| 名称 | 配置 | 链接 |
|---|---|---|
| R1基础模型 | DeepSeek-R1-Distill-Qwen-1.5B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B |
| 数据集 | nullskymc/ruozhiba_R1 | https://modelscope.cn/datasets/nullskymc/ruozhiba_R1 |
| 医疗数据集 | FreedomIntelligence/medical-o1-reasoning-SFT | https://modelscope.cn/search?search=FreedomIntelligence%2Fmedical-o1-reasoning-SFT |
| 名称 | 配置/版本 | 备注 |
|---|---|---|
| 操作系统 | Ubuntu 22.04.2 LTS | linux子系统需要win10/1的专业版 |
| 显卡 | RTX 4060 | |
| 内存 | 32G | |
| GPU | 8G | |
| python | 3.11 | |
| conda | 25.1.1 | |
| cuda | 12.4 | |
| CuDNN | 8.9.7 | |
| 镜像源 | 魔塔社区 |
一、系统安装
1.1. 查看wsl 可安装列表
wsl --list --online

1.2. 安装Ubuntu 22.04.2
wsl --install -d Ubuntu-22.04
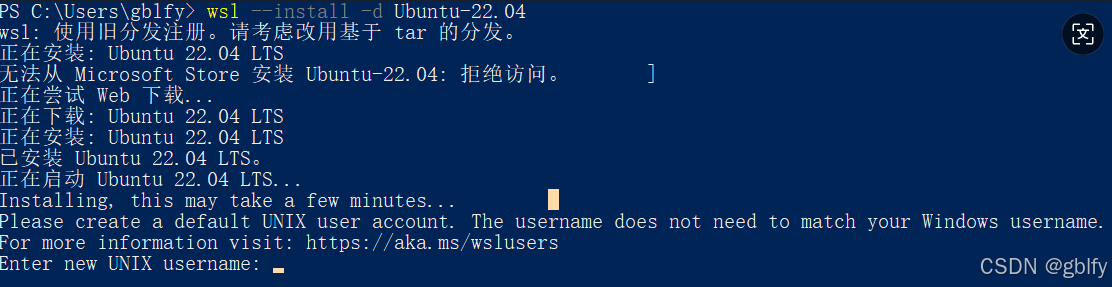
设置用户名和密码zhz/123456
1.3. 更新系统依赖
sudo apt update && sudo apt upgrade -y
1.4. 安装conda
以下方式任选其一:
- 方式1:单行执行
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh
suorce ~/.bashrc
- 方式2:整合执行
mkdir -p ~/miniconda3 && wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh && bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3 && rm -rf ~/miniconda3/miniconda.sh && ~/miniconda3/bin/conda init bash && suorce ~/.bashrc
suorce ~/.bashrc
conda -V
conda 25.1.1
conda create -n unsloth jupyterlab python=3.11 -y&conda activate unsloth
conda install -c conda-forge jupyterlab-lsp python-lsp-server
pip install jupyterlab-language-pack-zh-CN
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
cd unsloth
pip install unsloth vllm && pip install --upgrade pillow
conda activate unsloth
conda activate unsloth
cd unsloth
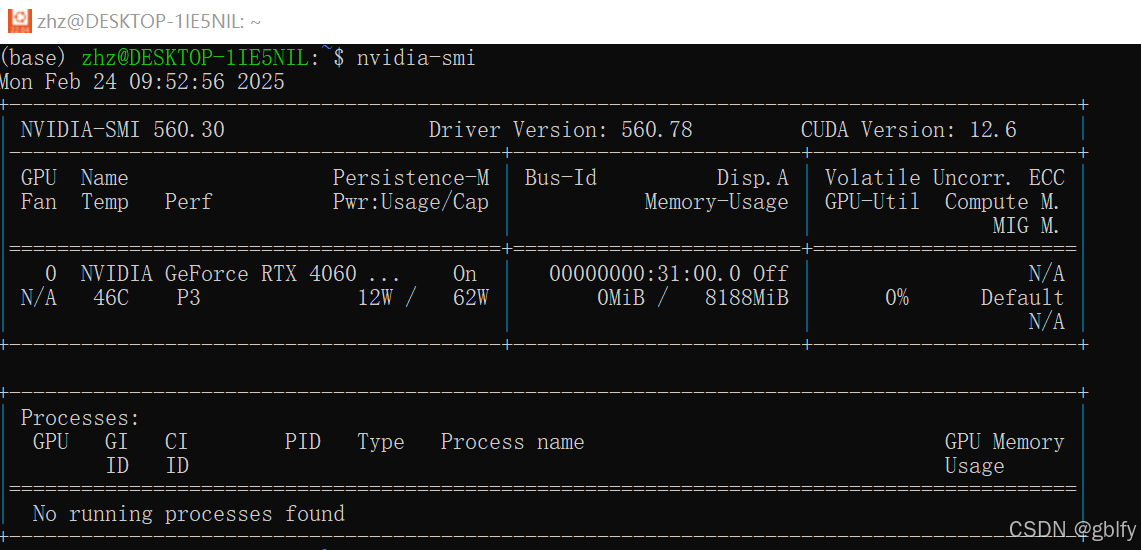
nvidia-smi
1.5. 安装cuda
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
CuDNN下载地址:
https://developer.nvidia.com/downloads/compute/cudnn/secure/8.9.7/local_installers/12.x/cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
复制到/home/zhz目录下
sudo tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
sudo sh cuda_12.4.0_550.54.14_linux.run
sudo apt update
sudo apt install gcc-11 g++-11
sudo sh cuda_12.4.0_550.54.14_linux.run
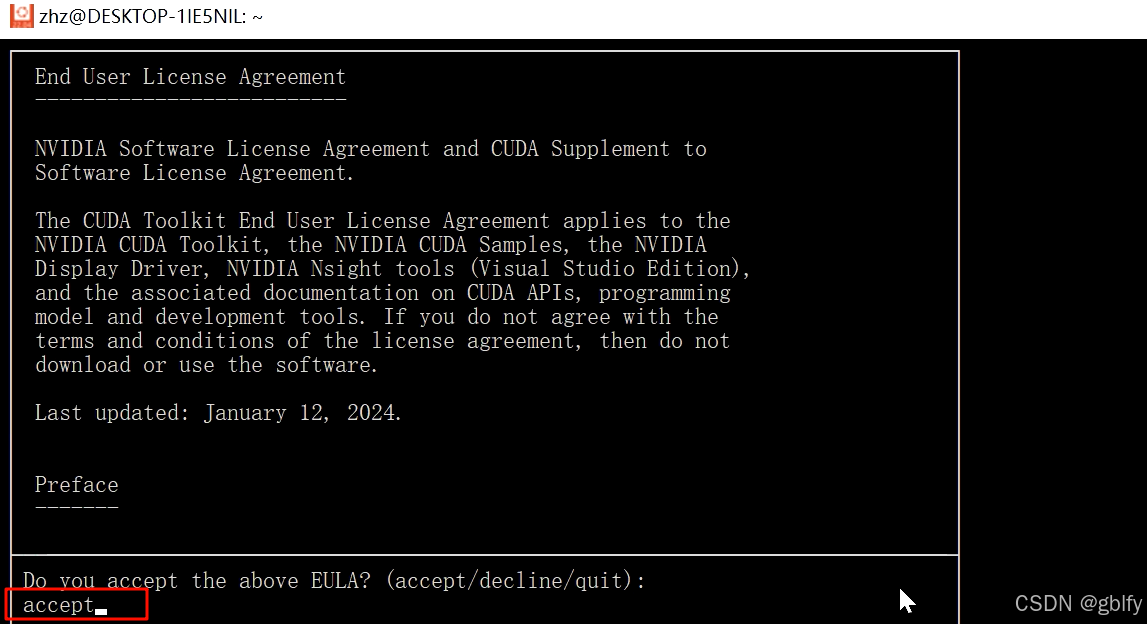
默认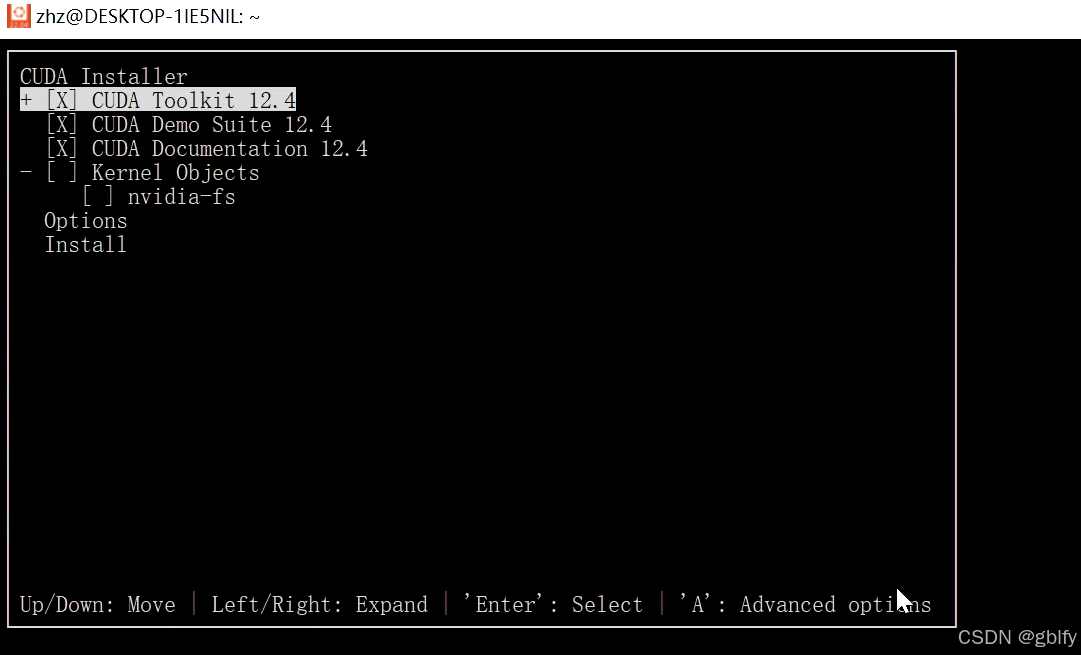
修改后
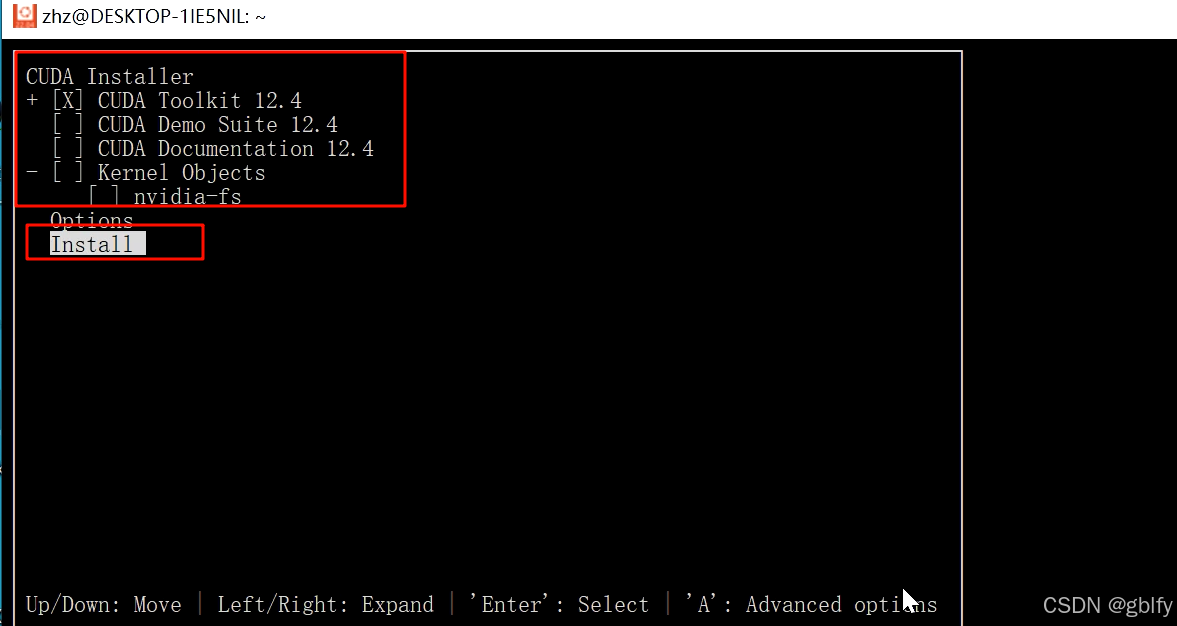
加入环境变量
nano ~/.bashrc
export PATH=/usr/local/cuda-12.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
source ~/.bashrc
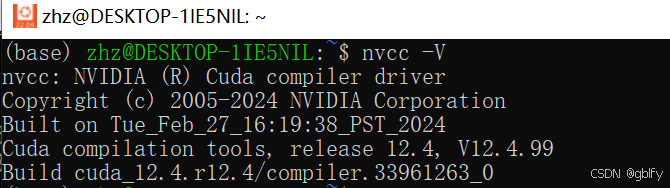
nvcc -V
sudo cp /home/zhz/cudnn-linux-x86_64-8.9.7.29_cuda12-archive/lib/* /usr/local/cuda-12.4/lib64/
cuda12.4版本安装
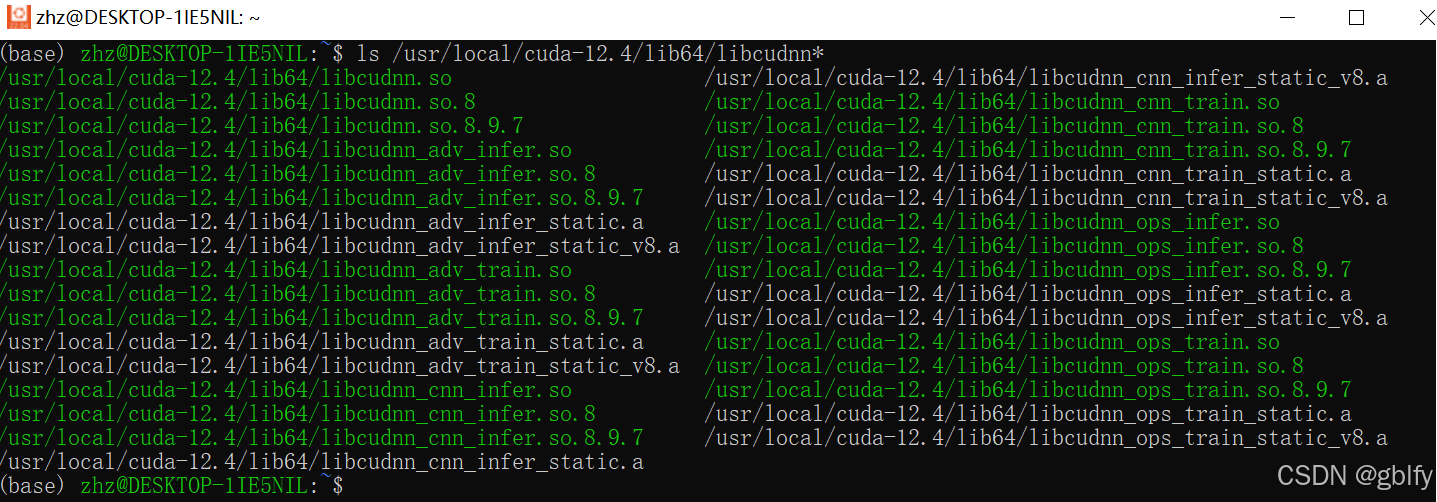
ls /usr/local/cuda-12.4/lib64/libcudnn* # 验证是否CP成功
sudo cp /home/zhz/cudnn-linux-x86_64-8.9.7.29_cuda12-archive/include/* /usr/local/cuda-12.4/include
cat /usr/local/cuda-12.4/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

sudo rm -rf cudnnlinux-x86_64-8.9.7.29_cudal2-archive.tar.xz
sudo rm -rf cudnn iinux-x86 64-8.9.7.29 cudal2-archive
sudo rm -rf cuda_12.4.0_550.54.14_linux.run cudnn-linux-x86_64-8.9.7.29_cudal2-archive.tar.xz:Zone.Identifier
conda activate unsloth
cd unsloth
conda install ipykernel -y
python -m ipykernel install --user --name=unsloth
pip install vllm
pip install --upgrade pillow
jupyter lab
接下来就是训练了。
模型下载
git lfs install
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git
千问模型(暂时没有用到,后续会用到)
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen2.5-3B-Instruct.git
数据集下载
git lfs install
git clone https://www.modelscope.cn/datasets/nullskymc/ruozhiba_R1.git
医疗数据集(暂时没有用到,后续会用到)
git lfs install
git clone https://www.modelscope.cn/datasets/FreedomIntelligence/medical-o1-reasoning-SFT.git
二、jupyter lab 服务启动
2.1. 激活 unsloth 环境
conda activate unsloth
2.2. 启动jupyter lab 服务
cd unsloth
jupyter lab

2.3. 进行jupyter lab 控台
访问浏览器,根据自己的实际情况
http://localhost:8888/lab?token=43c0043ce4726eac3928f3056d969f6cc4809d1fb2ac79d3
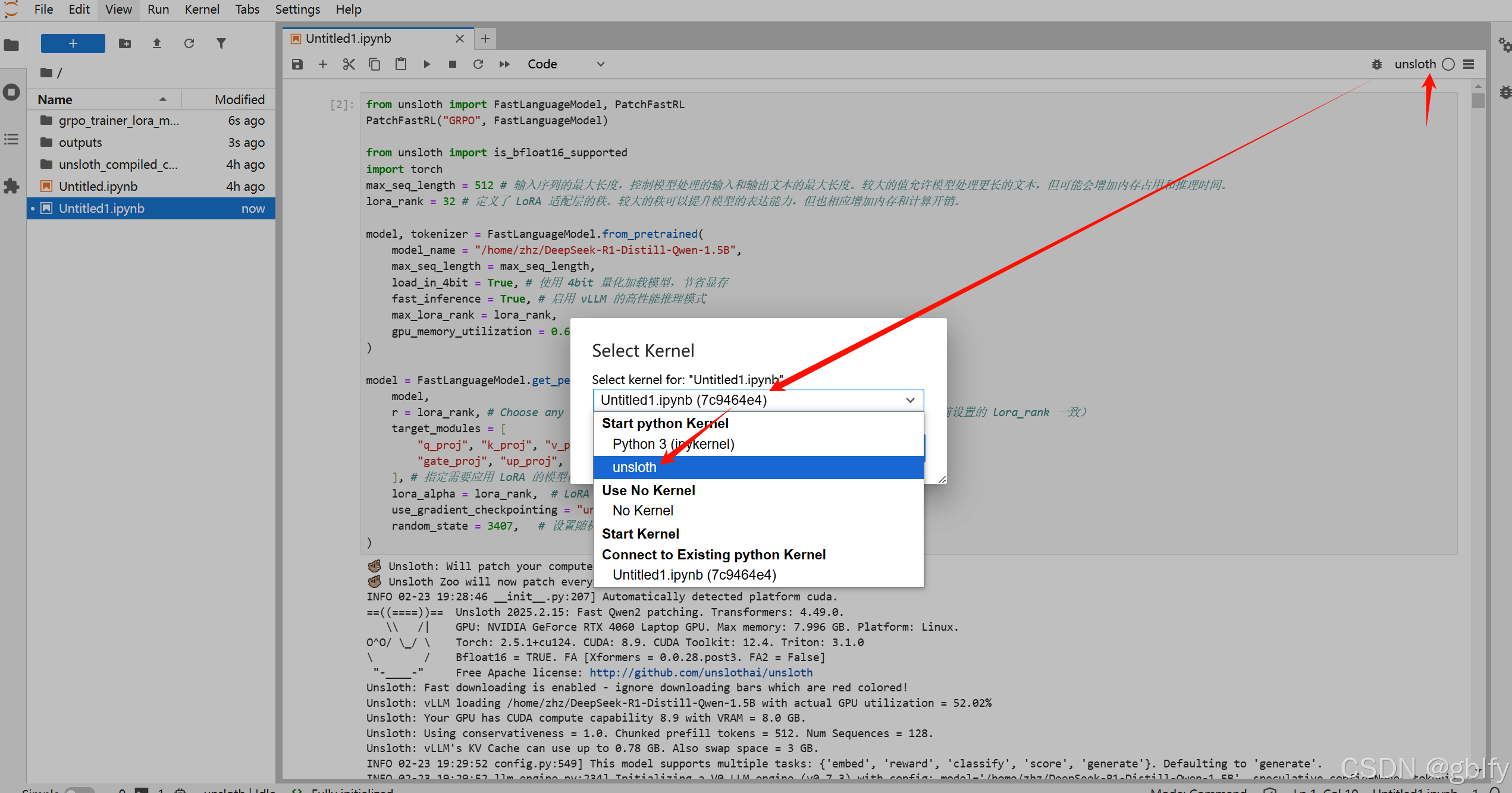
三、DeepSeek R1 微调训练
3.1. Unsloth 安装模型配置
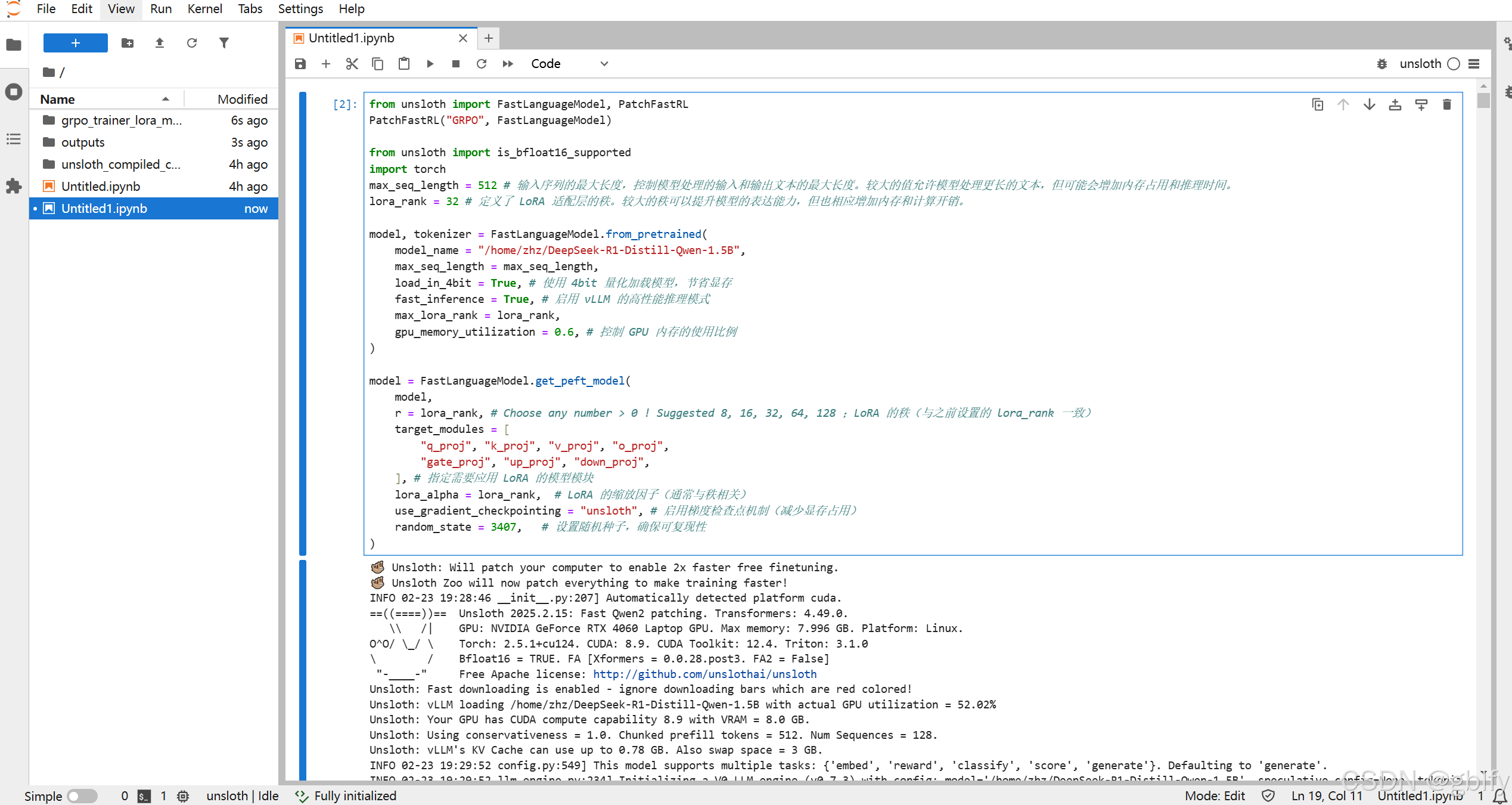
# 步骤一:使用深度学习框架和相关库来加载、配置和优化一个预训练语言模型,并为其添加低秩近似(LoRA)适配层,以实现高效的文本生成和推理任务
# 总结:
# 这段代码的核心目的在于:加载和配置预训练模型:使用 4bit 量化加载大型语言模型(如 Qwen 2.5-3B),减少显存占用。
# 启用 vLLM 的高性能推理模式,加速文本生成。添加 LoRA 适配层:通过 LoRA 方法微调模型,使其能够在特定任务上表现更好。
# 控制适配层的秩和缩放因子,平衡模型性能和资源占用。优化推理过程:启用梯度检查点机制,减少显存占用。
# 控制 GPU 内存使用比例,确保模型能够在硬件资源限制下稳定运行。最终,这段代码实现了一个高效、可扩展且资源优化的大语言模型部署方案。
# 这段代码的主要目的是通过 unsloth 库中的 PatchFastRL 函数,将 GRPO 补丁应用到 FastLanguageModel 类,以实现对语言模型的强化学习优化。
# 这通常用于提高模型在特定任务上的性能,例如对话生成、文本摘要等。
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
from unsloth import is_bfloat16_supported
import torch
max_seq_length = 512 # 输入序列的最大长度,控制模型处理的输入和输出文本的最大长度。较大的值允许模型处理更长的文本,但可能会增加内存占用和推理时间。
lora_rank = 32 # 定义了 LoRA 适配层的秩。较大的秩可以提升模型的表达能力,但也相应增加内存和计算开销。
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/home/zhz/DeepSeek-R1-Distill-Qwen-1.5B",
max_seq_length = max_seq_length,
load_in_4bit = True, # 使用 4bit 量化加载模型,节省显存
fast_inference = True, # 启用 vLLM 的高性能推理模式
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.6, # 控制 GPU 内存的使用比例
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128 ;LoRA 的秩(与之前设置的 lora_rank 一致)
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # 指定需要应用 LoRA 的模型模块
lora_alpha = lora_rank, # LoRA 的缩放因子(通常与秩相关)
use_gradient_checkpointing = "unsloth", # 启用梯度检查点机制(减少显存占用)
random_state = 3407, # 设置随机种子,确保可复现性
)

3.2. 数据集配置和加载
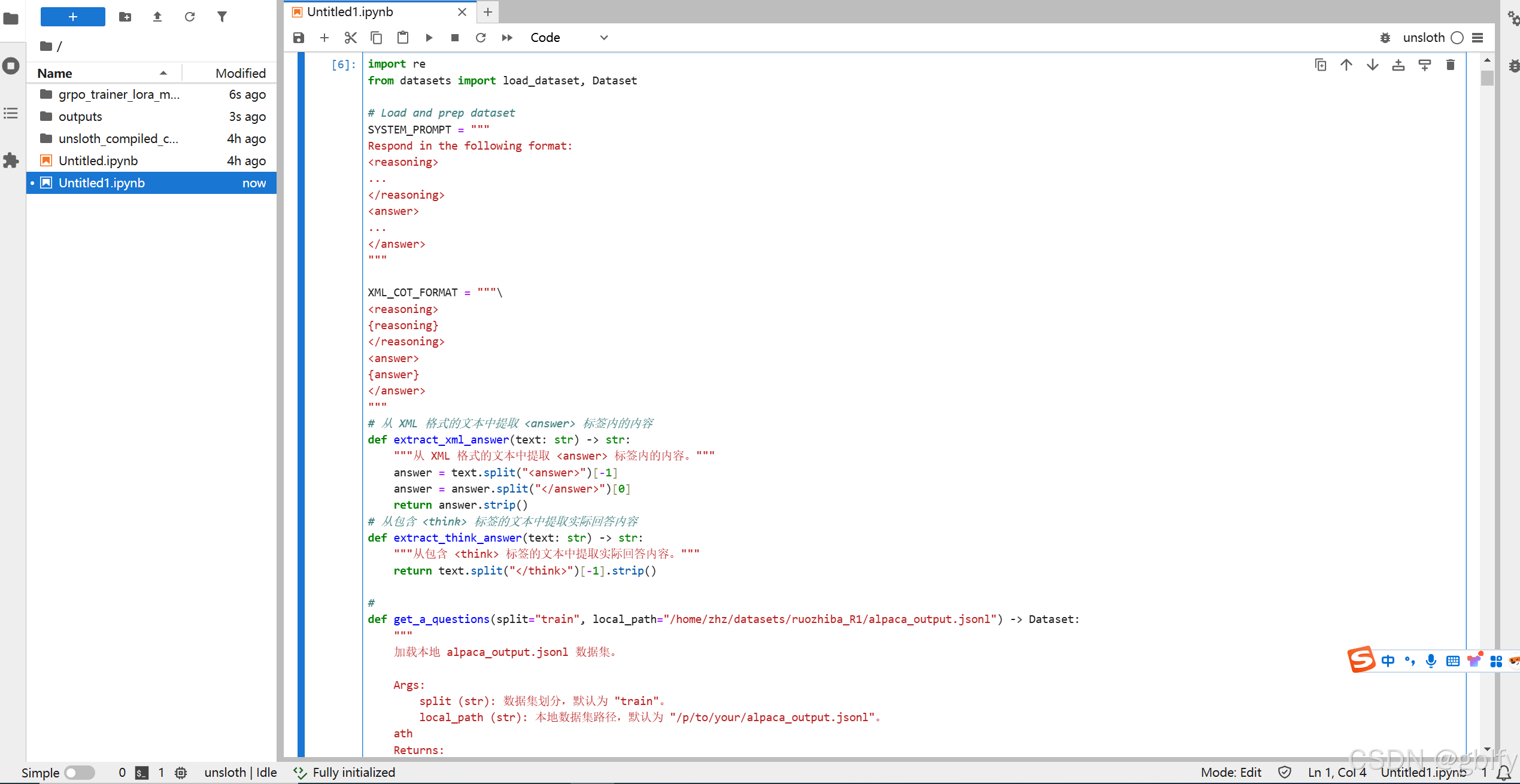
import re
from datasets import load_dataset, Dataset
# Load and prep dataset
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{
reasoning}
</reasoning>
<answer>
{
answer}
</answer>
"""
# 从 XML 格式的文本中提取 <answer> 标签内的内容
def extract_xml_answer(text: str) -> str:
"""从 XML 格式的文本中提取 <answer> 标签内的内容。"""
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
# 从包含 <think> 标签的文本中提取实际回答内容
def extract_think_answer(text: str) -> str:
"""从包含 <think> 标签的文本中提取实际回答内容。"""
return text.split("</think>")[-1].strip()
#
def get_a_questions(split="train", local_path="/home/zhz/datasets/ruozhiba_R1/alpaca_output.jsonl") -> Dataset:
"""
加载本地 alpaca_output.jsonl 数据集。
Args:
split (str): 数据集划分,默认为 "train"。
local_path (str): 本地数据集路径,默认为 "/p/to/your/alpaca_output.jsonl"。
ath
Returns:
Dataset: 处理后的数据集。
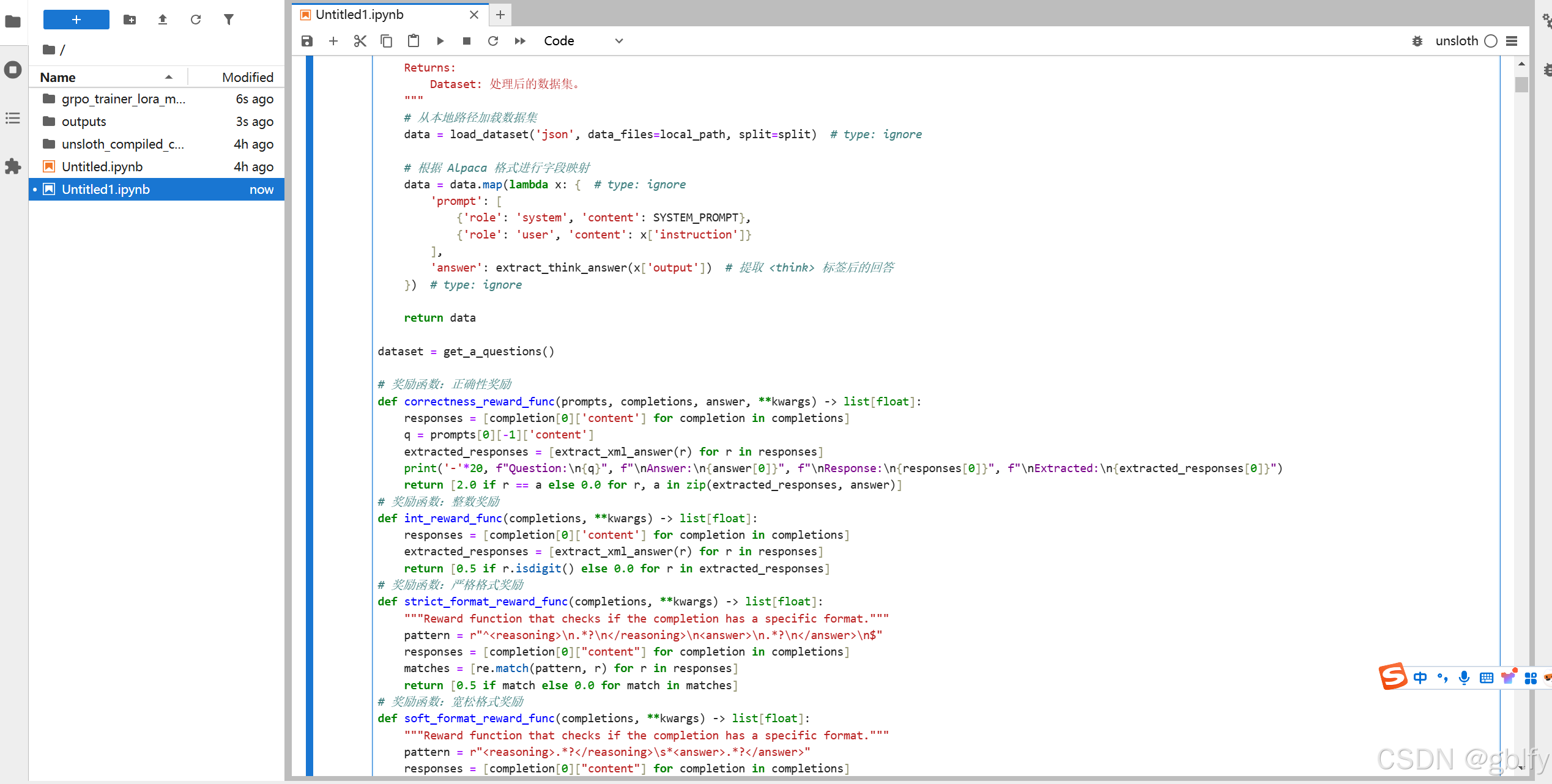
"""
# 从本地路径加载数据集
data = load_dataset('json', data_files=local_path, split=split) # type: ignore
# 根据 Alpaca 格式进行字段映射
data = data.map(lambda x: {
# type: ignore
'prompt': [
{
'role': 'system', 'content': SYSTEM_PROMPT},
{
'role': 'user', 'content': x['instruction']}
],
'answer': extract_think_answer(x['output']) # 提取 <think> 标签后的回答
}) # type: ignore
return data
dataset = get_a_questions()
# 奖励函数:正确性奖励
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
# 奖励函数:整数奖励
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
# 奖励函数:严格格式奖励
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
# 奖励函数:宽松格式奖励
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
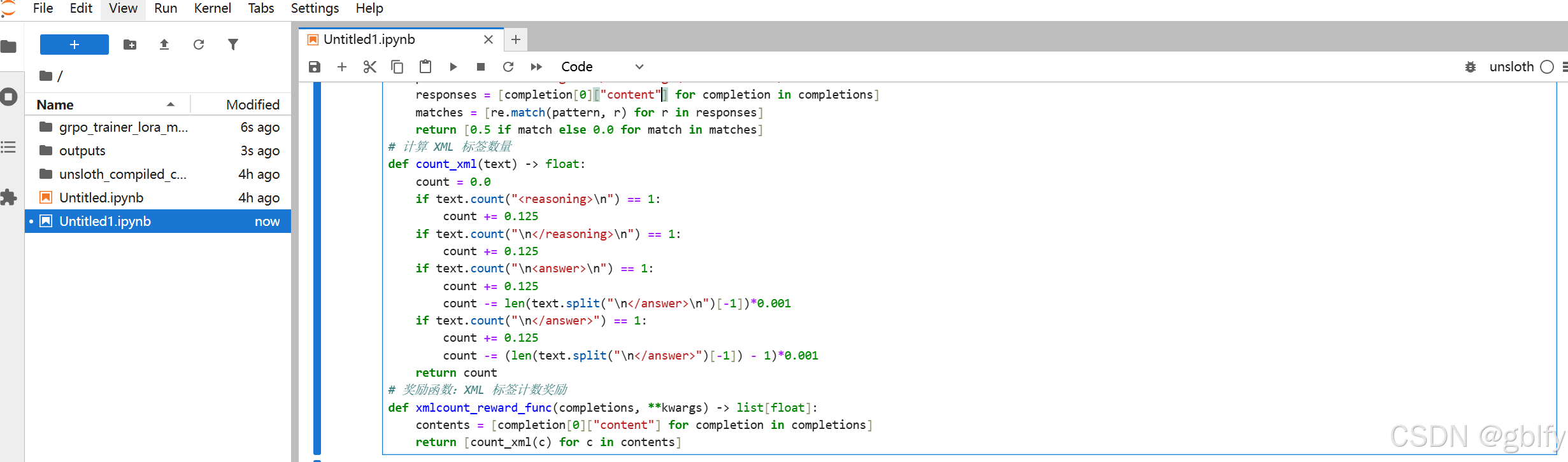
# 计算 XML 标签数量
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
# 奖励函数:XML 标签计数奖励
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
3.3. 配置 GRPO 训练参数
from trl import GRPOConfig, GRPOTrainer
# 配置 GRPO 训练参数
training_args = GRPOConfig(
use_vllm=True, # 使用 vLLM 进行快速推理
learning_rate=5e-6, # 学习率
adam_beta1=0.9, # Adam 优化器的 beta1 参数
adam_beta2=0.99, # Adam 优化器的 beta2 参数
weight_decay=0.1, # 权重衰减
warmup_ratio=0.1, # 学习率预热比例
lr_scheduler_type="cosine", # 学习率调度器类型
optim="paged_adamw_8bit", # 优化器类型
logging_steps=1, # 日志记录步数
bf16=is_bfloat16_supported(), # 是否支持 bfloat16
fp16=not is_bfloat16_supported(), # 是否支持 fp16
per_device_train_batch_size=1, # 每个设备的训练批量大小,根据 GPU 内存调整
gradient_accumulation_steps=1, # 梯度累积步数,根据 GPU 内存调整
num_generations=6, # 生成数量,根据 GPU 内存调整
max_prompt_length=256, # 最大提示长度
max_completion_length=200, # 最大完成长度
max_steps=300, # 最大训练步数
save_steps=300, # 保存步数
max_grad_norm=0.1, # 最大梯度范数
report_to="none", # 日志报告目标,可以使用 Weights & Biases
output_dir="outputs", # 输出目录
)
3.4. GRPOTrainer配置和加载
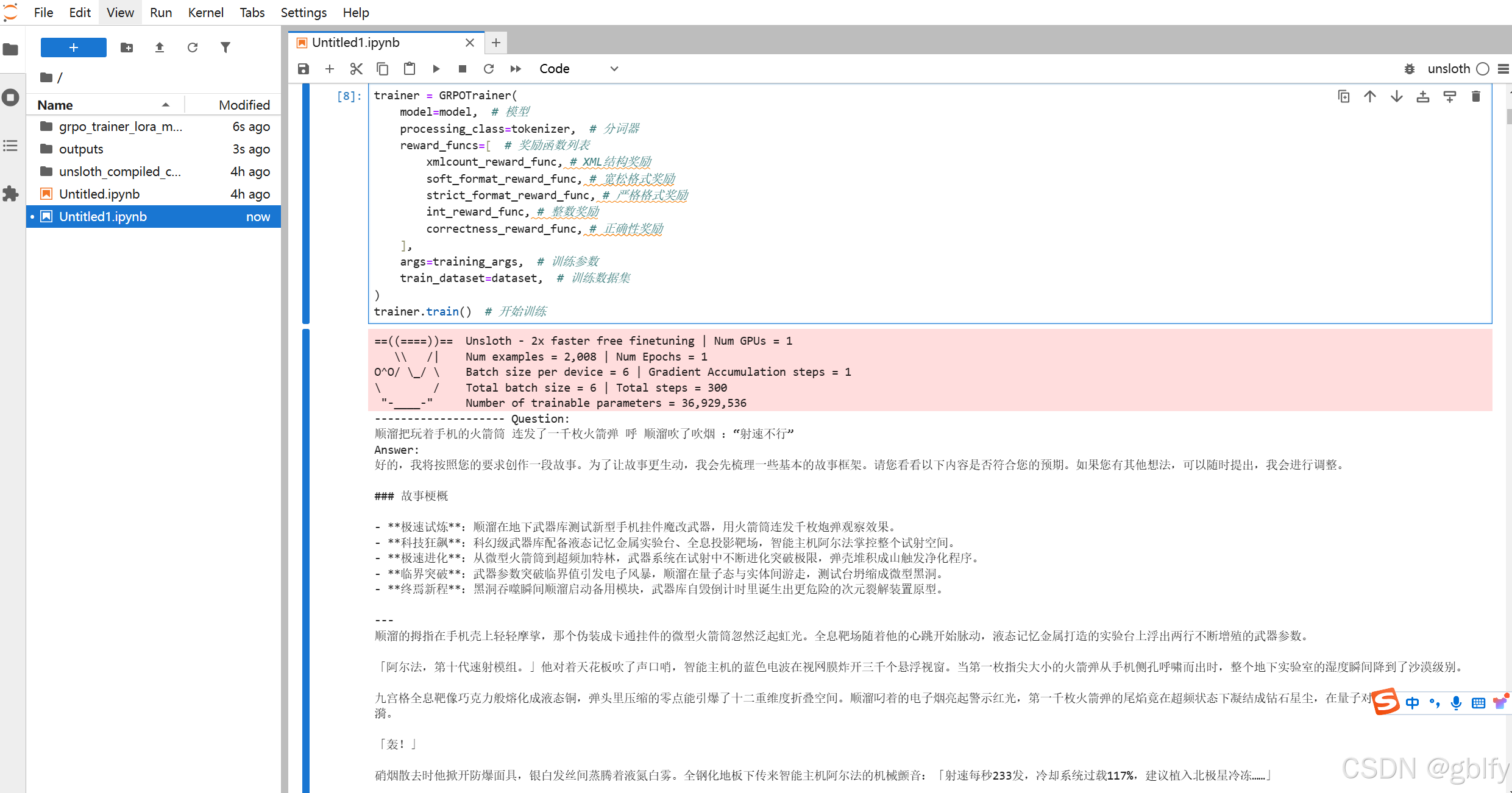
trainer = GRPOTrainer(
model=model, # 模型
processing_class=tokenizer, # 分词器
reward_funcs=[ # 奖励函数列表
xmlcount_reward_func, # XML结构奖励
soft_format_reward_func, # 宽松格式奖励
strict_format_reward_func, # 严格格式奖励
int_reward_func, # 整数奖励
correctness_reward_func, # 正确性奖励
],
args=training_args, # 训练参数
train_dataset=dataset, # 训练数据集
)
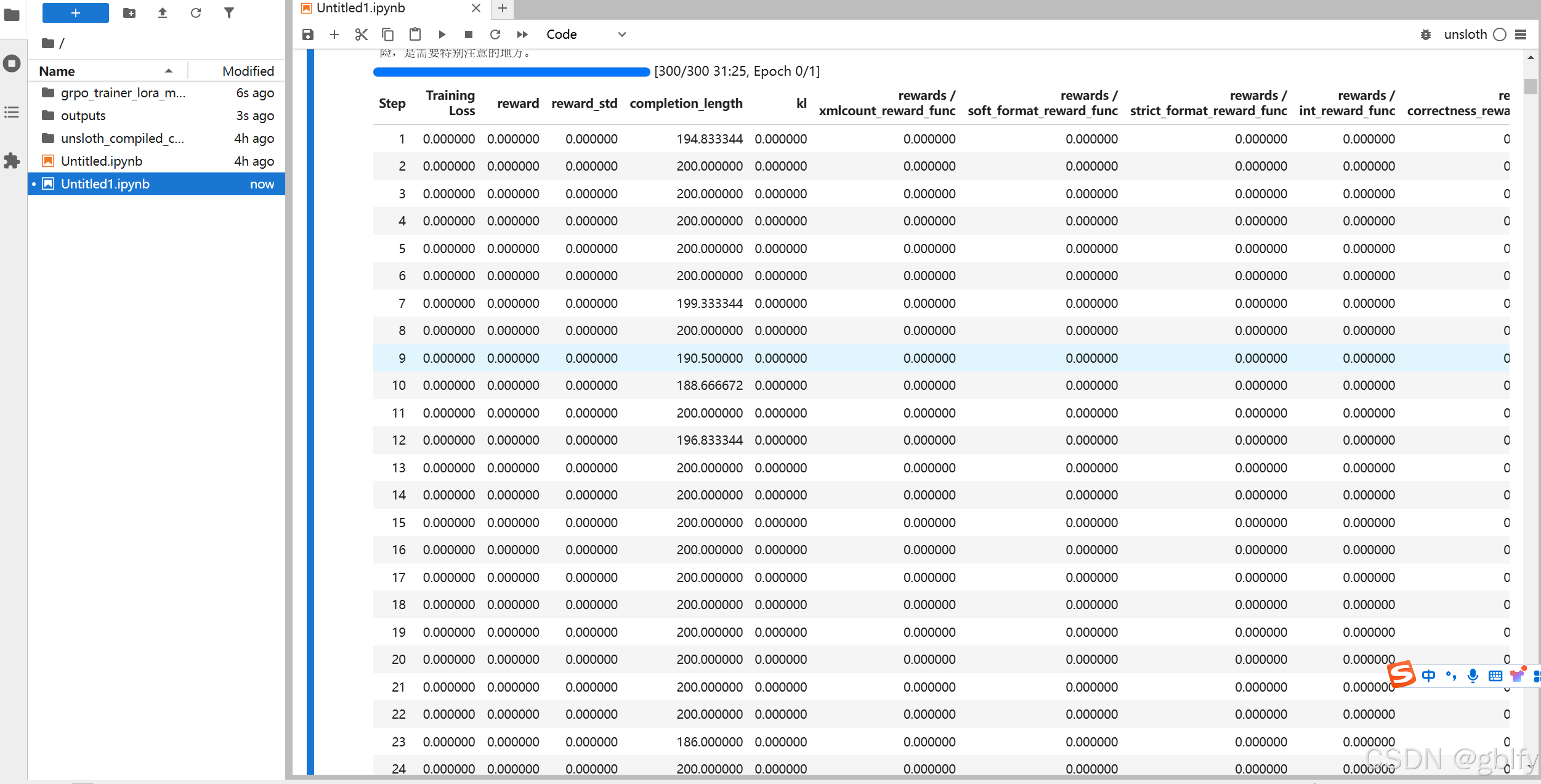
trainer.train() # 开始训练
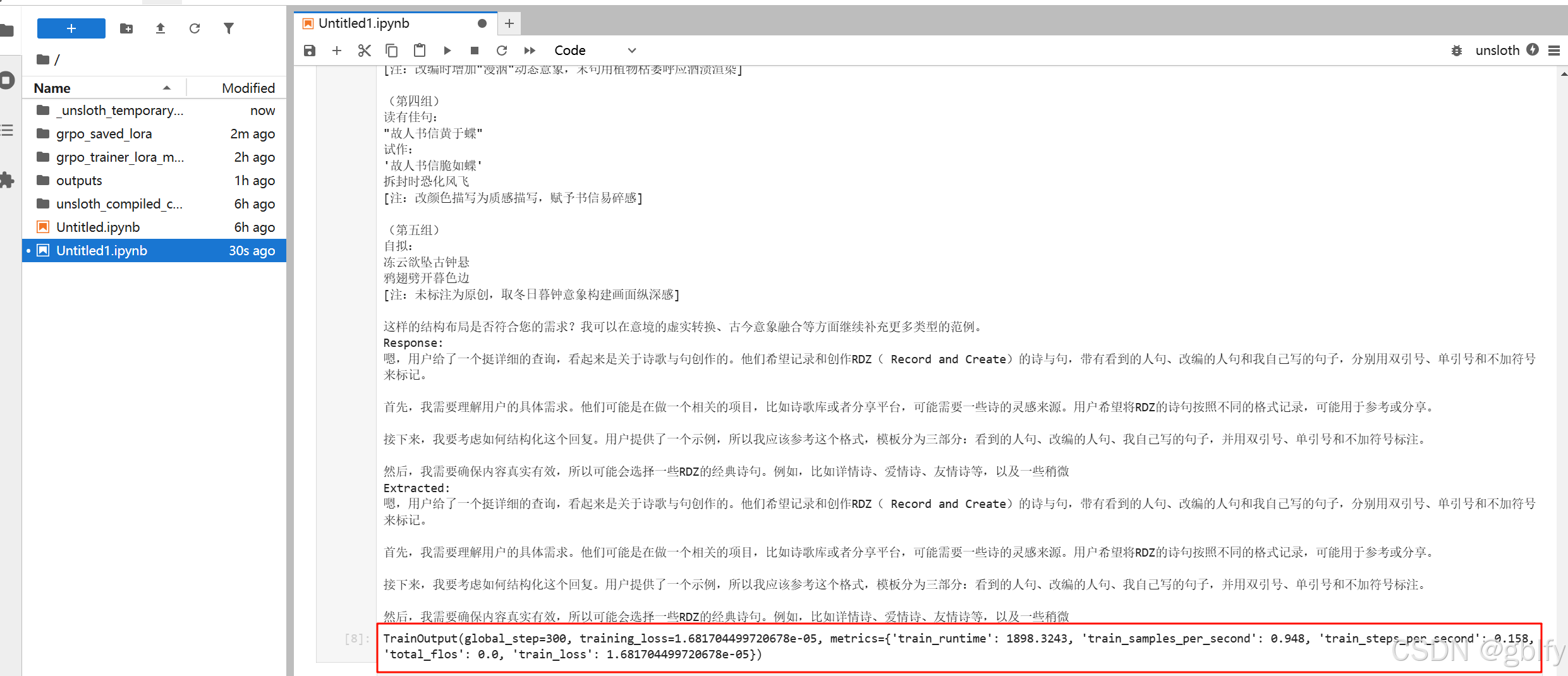
3.5. 文本生成任务实现流程
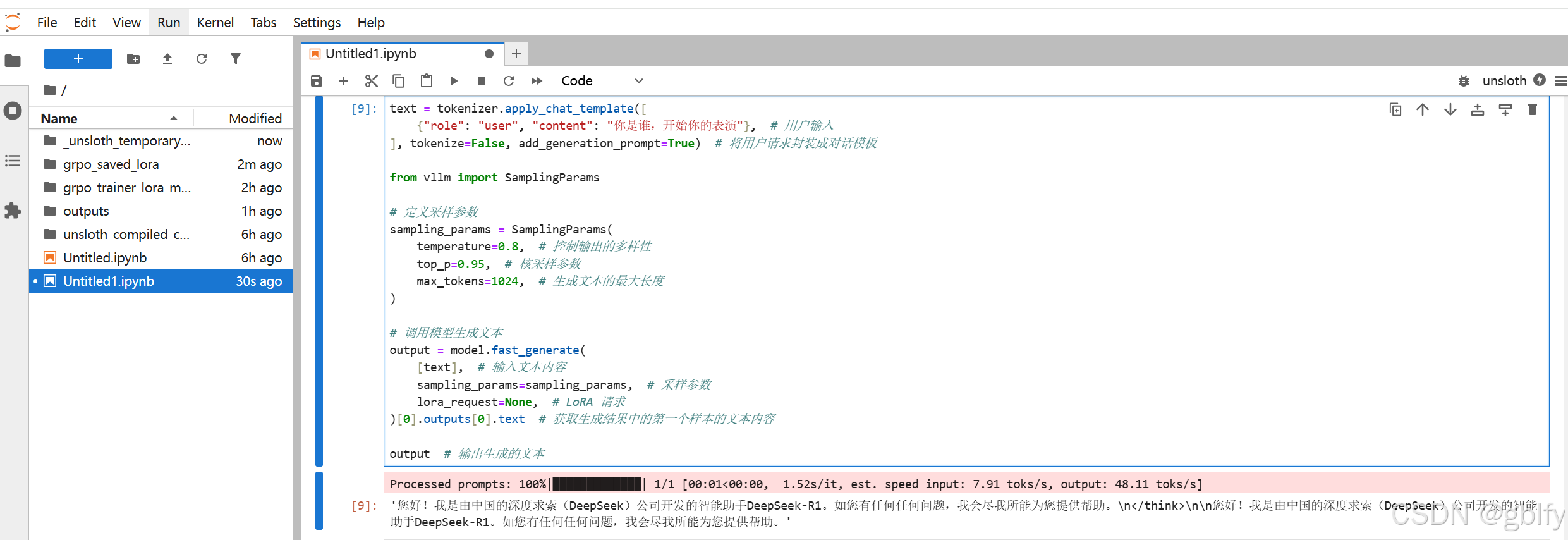
# 用户请求: 用户提供一段文字作为输入
text = tokenizer.apply_chat_template([
{
"role": "user", "content": "你是谁,开始你的表演"}, # 用户输入
], tokenize=False, add_generation_prompt=True) # 将用户请求封装成对话模板
from vllm import SamplingParams
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.8, # 控制输出的多样性
top_p=0.95, # 核采样参数
max_tokens=1024, # 生成文本的最大长度
)
# 调用模型生成文本
output = model.fast_generate(
[text], # 输入文本内容
sampling_params=sampling_params, # 采样参数
lora_request=None, # LoRA 请求
)[0].outputs[0].text # 获取生成结果中的第一个样本的文本内容
output # 输出生成的文本
3.6. 保存 LoRA 权重

model.save_lora("grpo_saved_lora")
3.7. 加载 LoRA 权重并进行推理
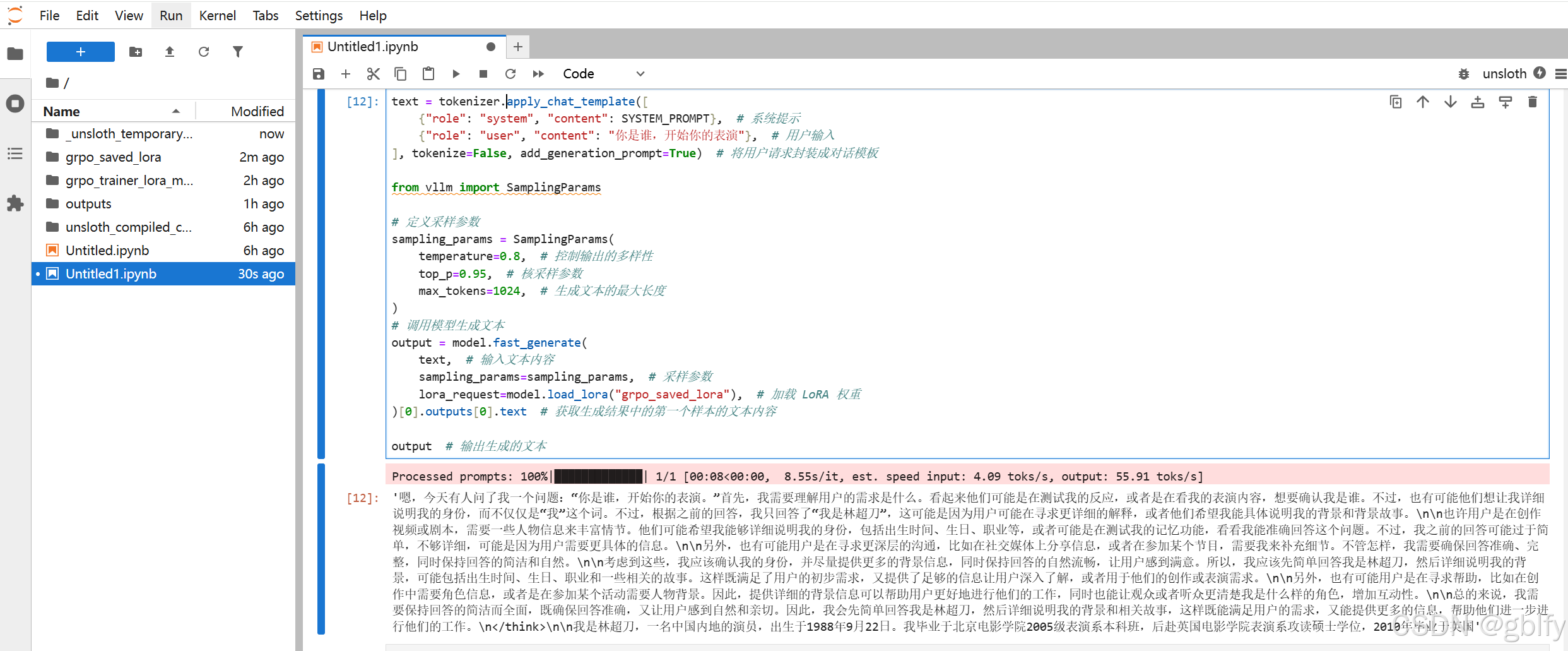
# 加载之前保存的 LoRA 权重(通过 "grpo_saved_lora")
# 使用这些权重和配置的参数生成回答
# 返回生成的文本结果
text = tokenizer.apply_chat_template([
{
"role": "system", "content": SYSTEM_PROMPT}, # 系统提示
{
"role": "user", "content": "你是谁,开始你的表演"}, # 用户输入
], tokenize=False, add_generation_prompt=True) # 将用户请求封装成对话模板
from vllm import SamplingParams
# 定义采样参数
sampling_params = SamplingParams(
temperature=0.8, # 控制输出的多样性
top_p=0.95, # 核采样参数
max_tokens=1024, # 生成文本的最大长度
)
# 调用模型生成文本
output = model.fast_generate(
text, # 输入文本内容
sampling_params=sampling_params, # 采样参数
lora_request=model.load_lora("grpo_saved_lora"), # 加载 LoRA 权重
)[0].outputs[0].text # 获取生成结果中的第一个样本的文本内容
output # 输出生成的文本
3.8. 合并为 16bit 格式
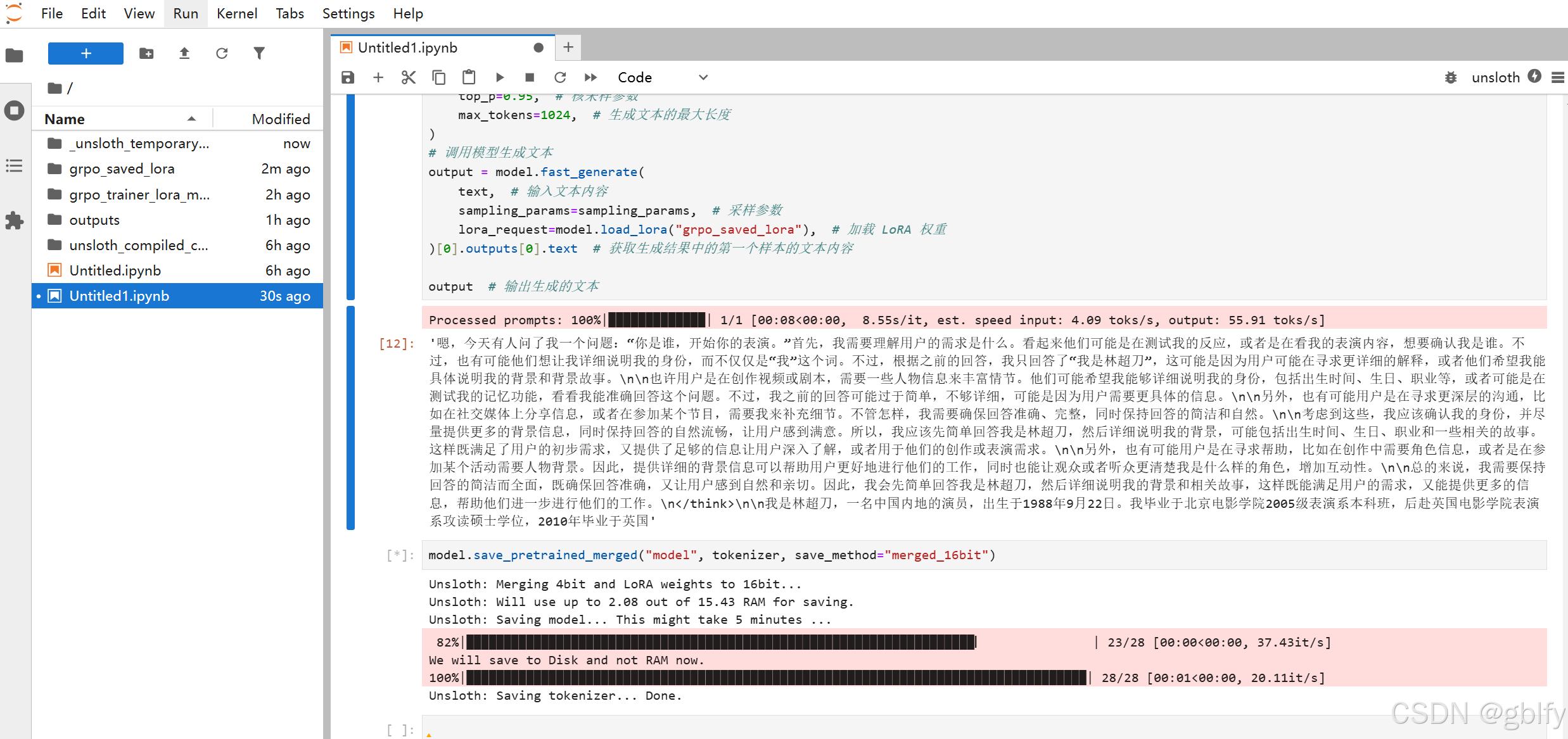
model.save_pretrained_merged("model", tokenizer, save_method="merged_16bit")