IGU-Aug: Information-Guided Unsupervised Augmentation and Pixel-Wise Contrastive Learning for Medical Image Analysis
标签: 医学图像、对比学习、无监督增强
【背景】
对比学习(CL)是一种自监督学习(SSL)形式,已广泛用于各种任务。与广泛研究的实例级对比学习不同,像素级对比学习主要助力于像素级密集预测任务。在实例级 CL 中实例的对应物在像素级 CL 中是一个像素及其相邻上下文。为构建更好的特征表示,有大量关于为实例级 CL 设计实例增强策略的文献,但针对像素级 CL 的像素增强工作较少。
- 对比学习应用局限:对比学习作为自监督学习的一种,在实例级任务中广泛应用,可有效提升分类等任务性能。但将实例级对比学习方法直接应用于像素级下游任务(如地标检测、分割、对象检测)时,因监督粒度差异,效果有限,研究者转而关注像素级对比学习。
- 像素级对比学习挑战:像素级对比学习性能很大程度取决于正负样本对生成。当前缺乏无监督的自动数据增强方法,虽有监督训练中的方法可借鉴,但因缺乏标签无法用于无监督像素级对比学习。如何在无监督方式下,有效增强像素级对比学习的训练样本对成为挑战。
- 像素信息特性及增强需求:图像在像素层面信息分布不均衡,不同像素及其上下文对理解图像中部分、对象和结构的帮助程度不同。如地标检测等像素级任务,更依赖信息丰富的像素。且在对比学习中,语义信息多的像素对在强增强下受影响更大,现有方法很少以无监督方式针对不同像素采用不同增强策略。
【方法】
本文尝试填补这一空白,首先根据像素所含信息量将其分为低、中、高信息三类,然后针对每类在增强强度和采样比方面自适应设计单独的增强策略。
【结果】
大量实验验证,我们的信息引导像素增强策略能成功编码更具判别力的表示,在无监督局部特征匹配中优于其他竞争方法。此外,我们的预训练模型提升了一次性和完全监督模型的性能。据我们所知,我们是首个提出像素级像素增强方法以增强无监督像素级对比学习的团队。代码可在 GitHub - Curli-quan/IGU-Aug 获取。
>
引言:
文章主要探讨了如何在无监督情况下有效扩充逐像素对比学习(pixel - wise CL)的训练对,提出两点内容:
根据像素信息含量调整增强策略:图像像素信息不均衡,语义信息多的正样本对在强增强下易受损,因此对信息含量高的像素采用弱增强,信息含量低的像素采用强增强。借助图像信息熵(IIE)划分像素组,在信息丰富区域对比更多像素对。
- 举例子:比如说,可能会对图像进行大幅度的扭曲、色彩改变等操作,这些操作会改变像素原本携带的语义信息。比如原本图像中代表某个物体的像素区域,经过强增强后,可能变得难以辨认其代表的物体,从而侵蚀(erodes)了语义信息。 所以在这种情况下,强增强对含有较多语义信息的像素正样本对的负面影响更大。
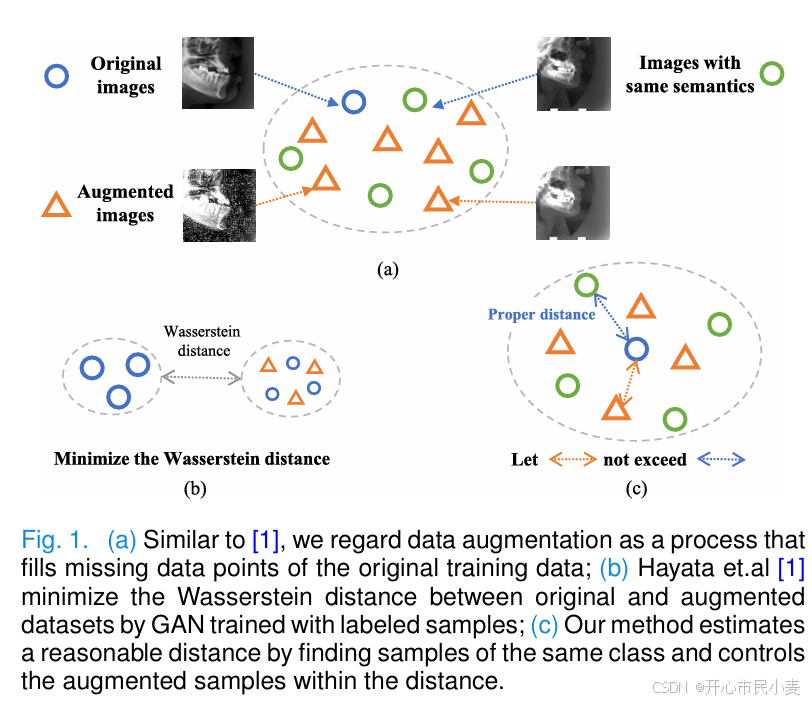
基于语义一致性评估增强参数:将语义一致的像素视为同一类别,通过观察增强数据与原始数据的兼容性评估数据增强参数的适用性。用互信息估计边缘样本到中心的距离判断增强是否合适,同时采用组级平均减少逐像素估计增强参数带来的误差 。
核心思想:受 FasterAug 启发,提出的方法核心思想是优化增强参数,使实例内样本(通过数据增强得到)和类内样本(从数据集中搜索的语义相同样本)的分布一致。具体步骤为计算实例内和类内样本之间的互信息,得到相应的密度,然后调整增强参数使这两种密度一致。
图片内容解释
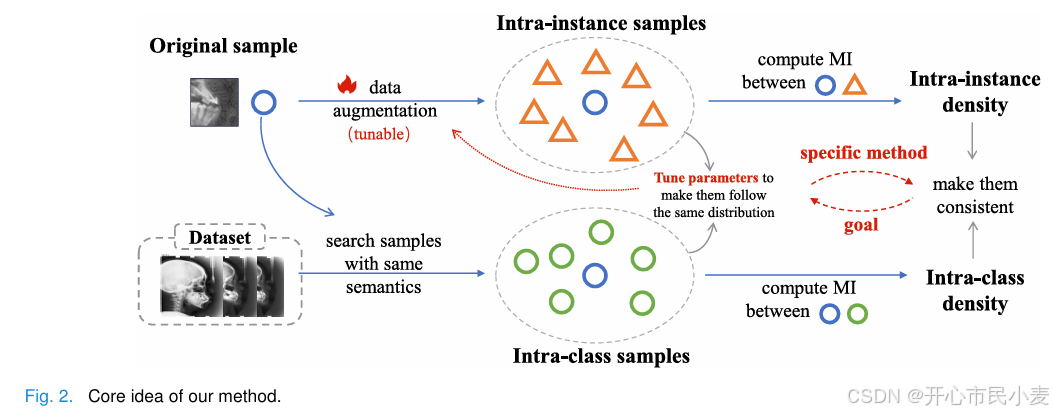
图 2 展示了上述方法的核心思想:
- 原始样本(蓝色圆圈)经过可调节的数据增强,生成实例内样本(橙色三角形),计算原始样本和实例内样本之间的互信息,得到实例内密度。
- 从数据集中搜索具有相同语义的样本(绿色圆圈),计算原始样本和这些类内样本之间的互信息,得到类内密度。
目标是通过特定方法调整增强参数,使实例内密度和类内密度一致。
然而,上述方法存在不足。对于像素级任务,每个像素都相当于一个样本。对每个像素使用不同的增强会使训练过程过于复杂。此外,当为单个像素寻找增强参数时,其类内样本大小是有限的,这相当于训练图像的数量,从而导致估计不可靠。
因此,核心思想:(1)通过图像信息熵将熵样本(像素),聚类成几组;(2)对每个组应用自适应增强。
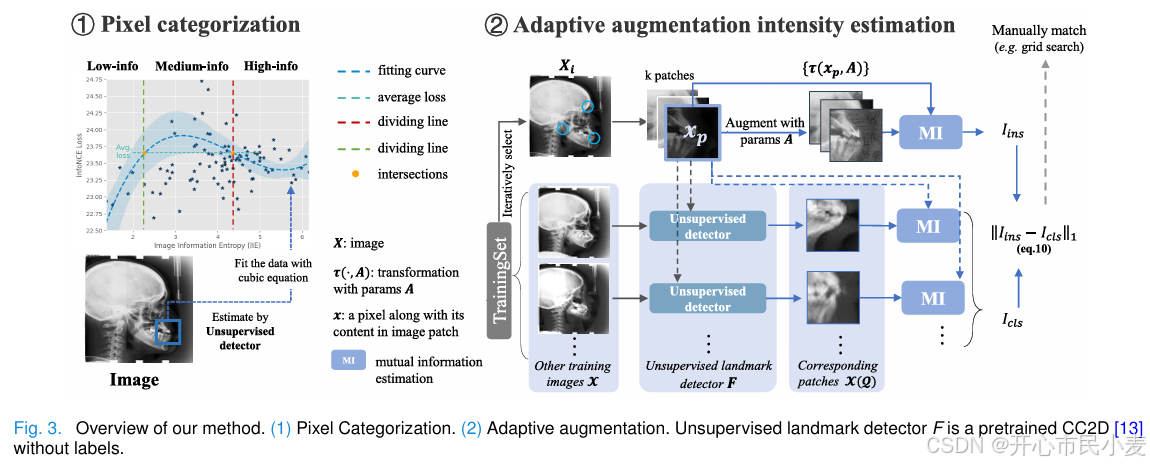

像素分类(Pixel categorization)
- 原理与坐标含义:在图 3 的左图中,横坐标是图像信息熵(IIE),它衡量了图像中像素信息的不确定性或丰富程度;纵坐标是对比损失(Loss),用于衡量模型预测结果与真实结果之间的差异。
- 数据拟合与分类:使用三阶多项式回归对数据进行拟合,得到蓝色曲线。结合损失的 U 形曲线以及总平均损失的虚线,将像素划分成三类。低信息(Low - info)像素表示其包含的信息量较少,对模型的贡献可能相对较小;中等信息(Medium - info)像素处于中间状态;高信息(High - info)像素则包含丰富的信息,对模型的训练可能更为关键。
- 辅助分析:图中展示的示例图像,通过无监督检测器来分析像素的相关特征,帮助确定每个像素所属的类别。无监督检测器不需要人工标注的数据,能够自动从图像中提取特征并进行分析。
无监督检测器作用:无监督检测器不需要事先标记好的数据,能自主从示例图像中挖掘特征信息。它可以检测出图像中像素的各种属性,比如像素的灰度值分布、纹理特征、局部的空间结构等。以医学图像为例,无监督检测器可能会发现某些区域像素灰度值较为均匀,而另一些区域像素灰度值变化剧烈,这些特征对于判断像素类别很关键。
特征提取与分析:对于示例图像中的每一个像素,无监督检测器会基于周围像素的信息来提取其特征。比如在图像的边缘区域,像素的变化往往比较明显,无监督检测器能识别出这些边缘像素的独特特征,像梯度的方向和大小等。而在图像的平滑区域,像素的特征可能表现为灰度值相近且变化幅度小。通过对这些特征的分析,无监督检测器可以为每个像素生成一个特征描述符,这个描述符包含了像素在空间、灰度、纹理等方面的信息。
辅助像素分类:有了每个像素的特征描述符后,就可以结合图像信息熵和对比损失的分析结果,将像素划分到低信息、中等信息和高信息类别中。例如,具有较高信息熵且处于对比损失 U 形曲线特定位置,同时其特征描述符显示包含丰富纹理和灰度变化的像素,可能会被归类为高信息像素;而那些信息熵较低,特征描述符显示像素特征单一的,则可能被划分为低信息像素。无监督检测器提取的特征为像素分类提供了更具体、更细致的依据,使得分类结果更加准确合理 。
信息引导像素分类

D. Detailed Guidance

上述操作的计算复杂度主要取决于采样SIFT点和训练图像的计数。假设我们有NP采样点和NI训练图像。对于每个采样点,我们需要识别所有其他图像中的对应点,并计算它们的互信息(MI)。然后,我们迭代调整增广参数,直到达到最佳参数,通常在K次迭代中。对于每次迭代,我们为每个采样点生成NA增强点并计算它们的MI。预测点的计算复杂度为O(NP NI)。估计互信息的计算复杂度为O(NP NI)+O(NP NA K)。在实践中,我们通常将NP设置为100,并确保NA保持在20以下。NI的值因数据集大小而异。然而,如果NI变得非常大,可能会导致计算时间非常长,从而限制了我们方法的可扩展性。为了缓解这个问题,我们可以对训练图像进行采样,而不是使用完整的训练集,以降低计算复杂度。
实验:
Other CL Methods 其他对比学习方法对比
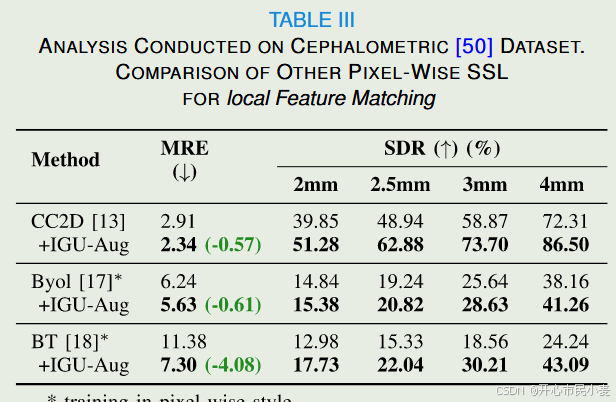
我们在另外两个CL框架上尝试了我们的方法,BYOL[17]和Barlow Twins[18](BT)。与将整个图像编码为向量的普通BYOL和BT不同,我们将图像编码为特征图,并计算与感兴趣点对应的向量损失。因此,我们将实例CL框架更改为像素CL框架。我们的方法成功地提升了这些方法,如表三所示。此外,这两种模型都专注于聚类正对,而忽略了区分负对,这导致了比CC2D更差的性能。
鲁棒、泛化,不足:
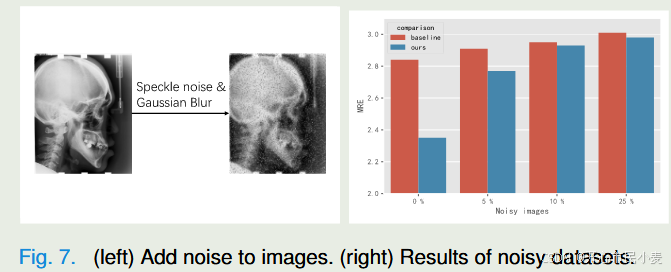
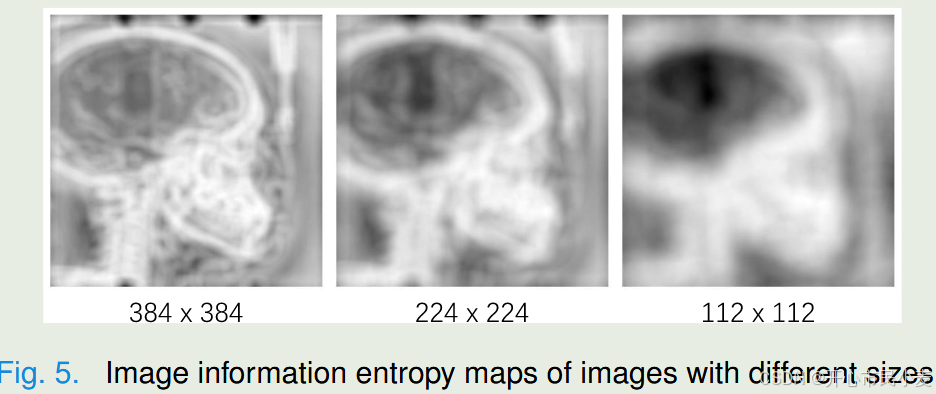
1) 低分辨率图像:我们对低分辨率图像进行实验。如图5所示,由于边界模糊,从分辨率较低的图像中很难区分中高信息像素。如图6(左)所示,随着分辨率的降低,IIE的范围变得越来越窄。如图6(右)所示,我们的方法带来的改进也变小了。

2) 噪声图像:我们对包含显著噪声的图像进行实验,如图7所示。我们将强散斑噪声和高斯模糊引入头影测量数据集中5%、10%、25%和50%的图像,以创建具有噪声的新数据集,然后评估其性能。同样,我们也将我们的方法应用于这些有噪声的数据集。我们观察到,当更多的图像从无噪声过渡到有噪声时,类内样本之间的互信息会增加,这会导致对数据增强参数的保守预测。此外,使用噪声图像作为模板进行预测会导致预测精度降低,并在互信息计算中引入更多误差。这两种操作都会导致数据集的参数估计较差。图7显示,随着噪声图像数量的增加,我们的方法带来的好处会变小。