随机梯度下降
给定一个可微函数,理论上可以用解析法找到它的最小值:函数的最小值就是导数为0的点,因此只需找到所有导数为0的点,然后比较函数在其中哪个点的取值最小。将这一方法应用于神经网络,就是用解析法求出损失函数最小值对应的所有权重值。可以通过对方程grad(f(W), W) = 0求解W来实现这一方法。这是一个包含N个变量的多项式方程,其中N是模型的系数个数。当N = 2或N = 3时,可以对这样的方程进行求解,但对于实际的神经网络是无法求解的,因为参数的个数不会少于几千个,而且经常有上千万个。
不过可以这么做:基于当前在随机数据批量上的损失值,一点一点地对参数进行调节。我们要处理的是一个可微函数,所以可以计算出它的梯度。沿着梯度的反方向更新权重,每次损失值都会减小一点。
(1)抽取训练样本x和对应目标y_true组成的一个数据批量。(2)在x上运行模型,得到预测值y_pred。这一步叫作前向传播。(3)计算模型在这批数据上的损失值,用于衡量y_pred和y_true之间的差距。(4)计算损失相对于模型参数的梯度。这一步叫作反向传播(backward pass)。(5)将参数沿着梯度的反方向移动一小步,比如W -= learning_rate * gradient,从而使这批数据上的损失值减小一些。学习率(learning_rate)是一个调节梯度下降“速度”的标量因子。这个方法叫作小批量随机梯度下降(mini-batch stochastic gradient descent,简称小批量SGD)。术语随机(stochastic)是指每批数据都是随机抽取的(stochastic在科学上是random的同义词)。下图给出了一维的例子,模型只有一个参数,并且只有一个训练样本。
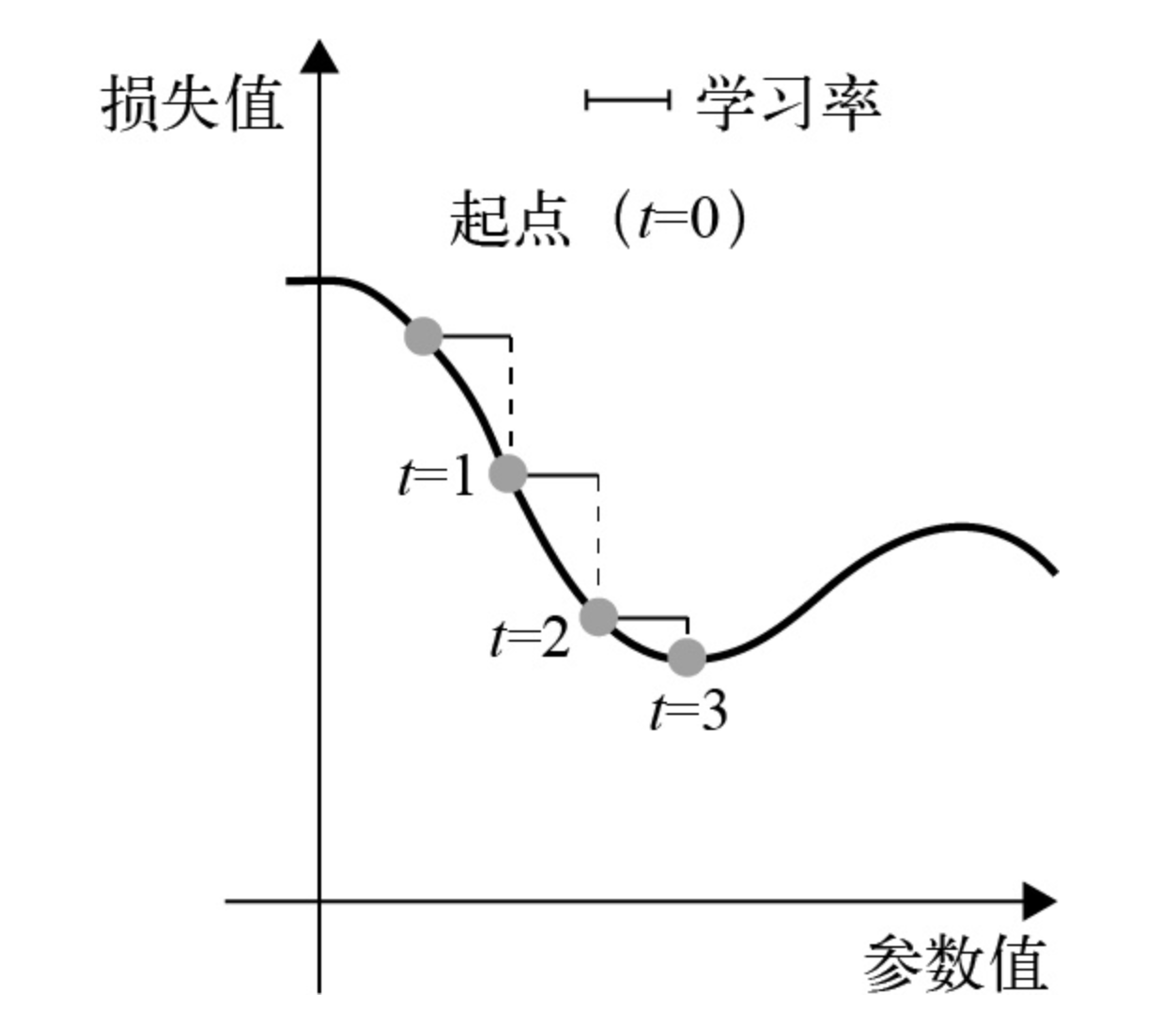
learning_rate因子的取值很重要。如果取值太小,那么沿着曲线下降需要很多次迭代,而且可能会陷入局部极小点。如果取值过大,那么更新权重值之后可能会出现在曲线上完全随机的位置。注意,小批量SGD算法的一个变体是每次迭代只抽取一个样本和目标,而不是抽取一批数据。这叫作真SGD(true SGD,有别于小批量SGD)。还可以走向另一个极端:每次迭代都在所有数据上运行,这叫作批量梯度下降(batch gradient descent)。这样做的话,每次更新权重都会更加准确,但计算成本也高得多。这两个极端之间有效的折中方法则是选择合理的小批量大小。
在实践中需要在高维空间中使用梯度下降。神经网络的每一个权重