用计算图进行自动微分
思考反向传播的一种有用方法是利用计算图(compu- tation graph)。计算图是TensorFlow和深度学习革命的核心数据结构。它是一种由运算(比如我们用到的张量运算)构成的有向无环图。下图给出了一个模型的计算图表示。
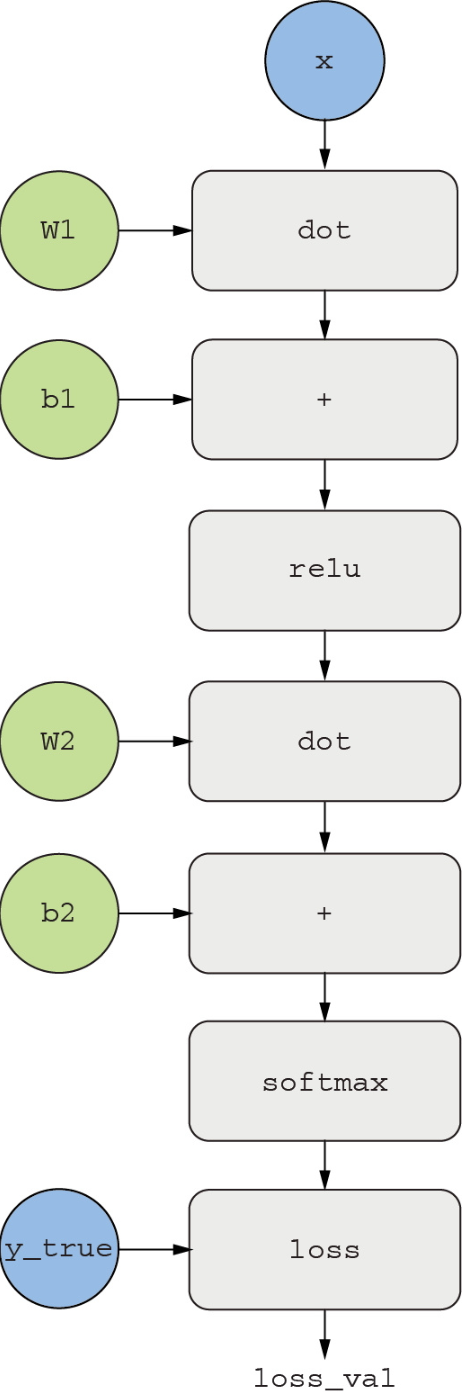
计算图是计算机科学中一个非常成功的抽象概念。有了计算图,我们可以将计算看作数据:将可计算的表达式编码为机器可读的数据结构,然后作为另一个程序的输入或输出。举个例子,你可以想象这样一个程序:接收一个计算图作为输入,并返回一个新的计算图,新计算图可实现相同计算的大规模分布式版本。这意味着你可以对任意计算实现分布式,而无须自己编写分布式逻辑。或者想象这样一个程序:接收一个计算图作为输入,然后自动计算它所对应表达式的导数。如果将计算表示为一个明确的图数据结构,而不是.py文件中的几行ASCII字符,那么做这些事情就容易多了。为了解释清楚反向传播的概念,我们来看一个非常简单的计算图示例,只有一个线性层,所有变量都是标量。我们将取两个标量变量w和b,以及一个标量输入x,然后对它们做一些运算,得到输出y。最后,我们使用绝对值误差损失函数:loss_val = abs(y_true - y)。我们希望更新w和b以使loss_val最小化,所以需要计算grad(loss_val, b)和grad(loss_val, w)。
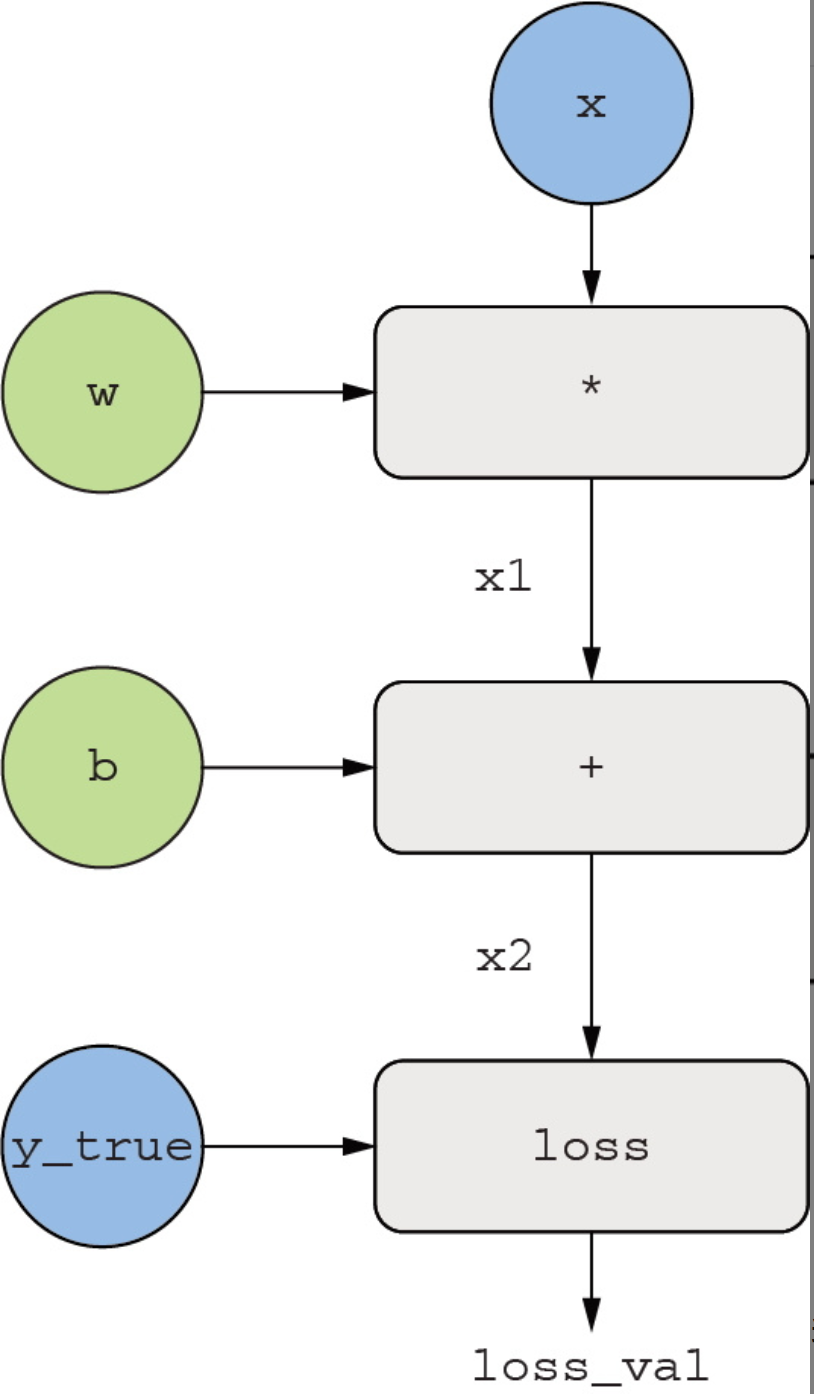
我们为图中的“输入节点”(输入x、目标y_true、w和b)赋值。我们将这些值传入图中所有节点,从上到下,直到loss_val。这就是前向传播过程(如下图)。

下面我们“反过来”看这张图。对于图中从A到B的每条边,我们都画一条从B到A的反向边,如果A发生变化,那么B会怎么变?也就是说,grad(B, A)是多少?我们在每条反向边上标出这个值。这个反向图表示的是反向传播过程(见下图)。

我们得到以下结果。grad(loss_val, x2) = 1。随着x2变化一个小量epsilon,loss_val = abs(4 - x2)的变化量相同。grad(x2, x1) = 1。随着x1变化一个小量epsilon,x2 = x1 + b = x1 + 1的变化量相同。grad(x2, b) = 1。随着b变化一个小量epsilon,x2 = x1 + b = 6 + b的变化量相同。grad(x1, w) = 2。随着w变化一个小量epsilon,x1 = x * w = 2 * w的变化量为2 * epsilon。链式法则告诉我们,对于这个反向图,想求一个节点相对于另一个节点的导数,可以把连接这两个节点的路径上的每条边的导数相乘。比如,grad(loss_val, w) =grad(loss_val, x2) * grad(x2, x1) * grad(x1, w),如下图所示。
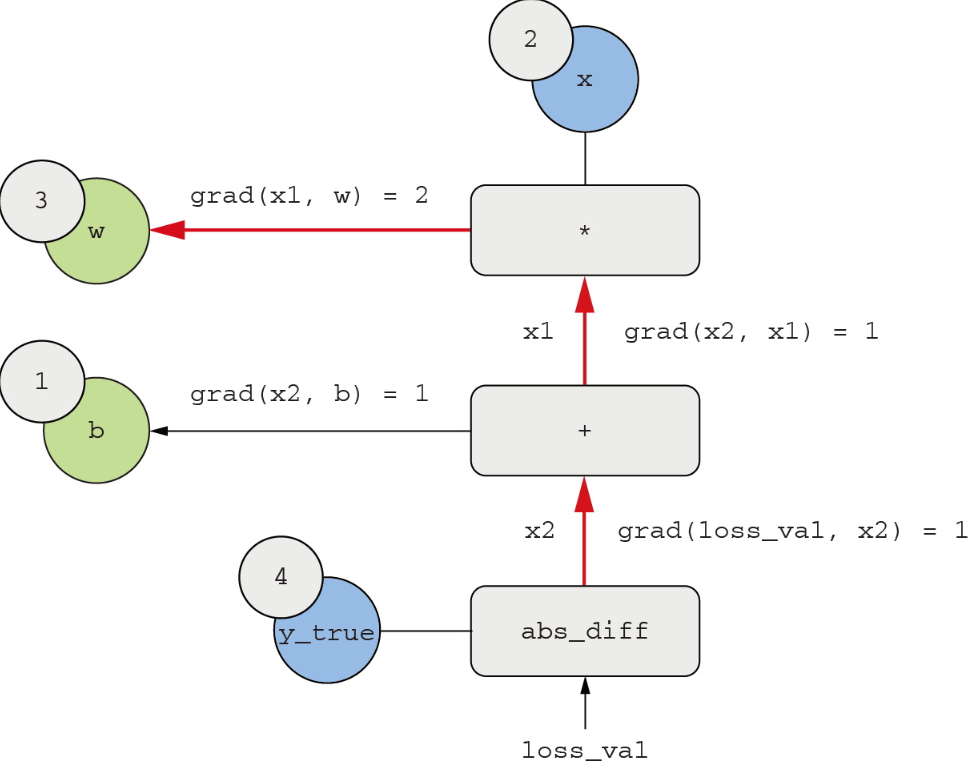
对该图应用链式法则,我们可以得到如下想要的结果。grad(loss_val, w) = 1 * 1 * 2 = 2grad(loss_val, b) = 1 * 1 = 1注意 在反向图中,如果两个节点a和b之间有多条路径,那么grad(b, a)就是将所有路径的值相加。刚刚,你看到的就是反向传播的具体过程。反向传播就是将链式法则应用于计算图,仅此而已。反向传播从最终损失值开始,自下而上反向运行,计算每个参数对损失值的贡献。这就是“反向传播”这个名称的由来:我们“反向传播”计算图中不同节点对损失值的贡献。人们利用能够自动微分的现代框架来实现神经网络,比如TensorFlow。自动微分是利用前文所述的计算图来实现的。自动微分可以计算任意可微张量运算组合的梯度,只需要写出前向传播,而无须做任何额外工作。
TensorFlow的梯度带
GradientTape是一个API,让你可以充分利用TensorFlow强大的自动微分能力。它是一个Python作用域(scope),能够以计算图[有时也被称为“条带”(tape)]的形式“记录”在其中运行的张量运算。计算图可用来获取任意输出相对于任意变量或变量集的梯度,这些变量或变量集都是tf.Variable类的实例。tf.Variable是一类用于保存可变状态的张量,比如神经网络的权重就是tf.Variable的实例。
import tensorflow as tf
#将标量Variable的值初始化为0
x = tf.Variable(0.)
#创建一个GradientTape作用域
with tf.GradientTape() as tape:
#在作用域内,对变量做一些张量运算
y = 2 * x + 3
#利用梯度带获取输出y相对于变量x的梯度
grad_of_y_wrt_x = tape.gradient(y, x)
print(grad_of_y_wrt_x)
GradientTape也可用于张量运算。
#将Variable初始化为形状为(2, 2)的零张量
x = tf.Variable(tf.zeros((2, 2)))
with tf.GradientTape() as tape:
y = 2 * x + 3
#grad_of_y_wrt_x是一个形状为(2, 2)的张量(形状与x相同),表示y = 2 * a + 3在x = [[0, 0], [0, 0]]附近的曲率
grad_of_y_wrt_x = tape.gradient(y, x)
print(grad_of_y_wrt_x )
它还适用于变量列表。
W = tf.Variable(tf.random.uniform((2, 2)))
b = tf.Variable(tf.zeros((2,)))
x = tf.random.uniform((2, 2))
with tf.GradientTape() as tape:
#在TensorFlow中,matmul是指点积
y = tf.matmul(x, W) + b
# grad_of_y_wrt_W_and_b是由两个张量组成的列表,这两个张量的形状分别与W和b相同
grad_of_y_wrt_W_and_b = tape.gradient(y, [W, b])
print(grad_of_y_wrt_W_and_b )
本文所有可执行代码如下:
import tensorflow as tf
#将标量Variable的值初始化为0
x = tf.Variable(0.)
#创建一个GradientTape作用域
with tf.GradientTape() as tape:
#在作用域内,对变量做一些张量运算
y = 2 * x + 3
#利用梯度带获取输出y相对于变量x的梯度
grad_of_y_wrt_x = tape.gradient(y, x)
print()
print(grad_of_y_wrt_x)
#将Variable初始化为形状为(2, 2)的零张量
x = tf.Variable(tf.zeros((2, 2)))
with tf.GradientTape() as tape:
y = 2 * x + 3
#grad_of_y_wrt_x是一个形状为(2, 2)的张量(形状与x相同),表示y = 2 * a + 3在x = [[0, 0], [0, 0]]附近的曲率
grad_of_y_wrt_x = tape.gradient(y, x)
print()
print(grad_of_y_wrt_x )
W = tf.Variable(tf.random.uniform((2, 2)))
b = tf.Variable(tf.zeros((2,)))
x = tf.random.uniform((2, 2))
with tf.GradientTape() as tape:
#在TensorFlow中,matmul是指点积
y = tf.matmul(x, W) + b
# grad_of_y_wrt_W_and_b是由两个张量组成的列表,这两个张量的形状分别与W和b相同
grad_of_y_wrt_W_and_b = tape.gradient(y, [W, b])
print()
print(y)
print()
print(grad_of_y_wrt_W_and_b )
执行结果如下:
tf.Tensor(2.0, shape=(), dtype=float32)
tf.Tensor(
[[2. 2.]
[2. 2.]], shape=(2, 2), dtype=float32)
tf.Tensor(
[[0.56152403 0.89904356]
[0.8393539 1.3886162 ]], shape=(2, 2), dtype=float32)
[<tf.Tensor: shape=(2, 2), dtype=float32, numpy=
array([[0.77996933, 0.77996933],
[1.5719919 , 1.5719919 ]], dtype=float32)>, <tf.Tensor: shape=(2,), dtype=float32, numpy=array([2., 2.], dtype=float32)>]