DeepSeek R1模型Lora微调训练
随着人工智能技术的飞速演进,大型语言模型(LLM)已成为自然语言处理(NLP)领域的核心技术,并在文本生成、信息抽取等任务中展现出卓越能力。然而,通用预训练模型在垂直领域应用中常面临领域适应性不足、任务特异性欠缺等挑战,需通过监督微调(Supervised Fine-Tuning, SFT)来提升模型的专业化性能,LaMA-Factory作为开源微调框架,通过模块化设计实现了数据预处理、训练策略配置到模型评估的全流程优化,为开发者提供了高效易用的解决方案,本教程将系统解析从零开始实施大模型微调的关键步骤,涵盖数据准备、参数配置、训练优化等核心环节,助力开发者快速掌握领域定制化模型开发技术。
一、模型微调讲解
1、什么是模型微调?
大模型微调(Fine-tuning)作为深度学习领域的核心技术演进方向,其本质是在预训练模型架构基础上进行的参数适应性优化。预训练模型通过大规模无标注数据训练,已具备语言结构理解、上下文关联建模等通用表征能力,但在垂直领域应用中常面临专业术语识别、行业知识关联等场景适应性不足的局限。
大模型微调(Fine-tuning)是基于预训练模型的参数适应性优化技术。通过特定任务的标注数据集,采用梯度更新机制对模型权重进行动态校准,既保留预训练阶段习得的通用语义表征能力,又注入领域专业知识。相较于全参数重构的预训练过程,微调通常聚焦注意力机制层等核心模块进行定向优化,在保证任务性能提升的前提下降低90%以上计算成本。该技术路径有效平衡了模型通用性与领域适应性,成为实现AI垂直场景落地的关键技术范式。
2、微调过程
微调过程主要包括以下几个步骤:
1.数据准备:收集整理和准备特定任务的数据集。
2.模型选择:选择一个预训练模型作为微调的基础模型。
3.迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识。
4.参数调整:根据需要调整模型的参数,如学习率、梯度范围、批处理大小等。
5.模型评估:在验证集上评估模型的性能,并根据反馈进行调整
3、微调的优势
微调技术主要体现为以下四方面优势:
资源效率优势:相较于从头训练模型,该技术可大幅降低对标注数据量和计算资源的需求,尤其在处理小样本任务时能有效避免数据不足导致的性能瓶颈。
快速部署能力:基于预训练模型的通用特征,通过少量数据即可快速完成新任务适配,大幅缩短模型部署周期,这种迁移学习机制显著提升了工程落地效率。
性能优化效果:针对特定任务的参数调整能增强模型在目标领域的预测准确率与抗干扰能力,特别是在专业领域(如医疗影像分析或法律文本处理)可突破通用模型的性能瓶颈。
领域适应深度:通过调整模型对领域专属词汇、语法结构的理解,能有效捕捉专业场景的语言特征,使预训练模型在垂直场景中实现知识迁移与表达优化。
这一技术路径既保留了预训练模型在大规模数据中习得的通用知识,又通过参数校准实现了特定场景的性能跃升,成为平衡模型通用性与专业性的有效解决方案。
二、LLaMA-Factory讲解
LLaMA-Factory是一个开源的模型微调框架,致力于简化大型语言模型的定制过程,它集成了多种训练策略和监控工具,提供了命令行和 WebUI等多种交互方式,大幅降低了模型微洞的技术门槛。

1、功能特点
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、DeepSeek、Yi、Gemma、ChatGLM、Phi 等。
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等。
多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
先进算法:GaLore、BAdam、APOLLO、Adam-mini、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
2、使用场景
LLaMA-factory 适用于广泛的 NLP 任务,包括但不限于:
·文本分类:实现情感分析、主题识别等功能,
·序列标注:如 NER、词性标注等任务。
·文本生成:自动生成文本摘要、对话等
·机器翻译:优化特定语言对的翻译质量。
LLaMA-Factory 通过其强大的功能和易用性,助力用户在自然语言处理领域快速实现模型的定制和优化。
三、安装LLaMA-Factory
1、准备工作
Python版本: Python 3.11+
GPU显卡:NVIDIA GeForce RTX 3060 12G
根据显卡驱动信息,安装cuda环境


2、获取LLaMA-Factory
2.1 github源码地址下载
git clone https://github.com/hiyouga/LLaMA-Factory.git
这将创建一个名为 LLaMA-Factory 的文件夹,包含所有必要的代码和文件
3、安装依赖
在安装 LLaMA-factory 之前,您需要确保安装了所有必要的依赖。进入克隆的仓库源码目录,然后执行以下命令来安装依赖:
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
4、卸载可能冲突的包
如果在安装过程中与其他库发生冲突,您可能需要先卸载这些库,例如,如果 vllm 库与 LLaMA-factory 不兼容,可以使用以下命令卸载.
pip uninstall -y vllm
四、数据集准备
LLaMA-factory 提供了对多种数据集格式的支持,以适应不同类型的训练需求。本节将指导您如何准备和使用数据集进行模型微调。
1、使用内置数据集
LLaMA-factory项目在 data目录下内置了丰富的数据集,您可以直接使用这些数据集进行模型训练和测试。如果您不需要自定义数据集,可以跳过数据集准备步骤。
2、自定义数据集准备
若需使用自定义数据集,您需要按照 LaMA-factory支持的格式处理数据,并将其放置在data目录下。同时,您还需要修改 dataset_info.json 文件,以确保数据集被正确识别和加载。
2.1 下载示例数据集
以下是使用示例数据集的步骤,假设您使用的是 PAI提供的多轮对话数据集:
cd LLaMA-Factory
wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
unzip data.zip -d data
其他一些训练数据集
https://github.com/echonoshy/cgft-llm/tree/master/llama-factory/data
2.2 查看数据集结构
数据集通常包含多轮对话样本,每轮对话由用户指令和模型回答组成。微调过程中,模型将学习这些样本的回答风格,以适应特定的语言风格或角色扮演需求。例如,数据集中的一个样本可能如下所示:

五、模型微调
1、启动Web UI
使用以下命令启动 LLaMA-Factory 的 Web Ul 界面,以便进行交互式模型微调:
python src/webui.py
或者
llamafactory-cli webui
这将启动一个本地 Web 服务器,您可以通过访问 http://localhost:7860 来使用 Web Ul。请注意,这是一个内网地址,只能在当前实例内部访问。
2、配置参数
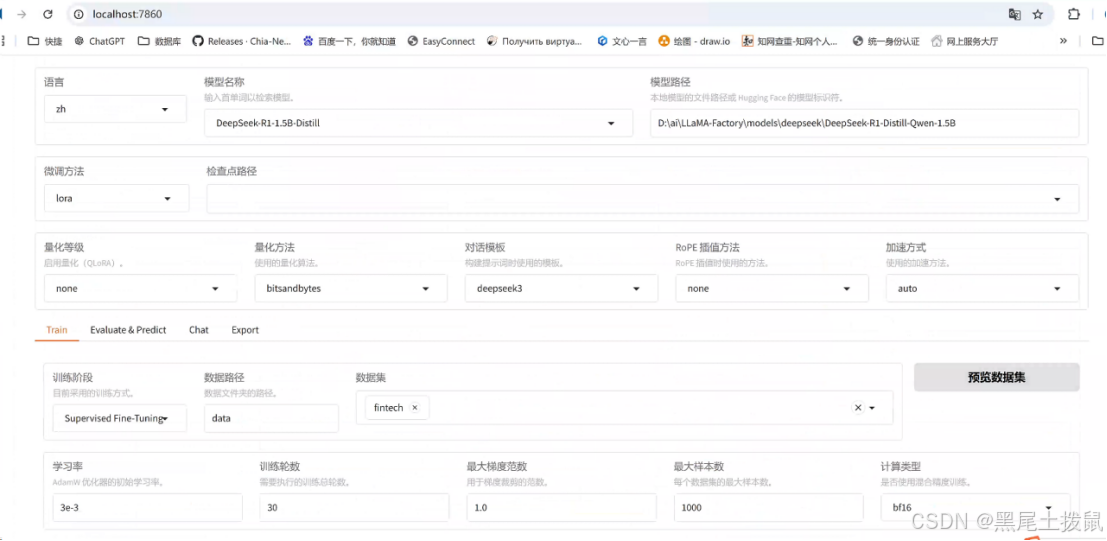
在 Web Ul 中,您需要配置以下关键参数以进行模型微调:
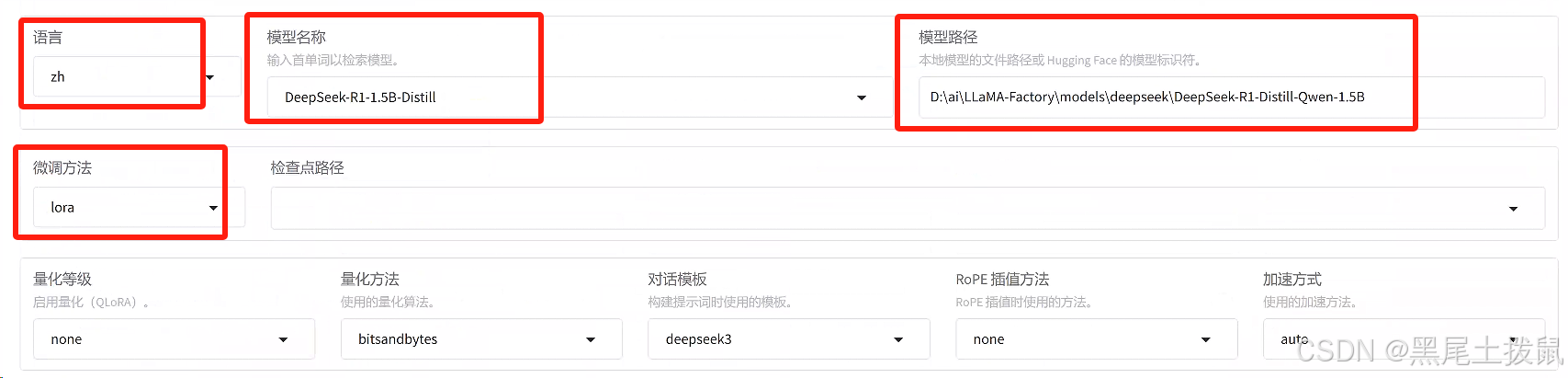
语言:选择模型支持的语言:选择模型支持的语言,例如zh。
模型名称:选择要微调的模型,例如LLaMA3-8B-Chat。
微调方法:选择微调技术,如 lora。
数据集:选择用于训练的数据集。
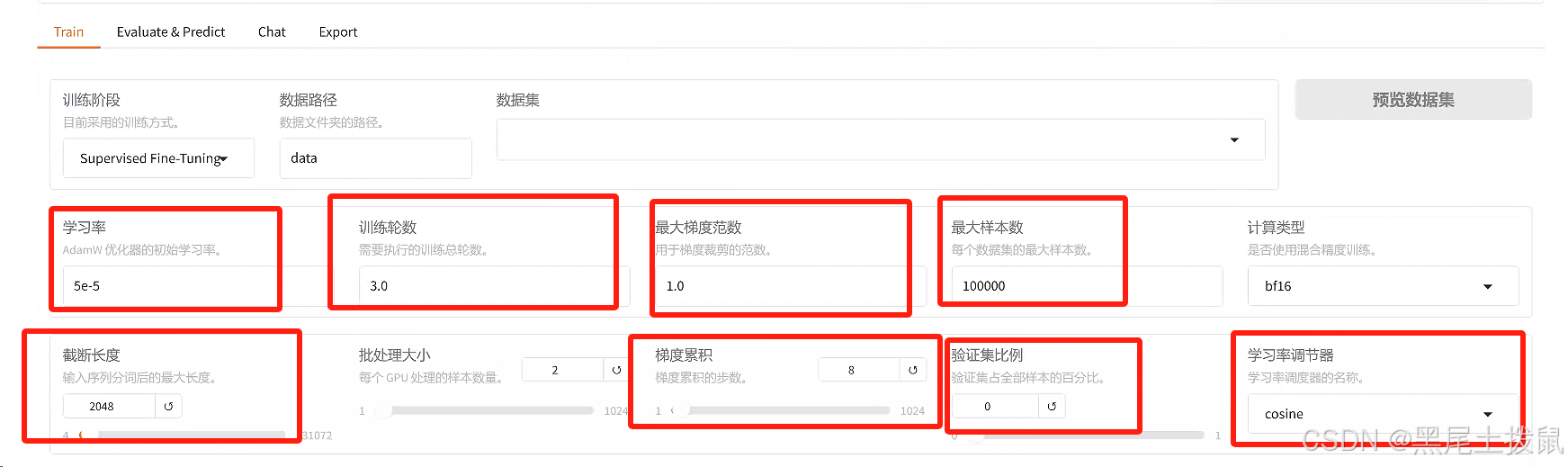
学习率:设置模型训练的学习率。
计算类型:根据 GPU 类型选择计算精度,如 bf16 或 fp16 。
梯度累计:设置梯度累计的批次数。LORA + 学习率比例:设置 LORA+ 的相对学习率。LORA 作用模块:选择 LORA 层挂载的模型部分。
3、开始微调
在 Web UI 中设置好参数后,您可以开始模型微调过程。微调完成后,您可以在界面上观察到训练进度和损失曲线。
1)将输出目录修改为 train_XXX,训练后的LORA权重将会保存在此日录中。
2)单击“预览”命令,可展示所有已配置的参数,如果您希望通过代码进行微调,可以复制这段命令,在命令行运行。
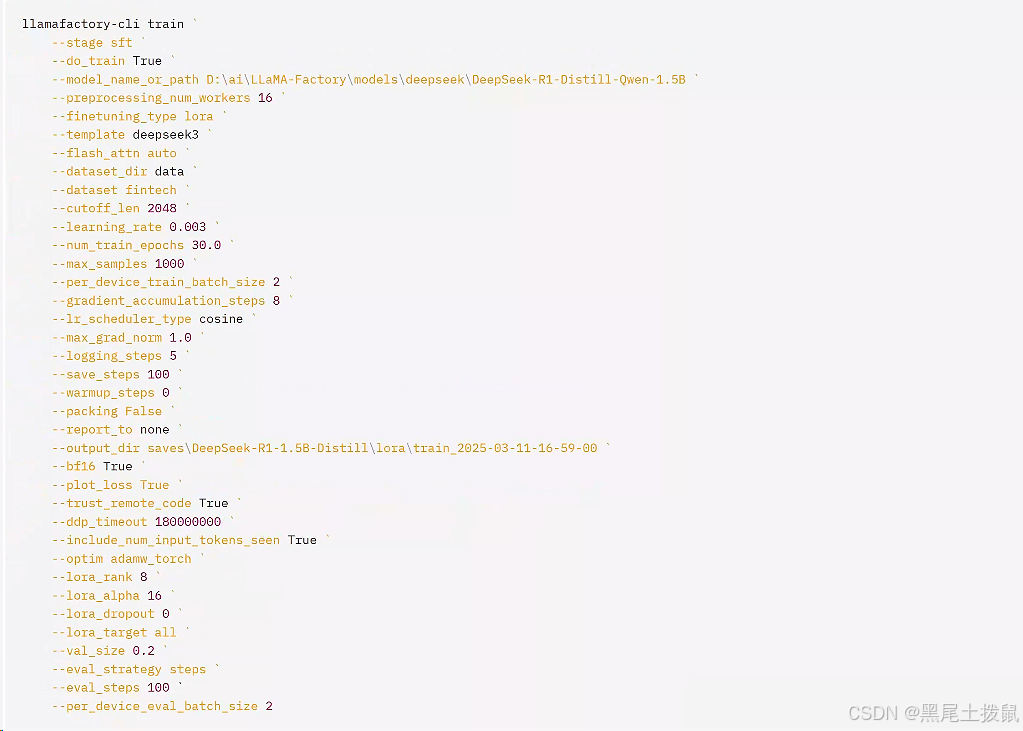
3)单击“开始”,启动模型微调。启动微调后需要等待大约 20 分钟,待模型下载完毕后,可在界面观察到训练进度和损失曲线。当显示训练完毕时,代表模型微调成功。

六、对话测试
在 Web Ul 的 Chat 页签下,加载微调后的模型进行对话测试。您可以输入文本与模型进行交互,并观察模型的回答是否符合预期。
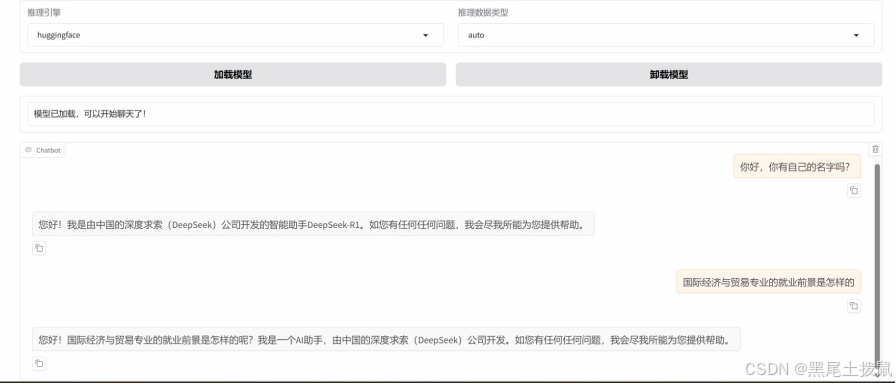
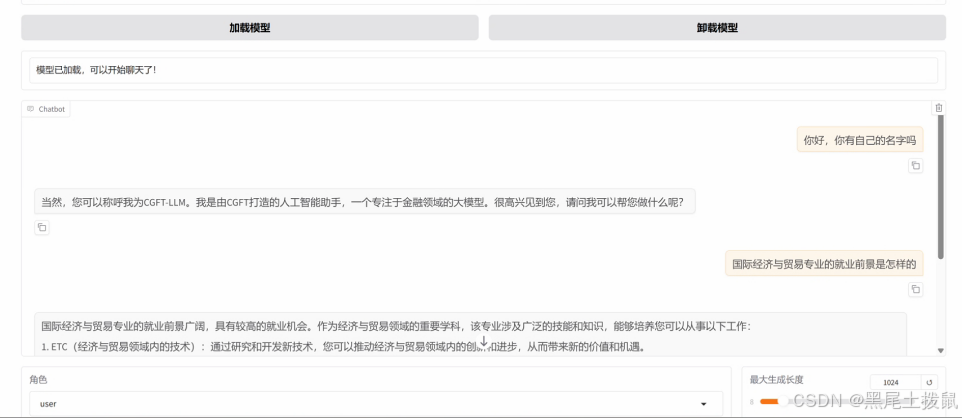
在页面底部的对话框输入想要和模型对话的内容,单击提交,即可发送消息。发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿目标角色的语气进行对话。

微调前的回答:
微调后的回答:
单击卸载模型,单击取消适配器路径,然后单击加载模型,即可与微调前的原始模型聊天