线性回归是一种用于建模和分析关系的线性方法。在简单线性回归中,我们考虑一个 自变量和一个因变量之间的关系,用一条直线进行建模。而在多元线性回归中,我们 可以使用多个自变量来建模,因此我们需要拟合的不再是一个简单的直线,而是在高 维空间上的一个超平面。每个样本的因变量(y)在多元线性回归中依赖于多个自变 量(x),这样的关系可以用一个超平面来表示,这个超平面被称为回归平面。因 此,在多元线性回归中,我们试图找到一个最适合数据的超平面,以最小化实际观测 值与模型预测值之间的差异。
一、数据集介绍
本例使用了一个Bike Sharing Dataset( Datasets - UCI Machine Learning Repository),其中包含关于自行车租赁的信息。数据以csv表格形式保存在dataset 文件夹中,其中day.csv是按日期为最小粒度进行记录的数据,hour.csv是以小时为 最小粒度进行记录的数据,Readme.txt是本案例数据的英文解释。以下是数据集的 中文解释:
数据集地址
自行车共享系统是新一代的传统自行车租赁系统,从会员、租赁和归还的整个过程都变得自动化。通过这些系统,用户可以轻松地从特定位置租用自行车,然后在另一个位置返回。目前,全球约有 500 多个自行车共享计划,由 500 多万辆自行车组成。今天,由于这些系统在交通、环境和健康问题上的重要作用,人们对它们产生了极大的兴趣。
除了自行车共享系统有趣的实际应用外,这些系统生成的数据特性也使它们对研究具有吸引力。与公共汽车或地铁等其他交通服务相反,这些系统中明确记录了旅行时间、出发和到达位置。此功能将自行车共享系统转变为可用于感知城市移动性的虚拟传感器网络。因此,预计可以通过监控这些数据来检测城市中的大多数重要事件。
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| instant | 身份证 | 整数 | 记录索引 | 不 | |
| dteday | 特征 | 日期 | 日期 | 不 | |
| season |
特征 | 分类 | 1:冬天,2:春天,3:夏天,4:秋天 | 不 | |
| yr | 特征 | 分类 | 年份 (0: 2011, 1: 2012) | 不 | |
| casual | 特征 | 分类 | 月 (1 至 12) | 不 | |
| hr | 特征 | 分类 | 小时(0 到 23) | 不 | |
| holiday | 特征 | 二元的 | 天气 DAY IS HOLIDAY OR NOT (摘自 http://dchr.dc.gov/page/holiday-schedule) | 不 | |
| weekday | 特征 | 分类 | 星期几 | 不 | |
| workingday | 特征 | 二元的 | 如果 Day 既不是 Weekend 也不是 Holiday 为 1,否则为 0 | 不 | |
| weathersit | 特征 | 分类 | - 1:晴朗,云少,部分多云,部分多云 | 不 | |
| temp | 特征 | 连续的 | 以摄氏度为单位的标准化温度。这些值是通过 (t-t_min)/(t_max-t_min)、t_min=-8、t_max=+39 得出的(仅限小时刻度) | C | 不 |
| atemp | 特征 | 连续的 | 以摄氏度为单位的正常感觉温度。这些值是通过 (t-t_min)/(t_max-t_min)、t_min=-16、t_max=+50 得出的(仅限小时刻度) | C | 不 |
| hum | 特征 | 连续的 | 标准化湿度。值被划分为 100 (max) | 不 | |
| windspeed | 特征 | 连续的 | 归一化风速。这些值被划分为 67 (max) | 不 | |
| casual | 其他 | 整数 | 临时用户数 | 不 | |
| registered | 其他 | 整数 | 注册用户数 | 不 | |
| cnt | 目标 | 整数 | 租赁自行车总数,包括休闲自行车和注册自行车 | 不 |
hour.csv 和 day.csv 都有以下字段,但 hr 除外,它在 day.csv 中不可用
通过数据集字段的介绍我们可以明确我们的任务是通过不同的特征对cnt(总租赁自 行车数量)进行线性回归预测。
二、读取数据集
数据展示
读取数据
import pandas as pd
df=pd.read_csv('day.csv')三、数据处理
对离散数据进行one-hot处理
df=pd.get_dummies(df,columns=['season','weathersit'])确定自变量(x)和因变量(y)
X=df.drop(columns=['instant','dteday','cnt'])
y=df['cnt']划分数据集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(X_train)
X_train_scaler=scaler.transform(X_train)
X_train_scaler=scaler.transform(X_test)四、模型训练
定义线性回归模型
from sklearn.linear_model import LinearRegression
line_model=LinearRegression()模型拟合
line_model.fit(X_train_scaler,y_train)模型预测
y_predit=line_model.predict(X_test_scaler)五、模型评估
模型评估
from sklearn.metrics import r2_score,mean_squared_error
mse = mean_squared_error(y_test,y_predit)
r2 = r2_score(y_test, y_predit)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
# Mean Squared Error: 1.3054823272945743e-24
# R-squared: 1.0可视化
from matplotlib import pyplot as plt
plt.scatter(y_test, y_predit)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs Predicted Values in Linear Regression') 
sorted_indices = X_test.index.argsort()
y_test_sorted = y_test.iloc[sorted_indices]
y_pred_sorted = pd.Series(y_predit).iloc[sorted_indices]
plt.figure(1,figsize=(15,6))
plt.plot(y_test_sorted.values, label='Actual Values', marker='o')
plt.plot(y_pred_sorted.values, label='Predicted Values', marker='x')
plt.xlabel('Sample Index (Sorted)')
plt.ylabel('Values')
plt.title('Actual vs Predicted Values in Linear Regression')
plt.legend()
plt.show()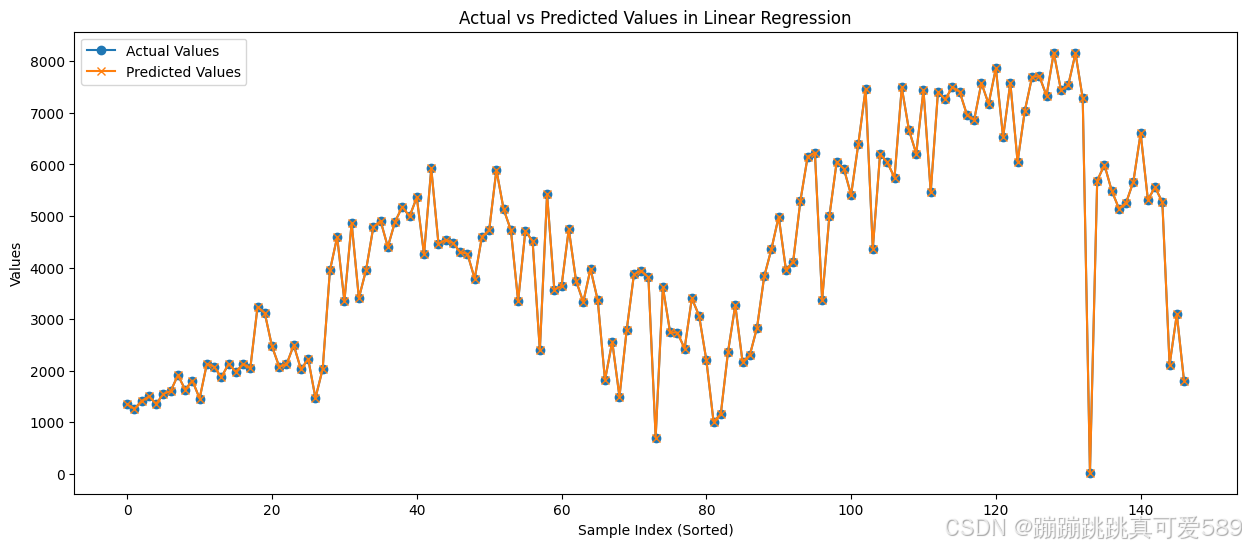
六、完整代码
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from sklearn.metrics import r2_score, mean_squared_error
# 使用pandas的read_csv函数读取数据,这里假设数据保存在day.csv文件中
df = pd.read_csv('day.csv')
# 处理类别特征:使用独热编码
# 通过pd.get_dummies对'day'数据集中季节和天气情况进行独热编码,将这些类别特征转换为多个二进制的虚拟变量列
df = pd.get_dummies(df, columns=['season', 'weathersit'])
# 从原始数据集中选取要作为模型输入特征的列,组成特征矩阵X
# 此处去掉'dteday'、'instant'、'cnt'这几列,因为它们不适合参与建模
X = df.drop(columns=['instant', 'dteday', 'cnt'])
# 选取 'cnt' 列作为目标变量,即模型要预测的对象
y = df['cnt']
# 划分训练集和测试集
# 使用sklearn的train_test_split函数,根据指定的测试集比例(这里是0.2,即20%)和随机种子(random_state=42确保每次划分结果一致)来划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用标准化进行特征缩放
# 创建StandardScaler对象,用于对数据进行标准化处理,使数据的各特征维度具有均值为0,方差为1的分布特点
scaler = StandardScaler()
# 在训练集上拟合标准化器,并将训练集和测试集都进行标准化处理
X_train_scaler = scaler.fit_transform(X_train)
X_test_scaler = scaler.transform(X_test)
# 创建线性回归模型
# 实例化sklearn中的线性回归模型类,这个模型将根据输入的特征和对应的目标变量学习一个线性关系,用于预测目标变量的值
line_model = LinearRegression()
# 训练模型
# 使用训练集数据(标准化后的特征和对应的目标变量)来训练线性回归模型,模型会自动拟合出最佳的系数(权重)
line_model.fit(X_train_scaler, y_train)
# 进行预测
# 使用训练好的线性回归模型对测试集特征数据(已经标准化)进行预测,得到预测值
y_predit = line_model.predict(X_test_scaler)
# 评估模型性能
# 计算均方误差(Mean Squared Error,MSE),它衡量了预测值与实际值之间的平均平方误差,值越小表示模型预测越准确
mse = mean_squared_error(y_test, y_predit)
# 计算R平方值(R-squared),表示模型对目标变量变异的解释程度,取值范围在0到1之间,越接近1表示模型拟合效果越好
r2 = r2_score(y_test, y_predit)
# 打印模型评估指标
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
# 绘制预测结果和实际值的散点图
# 创建第一个图形,用于绘制散点图展示预测值和实际值的对应关系
plt.figure(0)
# 绘制散点图,横坐标为实际值,纵坐标为预测值,通过散点的分布可以直观查看模型预测的准确性和偏差情况
plt.scatter(y_test, y_predit)
plt.xlabel('Actual Values') # 设置x轴标签
plt.ylabel('Predicted Values') # 设置y轴标签
plt.title('Actual vs Predicted Values in Linear Regression') # 设置图表标题
# 按照测试集索引的顺序进行排序
# 获取测试集索引的排序后的顺序,假设测试集索引对应着时间顺序或其他有意义的顺序
sorted_indices = X_test.index.argsort()
# 根据排序后的索引获取对应的实际值
y_test_sorted = y_test.iloc[sorted_indices]
# 根据排序后的索引获取对应的预测值,并转换为pandas的Series
y_pred_sorted = pd.Series(y_predit).iloc[sorted_indices]
# 绘制实际值和预测值的曲线
# 创建第二个图形
plt.figure(1)
# 绘制实际值的曲线,用圆形标记,添加标签
plt.plot(y_test_sorted.values, label='Actual Values', marker='o')
# 绘制预测值的曲线,用叉号标记,添加标签
plt.plot(y_pred_sorted.values, label='Predicted Values', marker='x')
plt.xlabel('Sample Index (Sorted)')
plt.ylabel('Values')
plt.title('Actual vs Predicted Values in Linear Regression')
plt.legend()
# 显示绘制的图形,使图形窗口弹出展示结果
plt.show()七、设计思路
数据准备:
开始时,使用 pandas 读取存储在 CSV 文件中的数据。数据集中包含了许多特征,例如天气、季节等信息,以及目标变量 cnt,表示某种计数或数量(例如自行车的租赁数量)。
为了便于模型处理,将类别特征(如季节和天气情况)通过独热编码转换为数值特征,这一操作将每个类别拆分成若干个二进制列,使模型能够理解这些类别信息。
特征与目标变量的分离:
从数据集中选择特征 X。在特征集内排除了不适合用于模型训练的列,如时间戳 instant 和日期 dteday,只保留影响结果的特征。确定目标变量 y 为 cnt,这是模型需要预测的对象。
数据集划分:
使用 train_test_split 函数将数据集划分为训练集和测试集。将 80% 的数据用于模型训练,20% 的数据用于评估模型性能。这一划分方式能帮助我们验证模型是否具有良好的泛化能力。
特征标准化:
使用 StandardScaler 对数据进行标准化处理,以确保所有特征在同一尺度上。这一步骤将特征的均值调整为0,方差调整为1,通过这种方式可以使模型在训练时更快收敛,并提高性能。
线性回归模型的创建:
实例化线性回归模型对象。这种模型假设特征与目标变量之间存在线性关系,为训练模型做好准备。
模型训练:
使用训练集的特征和目标变量来训练线性回归模型,模型自动学习特征与目标之间的线性关系,并拟合最佳的参数(系数和截距)。
进行预测:
在训练完成后,使用测试集的特征对目标变量进行预测,以获得模型的输出结果。
模型性能评估:
计算模型的性能指标,包括均方误差(MSE)和R平方值(R-squared)。均方误差帮助量化预测的误差,值越小表示预测越准确;而R平方值则反映模型对目标变量变异的解释能力,值越接近1意味着模型拟合效果越好。
结果可视化:
使用散点图展示模型的预测值与实际值之间的关系。通过横坐标为实际值、纵坐标为预测值,可以直观地观察模型的预测精度和偏差。
按照测试集索引的顺序进行排序并绘制实测值与预测值的比较曲线,这样更容易观察随样本索引变化而导致的预测走势。