Step3:对外访问

kubectl apply -f sglang-api-svc.yaml



进阶: 可观测 、弹性及模型加速
模型可观测
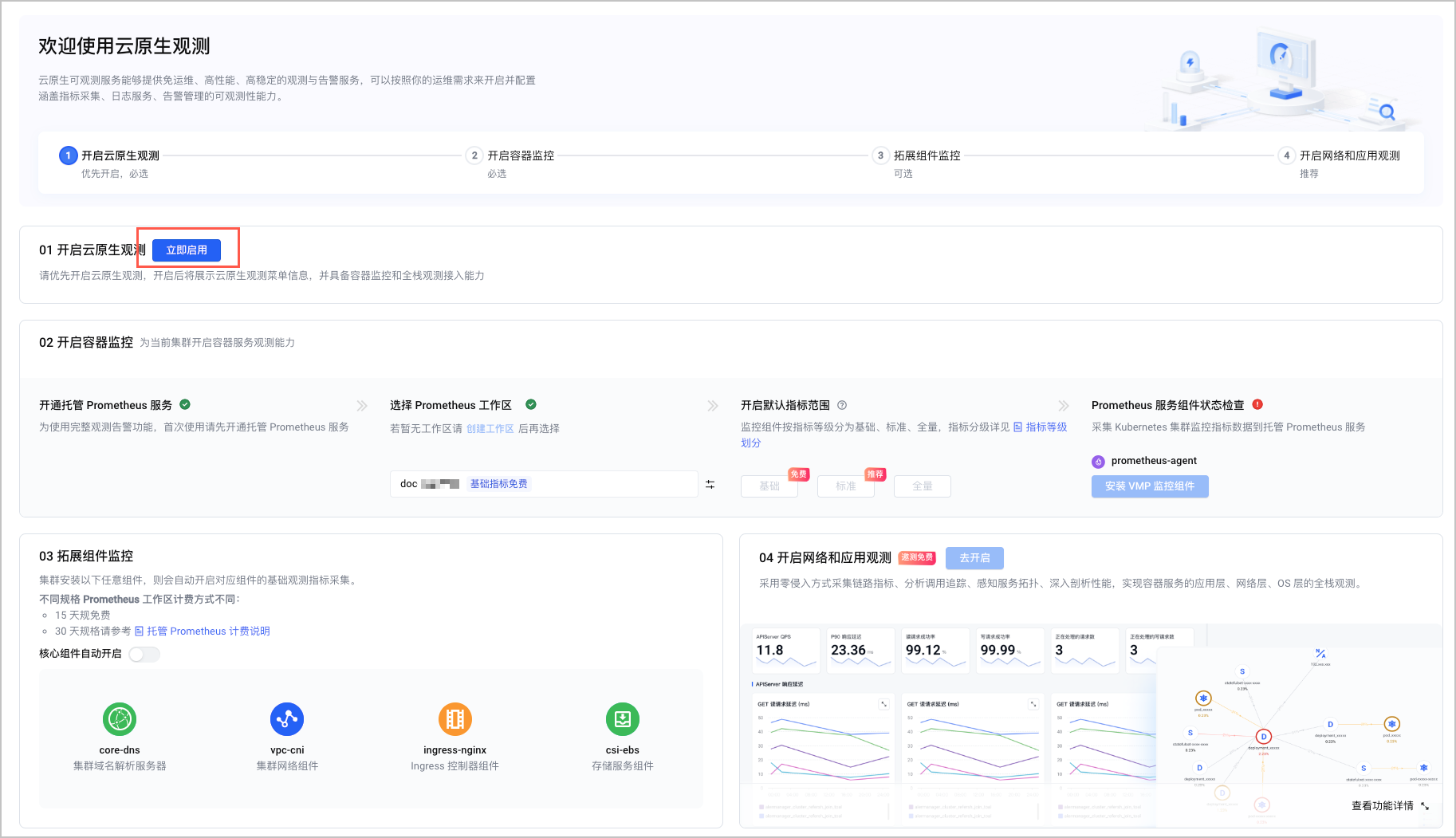
-
创建 service monitor

kubectl apply -f sglang-api-svc-discover.yaml
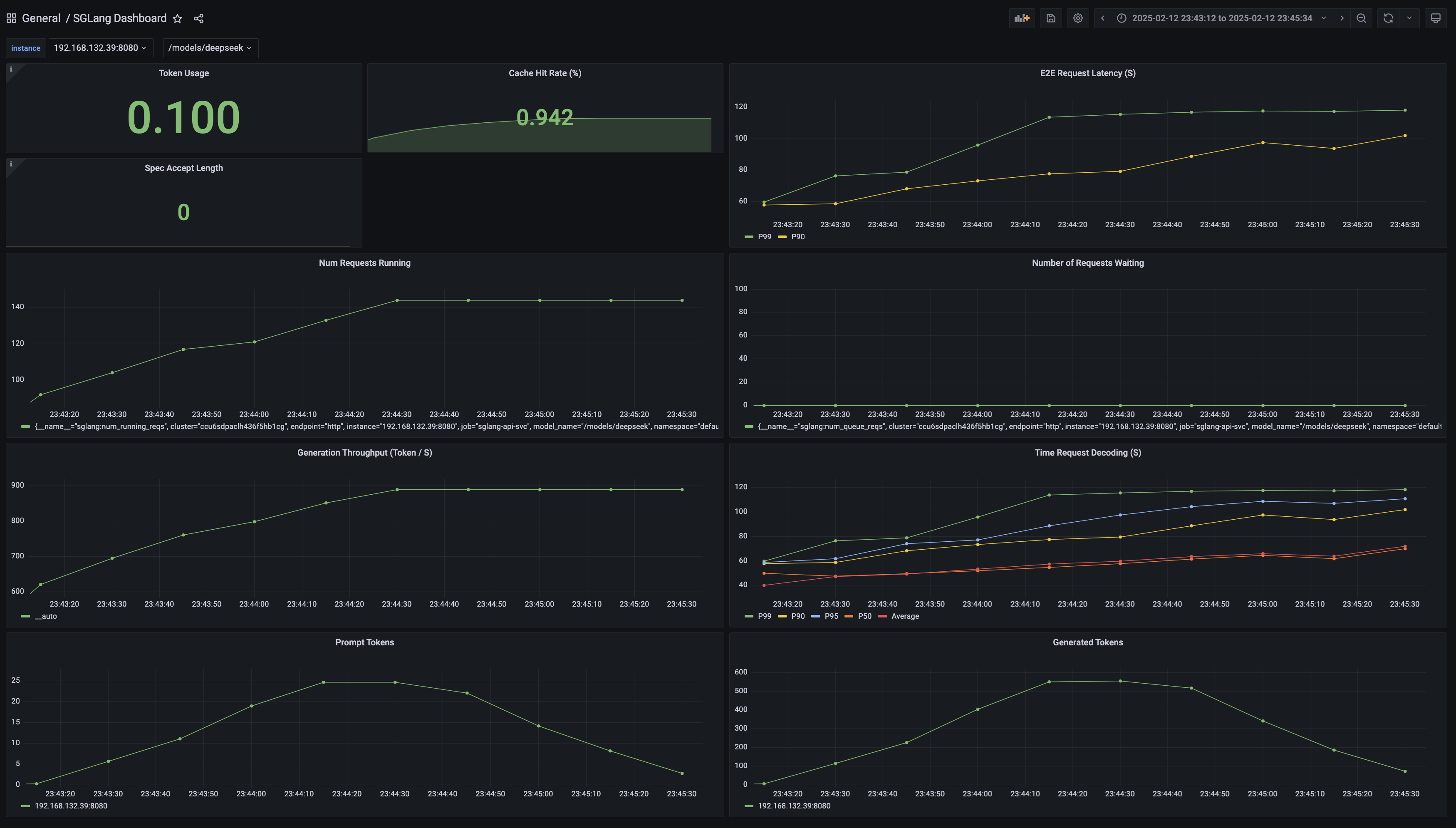
HPA 弹性扩展
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: sglang-hpa
spec:
minReplicas: 1
maxReplicas: 5
metrics:
- pods:
metric:
name: k8s_pod_gpu_prof_sm_active
target:
type: AverageValue
averageValue: "0.3" # 根据实际使用情况配置
type: Pods
scaleTargetRef:
apiVersion: http://leaderworkerset.x-k8s.io/v1
kind: LeaderWorkerSet
name: sglang
behavior:
scaleDown:
policies:
- periodSeconds: 300
type: Pods
value: 2
- periodSeconds: 300
type: Percent
value: 5
selectPolicy: Max
stabilizationWindowSeconds: 300
scaleUp:
policies:
- periodSeconds: 15
type: Pods
value: 2
- periodSeconds: 15
type: Percent
value: 15
selectPolicy: Max
stabilizationWindowSeconds: 0
kubectl apply -f sglang-hpa.yaml
模型加速

前置准备
操作步骤