文章目录
| PyTorch | 2.1.2 | ||
|---|---|---|---|
| Python | 3.10(ubuntu22.04) | ||
| Cuda | 11.8 | ||
| GPU | RTX 4090(24GB) * 1 | ||
| CPU | 16 vCPU Intel® Xeon® Gold 6430 | ||
| 内存 | 120GB | ||
| 系统盘 | 30 GB | ||
| 数据盘 | 免费:50GB | ||
| 计费方式 | 按量计费 |
一、模型微淘
1. 搭建训练环境
- 在云平台上租用一个实例(如 AutoDL,官网:https://www.autodl.com/market/list)

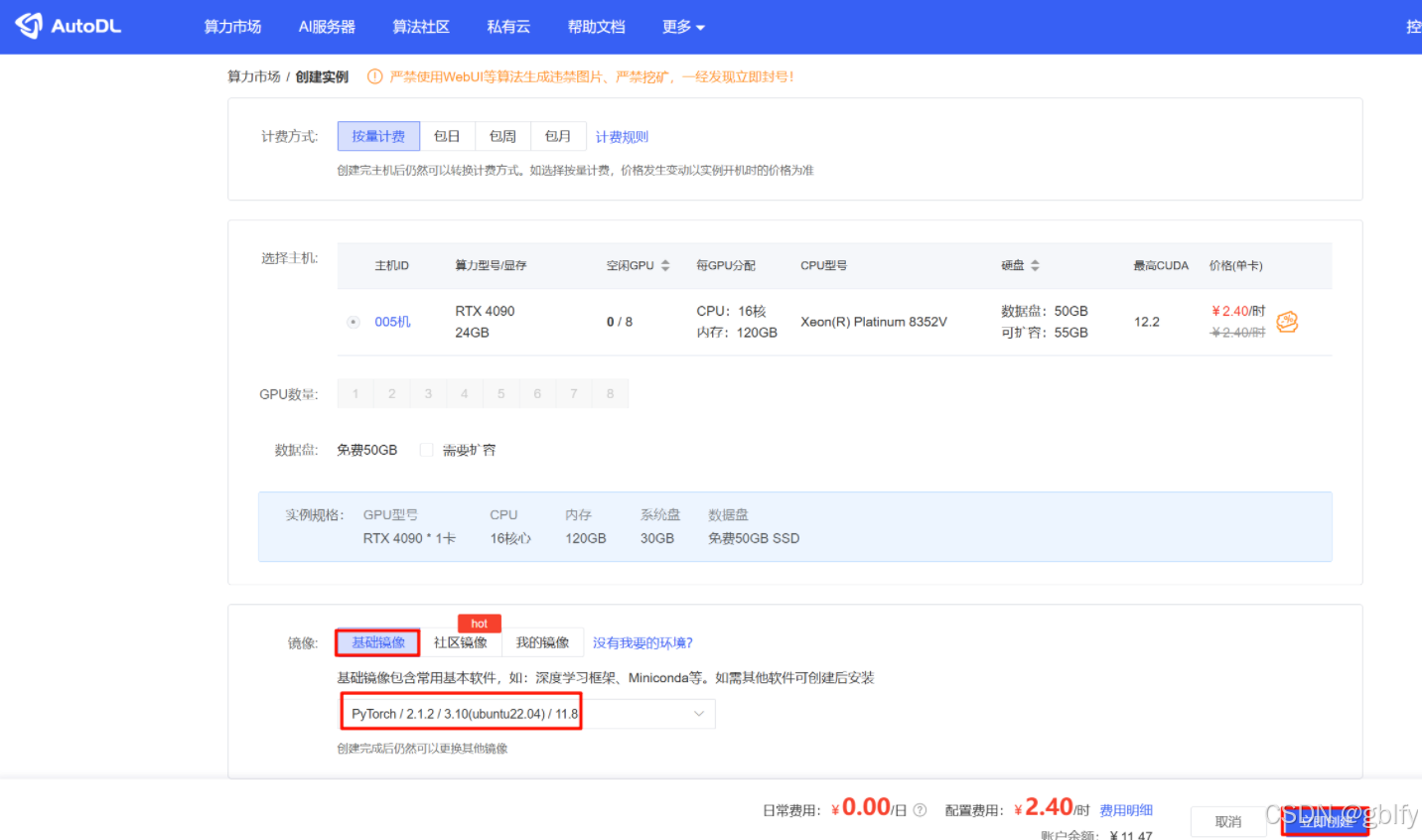
- 云平台一般会配置好常用的深度学习环境,如 anaconda, cuda等等
2. SSH 连接
ssh -p 36131 root@connect.bjb1.seetacloud.com
S1U6UAFHzaLX
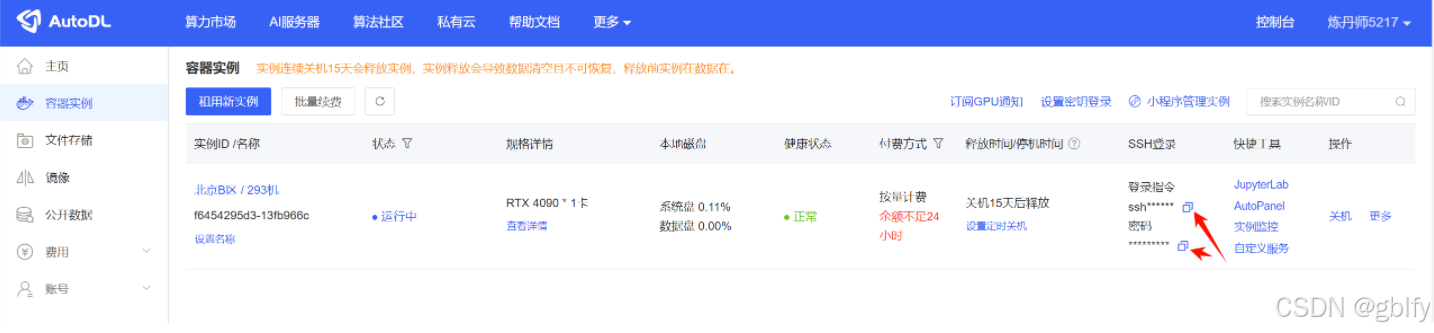
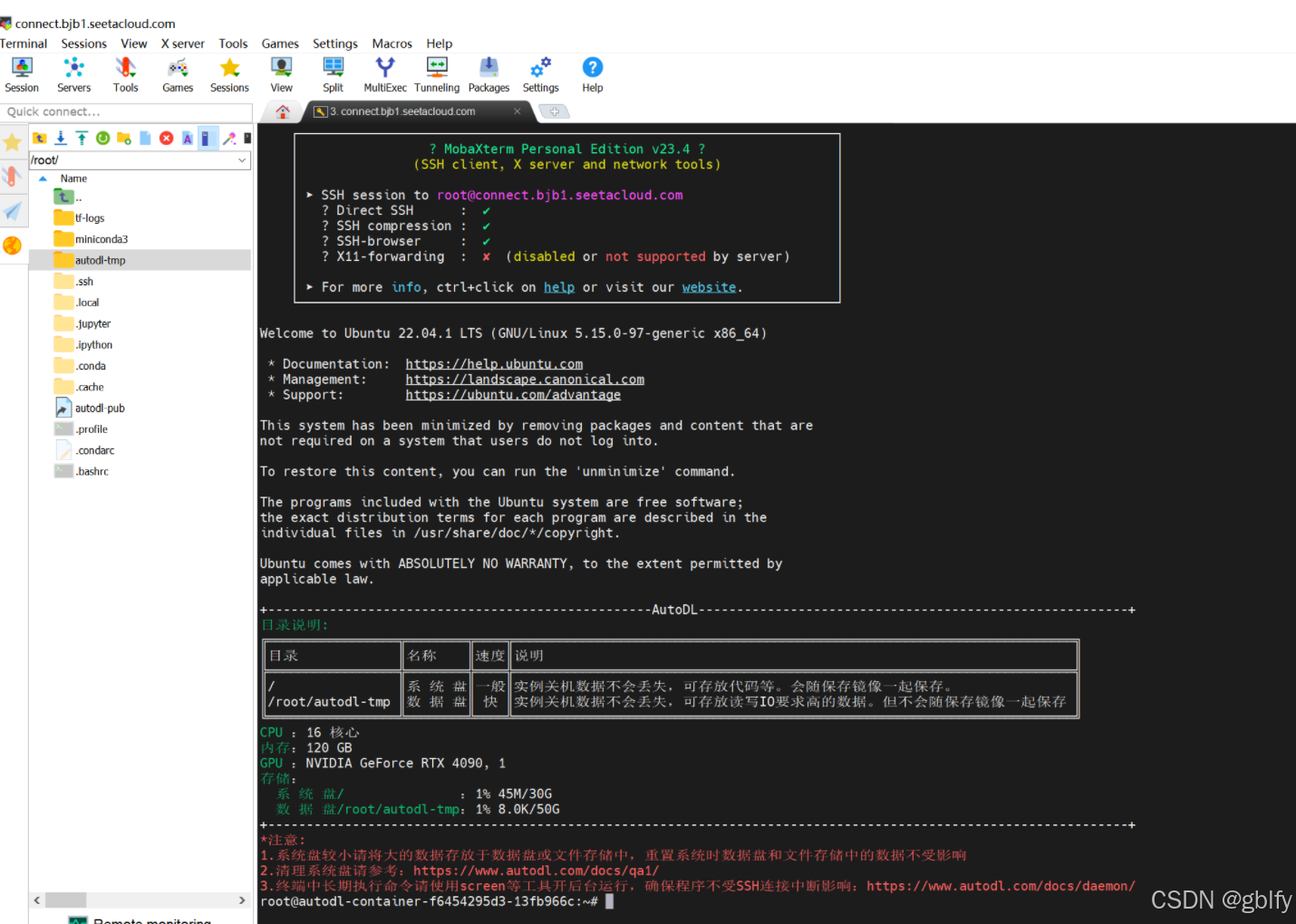
- 使用 MobaXterm SSH 连接到你租用的服务器,参考文档:
- 连接后打开个人数据盘文件夹 /root/autodl-tmp
cd /root/autodl-tmp
3. LLaMA-Factory 安装部署
LLaMA-Factory 的 Github地址:https://github.com/hiyouga/LLaMA-Factory
- 克隆仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git

如果下载慢,开启学术加速
source /etc/network_turbo
- 切换到项目目录
cd LLaMA-Factory
- 修改配置,将 conda 虚拟环境安装到数据盘(这一步也可不做)
mkdir -p /root/autodl-tmp/conda/pkgs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/conda/envs
conda config --add envs_dirs /root/autodl-tmp/conda/envs
- 创建 conda 虚拟环境(一定要 3.10 的 python 版本,不然和 LLaMA-Factory 不兼容)
conda create -n llama-factory python=3.10
选择 y,,等待安装依赖完成
- 初始化conda
conda init
新打开一个新窗口
- 激活虚拟环境
conda activate llama-factory
- 在虚拟环境中安装 LLaMA Factory 相关依赖
cd /root/autodl-tmp/LLaMA-Factory/
pip install -e ".[torch,metrics]"
注意:如报错 bash: pip: command not found ,先执行 conda install pip 即可
- 检验是否安装成功
llamafactory-cli version

4. 启动可视化微调界面
启动 LLama-Factory 的可视化微调界面 (由 Gradio 驱动)
llamafactory-cli webui
5. 配置端口转发
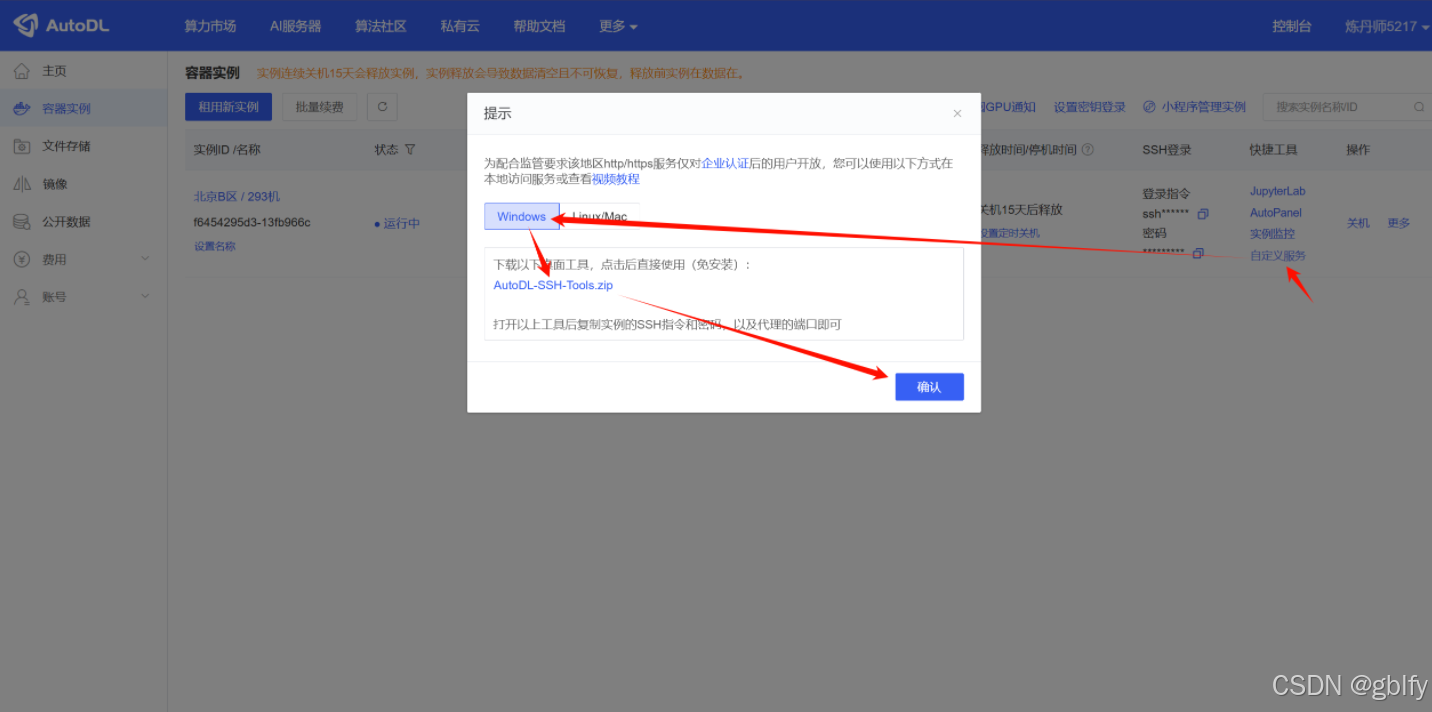
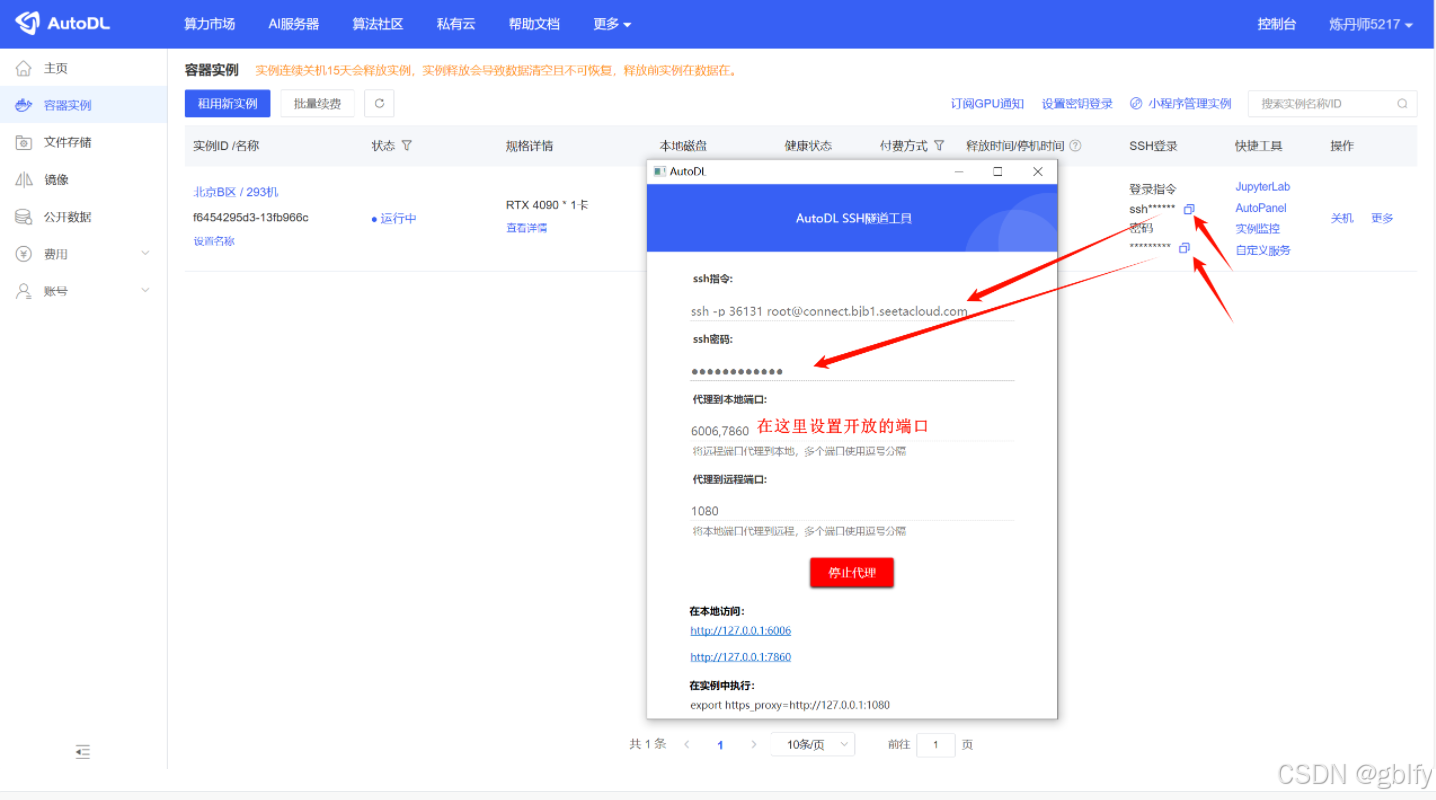
访问:http://localhost:7860/
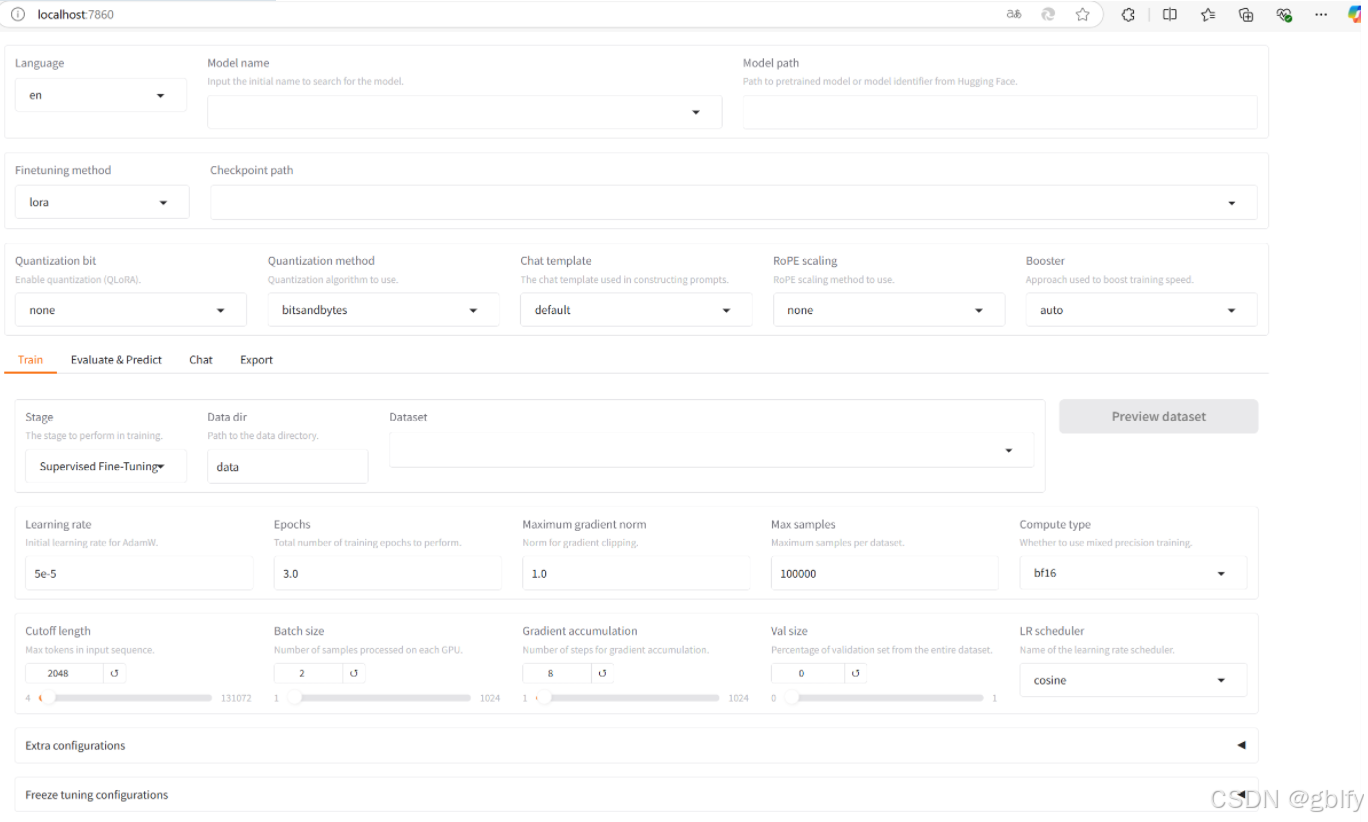
6. 下载基座模型
从 HuggingFace 上下载基座模型
HuggingFace 是一个集中管理和共享预训练模型的平台 https://huggingface.co;
从 HuggingFace 上下载模型有多种不同的方式,可以参考:如何快速下载huggingface模型——全方法总结
- 创建文件夹统一存放所有基座模型
cd autodl-tmp/
mkdir Hugging-Face
- 修改 HuggingFace 的镜像源
export HF_ENDPOINT=https://hf-mirror.com
- 修改模型下载的默认位置
export HF_HOME=/root/autodl-tmp/Hugging-Face
- 注意:这种配置方式只在当前 shell 会话中有效,如果你希望这个环境变量在每次启动终端时都生效,可以将其添加到你的用户配置文件中(修改
~/.bashrc或~/.zshrc) - 检查环境变量是否生效
echo $HF_ENDPOINT
echo $HF_HOME
- 安装 HuggingFace 官方下载工具
pip install -U huggingface_hub

- 执行下载命令
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
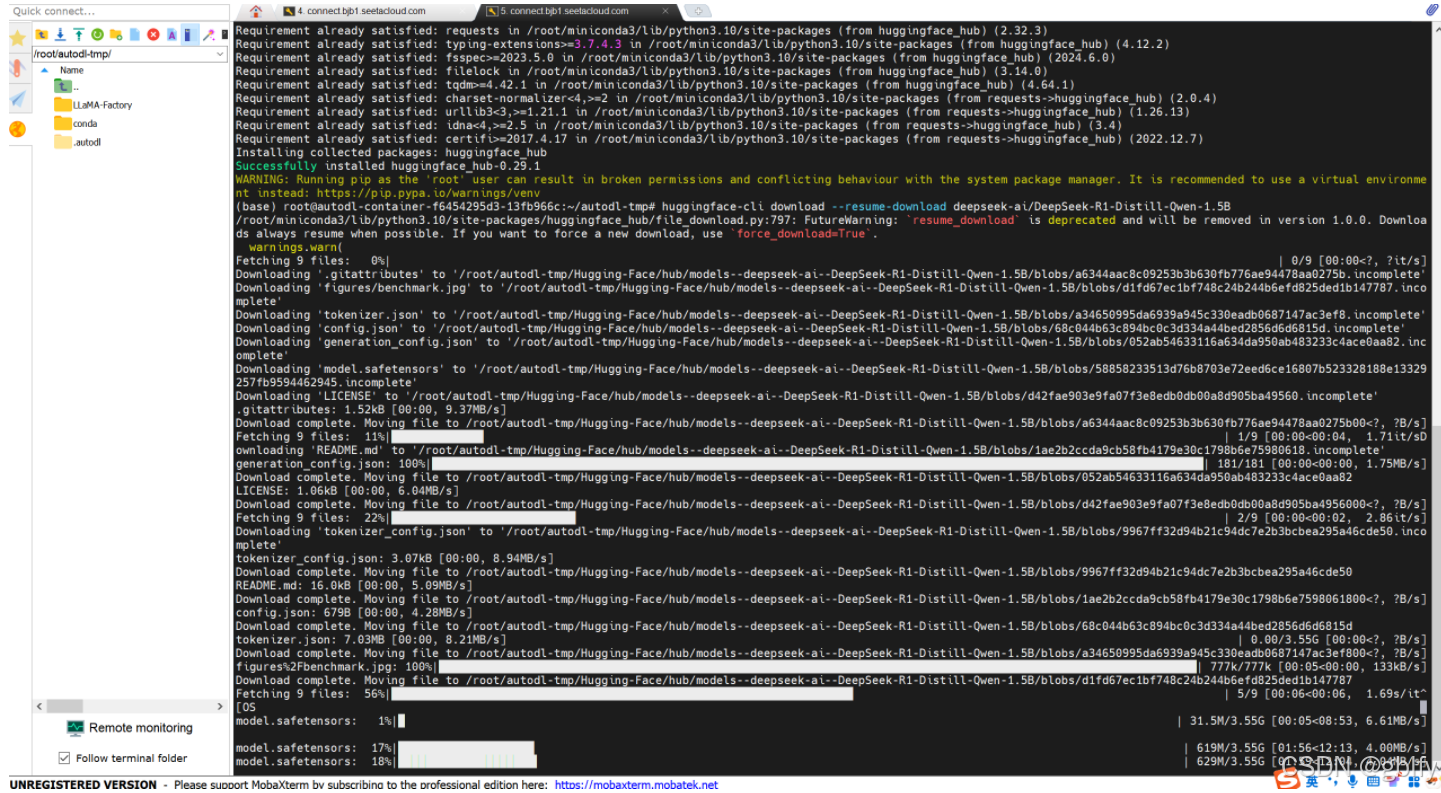
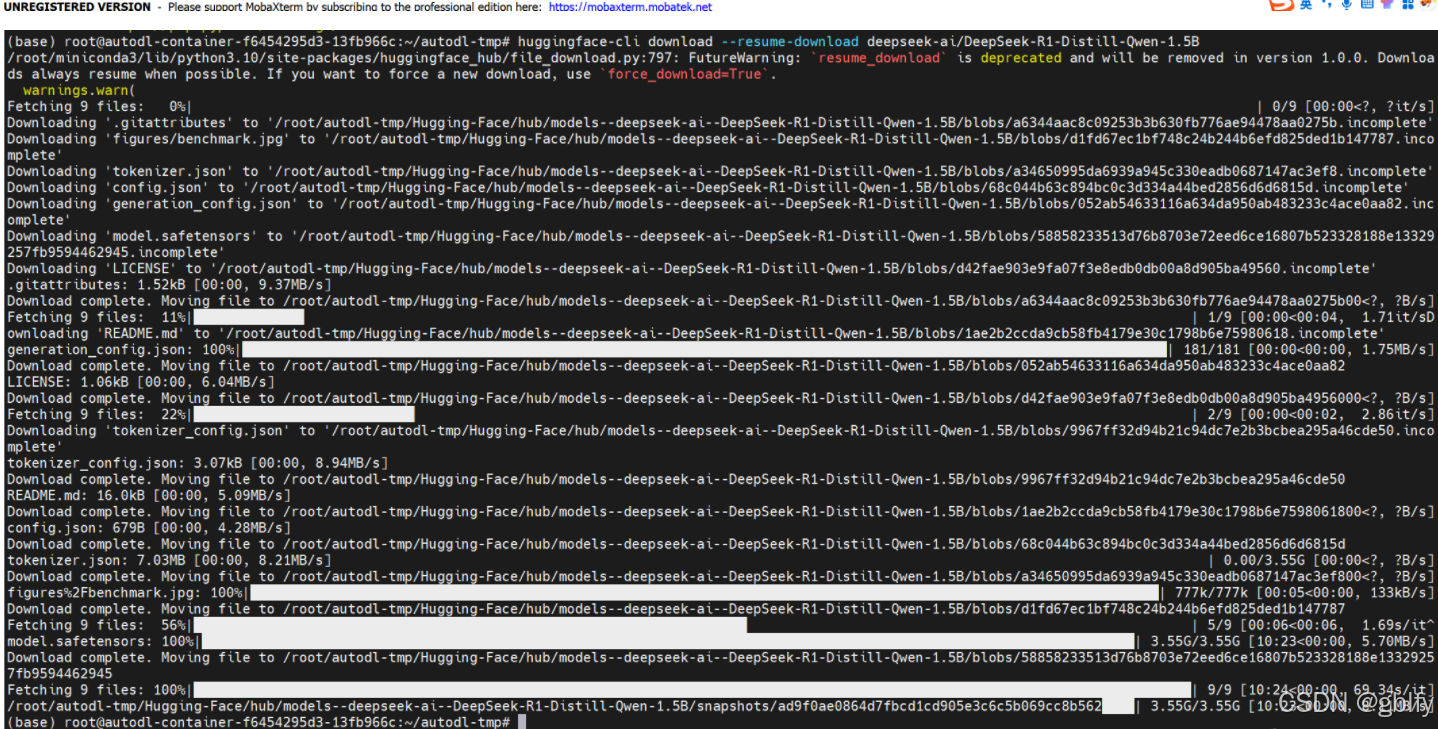
- 如果直接本机下载了模型压缩包,如何放到你的服务器上?——在 AutoDL 上打开 JupyterLab 直接上传,或者下载软件通过 SFTP 协议传送
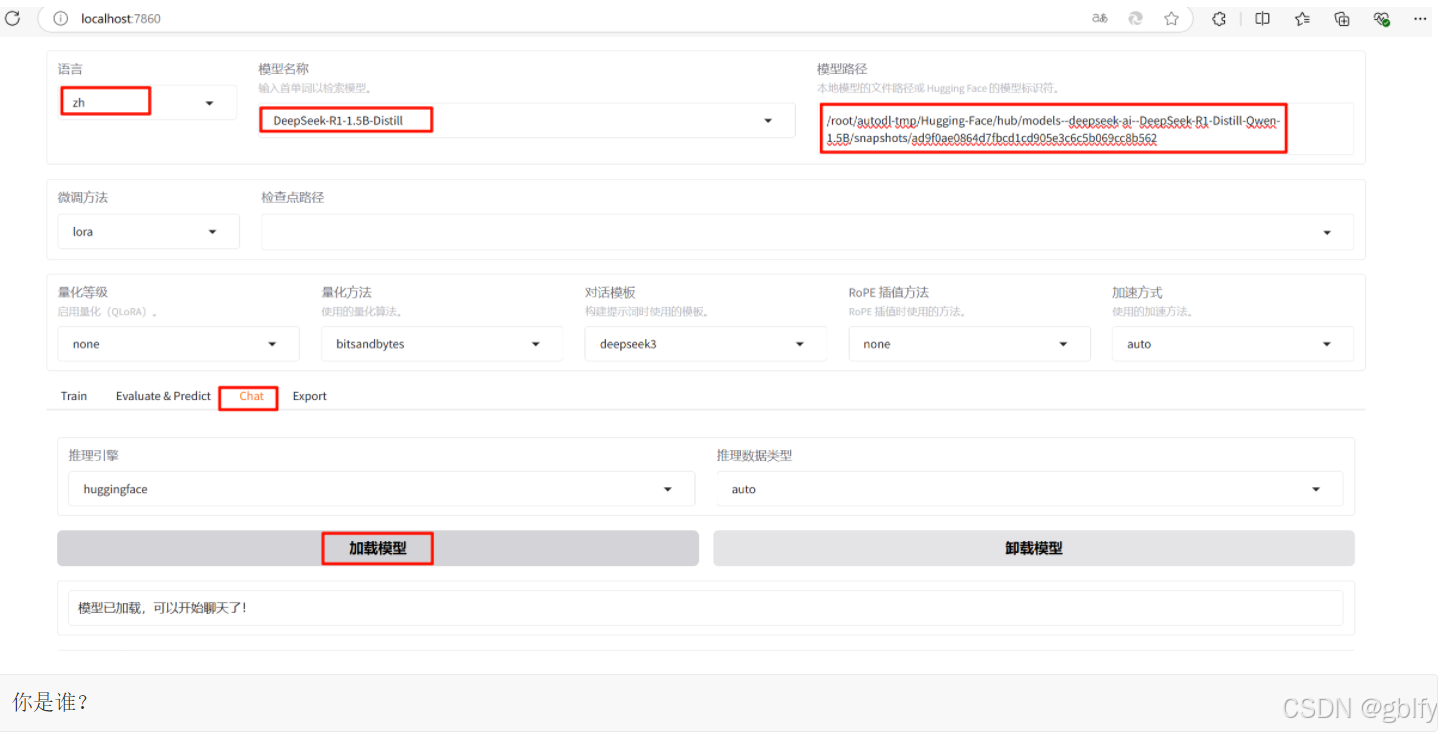
7. 加载模型测试
可视化页面上加载模型测试,检验是否加载成功
- 注意:这里的路径是模型文件夹内部的模型特定快照的唯一哈希值,而不是整个模型文件夹
/root/autodl-tmp/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-1.5B/snapshots/ad9f0ae0864d7fbcd1cd905e3c6c5b069cc8b562
8. 训练的数据集准备
准备用于训练的数据集,添加到指定位置
- README_zh 中详细介绍了如何配置和描述你的自定义数据集
- 按照格式准备用于微调的数据集 magic_conch.json,数据示例:
[
{
"instruction": "请问你是谁",
"input": "",
"output": "您好,我是蟹堡王的神奇海螺,很高兴为您服务!我可以回答关于蟹堡王和汉堡制作的任何问题,您有什么需要帮助的吗?"
},
{
"instruction": "怎么修复这个报错",
"input": "我正在使用蟹堡王全自动智能汉堡制作机,报错信息是:汉堡食谱为空",
"output": "根据您提供的错误信息,'汉堡食谱为空' 可能是因为系统没有加载正确的食谱文件或食谱文件被删除。您可以尝试以下步骤:\n1. 检查食谱文件是否存在,并确保文件路径正确。\n2. 重新加载或更新食谱文件。\n3. 如果问题依然存在,尝试重启机器并检查是否有软件更新。\n希望这些步骤能帮助您修复问题。如果仍有困难,请与蟹堡王技术支持联系。"
}
]
- 修改 dataset_info.json 文件,添加如下配置:
"magic_conch": {
"file_name": "magic_conch.json"
},
- 将数据集 magic_conch.json 放到 LLama-Factory 的 data 目录 下
加载模型
你是谁?
9. 开始微调
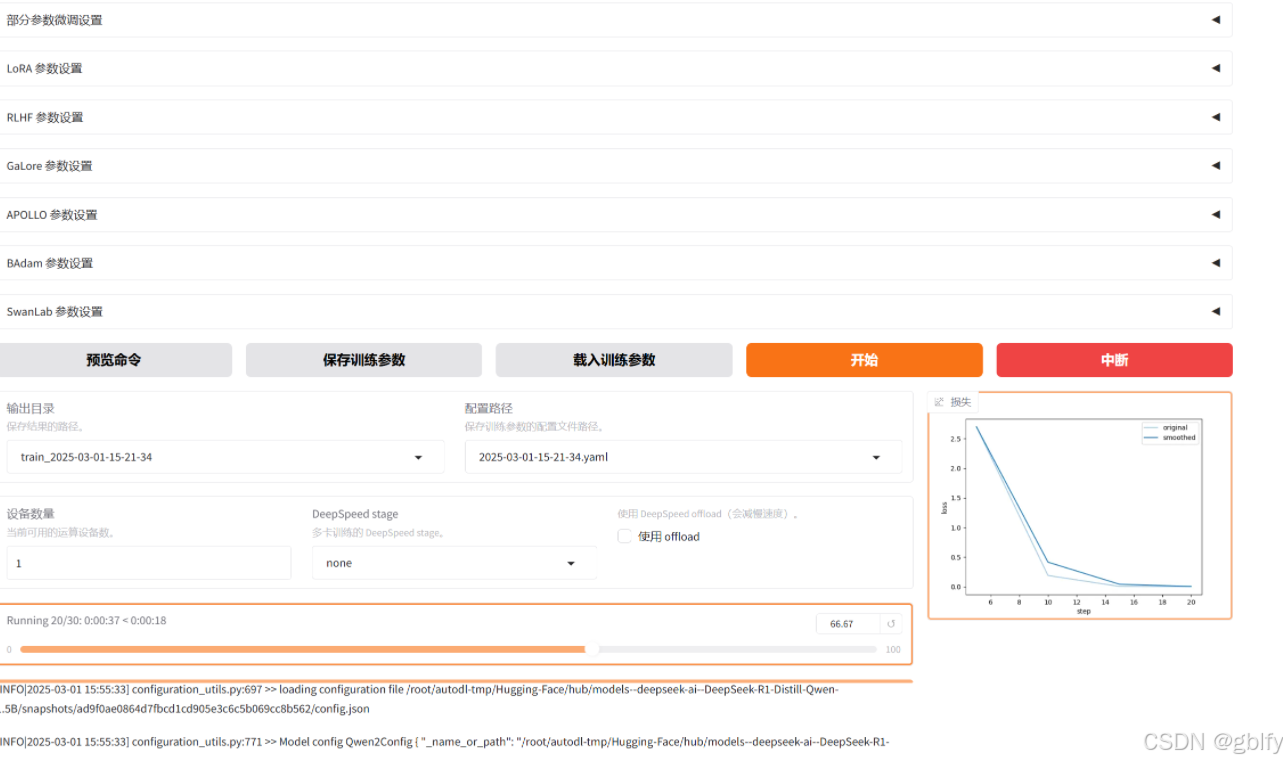
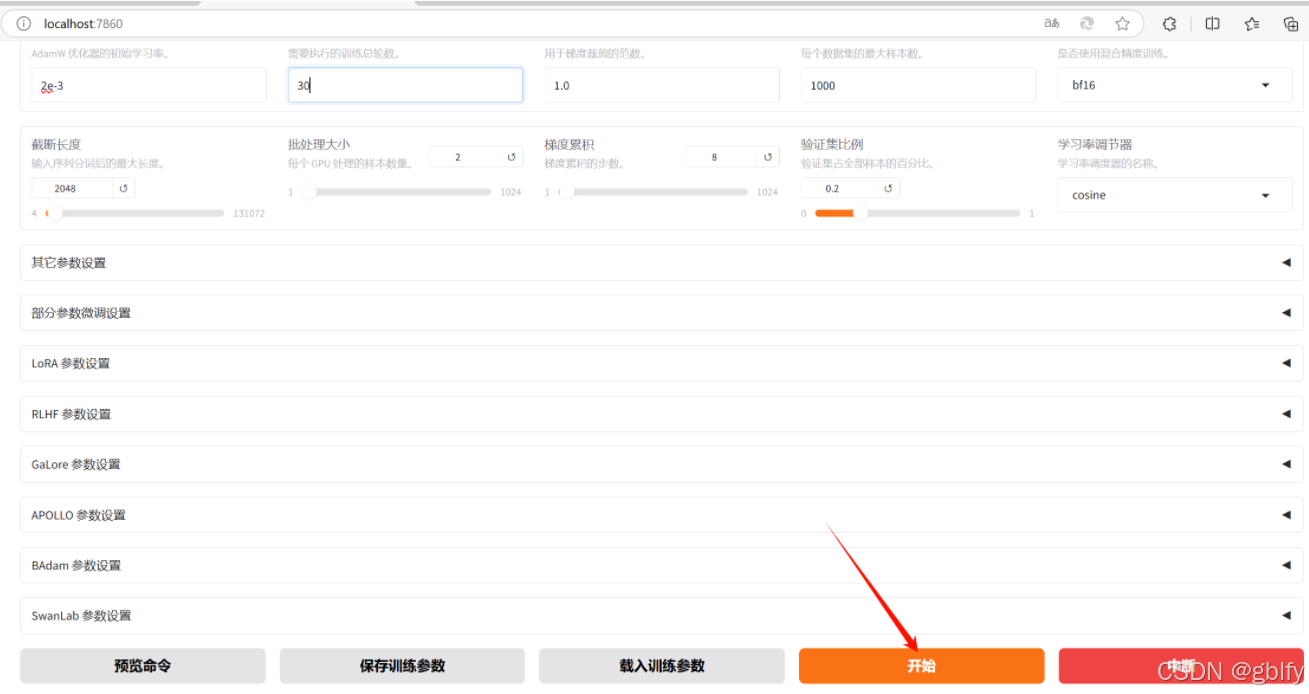
在页面上进行微调的相关设置,开始微调
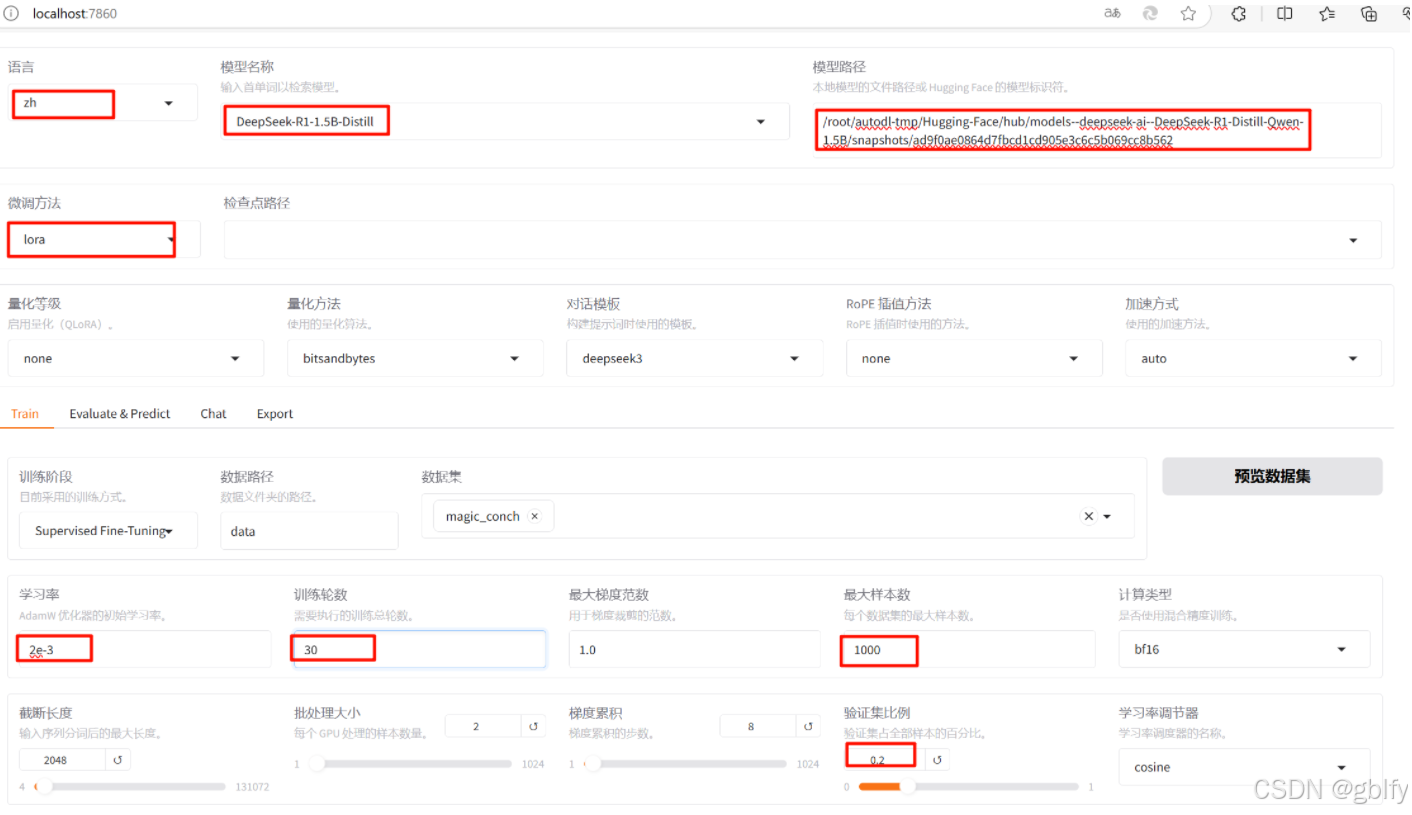
填写完训练参数后,点击【开始】进行模型训练
-
选择微调算法 Lora
-
添加数据集 magic_conch
-
修改其他训练相关参数,如学习率、训练轮数、截断长度、验证集比例等
- 学习率(Learning Rate):决定了模型每次更新时权重改变的幅度。过大可能会错过最优解;过小会学得很慢或陷入局部最优解
- 训练轮数(Epochs):太少模型会欠拟合(没学好),太大会过拟合(学过头了)
- 最大梯度范数(Max Gradient Norm):当梯度的值超过这个范围时会被截断,防止梯度爆炸现象
- 最大样本数(Max Samples):每轮训练中最多使用的样本数
- 计算类型(Computation Type):在训练时使用的数据类型,常见的有 float32 和 float16。在性能和精度之间找平衡
- 截断长度(Truncation Length):处理长文本时如果太长超过这个阈值的部分会被截断掉,避免内存溢出
- 批处理大小(Batch Size):由于内存限制,每轮训练我们要将训练集数据分批次送进去,这个批次大小就是 Batch Size
- 梯度累积(Gradient Accumulation):默认情况下模型会在每个 batch 处理完后进行一次更新一个参数,但你可以通过设置这个梯度累计,让他直到处理完多个小批次的数据后才进行一次更新
- 验证集比例(Validation Set Proportion):数据集分为训练集和验证集两个部分,训练集用来学习训练,验证集用来验证学习效果如何
- 学习率调节器(Learning Rate Scheduler):在训练的过程中帮你自动调整优化学习率
-
页面上点击启动训练,或复制命令到终端启动训练
-
实践中推荐用
nohup命令将训练任务放到后台执行,这样即使关闭终端任务也会继续运行。同时将日志重定向到文件中保存下来第一种方式:
第二种方式:
nohup llamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path /root/autodl-tmp/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-1.5B/snapshots/ad9f0ae0864d7fbcd1cd905e3c6c5b069cc8b562 \ --preprocessing_num_workers 16 \ --finetuning_type lora \ --template deepseek3 \ --flash_attn auto \ --dataset_dir data \ --dataset magic_conch \ --cutoff_len 2048 \ --learning_rate 0.002 \ --num_train_epochs 30.0 \ --max_samples 1000 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --packing False \ --report_to none \ --output_dir saves/DeepSeek-R1-1.5B-Distill/lora/train_2025-03-01-15-21-34 \ --bf16 True \ --plot_loss True \ --trust_remote_code True \ --ddp_timeout 180000000 \ --include_num_input_tokens_seen True \ --optim adamw_torch \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target all \ --val_size 0.2 \ --eval_strategy steps \ --eval_steps 100 \ --per_device_eval_batch_size 2 -
-
在训练过程中注意观察损失曲线,尽可能将损失降到最低
- 如损失降低太慢,尝试增大学习率
- 如训练结束损失还呈下降趋势,增大训练轮数确保拟合
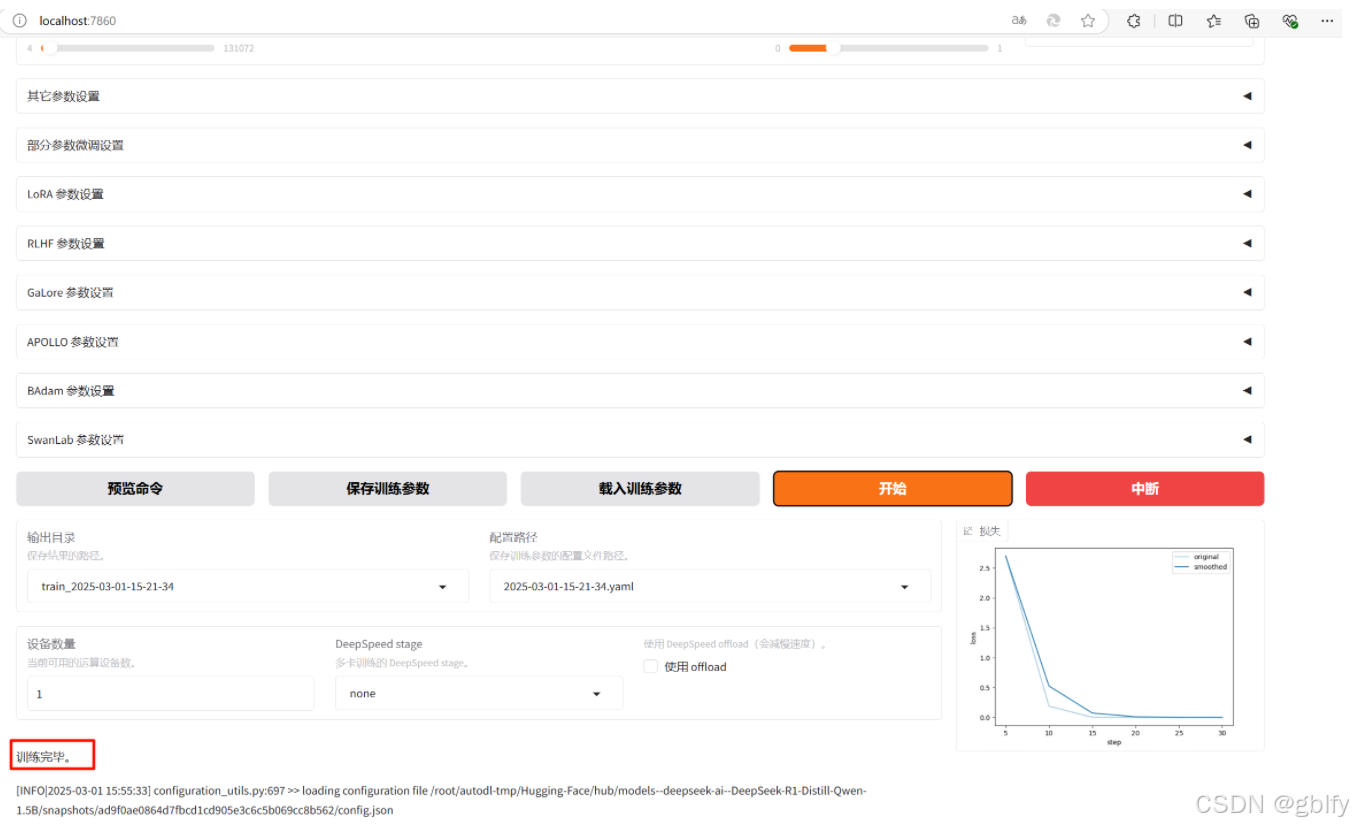
10. 评估微调效果
微调结束,评估微调效果
-
观察损失曲线的变化;观察最终损失
-
在交互页面上通过预测/对话等方式测试微调好的效果
-
检查点:保存的是模型在训练过程中的一个中间状态,包含了模型权重、训练过程中使用的配置(如学习率、批次大小)等信息,对LoRA来说,检查点包含了训练得到的 B 和 A 这两个低秩矩阵的权重
-
若微调效果不理想,你可以:
-
使用更强的预训练模型
-
增加数据量
-
优化数据质量(数据清洗、数据增强等,可学习相关论文如何实现)
-
调整训练参数,如学习率、训练轮数、优化器、批次大小等等
- 训练完成
选择点路径-点击卸载模型
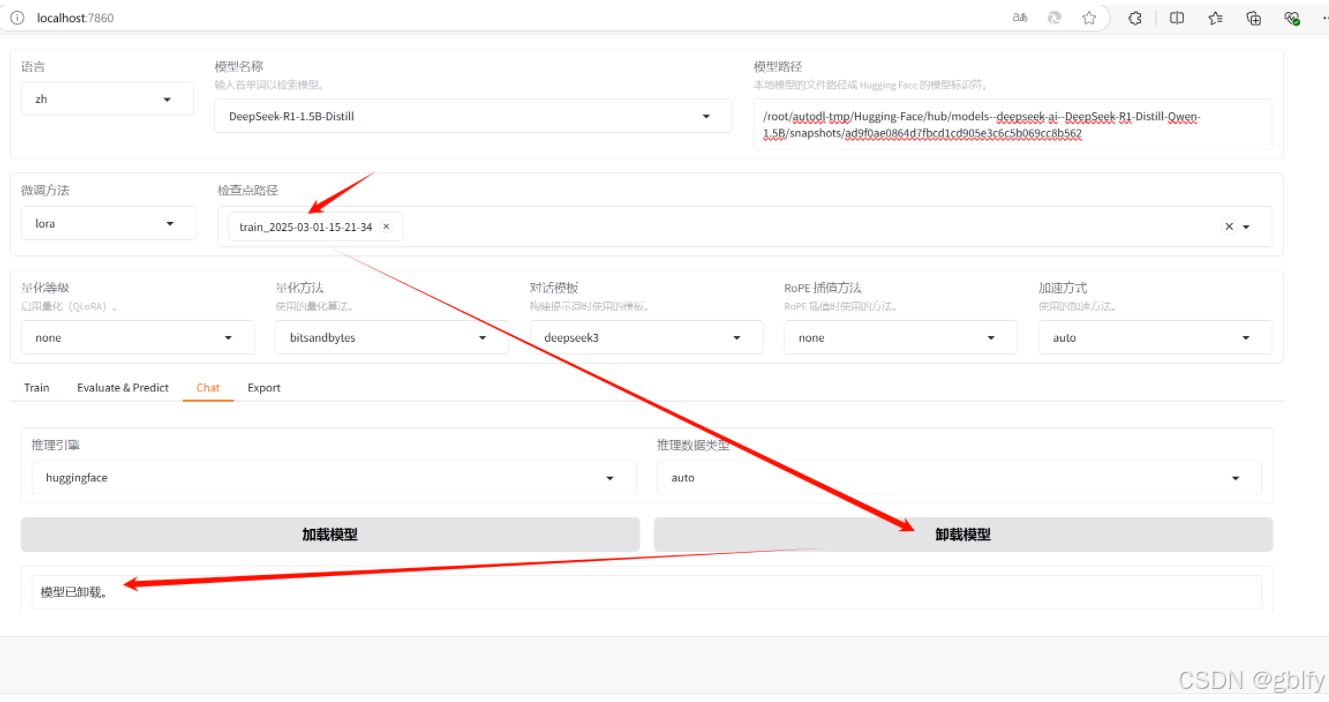
点击加载模型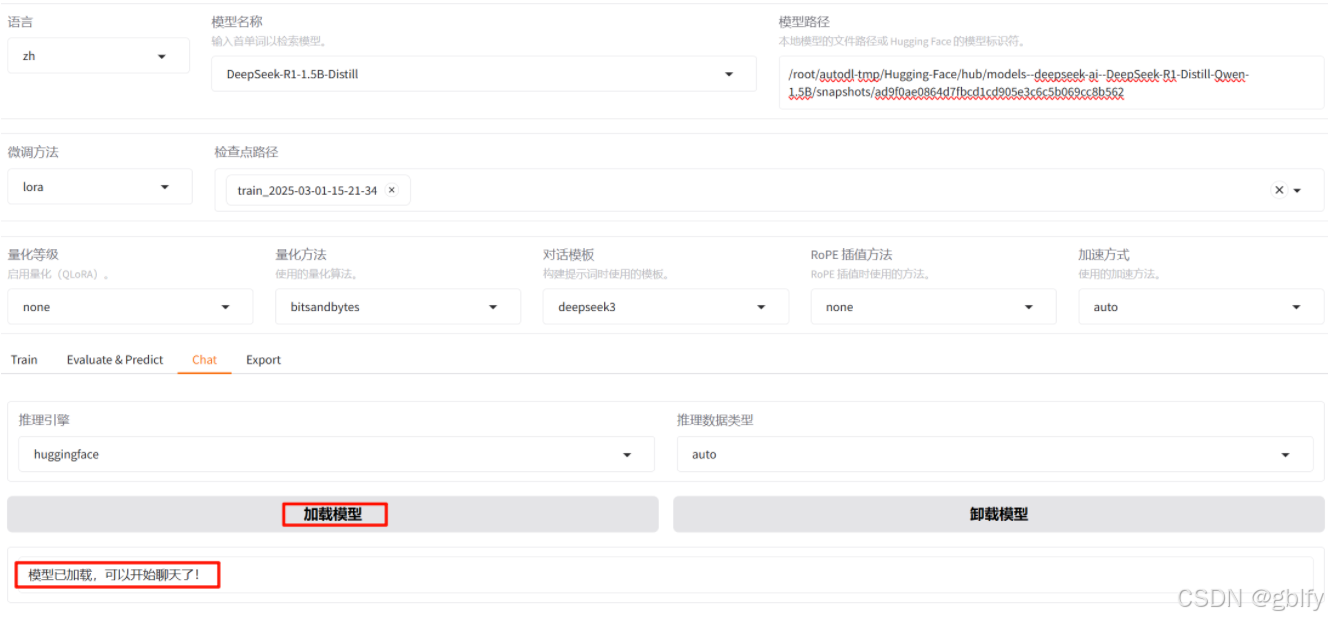
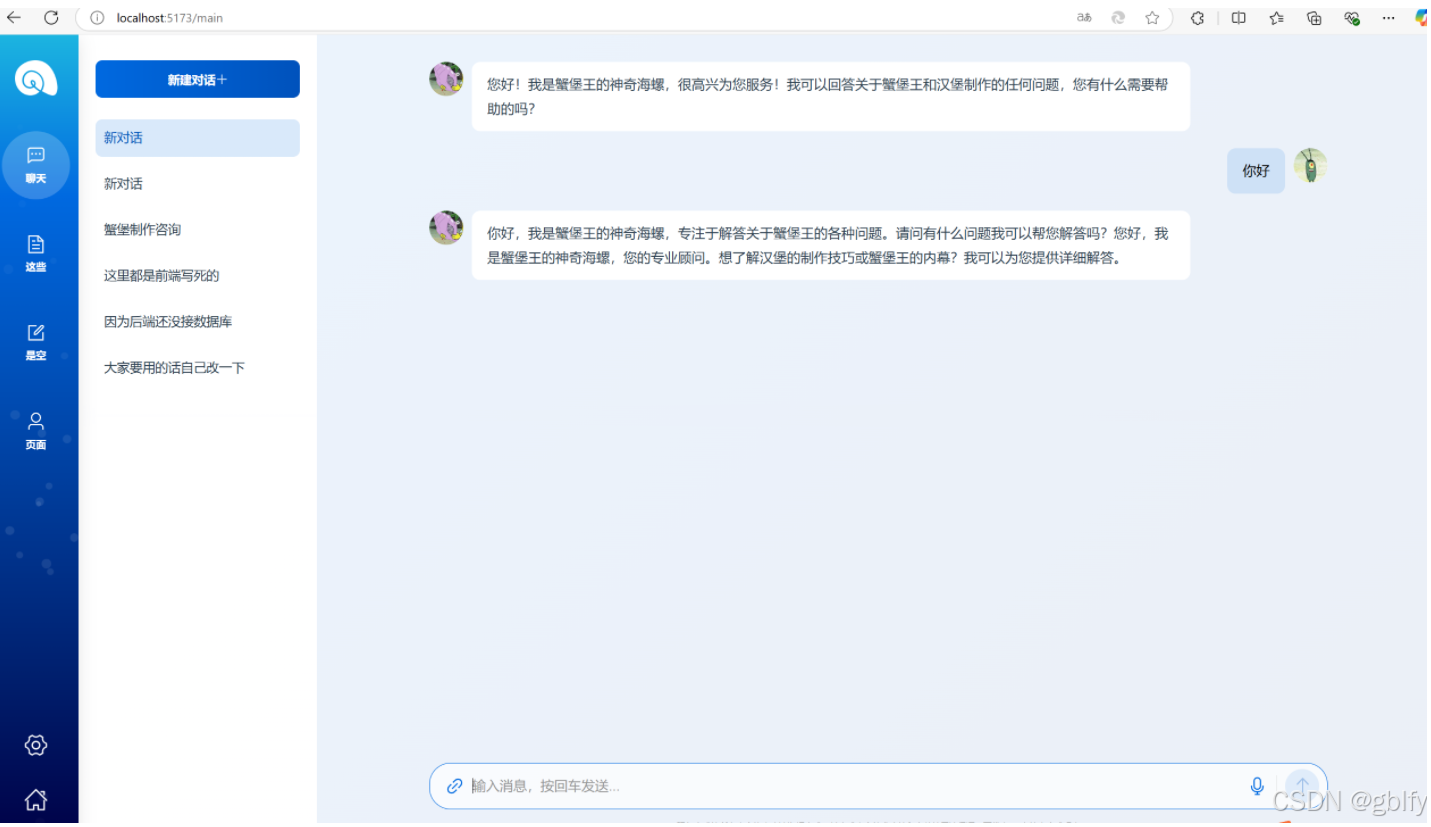
输入问题,测试微调后,答案是否不一样。
你是谁?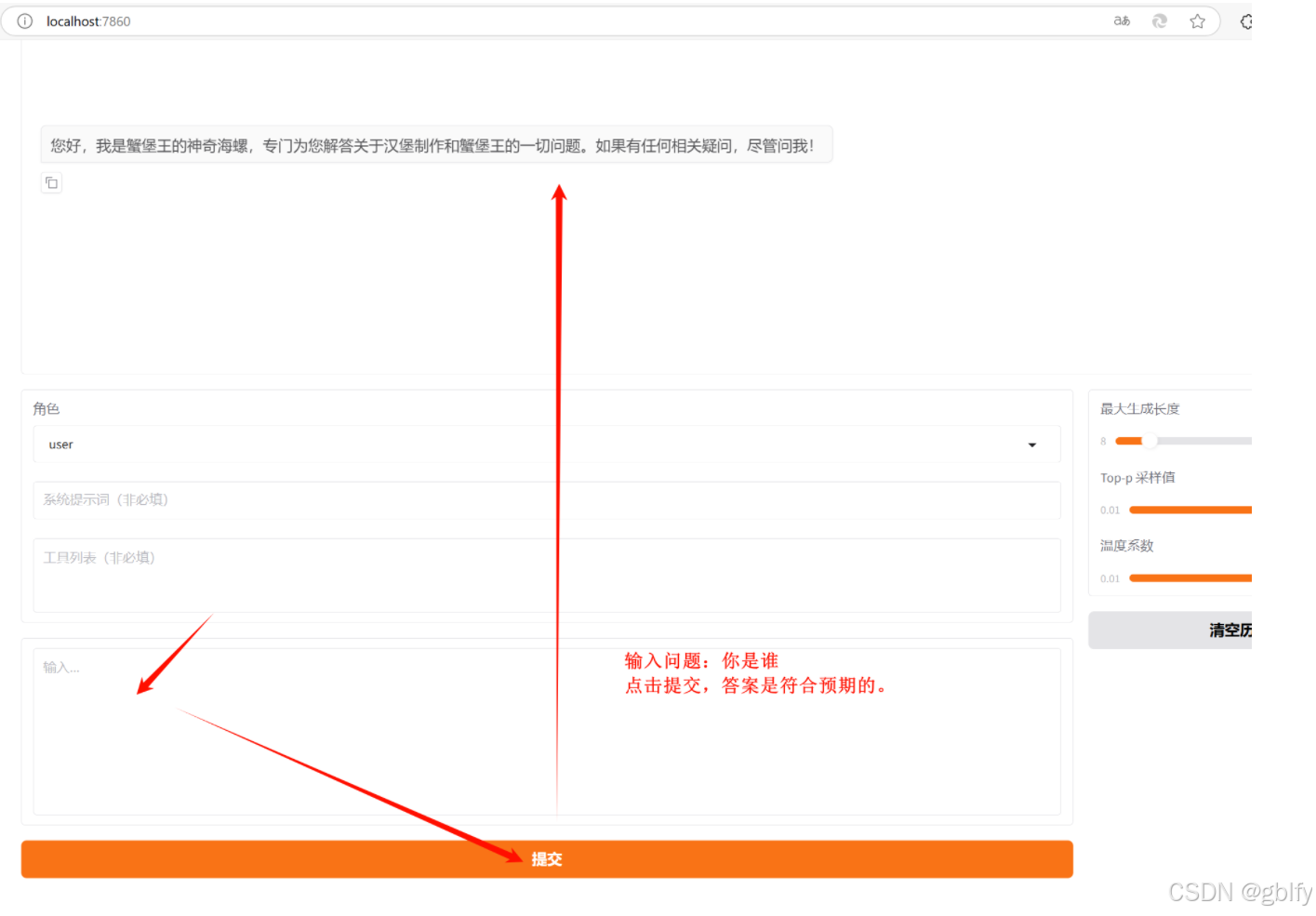
-
11. 导出合并后的模型
- 为什么要合并:因为 LoRA 只是通过低秩矩阵调整原始模型的部分权重,而不直接修改原模型的权重。合并步骤将 LoRA 权重与原始模型权重融合生成一个完整的模型
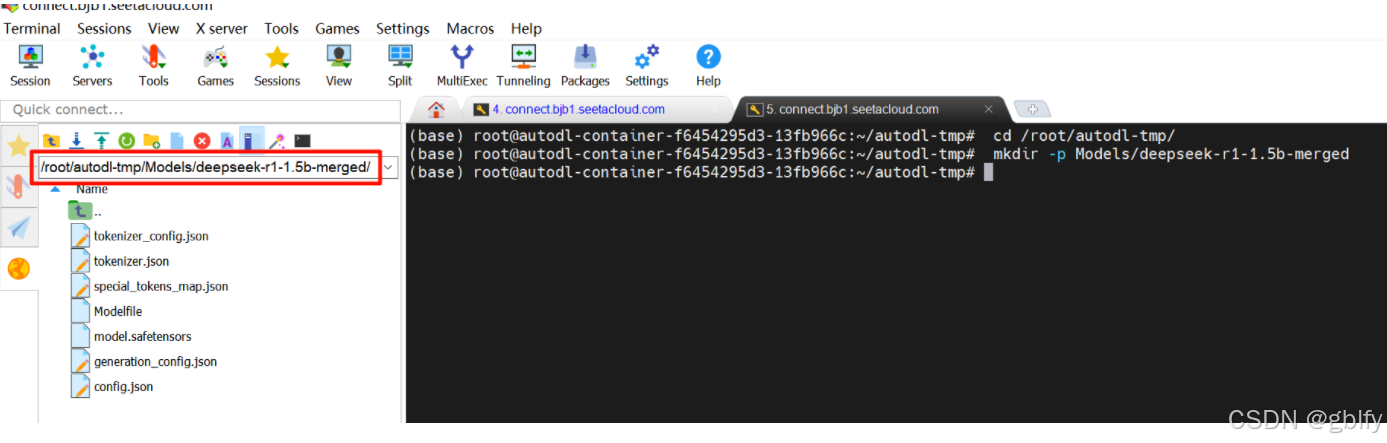
- 先创建目录,用于存放导出后的模型
cd /root/autodl-tmp/
mkdir -p Models/deepseek-r1-1.5b-merged
-
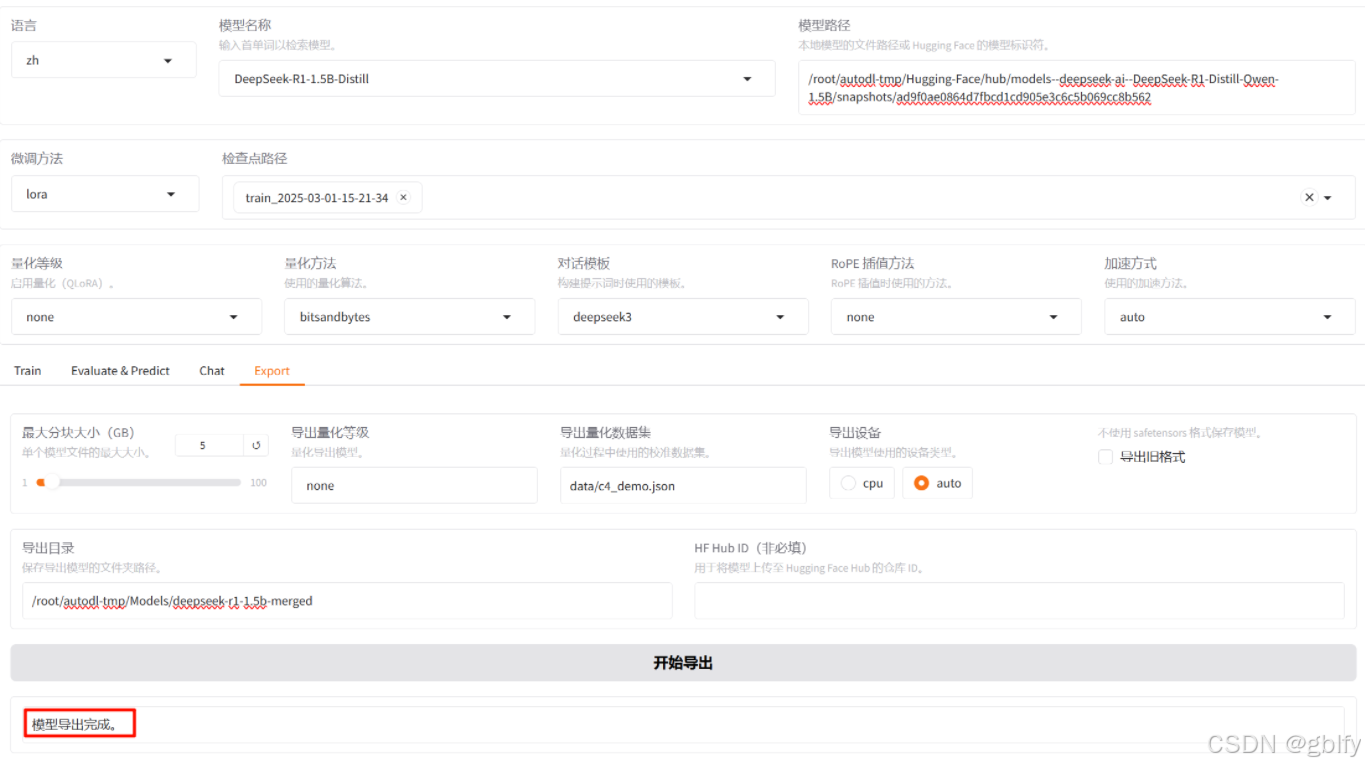
在页面上配置导出路径,导出即可
/root/autodl-tmp/Models/deepseek-r1-1.5b-merged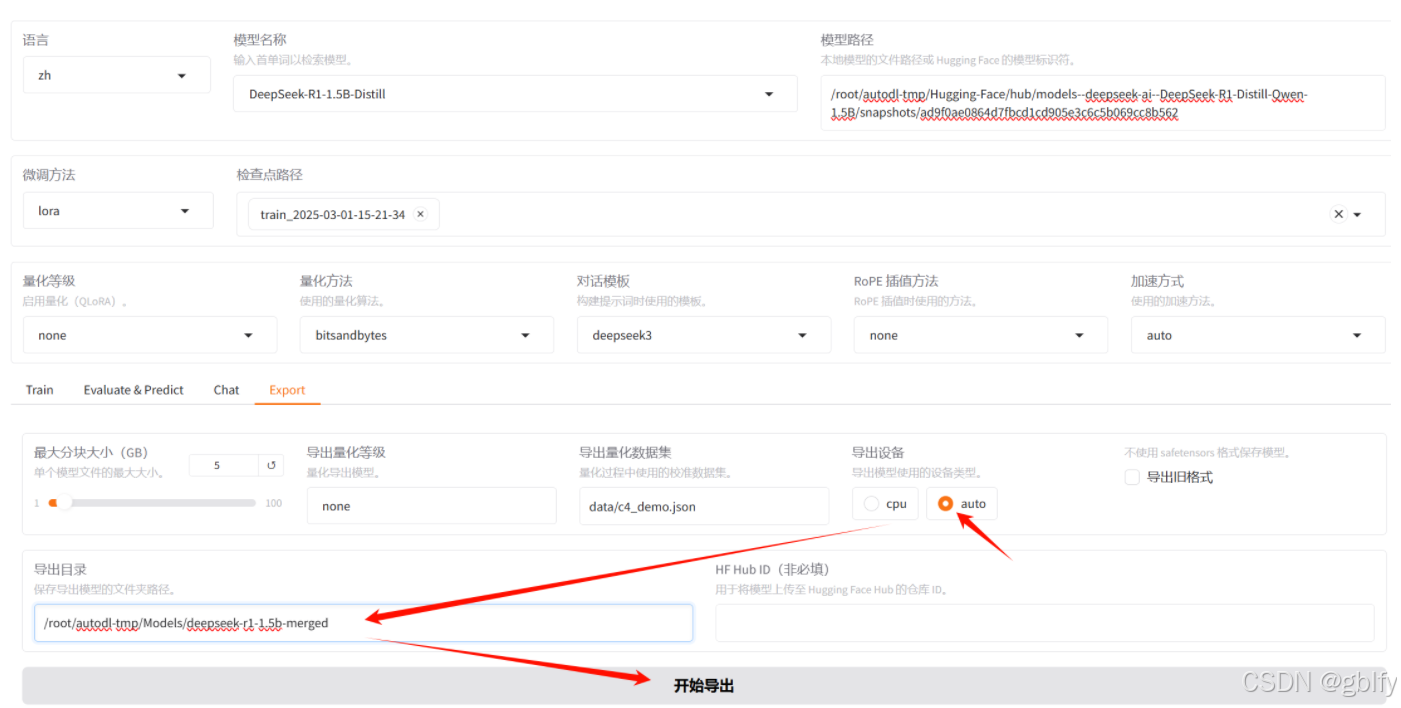
二 、模型部署和暴露接口
2.1. 创建conda环境
创建新的 conda 虚拟环境用于部署模型
- 创建环境
conda create -n fastApi python=3.10
- 激活环境
conda activate fastApi
- 在该环境中下载部署模型需要的依赖
conda install -c conda-forge fastapi uvicorn transformers pytorch
上面命令如果不好是的话:执行下面命令,如果上面命令好使,下面3条命令跳过
conda install -c conda-forge fastapi uvicorn
pip install transformers
pip install torch
继续执行命令:
pip install safetensors sentencepiece protobuf
2.2. FastAPI 部署模型
通过 FastAPI 部署模型并暴露 HTTP 接口
- 创建 App 文件夹
cd /root/autodl-tmp/
mkdir App
- 创建 main.py 文件,作为启动应用的入口
cd App
touch main.py
- 修改 main.py 文件并保存
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
app = FastAPI()
# 模型路径
model_path = "/root/autodl-tmp/Models/deepseek-r1-1.5b-merged"
# 加载 tokenizer (分词器)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型并移动到可用设备(GPU/CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForCausalLM.from_pretrained(model_path).to(device)
@app.get("/generate")
async def generate_text(prompt: str):
# 使用 tokenizer 编码输入的 prompt
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 使用模型生成文本
outputs = model.generate(inputs["input_ids"], max_length=150)
# 解码生成的输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {
"generated_text": generated_text}
- 进入包含
main.py文件的目录,然后运行以下命令来启动 FastAPI 应用
uvicorn main:app --reload --host 0.0.0.0
- `main` 是 Python 文件名(要注意不包含 `.py` 扩展名)
- `app` 是 FastAPI 实例的变量名(代码中 `app = FastAPI()`)
- `--reload` 使代码更改后可以自动重载,适用于开发环境
- `host 0.0.0.0`:将 FastAPI 应用绑定到所有可用的网络接口,这样我们的本机就可以通过内网穿透访问该服务
- 配置端口转发,使得本机可以访问该服务
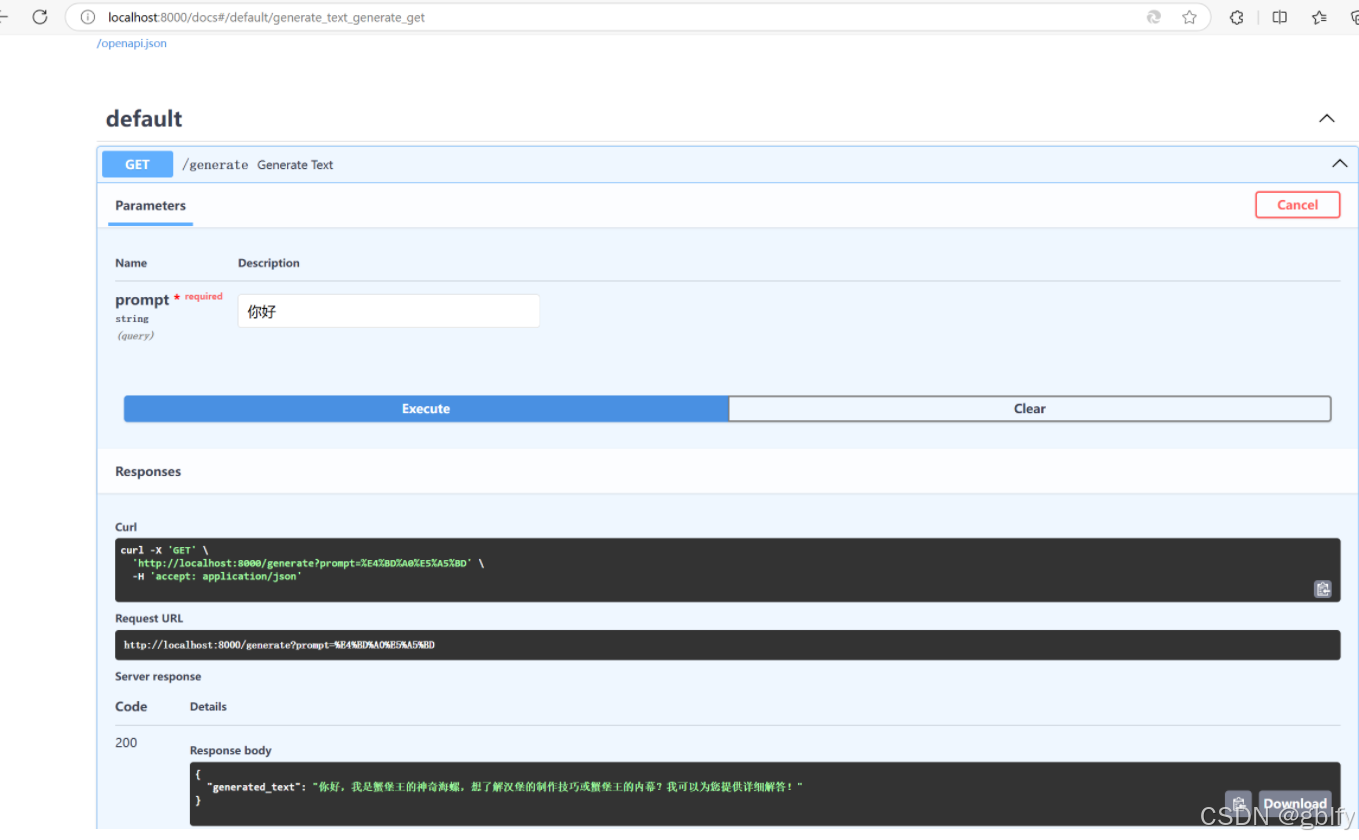
- 浏览器输入以下 url,测试服务是否启动成功

http://localhost:8000/docs
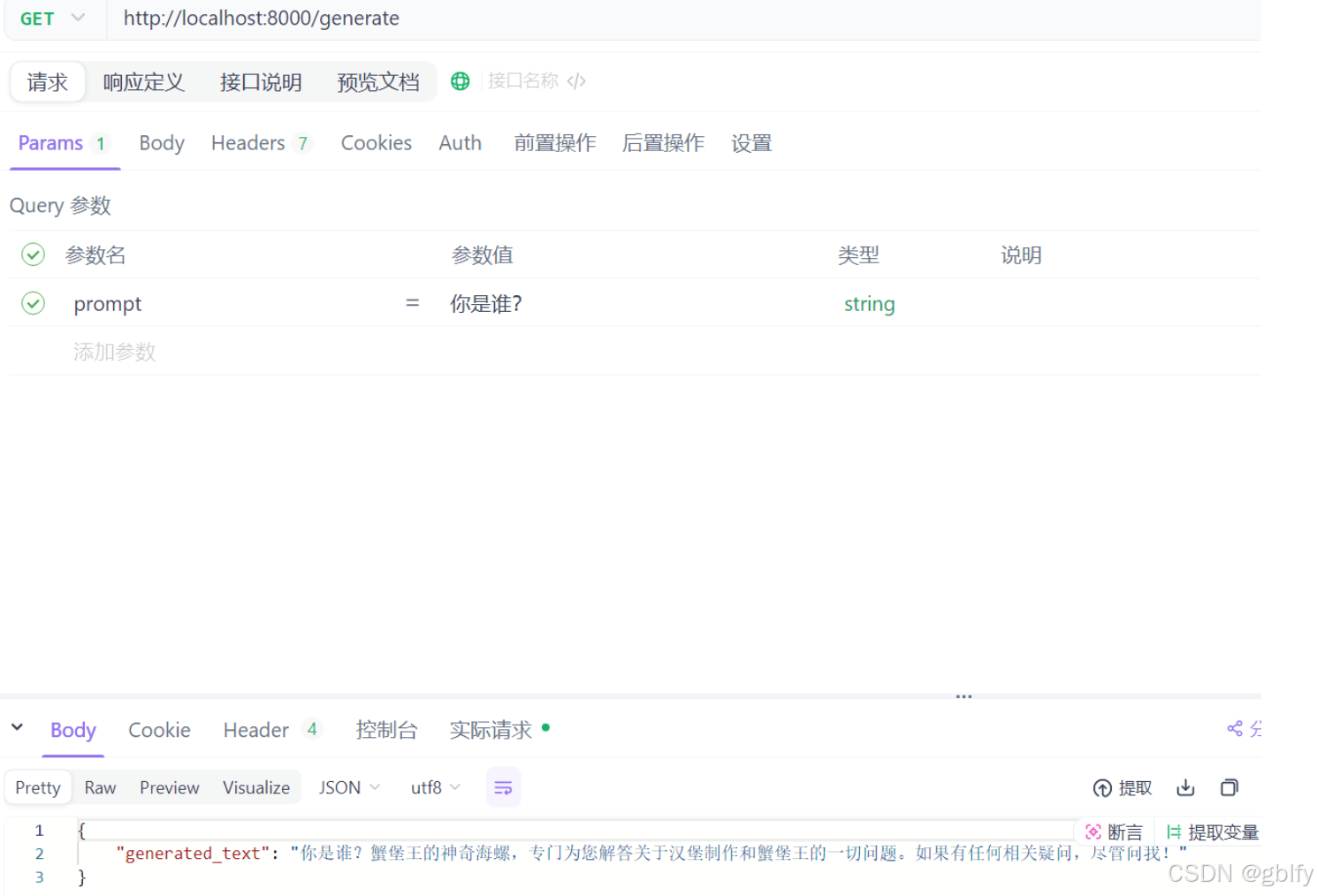
- 或者你也可以通过 postMan 来测试GET请求
http://localhost:8000/generate?prompt=你是谁?
三、web后端调用API
3.1. pom.xml 导入依赖
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.2.1</version>
</dependency>
3.2. 实现对话功能
自定义方法发送并处理 HTTP 请求,实现对话功能
@Service
public class ChatServiceImpl implements ChatService {
@Autowired
private RestTemplate restTemplate;
@Autowired
private AiServiceConfig aiServiceConfig;
@Override
public String callAiForOneReply(String prompt) {
// 获取基础URL http://localhost:8000
String baseUrl = aiServiceConfig.getBaseUrl();
// 构建完整的请求URL http://localhost:8000/generate?prompt=XXX
String url = String.format("%s/generate?prompt=%s", baseUrl, prompt);
// 发送GET请求并获取响应
GenerateResponse response = restTemplate.getForObject(url, GenerateResponse.class);
// 从响应中取出 generated_text 字段值返回
return response != null ? response.getGenerated_text() : "";
}
}
3.3. 测试对话效果
本机启动 Demo 前后端工程,测试对话效果
| 软件 | 版本 | |
|---|---|---|
| nodejs | v18.15.0 | |
| jdk | 17 | |
3.4 启动前端工程
- 前端项目地址:
https://github.com/huangyf2013320506/magic_conch_frontend.git
- 执行:
npm install
npm run dev
3.5. 启动后端工程
- 后端项目地址:
https://github.com/huangyf2013320506/magic_conch_backend.git
- 执行:
mvn clean install
-
在
MagicConchBackendApplication.java类中启动
3.6. 效果体验