张量积
张量积(tensor product)或点积(dot product)是最常见且最有用的张量运算之一。注意,不要将其与逐元素乘积(*运算符)弄混。在NumPy中,使用np.dot函数来实现张量积,因为张量积的数学符号通常是一个点(dot)。
x = np.random.random((32,))
y = np.random.random((32,))
z = np.dot(x, y)
数学符号中的点(•)表示点积运算。
z = x•y
从数学角度来看,点积运算做了什么?我们首先看一下两个向量x和y的点积。计算过程如下。
def naive_vector_dot(x, y):
assert len(x.shape) == 1 ←---- (本行及以下1行) x和y都是NumPy向量
assert len(y.shape) == 1
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
z += x[i] * y[i]
return z
可以看到,两个向量的点积是一个标量,而且只有元素个数相同的向量才能进行点积运算。你还可以对一个矩阵x和一个向量y做点积运算,其返回值是一个向量,其中每个元素是y和x每一行的点积。实现过程如下。
def naive_matrix_vector_dot(x, y):
assert len(x.shape) == 2 ←---- x是一个NumPy矩阵
assert len(y.shape) == 1 ←---- y是一个NumPy向量
assert x.shape[1] == y.shape[0] ←---- x的第1维与y的第0维必须大小相同!
z = np.zeros(x.shape[0])
for i in range(x.shape[0]): ←----这个运算返回一个零向量,其形状与x.shape[0]相同
for j in range(x.shape[1]):
z[i] += x[i, j] * y[j]
return z
你还可以重复使用前面写过的代码,从中可以看出矩阵−向量点积与向量−向量点积之间的关系。
def naive_matrix_vector_dot(x, y):
z = np.zeros(x.shape[0])
for i in range(x.shape[0]):
z[i] = naive_vector_dot(x[i, :], y)
return z
注意,只要两个张量中有一个的ndim大于1,dot运算就不再是对称(symmetric)的。也就是说,dot(x, y)不等于dot(y, x)。当然,点积可以推广到具有任意轴数的张量。最常见的应用可能是两个矩阵的点积。对于矩阵x和y,当且仅当x.shape[1] == y.shape[0]时,你才可以计算它们的点积(dot(x, y))。点积结果是一个形状为(x.shape[0], y.shape[1])的矩阵,其元素是x的行与y的列之间的向量点积。简单实现如下
def naive_matrix_dot(x, y):
assert len(x.shape) == 2 ←---- (本行及以下1行) x和y都是NumPy矩阵
assert len(y.shape) == 2
assert x.shape[1] == y.shape[0] ←---- x的第1维与y的第0维必须大小相同!
z = np.zeros((x.shape[0], y.shape[1])) ←----这个运算返回一个特定形状的零矩阵
for i in range(x.shape[0]): ←----遍历x的所有行……
for j in range(y.shape[1]): ←----……然后遍历y的所有列
row_x = x[i, :]
column_y = y[:, j]
z[i, j] = naive_vector_dot(row_x, column_y)
return z
为了便于理解点积的形状匹配,可以将输入张量和输出张量像图2-5中那样排列,利用可视化来帮助理解。在图2-5中,x、y和z都用矩形表示(元素按矩形排列)。由于x的行和y的列必须具有相同的元素个数,因此x的宽度一定等于y的高度。如果你打算开发新的机器学习算法,可能经常要画这种图。
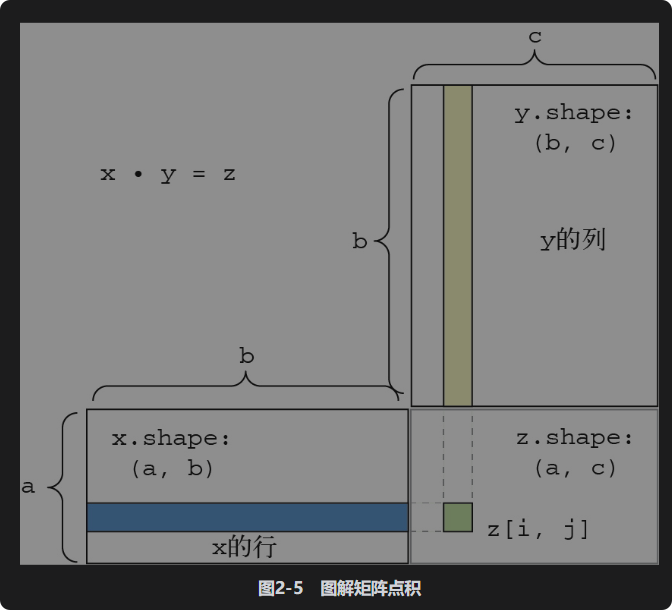
更一般地说,可以对更高阶的张量做点积运算,只要其形状匹配遵循与前面2阶张量相同的原则。
(a, b, c, d)•(d,)→(a, b, c)
(a, b, c, d)•(d, e)→(a, b, c, e)
以此类推。
张量变形
另一个需要了解的张量运算是张量变形(tensor reshaping)。虽然前面第一个神经网络例子的Dense层中没有用到它,但我们将数据输入神经网络之前,在预处理数据时用到了这种运算。
train_images = train_images.reshape((60000, 28 * 28))
张量变形是指重新排列张量的行和列,以得到想要的形状。变形后,张量的元素个数与初始张量相同。下面这个简单的例子可以帮助我们理解张量变形。
>>> x = np.array([[0., 1.],
[2., 3.],
[4., 5.]])
>>> x.shape
(3, 2)
>>> x = x.reshape((6, 1))
>>> x
array([[ 0.],
[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
>>> x = x.reshape((2, 3))
>>> x
array([[ 0., 1., 2.],
[ 3., 4., 5.]])
常见的一种特殊的张量变形是转置(transpose)。矩阵转置是指将矩阵的行和列互换,即把x[i, :]变为x[:, i]。
>>> x = np.zeros((300, 20)) ←----创建一个形状为(300, 20)的零矩阵
>>> x = np.transpose(x)
>>> x.shape
(20, 300)
张量运算的几何解释
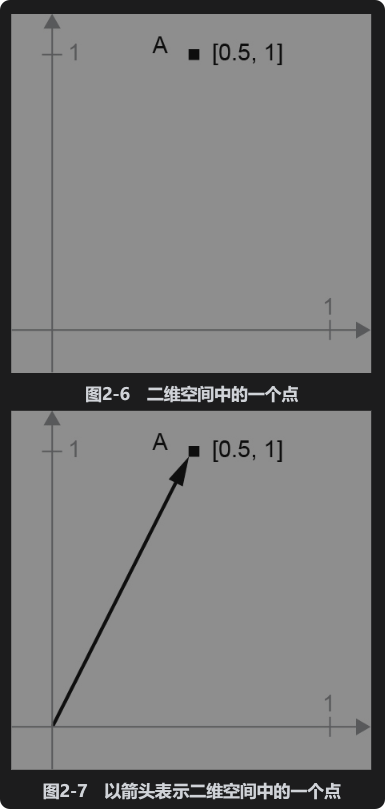
对于张量运算所操作的张量,其元素可看作某个几何空间中的点的坐标,因此所有的张量运算都有几何解释。以加法为例,假设有这样一个向量:
A = [0.5, 1]
它是二维空间中的一个点(见图2-6)。常见的做法是将向量描绘成由原点指向这个点的箭头,如图2-7所示。
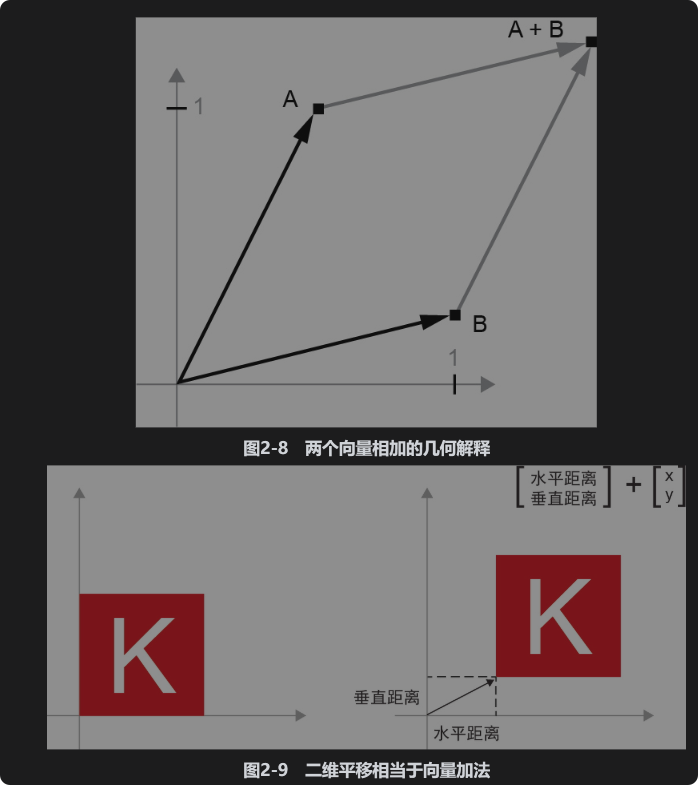
假设有另外一个点:B = [1, 0.25],我们将它与前面的A相加。从几何角度来看,这相当于将两个向量的箭头连在一起,得到的位置表示两个向量之和对应的向量(见图2-8)。如你所见,将向量B与向量A相加,相当于将A点复制到一个新位置,这个新位置相对于A点初始位置的距离和方向由向量B决定。如果将相同的向量加法应用于平面上的一组点(一个物体),就会在新位置上创建整个物体的副本(见图2-9)。因此,张量加法表示将物体沿着某个方向平移一段距离(移动物体,但不使其变形)。
一般来说,平移、旋转、缩放、倾斜等基本的几何操作都可以表示为张量运算。下面看几个例子。平移(translation)。如前所示,在一个点上加一个向量,会使这个点在某个方向上移动一段距离。如果将操作应用于一组点(比如一个二维物体),就叫作“平移”(见图2-9)。旋转(rotation)。要将一个二维向量逆时针旋转theta角(见图2-10),可以通过与一个2×2矩阵做点积运算来实现。这个矩阵为R = [[cos(theta), -sin(theta)],[sin(theta), cos(theta)]]。

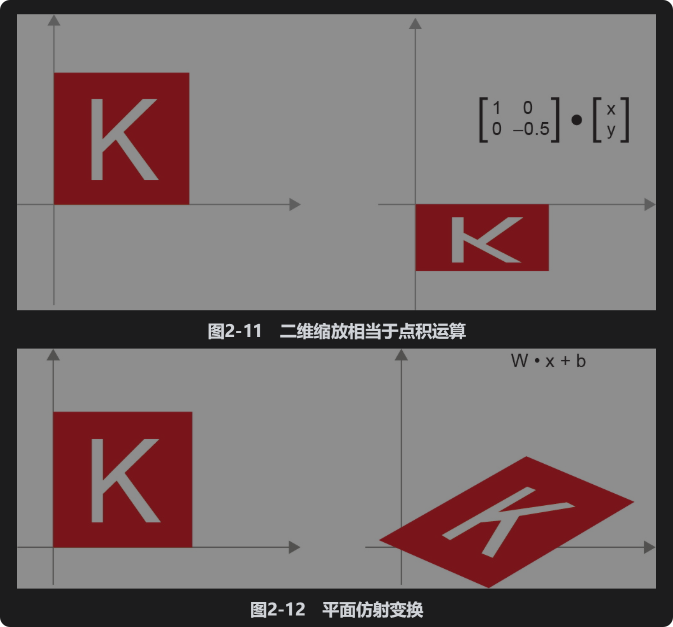
缩放(scaling)。要将图像在垂直方向和水平方向进行缩放(见图2-11),可以通过与一个2×2矩阵做点积运算来实现。这个矩阵为S=[[horizontal_factor, 0], [0,vertical_factor]]。(注意,这样的矩阵叫作“对角线矩阵”,因为它只有在从左上到右下的“对角线”上的元素不为零。)线性变换(linear transform)。与任意矩阵做点积运算,都可以实现一次线性变换。注意,前面所说的缩放和旋转,都属于线性变换。仿射变换(affine transform)。仿射变换(见图2-12)是一次线性变换(通过与某个矩阵做点积运算来实现)与一次平移(通过向量加法来实现)的组合。你可能已经发现,这正是Dense层所实现的y = W•x + b运算!一个没有激活函数的Dense层就是一个仿射层。
带有relu激活函数的Dense层。关于仿射变换的一个重要结论是,重复应用多次仿射变换,仍相当于一次仿射变换(所以可以在一开始就应用这个仿射变换)。我们用两个仿射变换来试一下:affine2(affine1(x)) = W2•(W1•x + b1) + b2 = (W2•W1)•x +(W2•b1 + b2)。这相当于是一次仿射变换,其线性变换部分是矩阵W2•W1,平移部分是向量W2•b1 + b2。因此,一个完全由没有激活函数的Dense层组成的多层神经网络等同于一个Dense层。这种“深度”神经网络其实就是一个线性模型!这就是需要用到激活函数的原因,比如relu(其效果见图2-13)。由于激活函数的存在,一连串Dense层可以实现非常复杂的非线性几何变换,从而为深度神经网络提供非常丰富的假设空间。第3章将更详细地介绍这一点。
