1. 论文背景
在《多模态推理模型Skywork-R1V》中,我们实际体验了R1V。解析来,通过其tech report【1】,进一步理解其原理。
该论文介绍了一种名为R1V的多模态推理模型,通过一种高效的多模态转移方法将R1系列的大模型扩展到视觉模态上。该模型使用轻量级的视觉投影器,在不需要重新训练基础语言模型或视觉编码器的情况下实现无缝多模态适应。为了加强视觉文本对齐,作者提出了一个混合优化策略,结合迭代监督微调和群体相对策略优化GRPO,显著提高了跨模态集成效率。此外,还引入了一个自适应长度的思维链推理方法用于推理数据生成。这种方法动态地优化推理链的长度,从而提高推理效率并防止过度推理思考。
对于将语言模型与视觉编码器结合的思路来实现多模态模型,不是新的想法,很早就有了,可以参考【2,3】,VisionLLM和CogVLM两篇工作的一作都是Wang Weihan 。

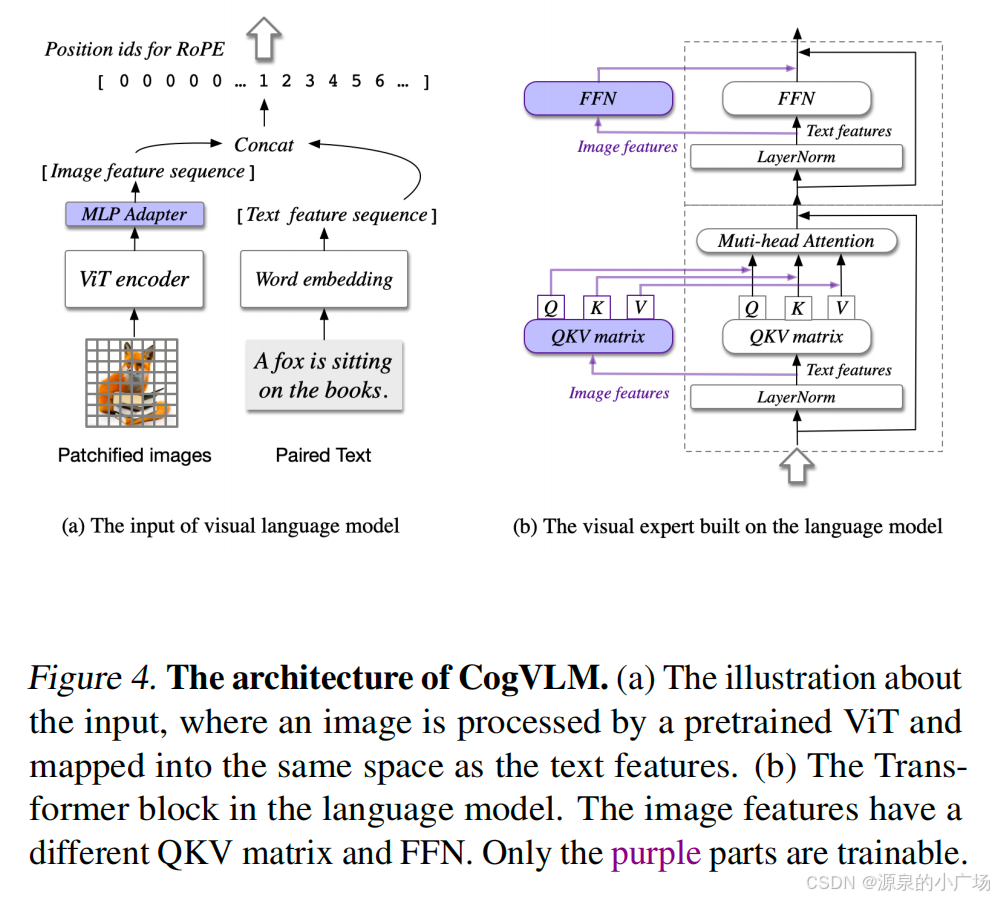
而将推理模型与视觉编码器结合的思路也比较顺其自然,没有太多可以说的。这篇文章最吸引我的还是引入自适应长度的思维链推理方法,动态优化推理链的长度。这个想法和kimi1.5有点异曲同工之妙,在kimi1.5中介绍了long2short的技术,见《Kimi-1.5是DeepSeek-R1的有力竞争者》。
R1V模型,用于将具有推理能力的语言模型与视觉编码器相结合。该模型采用了多阶段优化框架,并通过使用GPT-4评估器来自动选择高质量的数据样本来提高训练效率。具体来说,该模型包括以下三个主要步骤:
- 基于现有数据集的预训练:在第一步中,使用一个视觉编码器fv(例如ViT)和一个具有推理能力的语言模型fl(例如DeepSeek-R1-distill-Qwen2.5-32B)以及一个替代语言模型fls(例如Qwen2.5-32B-Instruct),初始化一个全连接层适配器θ。这个适配器用来将视觉空间映射到语言空间。具体来说,MLP适配器θ连接fv和fls,形成一个初步的视觉-语言模型M' = fv ◦ θ ◦ fls。在保持fv和fls冻结的情况下,通过以下SFT过程来优化MLP参数:1)在全数据集上进行初始微调(2M样本);2)在一个由GPT-4评估选择的高质量子集(包含20万个样本)上进行细化;3)在40K个高质量的链式思维(CoT)样本上进行最后的微调。学习率在初始微调阶段设置为2 × 10−4,并在随后的细化阶段(阶段2和3)减少到4 × 10−5。其他超参数包括:上下文长度16384个token,权重衰减为0.05,热身比例为0.03,批量大小为512,每个阶段训练1个epoch。
- 转移预训练适配器:在这个阶段,将预训练好的适配器应用于原始具有推理能力的语言模型,从而构建完整的R1V模型。此过程中,所使用的分词器是与原始具有推理能力的语言模型相同的。
- 模型调整以实现跨模态对齐:最后一步是在模型中执行跨模态对齐,仅微调适配器参数而不改变视觉编码器或具有推理能力的语言模型。这一过程利用了Hybrid Optimization Framework和Chain-of-Thought方法来进一步增强模型的一般化能力和鲁棒性。
2. 论文创新点
R1V模型的主要创新之处在于其迁移学习策略,能够有效地降低对大规模推理数据的需求。因多阶段优化框架和自适应链式思考(AL-CoTD)技术,使得模型能够在不同的任务场景下动态地调整推理长度,从而提高了模型的一般化性能。此外,还设计了一个奖励模型和强化学习算法,用于筛选高质量的数据样本并进一步提升模型的性能。这些改进措施有助于克服传统迁移学习方法中的问题,如过度推理、推理不足等。
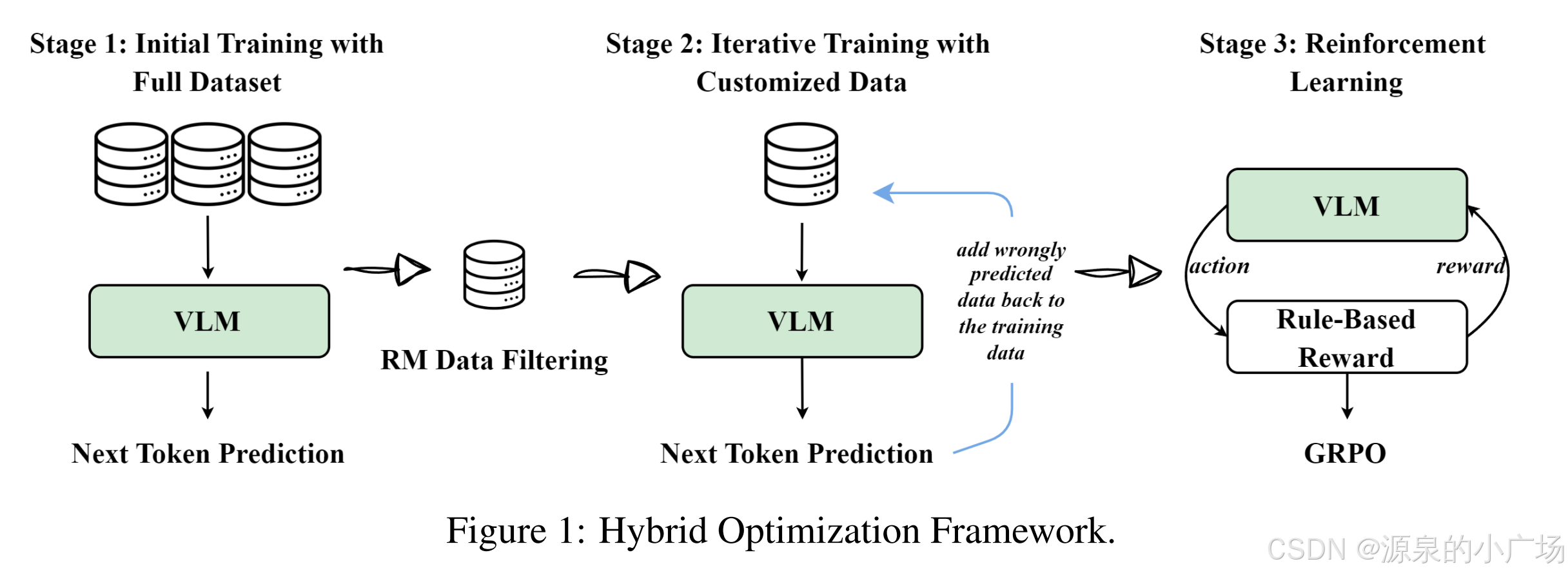
该研究还解决了迁移学习中的一个重要挑战,如何在有限的推理数据上高效地训练具有推理能力的语言模型。传统的迁移学习方法通常需要大量的推理数据才能获得良好的性能,而Skywork R1V模型通过其迁移学习策略和自适应链式思考技术,降低了对大规模推理数据的需求,从而解决了这个问题。同时,提出的奖励模型和强化学习算法也有助于提高模型的性能。

在自适应长度思维链蒸馏中,提到的自适应长度的推理链蒸馏(AL-CoTD)框架,包含质量和难度评估模块 (QDAM)和视觉文本集成分析器(VTIA)。
QDAM利用GPT-4o在两个主要维度上系统地评估图像-文本查询对: 视觉评分 (Sv) 和文本分数 (St)。具体来说,视觉评分通过两个标准评估视觉特征-图像清晰度和图像必要性。图像清晰度通过模糊检测和分辨率分析来量化感知质量,而图像必要性则通过上下文切除测试和相关性分类来评估文本对视觉上下文的依赖性。文本得分通过三个不同的方面检查语言属性: 问题质量,使用语法验证和语义连贯检查评估清晰度; 难度级别,根据特定领域的知识要求衡量概念复杂性;和推理需求,通过多跳推理分析量化推理步骤的复杂性。这些措施共同提供了一个全面的框架,用于捕获多模态查询理解中固有的感知和认知复杂性。所有这些属性都是通过使用GPT-4o获得的,除了图像清晰度。
视觉文本集成分析器(VTIA)通过执行句法和语义分析,生成一个集成分数(SI),使用GPT-4o在图像文本查询中进行模式识别来量化所需的跨模态集成深度。具有高集成度的查询导致SI增加的模式通常出现在需要科学解释或详细推理的任务中。这种模式包括因果连接词 (“为什么”/“如何”) 的存在,伴随着预设触发器,多对象视觉参考需要空间关系理解。和特定领域术语的共出现。相反,呈现低集成模式的查询会导致SI降低。这些通常出现在更简单的任务中,例如对象识别,其特点是带有定冠词的简单疑问 (“什么”/“哪里”),针对直接对象识别的查询,并且文本内容和视觉输入之间的依赖性最小。这个模式驱动的分析框架有助于自适应跨模态融合,精确地适应每个查询的复杂性。
动态推理长度控制器 (DRLC)模块在归一化得分上执行从原始Sv,St得出的归一化得分,和SI通过最小-最大缩放到范围 [0,1]。控制器通过基于查询复杂度调节重复惩罚来动态调整推理链长度。具体而言,具有高视觉-文本质量,相当大的认知困难和复杂的视觉场景,需要更深层次的推理 (反映在更高的值) 的查询。获得较低的重复惩罚,允许更长的推理链。相反,对于较低难度的查询,更简单的视觉识别任务,以及最低的跨模态整合要求 (由较低的 “v”,“t” 和 “i” 表示) 被分配更高的重复惩罚,以防止不必要的推理。重复罚款 (P) 的计算公式为:
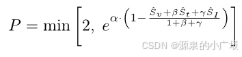
基于DRLC模块构建的多级自蒸馏管道,进一步提出了一种渐进式自蒸馏策略。在这个管道中,模型最初生成用 <思考> 标记明确标注的面向推理的数据,其中重复惩罚P由DRLC模块计算,动态调节推理长度。随后,GPT-4o评估生成答案的正确性。如果一个答案被评估为正确,原始推理链将被保留; 否则,GPT-4o将修改推理过程以使其与正确的答案保持一致。这个过程在阶段1之前进行,并在阶段2的每次迭代之前重复,以在混合优化框架内完善推理链。
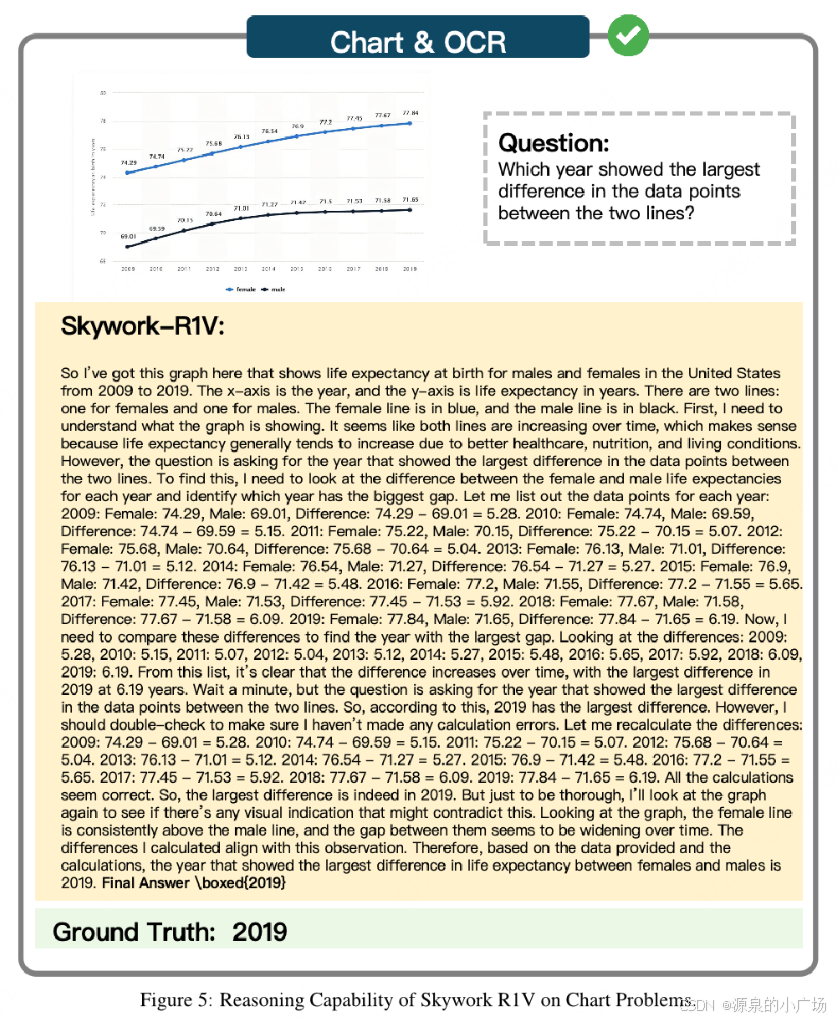
一些case验证:

3. 参考材料
【1】Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
【2】VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks
【3】CogVLM: Visual Expert for Pretrained Language Models