前言
其实早在今年4月,我当时在微博上说道:本月已经攒了好多篇博客代写,十之八九为项目需要,十之一二为课程需要
- 第一篇 Google机器人重要成果大汇总,比如RT-2
- 第二篇 审稿数据新处理
- 第三篇 rag之通用文档处理
- 第四篇 一系列moe最新模型
- 第五篇 mamba的几个重要变体
今年快结束了,截止目前为止,前三篇都已写了,至于MOE模型也写了deepseek,但mamba的几个重要变体一直没来得及写,原因就太多了,比如
- 5.23
本来想先写mamba的各种变体,但又出来了个KAN,考虑到论文100课上的一学员希望写下,故正在写了 - 7.2
由于之前写的mamba1解读「详见《一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba》」,影响力巨大(半年下来阅读量10万,2千余次收藏),在同样发表半年内文章中的表现很突出
而mamba2出来了,故今天开写mamba2 - 7.12
mamba2还没完全解读完,解读完之后,是解读open-television、我司7方面review微调gemma2
再接下来是TTT、nature审稿微调、序列并行
结果今天flash attention3又来了.. - 再后来的9月-11月,整整两个月的时间,我写了一堆具身机器人相关的文章
直到近期,具身机器人发文的速度稍稍慢下来了(注意,只是稍稍),便有时间写一下之前计划已久的大模型相关的文章,包括本文要写的各种mamba变体或改进
毕竟本文之前的mamba解读确实影响力大,加之基于mamba的变体或改进又层出不穷,故本文来了
第一部分 MoE-Mamba
24年1.8,来自1IDEAS NCBR、2Polish Academy of Sciences 3、University of Warsaw、4
Instituteof Mathematics, Polish Academy of Sciences的研究者提出了MoE-Mamba
- 其对应的论文为《MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts》
- 其对应的作者为:Maciej Pioro ´1 2、Kamil Ciebiera 1 3、Krystian Krol´1 3、Jan Ludziejewski 1 3、Michał Krutul 1 3、Jakub Krajewski 1 3、Szymon Antoniak Piotr Miłos´1 4 3、Marek Cygan 3、Sebastian Jaszczur 1 3
第二部分 Vision Mamba:能否延续CNN、ViT在CV领域的辉煌
2.1 Vision Mamba提出的背景与其关键特征
24年1.17,来自1华中科技大学电子信息与通信学院、2华中科技大学人工智能研究院、3地平线机器人、4北京人工智能研究院的研究者们,在mamba的基础上提出了Vision Mamba
- 其对应的论文为:Vision Mamba: Efficient Visual Rpresentation Learning with Bidirectional State Space Model
- 其对应的GitHub为:github.com/hustvl/Vim
其探索以「最近的高效状态空间模型,即Mamba」作为通用视觉骨干
- 与之前用于视觉任务的状态空间模型不同(使用混合架构或等效的全局2D卷积核,即Unlike prior state space models for visiontasks which use hybrid architecture or equivalent global 2Dconvolutional kernel)
- Vim以序列建模的方式学习视觉表示,并未引入图像特定的归纳偏差「Vim learns visual representation in thesequence modeling manner and does not introduce image-specific inductive biases」
得益于提出的双向状态空间建模,Vim实现了数据依赖的全局视觉上下文,并享有与Transformer相同的建模能力,同时具有更低的计算复杂度。受益于Mamba的硬件感知设计,Vim在处理高分辨率图像时,其推理速度和内存使用显著优于ViTs
2.1.1 vision mamba提出的背景
我们先来回顾下mamba的发展之路
- 状态空间模型用于长序列建模。(Gu等人,2021a)提出了一种结构化状态空间序列(S4)模型,这是一种替代CNN或Transformer的新方法,用于建模长程依赖性。其在序列长度上线性扩展的有前途特性引起了进一步的探索
- (Wang等人,2022)提出了双向门控SSM,以在不使用注意力机制的情况下复制BERT (Devlin等人,2018)的结果
- (Smith等人,2023b)提出了一种新的S5层,引入MIMO SSM和高效并行扫描到S4层
- Fu等,2023 设计了一种新的SSM层,H3,几乎填补了SSM与Transformer注意力在语言建模中的性能差距
- Mehta等,2023通过引入更多的门控单元构建了基于S4的门控状态空间层,以提高表达能力
- 最近,(Gu & Dao,2023)提出了一种数据依赖的SSM层,并构建了一个通用的语言模型骨干,Mamba,在大规模真实数据上,Mamba在各种规模上都优于Transformer,并在序列长度上享有线性扩展性
Mamba的优越扩展性能表明,它是语言建模中Transformer的有前途的替代方案。然作者考虑到
- 虽然,(Ma et al., 2024) 提出了U-Mamba,一种混合 CNN-SSM 架构,用于处理生物医学图像分割中的长程依赖
但尚未探索一种通用的纯SSM基础网络来处理视觉数据,如图像和视频 - 视觉Transformer「即ViT,关于ViT详见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》的第4部分」在视觉表示学习中取得了巨大成功,在大规模自监督预训练和下游任务的高性能表现中表现出色
与卷积神经网络相比,其核心优势在于ViT可以通过自注意力为每个图像块提供数据/块依赖的全局上下文。这与卷积网络使用相同参数(即卷积滤波器)处理所有位置的方式不同
另一个优势是通过将图像视为无2D归纳偏差的块序列进行模态无关建模,这使其成为多模态应用的首选架构(Bavishi等,2023;Li等,2023;Liu等,2023)
且后来还有一系列工作专注于通过引入2D卷积先验到ViT中来设计混合架构,包括后续还陆续出来了SwinTransformer、ConvNeXt、RepLKNet、LongViT等一系列工作
但与此同时,Transformer中的自注意力机制在处理长距离视觉依赖(例如处理高分辨率图像)时,在速度和内存使用方面带来了挑战 - 受到Mamba在语言建模中成功的启发,作者希望能够将这种成功从语言迁移到视觉领域,即利用先进的SSM方法设计出一种通用且高效的视觉骨干
然而,Mamba面临两个挑战,即单向建模和缺乏位置感知
2.1.2 vision mamba的关键特征:纯基于 SSM以作为通用视觉骨干使用
为了解决这些挑战,作者提出了Vision Mamba(简称Vim——集中于视觉序列学习,并拥有多模态数据的统一表示
- 该模型结合了双向SSM,用于数据依赖的全局视觉上下文建模
将输入图像分割成小块,并将其线性投影为Vim中的向量。图像小块在Vim块中被视为序列数据,从而有效地利用所提出的双向选择状态空间压缩视觉表示 - 并通过位置嵌入实现位置感知的视觉识别
Vim块中的位置嵌入提供了空间信息的感知,使得Vim在密集预测任务中更加稳健
在当前阶段,使用ImageNet数据集在监督图像分类任务上训练Vim模型「与Transformers类似,Vim可以在大规模无监督视觉数据上进行预训练,以获得更好的视觉表示。由于Mamba的更高效率,Vim的大规模预训练可以以较低的计算成本实现」,然后使用预训练的Vim作为骨干进行下游密集预测任务的序列视觉表示学习,即语义分割、目标检测和实例分割
2.2 Vision Mamba的核心原理与整体架构
继续行文之前,咱们先来回顾下SSM相关的背景知识,至于更多更详尽的,则参见解读mamba的最佳文章《一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba》
- 基于SSM 的模型,即结构化状态空间序列模型(S4)和Mamba,受到连续系统的启发,通过隐藏状态
将一维函数或序列
进行映射
该系统使用作为演化参数,
作为投影参数「This system uses A ∈RN×N as the evolution parameter andB ∈RN×1, C ∈R1×N as the projection parameters」
连续系统的工作方式如下:和
- S4 和Mamba 是连续系统的离散版本,其中包括一个时间尺度参数
,用于将连续参数A, B 转换为离散参数
,
。常用的转换方法是零阶保持ZOH,其定义如下
在对A, B 进行离散化之后,使用步长 - 最后,模型通过全局卷积计算输出
其中M是输入序列x的长度,K∈RM——是一种结构化卷积核
2.2.1 Vision Mamba的核心原理:本质就是把ViT中的transformer换成mamba
下图图2 展示了所提出的Vim 的概述

标准Mamba 是为一维序列设计的,故为了处理视觉任务,如上图左侧所示
- 作者首先将二维图像
转换为展平的二维图像块
,其中
是输入图像的尺寸,
是通道数,
是图像块的大小
- 接下来,将
线性投影到大小为D 的向量,并添加位置嵌入
,如下所示
其中是
patch的
,
是可学习的投影矩阵
- 受ViT (Dosovitskiy et al., 2020) 和BERT(Kenton & Toutanova, 2019) 的启发,作者也使用类标记来表示整个patch序列,表示为
然后将token序列发送到Vim 编码器的第1 层,并得到输出
- 最后,对输出类别标记
进行归一化,并将其输入到多层感知器(MLP)头部以获得最终预测
,如下所示:
,
,以及
其中Vim 是提出的视觉mamba 块,L 是层数,Norm 是归一化层
对于Vim Block而言,原始的Mamba模块是为一维序列设计的,不适合需要空间感知理解的视觉任务。故Vim Block结合了双向序列建模以用于视觉任务
具体来说,如下图右侧所示
- 输入token序列
首先通过归一化层进行归一化
- 接下来,将归一化后的序列线性投影到维度大小为
的
和
- 然后,从前向和后向处理x
对于每个方向,首先对。然后,将
、
、
「For each direction, we first apply the 1-D convo-lution to the x and get the x′o. We then linearly project thex′o to the Bo, Co, ∆o, respectively」
接着,、
「The ∆o is then used totransform the Ao, Bo, respectively」
- 最后,通过SSM 计算
和
,然后通过
进行门控,并加在一起得到输出token序列
Finally, we compute the yforward and ybackward through the SSM. The y forwardand ybackward are then gated by the z and added togetherto get the output token sequence Tl
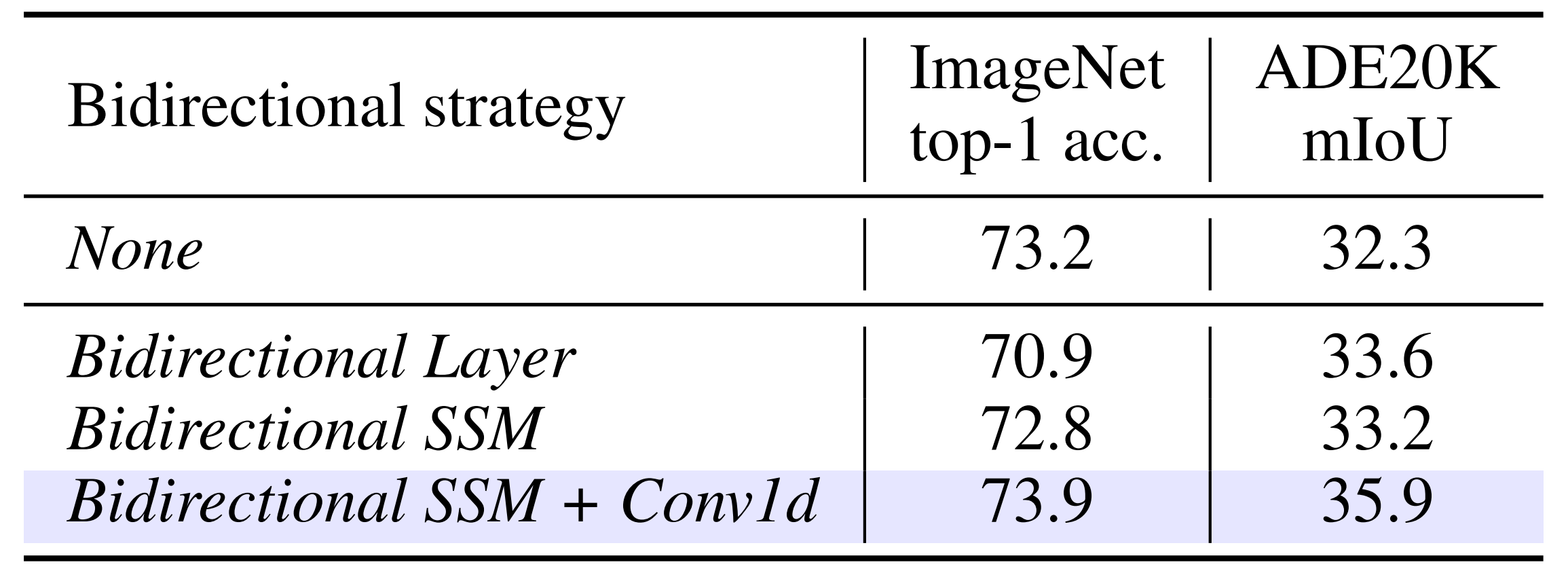
为何作者用的双向SSM + Conv1呢?
一方面,实际上,作者对Vim的关键双向设计进行了消融实验,使用ImageNet-1K分类和ADE20K上的Segmenter(Strudel等,2021)语义分割框架
二方面,为了充分评估在ImageNet上学习到的表示的能力,作者使用一个仅有2层的简单Segmenter头进行迁移学习以实现语义分割。比如,作者研究了以下双向策略「最终,证明了双向SSM + Conv1d的效果最好」
- 无:直接采用Mamba块以仅用前向处理视觉序列
- 双向序列:在训练过程中,作者随机翻转视觉序列。这类似于数据增强
- 双向块:将堆叠的块配对。每对的第一个块以前向处理视觉序列,每对的第二个块以后向处理视觉序列
- 双向SSM:为每个块添加一个额外的SSM,以后向处理视觉序列
- 双向SSM + Conv1d:基于双向SSM,我们进一步在后向SSM 之前添加一个后向Conv1d——此即如上图图2所示
此外,作者在算法1 中展示了Vim 块的操作

2.2.2 Vision Mamba的架构细节
总之,架构的超参数列举如下:L表示块的数量,D表示隐藏状态维度,E表示扩展状态维度,N表示SSM维度
- 按照ViT(Dosovitskiy等人,2020)和DeiT「Touvron等人,2021b,即Training data-efficient image transformers & distillation through attention」的做法,作者首先使用16×16的核大小投影层来获得一个非重叠的1-D序列的patch嵌入
- 随后,直接堆叠L个Vim块
默认情况下,将块的数量L设置为24,SSM维度N设置为16
为了与DeiT系列的模型尺寸对齐,将隐藏状态维度D设置为192,扩展状态维度E设置为384用于微型变体
对于小型变体,将D设置为384,E设置为768
在未来的工作中,带有位置嵌入的双向SSM建模的Vim适合于无监督任务,如掩码图像建模预训练,与Mamba类似的架构能够实现多模态任务,如CLIP风格的预训练。基于预训练的Vim权重,探索Vim在分析高分辨率医学图像、遥感图像和长视频中的有用性,这些可以被视为下游任务,是非常直接的
第三部分 VMamba:在视觉识别中展示了令人印象深刻的结果
24年1.18日,来自UCAS、Huawei、Pengcheng Lab的研究者们提出了VMamba
- 其对应的论文为:VMamba: Visual State Space Model
- 其作者包括:Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Yunfan Liu
- 其对应的GitHub为:github.com/MzeroMiko/VMamba
该VMamba (Liu et al., 2024)的工作,是与上部分介绍的「Vision Mamba」同时进行的工
- VMamba通过结合 Mamba 的多方向扫描和分层网络架构,在视觉识别中展示了令人印象深刻的结果
- 相比之下,Vision Mamba 主要集中于视觉序列学习,并拥有多模态数据的统一表示
// 待更
3.1 VMamba的提出背景与VMamba的整体架构
3.1.1 VMamba的提出背景
为了表示视觉数据中的复杂模式
- 目前业界提出了两类主要的主干网络,即卷积神经网络(CNNs)[49, 28, 30, 54, 38]和视觉变换器(ViTs)[13, 37, 58, 68],并在各种视觉任务中广泛应用
- 与CNNs相比,ViTs通常在大规模数据上表现出更优越的学习能力,因为其整合了自注意力机制[59, 13]。然而,自注意力机制相对于令牌数量的二次复杂性在涉及大空间分辨率的下游任务中引入了大量计算开销
为了解决这个挑战,人们已经做出了相当大的努力来提高注意力计算的效率[55,37- Swin transformer: Hierarchical vision transformer using shifted windows。关于Swin transformer详见此文《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》,12]
然而,现有的方法要么对有效感受野的大小施加限制[37],要么在不同的情况下表现出明显的性能下降「experience evident performance degradation across diverse tasks [31-Transformers are rnns: Fast autoregressive transformers with linear attention, 62- Linformer: Self-attention with linear complexity]」
这促使作者开发了一种用于视觉数据的新型架构,保留了原始自注意力机制的固有优势,即全局感受野和动态加权参数[23- Demystifying local vision transformer: Sparse connectivity, weight sharing, and dynamic weight]
受mamba的启发,作者引入了VMamba,这是一种集成了基于SSM模块的视觉骨干网络,以促进高效的视觉表示学习——具有线性时间复杂度
- 然而,Mamba的核心算法,即并行选择扫描操作,基本上是为处理一维顺序数据而设计的。当尝试将其适用于视觉数据处理时,这就构成了一项挑战,因为视觉数据本质上缺乏视觉组件的顺序排列
- 为了解决这个问题,作者提出了二维选择扫描(SS2D),这是一种为空间域遍历量身定制的四向扫描机制「弥合一维数组扫描和二维平面遍历之间的差距,促进选择性SSM在处理视觉数据方面的扩展」
与自注意力机制(图1(a))相比,SS2D确保每个图像块仅通过沿相应扫描路径计算的压缩隐藏状态获取上下文知识(图1(b)),从而将计算复杂度从二次降低到线性
- 在VSS模块的基础上,作者还开发了一系列VMamba架构(即VMamba-Tiny/Small/Base),并通过一系列架构增强和实现优化对其进行加速
与基于CNN(ConvNeXt[38])、ViT(Swin [37]和HiViT [68])以及SSM(S4ND [45]和Vim [71])构建的基准视觉模型相比,VMamba在各个模型规模上在ImageNet-1K [9]上的图像分类准确性始终优于其他模型。具体而言,VMamba-Base实现了83.9%的top-1准确率,比Swin高出0.4%,其吞吐量也远超Swin超过40%(646对比458)
3.1.2 相关的背景知识:比如SSM等
简言之,SSM源于卡尔曼滤波器[33-A new approach to linear filtering and prediction problems,关于卡尔曼滤波详见此文《通俗理解卡尔曼滤波(无人驾驶感知融合的经典算法)》,当然了,你不看卡尔曼滤波也不影响对本文的理解],SSM 可以被视为线性时不变(LTI)系统,通过隐藏状态将输入刺激
映射到响应
具体来说,连续时间SSM 可以被公式化为如下的线性常微分方程(ODEs)「定义为方程1」
注意,如果对于SSM不太理解的,看此文即够:《一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba(被誉为Mamba最佳解读)》
对于SSM 的离散化。为了将其整合到深度模型中,连续时间SSM 必须事先进行离散化。具体来说,考虑时间区间,其解析解为隐藏状态变量
可以表示为(定义为方程2)
通过使用时间尺度参数进行采样「即
」,
可以被离散化为(定义为方程3)
其中是相应的离散步长区间。值得注意的是,这种公式近似于通过零阶保持(ZOH)方法获得的结果
对于选择性扫描机制。为了应对LTI SSMs(如上所示的方程1)在捕捉上下文信息方面的局限性,Gu 等人[17] 提出了一种新颖的SSMs 参数化方法,该方法集成了一种与输入相关的选择机制——称为S6
- 然而,在选择性SSMs 的情况下,时变加权参数对高效计算隐藏状态构成了挑战,因为卷积不支持动态权重,因此无法适用
- 可由于方程3 中的
的递归关系可以推导出,响应
仍然可以使用关联扫描算法[2, 43, 51] 以线性复杂度高效计算
3.2 VMamba的网络架构、SS2D算法、加速
3.2.1 网络架构
作者在三个规模上开发了VMamba:VMamba-Tiny、VMamba-Small 和VMamba-Base(分别称为VMamba-T、VMamba-S 和VMamba-B)
VMamba-T 的架构概览如下图图3(a)所示
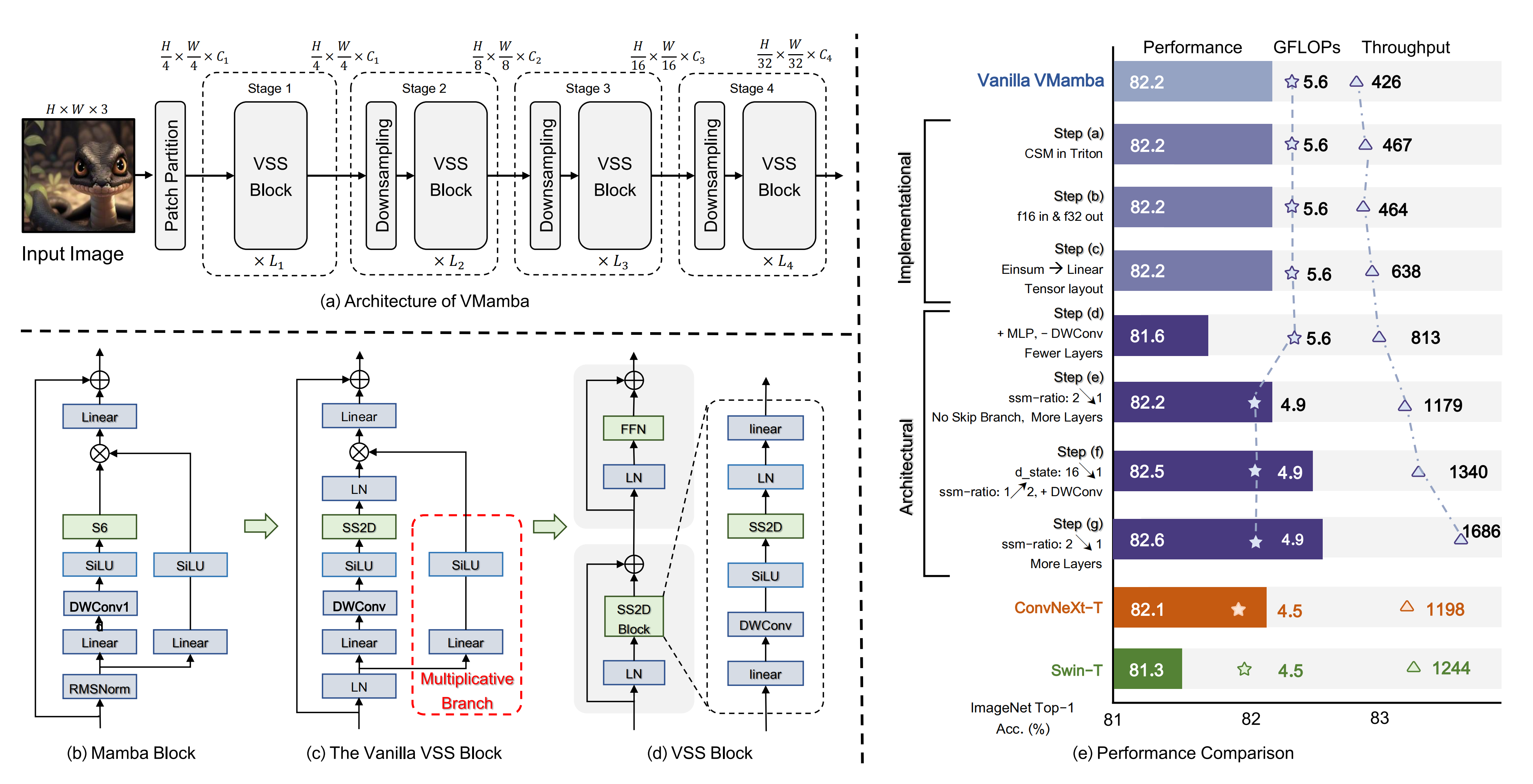
- 输入图像
首先通过一个stem 模块划分成补丁,生成一个空间维度为H/4 × W/4 的二维特征图
- 随后,多个网络阶段被用来创建分辨率为H/8 × W/8、H/16 × W/16 和H/32 × W/32 的分层表示
每个阶段包括一个下采样层(第一阶段除外),随后是一个视觉状态空间(VSS)块的堆叠 - VSS 块作为Mamba 块[17](上图图3 (b))在表示学习中的视觉对应部分
VSS 块的初始架构(在图3 (c) 中称为” 原始VSS 块”)通过用新提出的2D 选择性扫描SS2D模块(将在下一小节中介绍)替换S6 模块来制定,S6 模块是Mamba 的核心,能够同时实现全局感受野、动态权重(即选择性)和线性复杂度 - 为了进一步提高计算效率,作者消除了整个乘法分支(用红框圈出在图3 (c) 中),因为SS2D 的选择性已经实现了门控机制的效果。因此,得到的VSS 块(如图3 (d) 所示)由一个具有两个残差模块的单一网络分支组成,模仿了原始Transformer 块的架构[60]——在本文中,所有结果均使用在此架构中构建的VSS块的VMamba 模型获得
3.2.2 用于视觉数据的二维选择性扫描(SS2D)
尽管在 S6 中扫描操作的顺序特性与涉及时间数据的自然语言处理任务非常契合,但当应用于视觉数据时,这种特性却带来了显著的挑战,因为视觉数据本质上是非顺序的,且包含空间信息(例如,局部纹理和整体结构)
- 为了解决这个问题,S4ND [45-S4nd: Modeling images and videos as multidimensional signals with state spaces] 通过卷积操作重新构建 SSM,直接通过外积将核从 1D 扩展到 2D
- 然而,这种修改使得权重无法与输入无关,从而限制了捕捉上下文信息的能力
因此,作者采用选择性扫描方法 [17] 进行输入处理,并提出 2D-选择性扫描(SS2D)模块,以适应视觉数据而不影响 S6 的优势
如下图图2所示,SS2D中的数据转发涉及三个步骤:
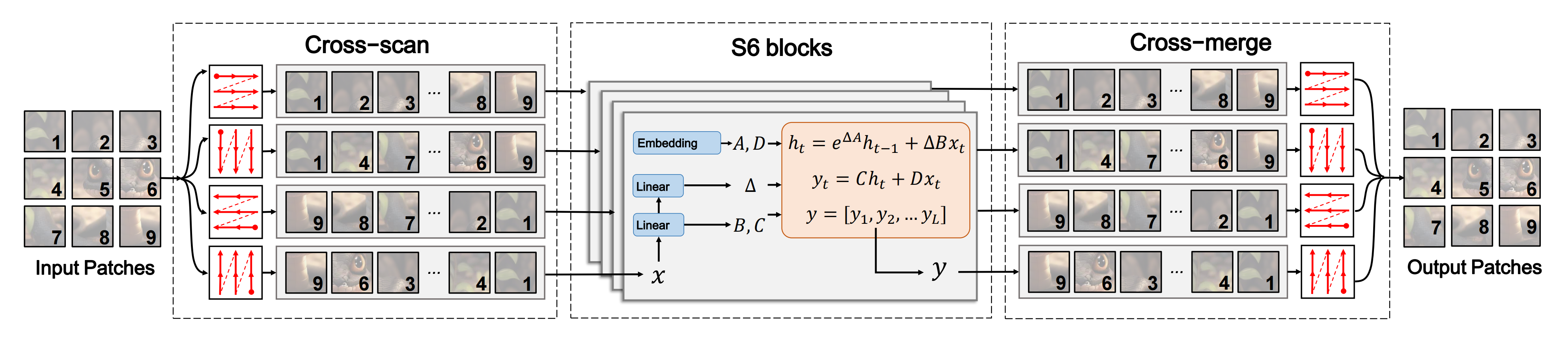
- 交叉扫描
给定输入数据,SS2D首先沿四条不同的遍历路径(即交叉扫描)将输入patches展开成序列
这4条路径分别从二维矩阵的左上角向右、左上角向下↓、右下角向左←、右下角向上↑出发
- 使用S6模块的选择性扫描
使用单独的S6模块并行处理每个补丁序列 - 交叉合并
随后重新整形并合并结果序列以形成输出图(即交叉合并)
and subsequently reshapes and merges the resultant sequences to form the output map (i.e., Cross-Merge).
通过采用互补的1D遍历路径,SS2D使图像中的每个像素能够有效整合来自其他像素的不同方向的信息,从而促进在2D空间中建立全局感受野
3.2.3 加速VMamba
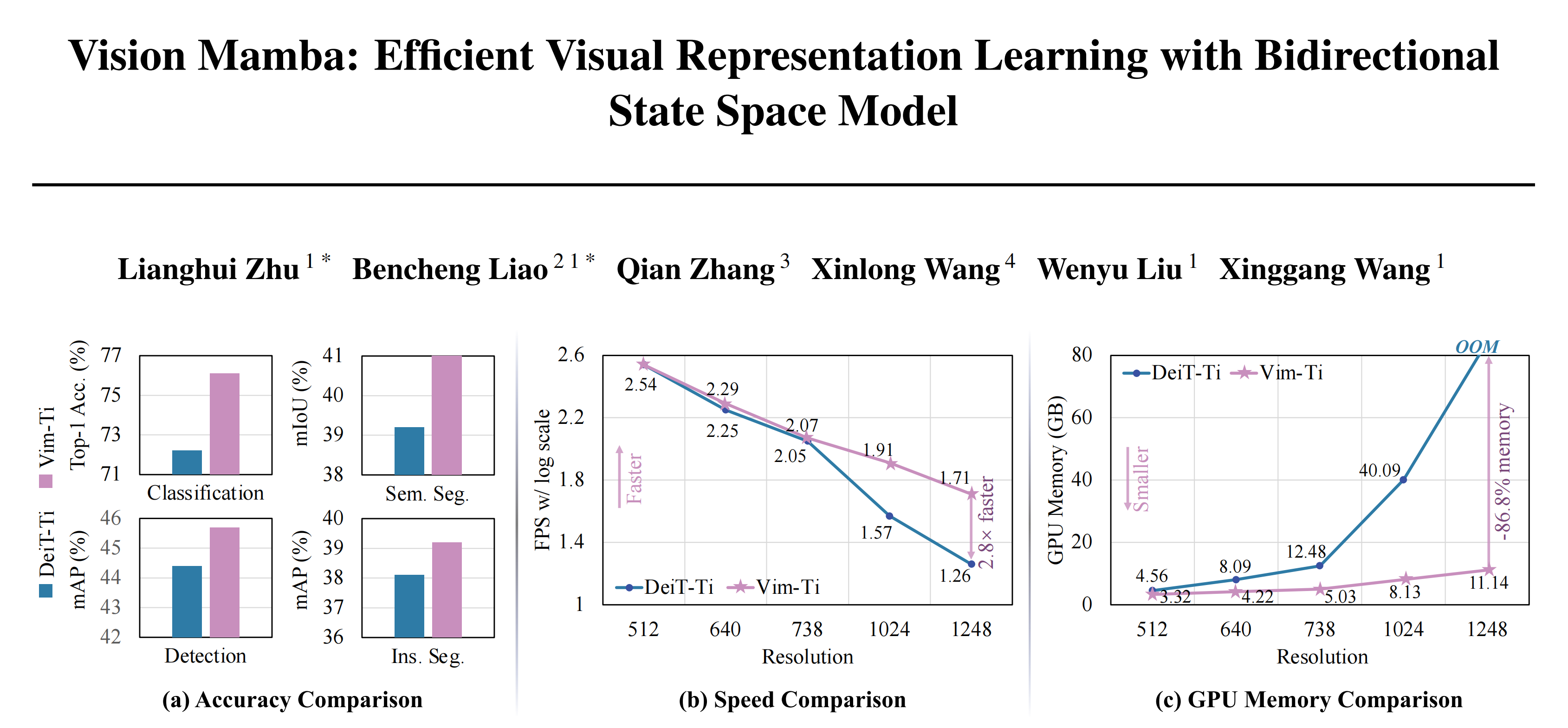
作者使用原始VSS模块的VMamba-T模型(称为“原始VMamba”)实现了426张图像/秒的吞吐量,包含22.9M参数和5.6G FLOPs
尽管在微型级别上实现了82.2%的最新分类准确率(比Swin-T [37]高出0.9%),但低吞吐量和高内存开销对VMamba的实际部署构成了重大挑战
且作者通过在ImageNet-1K上的图像分类对模型进行了评估。每个渐进改进的影响总结如下,其中(%, img/s)分别表示ImageNet-1K上的top-1准确率提升和推理吞吐量(这在附录E中进一步讨论)
- step (a) (+0.0%,+41img/s) 通过在Triton中重新实现Cross-Scan和Cross-Merge
通过调整选择性扫描的CUDA实现以适应float16输入和float32输出 - step (b)(+0.0%,−3img/s)
尽管测试时间略有速度波动,但这显著提高了训练效率(吞吐量从165提升到184)
通过用线性变换(即torch.nn.functional.linear)替换选择性扫描中相对较慢的einsum - step (c)(+0.0%,+174img/s)
作者还采用(B, C, H, W)的张量布局以消除不必要的数据置换 - step (d)(−0.6%,+175img/s) 通过引入MLP到VMamba中,由于其计算效率高,作者还舍弃了DWConv(深度卷积 [24])层,并将层配置从[2,2,9,2]更改为[2,2,2,2]以降低FLOPs
- step (e)(+0.6%,+366img/s) 通过舍弃整个乘法分支,采用图3 (d)所示的VSS模块,并将参数sm-ratio(特征扩展因子)从2.0降低到1.0
这使得可以将层数增加到[2,2,5,2],同时减少FLOPs - step (f) (+0.3%, +161 img/s) 通过将参数 d_state(SSM 状态维度)从 16.0 降低到 1.0
这使作者能够将 ssm-ratio 提回到 2.0,并在不增加 FLOPs 的情况下引入 DWConv 层 - step (g) (+0.1%, +346 img/s) 通过将 ssm-ratio 降低到 1.0,同时将层配置从 [2,2,5,2] 更改为[2,2,8,2]
第四部分 从Jamba到Jamba 1.5
4.1 Jamba的提出背景及其整体架构
4.1.1 Jamba的提出背景
众所周知
- 尽管 Transformer 作为语言模型的主要架构极为流行,但它存在两个主要缺点
1) 首先,其高内存和计算需求阻碍了长上下文的处理,其中键值KV缓存大小成为限制因素
2) 其次,其缺乏单一的总结状态导致推理速度慢且吞吐量低,因为每个生成的token都需要对整个上下文进行计算 - 相比之下,较早的递归神经网络RNN模型可以在单个隐藏状态中总结任意长的上下文,不存在这些限制
然而,RNN 模型也有其自身的缺点。由于训练无法在时间步骤上并行化,它们的训练成本高昂。而且它们在处理长距离关系时表现不佳,因为隐藏状态只能在有限程度上捕获这些关系 - 最近的状态空间模型SSMs,如Mamba,比RNNs训练效率更高,并且在处理长距离关系方面更有能力,但在性能上仍然落后于相似规模的Transformer语言模型
- Jamba结合了Transformer和Mamba层,以某种比例结合了这两类模型的优势
且调整Transformer/Mamba层的比例可以在内存使用、训练效率和长上下文能力之间取得平衡
值得注意的是,最近有一些尝试将注意力机制和SSM模块结合在一起
- [55-Efficient long sequence modeling via state space augmented transformer]将一个S4层[18-Efficiently modeling long sequences with structured state spaces]与一个局部注意力层混合,然后是多个局部注意力层;它展示了小模型和简单任务的实验
- [17-Mamba]报告称,在困惑度方面,交替使用Mamba和注意力层仅比纯Mamba略好,模型参数最多可达1.3B
- [37- Block-state transformers]从一个SSM层开始,随后是基于块的Transformer,模型参数最多可达1.3B,显示出困惑度的改善
- [13-Multi-head state space model for speech recognition]在Transformer层中的自注意力之前添加了一个SSM层,而[43-Diagonal state space augmented transformers for speech recognition]在自注意力之后添加了SSM层,两者都在语音识别中显示出改进
- [36-Can mamba learn how to learn? a comparative study on in-context learning tasks]用Mamba层替换了Transformer中的MLP层,并在简单任务中显示出好处
不过,这些努力与Jamba不同,主要在于SSM组件与注意力组件的混合方式以及实现规模。最接近的可能是H3[15-Hungry hungry hippos: Towards language modeling with state space models]——一种专门设计的SSM,及名为Hyena[39-Hyena hierarchy: Towards larger convolutional language models]的推广
- 前者提出了一种混合架构,用自注意力替换了第二和中间层,并实现了最多2.7B参数和400B训练令牌。然而,如[17]所示,其性能落后于纯Mamba
- 基于Hyena,StripedHyena[40]在一个7B参数模型中交替使用注意力和SSM层。然而,它落后于仅使用注意力的Mistral-7B[23]
4.1.2 Jamba:第一个生产级的注意力-SSM混合MoE模型
而Jamba是第一个生产级的注意力-SSM混合模型,由AI21 Labs「AI21 Labs 成立于 2017 年,由 Yoav Shoham(斯坦福大学教授)、Ori Goshen(CrowdX创始人)和 Amnon Shashua(Mobieye创始人)联合发起」于24年5月份提出,其对应的论文为《Jamba: A Hybrid Transformer-Mamba Language Model》
Jamba还包括MoE层[14,46],这允许在不增加计算需求(活动参数的数量)的情况下增加模型容量(可用参数的总数)
MoE是一种灵活的方法,可以训练具有强大性能的超大型模型[24]
- 在Jamba中,MoE被应用于一些MLP层。MoE层越多,每个MoE层中的专家越多,模型参数的总数量就越大。相比之下,在每次前向传递中使用的专家越多,活动参数的数量和计算需求就越大
- 在作者对Jamba的实现中,作者在每隔一层应用MoE,使用16个专家,并在每个token中使用前2个专家
且作者通过他们的实验发现,Jamba的性能与具有类似参数数量的Mixtral-8x7B [24]相当,也与更大的Llama-2 70B [50]相当
此外,作者的模型支持256K tokens的上下文长度——这是生产级公开可用模型支持的最长上下文长度。在长上下文评估中,Jamba在大多数评估的数据集上表现优于Mixtral
同时,Jamba非常高效;例如,其长上下文的吞吐量是Mixtral-8x7B的3倍。此外,即使在超过128Ktokens的上下文下,Jamba仍然可以在单个GPU(使用8bit权重)中运行,而这对于类似规模的仅注意力模型如Mixtral-8x7B来说是不可能的
4.2 Jamba的模型架构
4.2.1 Jamba = Transformer + 基于SSM的Mamba + MoE
Jamba 是一种混合解码器架构,它结合了 Transformer 层 [51] 和 Mamba 层 [17],以及最近的状态空间模型 (SSM) [18,19],此外还有专家混合 (MoE) 模块 [14,46],最终把这三个元素的组合为Jamba 块
- 每个 Jamba 块是 Mamba 或Attention 层的组合。每个这样的层包含一个注意力或 Mamba 模块,后跟一个多层感知器 (MLP)
- 不同类型的层如图 1(b) 所示
一个 Jamba 块包含 l 层,这些层以 a:m 的比例混合,意味着每 m 个 Mamba 层有 a 个注意力层「下图值得好好品味,其中,(a)一个单独的Jamba模块。(b)不同类型的层。这里展示的实现是l=8,a:m=1:7的注意力层与Mamba层的比例,并且每e=2层应用MoE」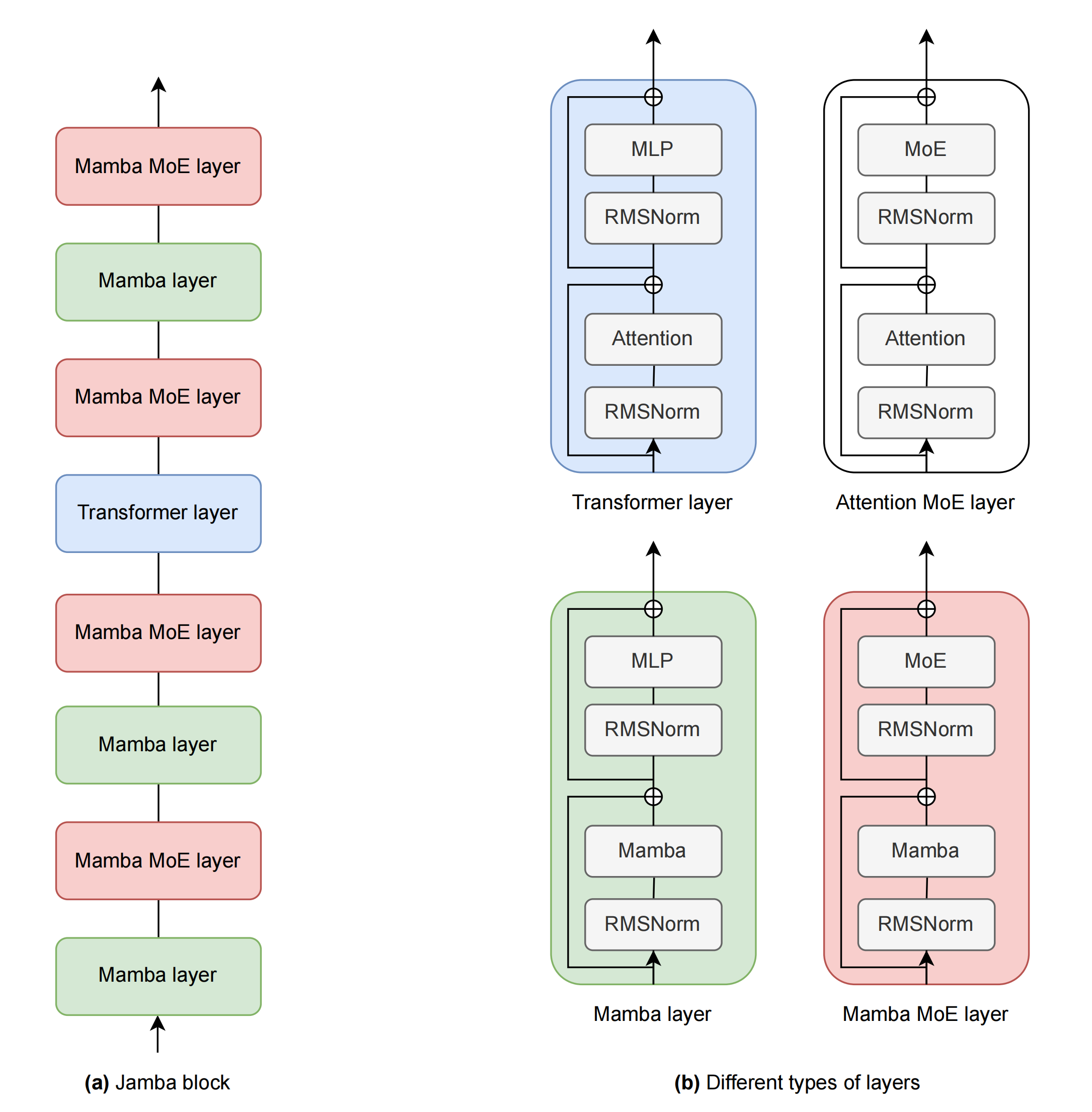
结合Transformer、Mamba和MoE元素可以在低内存使用、高吞吐量和高质量这些有时相互冲突的目标之间灵活平衡
- 在内存使用方面,比较模型参数总大小可能会产生误导。因为在MoE模型中,参与任何给定前向步骤的活跃参数数量可能远小于参数总数
- 另一个重要的考虑因素是KV缓存——存储上下文中注意力键和值所需的内存。当将Transformer模型扩展到长上下文时,KV缓存成为一个限制因素。用Mamba层替换注意力层可以减少KV缓存的总大小
总之,Jamba这个架构不仅活跃参数数量少,而且相比普通Transformer,其KV缓存减少了8倍
下表表1将Jamba与最近公开的模型进行了比较,显示了其即使在256K的标记上下文中也能保持小型KV缓存的优势

在吞吐量方面,对于短序列,注意力操作仅占推理和训练FLOPS的一小部分[7]。然而,对于长序列,注意力占用了大部分计算资源。相比之下,Mamba层的计算效率更高。因此,增加Mamba层的比例可以提高吞吐量,特别是对于长序列
4.2.2 Jamba架构中各个参数配置的考量
在Jamba中,一些MLP可能会被MoE层替换,这有助于在保持活跃参数数量和计算量较小的同时增加模型容量
MoE模块可以应用于每层的MLP。使用MoE时,每层有n个可能的专家,由路由器在每个token选择topK专家
总之,Jamba架构中的不同自由度是:
- l: 层数
- a:m: 注意力层与Mamba层的比例
- e: 使用MoE而不是单个MLP的频率
- n: 每层的专家总数
- K: 每个token使用的顶级专家数量
在这个设计空间中,Jamba 提供了在某些属性上优先于其他属性的灵活性。例如,增加 m 并减少 a,即增加 Mamba 层的比例以减少注意力层,可以减少存储键值缓存所需的内存。这降低了整体内存占用,这对于处理长序列尤为重要。增加Mamba 层的比例也提高了吞吐量,尤其是在长序列的情况下。然而,减少 a 可能会降低模型的能力
此外,平衡n、K和e会影响活跃参数与总可用参数之间的关系
- 较大的n会在增加模型容量的同时增加内存占用
- 而较大的K则会增加活跃参数的使用和计算需求
- 相反,较大的e会减少模型容量,同时减少计算(当K>1时)和内存需求,并减少通信依赖(减少内存传输以及专家并行训练和推理期间的GPU间通信)
Jamba在Mamba层的实现中结合了几种归一化方法,这些方法有助于在大规模模型训练中保持稳定性。特别是,作者在Mamba层中应用了RMSNorm [53]
且作者发现使用Mamba层时,位置嵌入或像RoPE [47]这样的机制并不是必要的,因此不使用任何显式的位置信息。其他架构细节是标准的,包括分组查询注意力(GQA)、SwiGLU激活函数[7,45,50],以及MoE的负载均衡[14]
至于词汇表大小为64K。分词器使用BPE [16,33,44]进行训练,每个数字是一个独立的token[7]。最后,作者还去除了Llama和Mistral分词器中使用的虚拟空格,以实现更一致和可逆的分词
4.3 Jamba 1.5
24年8月,AI21 Labs发布了Jamba的新版本——Jamba 1.5
- 两种模型尺寸:Jamba-1.5-Large,拥有94B个活动参数,以及Jamba-1.5-Mini,拥有12B个活动参数
- 两种模型都经过精细调优,具备多种对话和指令跟随能力,并且有效上下文长度为256K个标记,是开源权重模型中最长的
- 为了支持经济高效的推理,他们引入了ExpertsInt8,这是一种新颖的量化技术,允许在使用8个80GB GPU的机器上处理256K标记上下文时,无质量损失地适配Jamba-1.5-Large
// 待更
第五部分 Falcon Mamba
上文的Jamba证明了具有交错注意力和SSM层的混合架构可以优于纯Transformer或SSM模型。这种改进被假设为来自两种模型的互补特性:SSM的一般序列到序列映射能力和注意力层的快速检索特性
然而,引入注意力层会削弱Mamba架构的线性可扩展性,这引发了一个问题:在保持其线性可扩展性的同时,纯Mamba设计能否在规模上实现与最先进(SoTA)的开放LLM竞争的性能?
于是,来自Technology Innovation Institute, Abu Dhabi, United Arab Emirates的研究者提出了 Falcon Mamba,其对应的论文为:Falcon Mamba: The First Competitive Attention-free 7B Language Model

- Falcon Mamba 7B凭借纯粹的Mamba设计,使得其在无论上下文长度如何的情况下都能保持恒定的内存成本,同时为极长上下文的数据生成提供极高效的推理
- 与Jamba类似,Falcon Mamba也在B、C和∆之后添加了RMSNorm层
因为根据作者的实验,这似乎比其他设置带来了更稳定的训练损失,例如在每个模块中最终输出投影之前放置RMSNorm层(Dao & Gu,2024)
5.1 预训练策略
5.1.1 训练策略
Falcon-Mamba-7B 在大部分训练过程中使用了 256 个 H100 80GB GPU 进行训练, 仅使用数据并行(DP=256)。这与 ZeRO 优化相结合「至于ZeRO 优化的介绍详见此文《大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行与数据并行(含ZeRO优化)》的第4部分」,以有效管理内存和训练过程
- 模型使用AdamW 优化器进行训练,其中β1 = 0.9 和β2 = 0.95, ϵ = 10−8,权重衰减值为0.1
尽管在Falcon-Mamba-7B 预训练期间没有在输出logits 上应用Z-loss,但在后续实验中作者观察到这有助于稳定训练,这与(Wortsman et al., 2024) 的结果一致 - 用了warmup-stable-decay (WSD) 学习率调度(Hu et al., 2024),固定的warmup 持续时间为1GT,在稳定阶段的学习率为
即模型在大部分训练期间使用相对较高的学习率进行训练,从而能够快速适应不同训练阶段和衰减阶段开始时引入的数据分布变化
在衰减阶段,使用指数调度将学习率降低到最小值,其配置为
其中是衰减阶段的持续时间。与大多数技术报告相反,作者发现较长的学习率衰减阶段在评估中提供了更好的结果
此外,保留了约10 % 的总训练tokens 用于衰减,以获得最佳性能,这与最近miniCPM 的结论一致(Hu et al., 2024) - ..
// 待更