从modelScope中下载模型:
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B在home下创建项目名:deepseek_finetune
创建目录结构:

再增加:根目录下创建 output
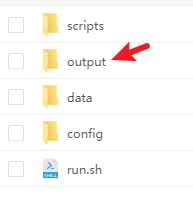
在data下再创建: processed_data

run.sh:
#!/bin/bash
# 数据预处理
python3 scripts/preprocess.py
# 启动训练(单卡)
CUDA_VISIBLE_DEVICES=0 python3 scripts/train.py
# 多卡训练示例(需安装 accelerate)
# accelerate launch --num_processes 2 scripts/train.py
config/train_config.json:
{
"model_id": "deepseek-ai/DeepSeekDeepSeek-R1-Distill-Qwen-1___5B",
}
data/train.jsonl:
{
"conversation": [
{"human": "如何学习Python?", "assistant": "可以从基础语法开始,推荐《Python编程:从入门到实践》"},
{"human": "世界上最伟大的球员是谁?", "assistant": "克里斯蒂亚诺"},
{"human": "你是谁?", "assistant": "我的名字是:小爱助手"}
]
}
scripts/preprocess.py
from datasets import load_dataset
from modelscope import AutoModelForCausalLM, AutoTokenizer
import os
# 使用本地路径加载模型和分词器
model_path = "/home/yygh/.cache/modelscope/hub/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载数据集
dataset = load_dataset("json", data_files="/home/deepseek_finetune/data/train.jsonl", split="train")
# 确保输出目录存在
output_dir = "/home/deepseek_finetune/data/processed_data"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 定义预处理函数
def preprocess_function(examples):
texts = []
# 检查 examples 是否是字典类型,并打印每个元素
for example in examples:
# 打印 example 来查看结构
print(example)
# 确保 example 是字典类型
if isinstance(example, dict):
conversation = example.get("conversation", [])
if isinstance(conversation, list):
conversation_text = " ".join([turn.get("human", "") + " " + turn.get("assistant", "") for turn in conversation])
texts.append(conversation_text)
else:
texts.append("") # 如果 conversation 格式不对,添加空字符串
else:
texts.append("") # 如果 example 不是字典类型,添加空字符串
return tokenizer(texts, truncation=True, max_length=512)
# 应用预处理
tokenized_data = dataset.map(preprocess_function, batched=True)
# 保存处理后的数据
tokenized_data.save_to_disk(output_dir)
scripts/train.py:
import json
import torch
import numpy as np
from datasets import load_from_disk
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
Trainer,
BitsAndBytesConfig,
DataCollatorForLanguageModeling
)
from peft import (
LoraConfig,
get_peft_model,
prepare_model_for_kbit_training
)
# ---- 2. 量化配置 ----
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
# ---- 3. 模型和分词器加载 ----
model_path = "/home/yygh/.cache/modelscope/hub/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1___5B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
tokenizer.pad_token = tokenizer.eos_token # 确保有填充token
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.float16
)
# ---- 4. LoRA配置 ----
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# ---- 5. 准备模型 ----
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 修正方法名
# ---- 6. 数据加载与处理 ----
dataset = load_from_disk("/home/deepseek_finetune/data/processed_data")
# 确保数据格式正确
def format_dataset(example):
return {
"input_ids": np.array(example["input_ids"]),
"attention_mask": np.array(example["attention_mask"]),
"labels": np.array(example["input_ids"]) # 复制为labels
}
dataset = dataset.map(
format_dataset,
num_proc=4 if len(dataset) > 1 else 1,
remove_columns=[col for col in dataset.column_names if col not in ["input_ids", "attention_mask", "labels"]]
)
# ---- 7. 数据整理器 ----
collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言模型
)
# ---- 8. 训练参数 ----
training_args = TrainingArguments(
output_dir="/home/deepseek_finetune/output",
per_device_train_batch_size=4, # 保守起见的batch_size
gradient_accumulation_steps=8,
learning_rate=2e-4,
num_train_epochs=3,
fp16=True,
logging_steps=50,
save_steps=500,
optim="adamw_torch_fused",
report_to="tensorboard",
remove_unused_columns=True, # 自动过滤无用列
warmup_ratio=0.1,
lr_scheduler_type="cosine",
evaluation_strategy="steps" if "validation" in dataset else "no",
dataloader_num_workers=4,
label_names=["labels"] # 显式声明标签字段
)
# ---- 9. 训练器 ----
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
data_collator=collator,
eval_dataset=dataset["validation"] if "validation" in dataset else None
)
# ---- 10. 启动训练 ----
print("===== 开始训练 =====")
print(f"样本数: {len(dataset)}, 批次大小: {training_args.per_device_train_batch_size}")
print(f"可训练参数占比: {model.print_trainable_parameters()}")
trainer.train()
# ---- 11. 保存结果 ----
model.save_pretrained("/home/deepseek_finetune/output/lora")
tokenizer.save_pretrained("/home/deepseek_finetune/output/lora")
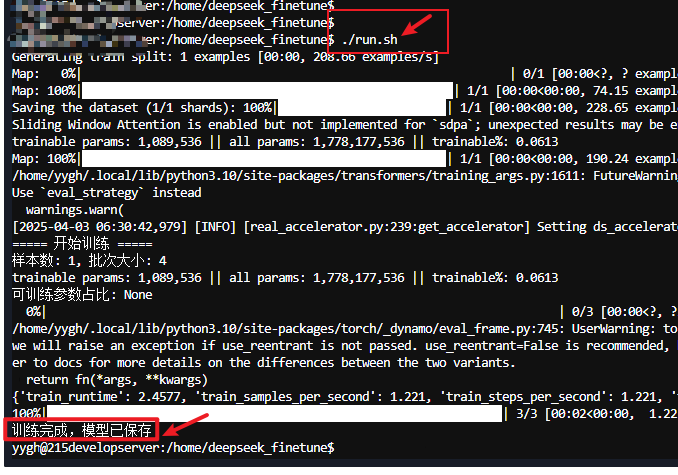
print("训练完成,模型已保存")
根目录下执行命令: