作为一名很久没更新的UP:今天为大家提供一篇最近很火的DeepSeek本地部署教程。
本教程将涵盖从环境搭建到模型部署的整个过程,并提供简单的代码和bash命令示例。

引言
随着人工智能技术的飞速发展,越来越多的开发者希望在本地环境中运行和使用大模型,以避免网络延迟、保护数据隐私以及降低成本。本文将详细介绍如何在本地部署DeepSeek模型,让你能够轻松上手并享受其强大的功能。
一、准备工作
1. 硬件要求
为了确保DeepSeek模型的顺利运行,建议使用以下硬件配置:
- CPU:支持AVX2指令集(大多数现代CPU都支持)
- 内存:至少16GB,推荐32GB或以上
- 存储空间:至少50GB空闲空间
- 显卡:NVIDIA GPU推荐,显存8GB及以上
2. 软件要求
- 操作系统:Windows、macOS或Linux
- Ollama:一个轻量级AI模型运行框架,用于下载和运行模型
- ChatBox:一个可视化界面工具,用于与模型进行交互(可选)
二、安装Ollama
1. 下载Ollama
访问Ollama官网,根据你的操作系统选择对应的安装包进行下载。--点击进入
例如,对于Windows系统,直接下载.exe文件;对于MacOS系统,则下载.dmg文件。
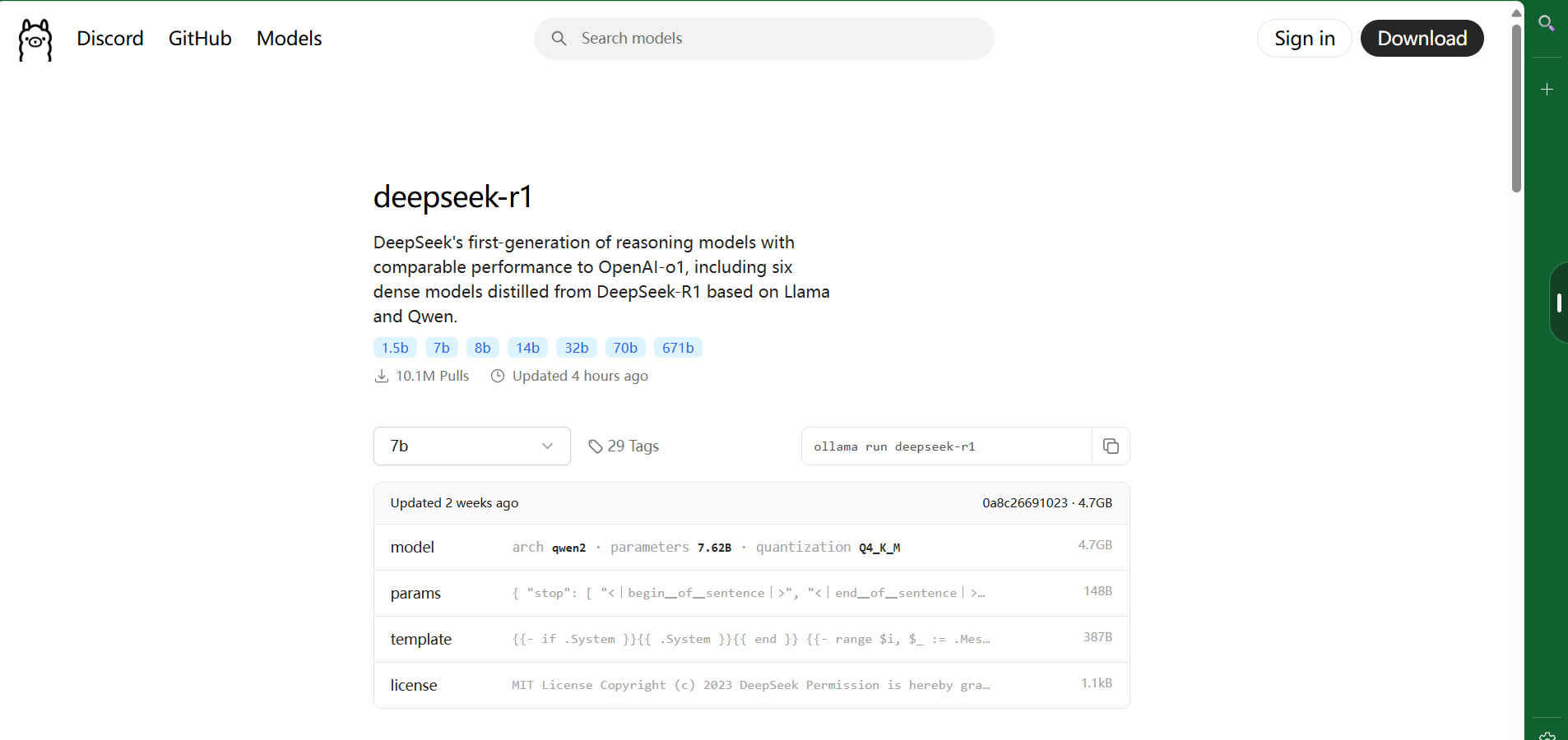
2. 安装Ollama
- Windows系统:双击下载的安装包,按照提示完成安装。
- MacOS系统:将下载的安装包拖动到“应用程序”文件夹中完成安装。
- Linux系统:在终端中输入以下命令进行安装:
curl -fsSL https://ollama.com/install.sh | sh
3. 验证安装
安装完成后,打开终端或命令提示符,输入以下命令检查Ollama是否安装成功:
ollama --version
如果显示了Ollama的版本号,则说明安装成功。
三、部署DeepSeek模型
1. 获取并安装模型
打开Ollama模型库,搜索deepseek-r1,并复制对应版本的安装命令。例如,如果你选择8B版本,可以在终端中输入以下命令进行安装:
ollama run deepseek-r1:8b
首次运行时,系统会自动下载约5GB左右的模型文件,请耐心等待。
2. 测试模型是否正常运行
安装完成后,在终端中输入以下命令测试模型是否正常运行:
说一句有趣的新年祝福
如果模型成功回应,则说明部署无误。
四、安装可视化界面(可选)
如果你更喜欢类似ChatGPT那样的可视化界面,可以安装ChatBox AI。以下是安装步骤:
1. 下载ChatBox
访问Chatbox官网,下载对应系统的安装包。
2. 连接本地模型
打开ChatBox,进入设置页面。在“模型设置”里选择“Ollama API”,并在模型名称中选择你刚刚部署的DeepSeek模型(如
deepseek-r1:8b)。点击“检查连接”,如果状态正常,就可以开始愉快地使用啦!
五、优化交互和性能
为了让AI跑得更顺畅,你可以尝试以下小技巧:
- 关闭其他大型程序,避免占用过多内存。
- 复杂问题分步提问,能提高模型的理解力。
- 使用英文关键词,有时能提升响应速度。
- 定期重启Ollama,释放内存,让AI保持最佳状态。
六、常见问题及解决方案
1. Q1:运行时提示显存不足?
A1:尝试使用8B版本或升级显卡驱动。
2. Q2:AI回答乱码?
A2:在Chatbox设置中切换编码为UTF-8。
3. Q3:如何更新模型?
A3:在终端执行:
ollama pull deepseek-r1:8b